Bonnes pratiques de gestion des erreurs API pour des messages utilisateur clairs
Apprenez les bonnes pratiques de gestion des erreurs API pour des formats cohérents, des messages sûrs, et une méthode simple pour mapper les pannes serveur à des états UI clairs.
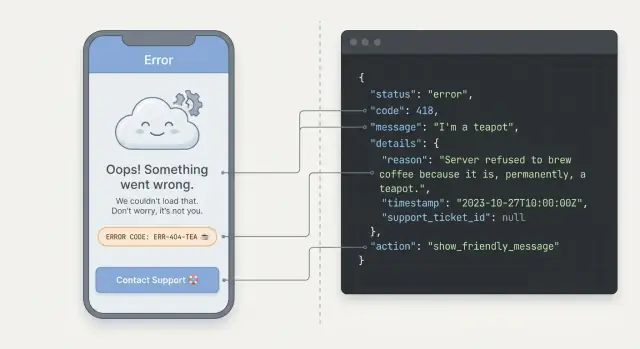
Pourquoi des erreurs API peu claires frustrent les utilisateurs
Quand une appli échoue, les utilisateurs ne voient pas « une exception ». Ils voient une tâche bloquée. Si le message est vague ou inquiétant, ils peuvent craindre d'avoir perdu des données, d'avoir fait une erreur, ou même d'avoir été piratés. La plupart n'essaieront pas de déboguer. Ils partiront, cliqueront frénétiquement à nouveau, ou contacteront le support.
Des erreurs confuses donnent aussi une impression d'aléa. Un écran peut dire « Quelque chose s'est mal passé », un autre affiche une longue trace serveur, et un troisième ne renvoie rien du tout. Cette incohérence fait hésiter les gens car ils ne savent pas à quoi s'attendre. Même si le problème est mineur, l'expérience paraît peu fiable.
Pour votre équipe, les erreurs incohérentes créent du bruit. Les tickets de support s'allongent parce que les utilisateurs ne peuvent pas décrire ce qui s'est passé. L'analytics se remplit d'échecs « inconnus » non regroupés. Les ingénieurs perdent du temps à reproduire des problèmes parce que la forme de la réponse change entre les endpoints, ou parce qu'un 500 est utilisé pour tout.
Quand les erreurs sont floues, les utilisateurs font généralement l'une des trois choses : réitérer à plusieurs reprises (ce qui peut créer des requêtes en double et parfois des facturations en double), abandonner le flux (surtout checkout, inscription, et réinitialisation de mot de passe), ou contacter le support avec des captures d'écran plutôt que des détails exploitables.
Une gestion claire des erreurs corrige cela en standardisant trois éléments :
- Une forme d'erreur cohérente (pour que chaque endpoint échoue de la même manière)
- Un libellé sûr (pour donner une étape suivante claire sans exposer les détails internes)
- Un comportement UI prévisible (pour que chaque erreur corresponde à un état connu comme « réessayer », « corriger le champ », ou « se reconnecter »)
Ce qu'une bonne erreur doit faire (pour les utilisateurs et pour votre équipe)
Une bonne erreur n'est pas seulement « quelque chose s'est mal passé ». Elle aide une personne réelle à se rétablir, et elle aide votre équipe à trouver la cause rapidement.
Pour les utilisateurs, une erreur doit contenir trois choses : ce qui s'est passé (en termes simples), que faire ensuite (une étape claire), et si leurs données sont en sécurité. « Votre carte a été refusée. Essayez une autre carte ou appelez votre banque. Aucun prélèvement n'a été effectué » est rassurant et exploitable. « Paiement échoué : 402 » ne l'est pas.
Pour votre équipe, la même erreur doit porter des identifiants stables et du contexte utile. Cela implique généralement un petit ensemble de codes d'erreur sur lesquels vous pouvez compter entre les endpoints, plus des champs cohérents pour que le logging, les alertes et la gestion côté UI ne se cassent pas lorsqu'un endpoint change. Quand un utilisateur signale un problème, le support doit pouvoir récupérer un identifiant d'erreur depuis l'UI et un ingénieur doit retrouver la trace exacte.
Ce qui ne doit jamais arriver dans l'UI
Certains détails sont utiles pour le débogage mais dangereux (ou juste déroutants) pour les utilisateurs. Gardez-les hors des messages destinés aux utilisateurs :
- Secrets (clés API, tokens, mots de passe, chaînes de connexion)
- Traces de pile et chemins de fichiers internes
- SQL brut, paramètres de requête et payloads complets
- Noms de services internes et d'infrastructures
- Règles de validation détaillées qui aident les attaquants à deviner des entrées
Une règle simple : renvoyez des messages sûrs et conviviaux, et conservez les détails précis dans des logs liés à un code stable et à un request ID.
Choisissez quelques états UI que vous supporterez partout
Si chaque écran invente son propre comportement d'erreur, les utilisateurs se sentent perdus. Mettez-vous d'accord sur un petit ensemble d'états UI que chaque page, modal et formulaire peut utiliser, puis mappez les erreurs API vers ces états de la même manière à chaque fois.
