Bugs d'expiration d'essai gratuit : cas limites et règles claires
Les bugs d'expiration d'essai viennent souvent des calculs temporels et d'états ambigus. Apprenez des règles claires, cas limites et tests pour périodes de grâce et comportement après fin d'essai.
Pourquoi les essais gratuits se terminent au mauvais moment
Les essais gratuits cassent souvent d'une façon qui semble personnelle : un utilisateur est bloqué un jour trop tôt, facturé plus tôt que prévu, ou voit une bannière « essai expiré » alors que l'application le laisse encore entrer. Les tickets de support suivent vite : « Votre minuterie est fausse », « Je me suis inscrit hier soir », ou « Ça s'est terminé pendant ma démo. »
Cela arrive parce que le temps est compliqué. Les gens s'inscrivent dans des fuseaux horaires différents. L'heure d'été fait avancer ou reculer les horloges. Les serveurs et bases de données stockent des timestamps dans différents formats. Même « 30 jours » peut signifier des choses différentes si une partie de votre code compte des jours calendaires et une autre compte des heures. Ajoutez des réessais, des jobs en arrière-plan et du cache, et vous obtenez plusieurs endroits qui calculent « le trial est-il actif ? » légèrement différemment.
Une source fréquente de confusion est de mélanger deux moments distincts :
- Trial ended : la période gratuite est terminée (point de décision de facturation).
- Access revoked : l'utilisateur ne peut plus utiliser les fonctionnalités payantes (point de décision produit).
Ces moments peuvent être identiques, mais ils n'ont pas à l'être. Si vous avez une période de grâce, des réessais ou des overrides manuels, explicitez-les en règles, pas en effets secondaires accidentels.
L'objectif est simple : définir une seule source de vérité pour le timing des essais (généralement un timestamp stocké trial_ends_at), et construire des tests reproductibles autour. Les tests doivent inclure des dates délicates comme fins de mois et changements DST, pas seulement « maintenant + 7 jours ».
Les données à suivre (et ce en quoi ne pas avoir confiance)
La plupart des bugs d'expiration commencent par des données manquantes ou floues. Si vous ne stockez que « trial = true » et un nombre de « trial days », chaque décision ultérieure devient une supposition.
Stockez un petit ensemble de timestamps qui vous permettent de répondre à une question : que l'utilisateur est autorisé à faire maintenant ?
Au minimum, conservez :
trial_started_at: quand le trial a réellement commencé (après une inscription réussie, pas après le chargement de page)trial_ends_at: le moment exact où l'accès au trial s'arrêtecanceled_at: quand l'utilisateur a annulé (si vous autorisez l'annulation durant le trial)paid_at: quand le premier paiement réussi a eu lieu (pas quand vous avez créé une session de checkout)ended_at: quand vous avez marqué le trial comme terminé (utile pour audits et replay)
Sauvegardez ces valeurs comme des timestamps complets en UTC. UTC supprime les surprises liées à l'heure d'été et évite les bugs de « minuit » quand un utilisateur voyage ou qu'un serveur tourne dans une autre région. Convertissez en heure locale uniquement pour l'affichage.
Ne faites pas confiance à l'heure de l'appareil pour l'application des règles. Les téléphones peuvent être faux, les utilisateurs peuvent changer l'horloge, et l'heure du navigateur peut dériver. Utilisez l'heure serveur (ou l'heure de la base de données) comme source de « maintenant », et basez les comparaisons sur cette horloge unique.
Évitez aussi de mélanger des champs « date seulement » avec de vrais timestamps. « 2026-01-20 » semble simple, mais cela cache un fuseau horaire implicite et une coupure non définie. Est-ce minuit à l'emplacement de l'utilisateur, minuit UTC, ou fin de journée ? Cette ambiguïté est une cause fréquente de bugs d'expiration.
Règle simple : si l'accès en dépend, stockez un timestamp UTC exact.
Règles de calcul du temps qui évitent les erreurs d'unité
La plupart des bugs d'expiration surviennent parce que l'équipe produit entend une chose (« deux semaines ») et le code fait autre chose (« jusqu'au prochain minuit »). Corrigez cela en écrivant une règle claire, puis en faisant en sorte que chaque écran et job utilise la même règle.
D'abord, décidez ce qu'est un trial.
Si vous voulez le comportement le plus simple et le plus prévisible, utilisez une durée fixe : 14 x 24 heures depuis trial_started_at. Cela évite les débats sur ce que « minuit » signifie.
Si vous avez vraiment besoin d'un essai basé sur une date (« valide jusqu'à une date calendaire spécifique »), cela peut fonctionner, mais seulement si vous définissez le fuseau horaire à l'avance (fuseau horaire client, ou un fuseau de facturation unique) et sans deviner.
Ensuite, définissez la frontière comme exclusive, pas inclusive. Une règle claire : le trial est valide tant que now < trial_ends_at. À l'instant now == trial_ends_at, le trial est terminé. Cela élimine les cas limites où deux systèmes divergent d'une seconde.
Faites attention à l'arrondi. Les bugs apparaissent quand un endroit stocke les secondes, un autre tronque aux minutes, et un troisième affiche des jours. Traitez les timestamps comme précis, et n'arrondissez que pour l'affichage.
Enfin, documentez ce que « minuit » signifie pour votre business. Si vous utilisez le minuit local quelque part, vous devez définir quel locale et comment les changements DST l'affectent. Beaucoup d'équipes évitent cela en faisant tout le stockage et les comparaisons en UTC.
Périodes de grâce : choisissez une politique simple et tenez-vous-y
Une période de grâce est un tampon après lequel l'accès devrait normalement se terminer. Elle aide à réduire les verrouillages accidentels et donne au système de facturation le temps de réessayer sans générer une vague de tickets support.
Les équipes se mettent en difficulté en lançant accidentellement deux périodes de grâce différentes. Choisissez un seul déclencheur et faites-en le seul.
Choisissez un seul moment de départ
Choisissez l'un des deux :
- Démarrer la grâce à
trial_ends_at. - Démarrer la grâce après la première tentative de paiement échouée.
Puis écrivez la règle en une phrase et gardez-la stable, par exemple : « La période de grâce commence à trial_ends_at et dure 72 heures. » Stockez la durée (ou la date calculée de fin de grâce) pour que changer la politique plus tard n'écrase pas l'historique.
Décidez ce que signifie l'accès pendant la grâce
Évitez l'accès « qui marche à moitié ». Choisissez un mode clair que le produit et le support peuvent expliquer. L'accès complet est le plus simple mais risqué. Lecture seule est courant pour les tableaux de bord. Un mode limité (par exemple, consultation autorisée mais export bloqué) est souvent un bon compromis.
Les overrides du support sont un autre endroit où les politiques se cassent en silence. Si vous autorisez des extensions, traitez-les comme des événements explicites : qui a approuvé, pour combien de temps, pourquoi, et quelle est la nouvelle date de fin. Loggez cela avec les événements de facturation pour que les audits et tests puissent les rejouer.
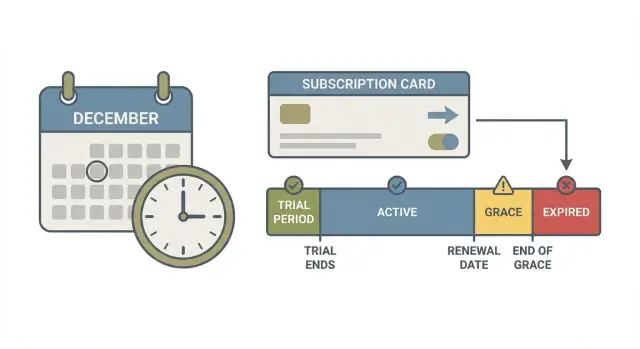
États « trial-ended » : rendez-les explicites, pas implicites
Beaucoup de bugs surviennent quand « trial ended » est traité comme une supposition : si now > trial_ends_at, le système suppose que le compte n'est plus en essai. Cela marche jusqu'à ce que vous ajoutiez des périodes de grâce, des paiements échoués, des upgrades, des remboursements ou des corrections manuelles.
Au lieu de cela, stockez un état d'abonnement explicite que votre système peut raisonner. Gardez-le petit et ennuyeux :
trialingactivepast_duecanceledexpired
Puis définissez les transitions autorisées et ce qui les déclenche. Par exemple :
trialing -> activequand le premier paiement réussittrialing -> expiredquandtrial_ends_atest atteint et qu'il n'y a pas de conversionactive -> past_duequand un renouvellement échouepast_due -> activequand un paiement réussit ensuiteactive -> canceledquand l'utilisateur annule
La réactivation est l'endroit où la logique implicite crée des restes bizarres. Si vous autorisez expired -> active (upgrade après essai), traitez cela comme un nouveau départ propre : définissez state=active, enregistrez une nouvelle fin de période payée (par exemple current_period_ends_at), et effacez ou ignorez les champs réservés au trial. Sinon vous vous retrouvez avec des utilisateurs « active » qui subissent encore des verrous liés à la fin d'essai.
Enfin, faites qu'un seul endroit dans le code décide de l'accès basé sur state + timestamps. Ne répandez pas les vérifications d'accès entre contrôleurs, UI et jobs background. Gardez une seule fonction de politique que toutes les surfaces appellent.
Cas limites qui cassent la logique d'expiration
La plupart des bugs apparaissent quand le temps réel devient désordonné. Quelques règles couvrent presque tous les cas, tant que vous les appliquez de manière cohérente.
- Stockez tous les timestamps d'essai en UTC et traitez-les comme source de vérité. Convertissez en fuseau horaire utilisateur uniquement pour l'affichage.
- Ne convertissez pas en va-et-vient pendant les calculs. C'est ainsi qu'un essai « bouge » d'une heure selon l'endroit où le code tourne.
L'heure d'été est le piège classique. Un « essai de 14 jours » n'est pas toujours la même chose que « 336 heures » une fois que vous impliquez l'heure locale. Décidez de ce que vous promettez et encodez-le : soit « expire après N x 24 heures en UTC » soit « expire à la même heure locale après N jours calendaires ». Choisissez une option, puis testez les weekends DST.
Les fins de mois et les jours bissextiles causent des surprises similaires quand on mélange la mathématique calendaire avec la mathématique de durée. « Ajouter 1 mois » à partir du 31 janvier peut devenir le 28/29 février, puis le 28/29 mars, ce qui semble incorrect si vous attendiez « fin de mois ». Si votre essai est mesuré en jours, évitez les mois entièrement.
Les problèmes opérationnels peuvent aussi casser l'expiration :
- Dérive d'horloge : n'utilisez jamais l'heure de l'appareil pour appliquer les règles.
- Dérive des serveurs : fiez-vous à une source de temps unique pour tous les services.
- Jobs tardifs : les tâches en file peuvent s'exécuter en retard, donc les vérifications doivent être idempotentes.
- Réessais : des événements « trial ended » dupliqués ne doivent pas entraîner une double facturation.
Annulations, upgrades et changements de plan pendant un essai
La logique d'expiration casse habituellement quand les règles normales entrent en collision avec les actions utilisateur. Si vous ne définissez pas de règles pour les annulations et changements de plan, l'app va deviner, et différents écrans devineront différemment.
Si un utilisateur annule pendant l'essai
Choisissez une politique et explicitez-la :
- Annuler maintenant, conserver l'accès jusqu'à
trial_ends_at. - Annuler maintenant, mettre fin à l'accès immédiatement.
« Fin de journée » semble simple, mais tend à créer des disputes de fuseau horaire. Si vous l'utilisez, vous devez définir quel fuseau et ce que « fin de journée » signifie.
Quelle que soit votre décision, stockez-la comme données. Par exemple : conservez trial_ends_at inchangé, définissez canceled_at, mettez un flag comme will_renew=false, et laissez les vérifications d'accès lire ces champs. Ajoutez un test qui annule 1 minute avant la fin d'essai et confirmez le même résultat via l'API et l'UI.
Upgrades, downgrades et changements de plan
Les upgrades sont l'endroit où l'argent et le temps se rencontrent, donc décidez si un upgrade déclenche une facturation immédiate ou attend la fin du trial.
Un ensemble de règles propre ressemble à ceci :
- Upgrade pendant l'essai : soit facturer immédiatement et définir
trial_ends_at=null, soit programmer le plan payant pour démarrer àtrial_ends_at. - Downgrade pendant l'essai : ne réinitialisez pas l'horloge du trial ; changez seulement ce qui se passe après le trial.
- Changement de plan : ne recomputez pas
trial_ends_atà partir de « maintenant » à moins que vous n'accordiez intentionnellement plus de temps.
Si vous facturez à la fin du trial, prévoyez des remboursements et des contestations. L'approche la plus sûre sépare « trial terminé » de « paiement réussi ». Un trial peut se terminer, un paiement peut échouer, et les règles d'accès doivent gérer cela sans envoyer les utilisateurs dans des états aléatoires.
Étape par étape : implémenter l'expiration avec une source de vérité
Différentes parties d'une app « décident » souvent du statut du trial indépendamment : une page vérifie un timestamp, un webhook un autre, et la facturation utilise une troisième règle. Corrigez cela en écrivant les règles une fois, puis en faisant en sorte que tout appelle la même décision.
Commencez par rédiger la politique en anglais simple (ou en français) avec des timestamps concrets, des fuseaux et des résultats. Exemple : « Un essai de 7 jours qui commence 2026-01-20 10:15:00Z se termine le 2026-01-27 10:15:00Z. L'accès est autorisé jusqu'à l'instant exact de fin, puis refusé. » Si vous autorisez une période de grâce, spécifiez-la avec la même précision.
Une séquence pratique :
- Définissez la politique avec quelques exemples réels (incluez un proche du minuit et un proche d'un changement DST).
- Implémentez une fonction de décision qui retourne
can_accessplus une chaîne de raison. - Quand le trial est créé, calculez et stockez une seule valeur
trial_ends_aten UTC. Ne la recalculez pas dans les vues, webhooks et jobs background. - Faites appliquer les changements d'état en un seul endroit : soit un job planifié qui marque les trials comme terminés, soit une vérification « à la demande » qui met à jour l'état quand un utilisateur charge l'app. Choisissez une approche et tenez-vous-y.
- Loggez chaque décision avec les entrées et la sortie (ID utilisateur,
now, timestamps stockés, décision). Cela accélère grandement la gestion des litiges et le débogage.
Erreurs courantes qui créent des bugs d'expiration
La plupart des bugs d'expiration ne sont pas des « problèmes de maths ». Ils viennent d'avoir plus d'un endroit qui décide si un utilisateur doit avoir accès.
Les timers côté client sont un échec classique. Si l'UI utilise l'horloge de l'appareil, les utilisateurs peuvent changer les paramètres temporels, traverser des fuseaux horaires, ou subir des changements DST et gagner des heures (ou en perdre). L'enforcement appartient au serveur, en utilisant une source de temps unique.
La logique éclatée est tout aussi pénible : l'UI dit « trial active » tandis que l'API bloque les requêtes, ou l'API autorise l'accès pendant que l'UI affiche un paywall. Cela arrive généralement quand des vérifications ont été ajoutées à différents endroits au fil du temps.
Autres pièges fréquents :
- Comparer des dates comme des chaînes ("2026-1-2" vs "2026-01-02")
- Mélanger millisecondes et secondes entre services
- Arrondir des timestamps à minuit sans s'accorder sur un fuseau horaire
- Traiter
trial_ends_atcomme inclusif à un endroit et exclusif à un autre
Surveillez aussi les extensions accidentelles d'essai. Il est facile de réinitialiser trial_ends_at à la connexion, au rafraîchissement ou lors de la visite de la page de prix, surtout quand la configuration du trial s'exécute depuis plusieurs écrans.
Les webhooks ajoutent leur propre désordre. Les événements de paiement peuvent arriver en retard, être réessayés, ou apparaître dans le mauvais ordre. Rendre les handlers idempotents, stocker le dernier temps d'événement traité, et baser l'accès sur votre état d'abonnement stocké, pas sur « quel webhook est arrivé en dernier ».
Checklist rapide avant la mise en production
La plupart des bugs apparaissent après le lancement, quand de vrais utilisateurs rencontrent des timings et des patterns de réessai étranges. Avant de déployer, confirmez que ceci est vrai dans votre codebase et vos tests :
trial_ends_atest stocké en UTC et ne change pas après création sauf extension explicite.- Chaque comparaison utilise la même règle partout (par exemple : accès autorisé tant que
now < trial_ends_at). - Le comportement de la période de grâce est cohérent entre UI, API et enforcement de facturation.
- Les événements tardifs ne font pas reculer l'état.
- Les logs montrent les timestamps exacts utilisés pour chaque décision d'accès (
now, temps de fin stockés, état résultant).
Un scénario de sanity check rapide
Créez un utilisateur de test dont l'essai se termine le 2026-01-20T00:00:00Z. Vérifiez l'accès 1 seconde avant, exactement à, et 1 seconde après. Répétez via chaque chemin qui peut contrôler l'accès : requête API, job d'expiration planifié, et tout handler de webhook.
Scénario d'exemple et prochaines étapes
Parcourez une timeline compliquée et notez ce que l'utilisateur devrait voir à chaque étape.
Un utilisateur s'inscrit vendredi à 23:30 dans une région où le DST commence dimanche (les horloges avancent). À l'inscription, définissez trial_started_at au timestamp exact d'inscription et trial_ends_at = trial_started_at + durée.
Samedi : l'utilisateur est trialing et a accès. L'UI doit afficher le temps restant basé sur trial_ends_at, pas des raccourcis de jours calendaires.
Dimanche : DST change. L'utilisateur est toujours trialing. Rien ne change côté backend. Seul l'affichage change.
Lundi 23:35 : l'utilisateur ouvre l'app et tente de payer.
Si vous offrez une période de grâce de 24 heures après la fin du trial, le comportement attendu doit être le même partout :
- Jusqu'à
trial_ends_at: accès trial - De
trial_ends_atàtrial_ends_at + grace: accès en grâce (tel que documenté) - Après la fin de la grâce sans paiement :
expiredet bloqué (hors facturation) - Après un paiement réussi à tout moment :
active
Les tests pour ce scénario doivent exister avant de livrer : fin d'essai pendant un changement DST, vérifications de frontière (une seconde avant/à/après), chemins de succès et d'échec de paiement, et accord UI/API sur l'état.
Si votre logique d'abonnement a été générée rapidement et se comporte maintenant de façon incohérente, un petit audit trouve souvent la cause : fuseaux mélangés, contrôles d'accès éparpillés, ou définitions concurrentes de « trial actif ». FixMyMess (fixmymess.ai) se concentre sur la transformation de prototypes fragiles générés par l'IA en systèmes prêts pour la production en consolidant le temps et la logique d'état en un point de décision testé.
Questions Fréquentes
Pourquoi l'essai gratuit d'un utilisateur s'est-il terminé un jour trop tôt ?
C'est généralement un décalage de fuseau horaire ou un problème d'arrondi. Une partie du système peut compter des « jours calendaires » (fin à minuit) tandis qu'une autre compte des « heures depuis l'inscription », donc les utilisateurs près de minuit perdent presque une journée complète. Corrigez cela en stockant un seul trial_ends_at en UTC et en appliquant la même comparaison partout pour l'accès.
Quels timestamps dois-je stocker pour éviter les bugs d'expiration d'essai ?
Stockez des timestamps UTC complets qui permettent de répondre aux questions d'accès sans deviner : trial_started_at, trial_ends_at, paid_at, canceled_at, et un champ d'audit comme ended_at si vous avez besoin d'un enregistrement de quand vous l'avez marqué comme terminé. Évitez de vous reposer sur un booléen comme trial=true plus un trial_days, car chaque vérification ultérieure va recalculer différemment.
Comment calculer `trial_ends_at` pour un essai de 7 ou 14 jours ?
Calculez-le une seule fois au moment où le trial commence réellement (après l'inscription réussie, pas après le chargement de page). Pour un essai basé sur la durée, définissez trial_ends_at = trial_started_at + (N * 24 heures) en UTC et persistez-le. Ne le recalculez pas dans l'UI, les webhooks ou les jobs en arrière-plan.
`trial_ends_at` doit-il être inclusif ou exclusif ?
Utilisez une frontière exclusive : autorisez l'accès tant que now < trial_ends_at. À l'instant où now == trial_ends_at, l'essai est terminé. Cela évite les désaccords « même seconde » entre services et les cas limites où une partie considère le moment de fin comme encore valide.
Puis-je appliquer l'expiration d'essai en utilisant l'heure du navigateur ou du téléphone ?
Appliquez l'expiration sur le serveur en utilisant une horloge de confiance (heure serveur ou heure base de données). Les horloges d'appareil dérivent, les utilisateurs peuvent les modifier, et les navigateurs peuvent être dans un fuseau différent de votre backend. Vous pouvez toujours afficher une minuterie dans l'UI, mais l'API doit être l'autorité finale.
Comment ajouter une période de grâce sans créer des règles d'accès confuses ?
Choisissez une politique simple et écrivez-la en une phrase, puis implémentez-la en un seul endroit. Un défaut courant : « La période de grâce commence à trial_ends_at et dure 72 heures », avec l'accès pendant la grâce clairement défini (accès complet, lecture seule, ou mode limité). Stockez la règle de grâce ou la date dérivée de fin pour que les changements de politique ultérieurs n'altèrent pas d'anciens comptes.
Quelle est la politique d'annulation la plus sûre pendant un essai ?
Choisissez une règle et appliquez-la de façon cohérente entre l'UI et l'API. L'option la moins surprenante : « annuler maintenant, conserver l'accès jusqu'à trial_ends_at », en définissant canceled_at et will_renew=false (ou équivalent) pour éviter le démarrage de la facturation. Si vous coupez l'accès immédiatement lors de l'annulation, indiquez-le explicitement et testez les annulations proches de la fin d'essai.
Comment gérer des webhooks de facturation tardifs ou dupliqués sans casser l'accès ?
Faites en sorte que le traitement des webhooks soit idempotent et basé sur l'état. Les événements de paiement peuvent arriver en retard, être réessayés ou arriver dans le désordre ; n'autorisez pas le « dernier webhook gagnant » à décider de l'accès. Stockez plutôt un état d'abonnement (trialing, active, past_due, expired, canceled) plus des timestamps, et laissez les webhooks mettre à jour cet état seulement lorsque la transition est valide.
Quels tests couvrent le mieux les cas limites d'expiration d'essai ?
Testez les frontières et les dates bizarres, pas seulement « maintenant + 7 jours ». Ajoutez des tests pour une seconde avant/à/après trial_ends_at, les fins de mois, le jour bissextile et les week-ends DST dans les fuseaux pertinents. Testez aussi que l'UI et l'API s'accordent sur le même état de compte pour les mêmes timestamps stockés.
Quand dois-je faire appel à FixMyMess pour corriger la logique d'essai et d'abonnement ?
Il est temps d'auditer lorsque vous voyez des comportements contradictoires : l'UI affiche « trial active » mais l'API bloque, différents endpoints calculent l'expiration différemment, ou les essais bougent d'une heure autour du DST. FixMyMess (fixmymess.ai) peut réaliser un audit gratuit du code pour trouver des contrôles d'accès éparpillés, des unités de temps mélangées et des fuites de fuseau horaire, puis consolider le tout en un point de décision testé afin que les essais se terminent exactement quand vous le souhaitez.