Pour la plupart des applis, un vocabulaire court et partagé suffit : loading, success, empty, needs action (l'utilisateur doit changer quelque chose), try again (problème temporaire), et blocked (il ne peut pas continuer sans support ou un autre abonnement).
Définissez ce que chaque état signifie en termes simples. Par exemple, « empty » signifie que la requête a réussi mais qu'il n'y a rien à afficher, tandis que « try again » signifie que la requête a échoué et qu'une réessai pourrait fonctionner.
Décidez ce qui est réessayable ou non. Un timeout, une limitation de débit ou une surcharge serveur est souvent réessayable. Permission manquante, entrée invalide, ou compte expiré ne le sont généralement pas tant que quelque chose n'a pas changé.
Une règle rapide :
- Try again : temporaire, sûr à réessayer
- Needs action : l'utilisateur peut corriger (éditer, se reconnecter, confirmer un e-mail)
- Blocked : l'utilisateur ne peut pas résoudre seul
Préparez aussi le cas de succès partiel. Cela survient quand une action en masse sauvegarde 8 éléments et que 2 échouent. L'UI doit montrer ce qui a réussi, indiquer clairement ce qui nécessite une action et permettre à l'utilisateur de réessayer uniquement les éléments échoués.
Concevez une forme d'erreur cohérente (un format pour tous les endpoints)
Si chaque endpoint renvoie des erreurs différemment, votre UI doit deviner ce qui s'est passé. Une forme d'erreur unique et prévisible est l'une des meilleures pratiques les plus pratiques car elle permet de construire un seul ensemble de règles UI et de le réutiliser partout.
Un format JSON simple
Choisissez une structure JSON et renvoyez-la pour toutes les erreurs (validation, auth, rate limits, bugs serveur). Gardez-la compacte, mais laissez de la place pour des détails.
{
"error": {
"code": "AUTH_INVALID_CREDENTIALS",
"message": "Email or password is incorrect.",
"details": {
"fields": {
"email": "Not a valid email address"
}
},
"developerMessage": "User not found for email: [email protected]"
},
"requestId": "req_01HZX..."
}
Utilisez des codes d'erreur stables, et ne considérez pas le texte du message comme un contrat. L'UI doit mapper les codes vers l'état approprié, tandis que le message reste lisible pour un humain.
Il aide souvent de garder deux messages : un message utilisateur sûr à afficher, et un message développeur optionnel qui aide au débogage mais ne doit pas exposer de secrets.
Pour les formulaires, prévoyez un emplacement clair pour les erreurs par champ afin de pouvoir surligner des entrées spécifiques sans analyser du texte.
Quelques règles qui évitent le chaos plus tard :
- Inclure toujours
error.codeetrequestId. - Garder
error.messagesûr et simple. - Mettre les problèmes au niveau champ sous
details.fields. - Garder les codes stables même si le libellé change.
- Ne jamais divulguer de traces de pile ou d'identifiants sensibles.
Messages d'erreur sûrs que les utilisateurs peuvent comprendre
De bons messages aident les gens à se rétablir. De mauvais messages les poussent à réessayer la même chose ou à abandonner le flux. Soyez précis sur ce que l'utilisateur peut faire ensuite, sans révéler le fonctionnement interne de votre système.
Un message sûr explique le résultat et la prochaine étape, sans exposer des détails comme des noms de tables, des traces de pile, des réponses de fournisseurs, des clés secrètes, ou si une adresse e-mail existe dans votre système.
Gardez deux messages : un pour les utilisateurs, un pour les développeurs. Le message utilisateur doit être court et calme. Le message interne peut inclure la raison technique, le service en échec et une trace complète (mais seulement dans les logs, pas dans la réponse API affichée aux utilisateurs finaux).
Des modèles qui fonctionnent bien :
- Dites ce qui s'est passé en termes simples : « Nous n'avons pas pu enregistrer vos modifications. »
- Dites quoi faire ensuite : « Réessayez dans une minute » ou « Vérifiez les champs mis en surbrillance. »
- Évitez les reproches et le jargon : évitez « invalid payload » et « unauthorized ».
- Utilisez le même ton partout afin que les erreurs paraissent familières et non effrayantes.
Les codes d'erreur peuvent aider, mais traitez-les comme des identifiants de support, pas comme des énigmes. Si cela aide le support, affichez un code court et stable (par exemple « Error: AUTH-102 ») et conservez sa cohérence dans le temps.
Exemple : l'inscription échoue parce que la base de données a un timeout. Un message utilisateur sûr est : « Nous n'avons pas pu créer votre compte pour le moment. Veuillez réessayer. » Vos logs internes peuvent noter : « DB timeout on users_insert, requestId=... ».
Si vous avez hérité d'un backend généré par IA, cette séparation manque souvent. FixMyMess voit couramment des exceptions brutes renvoyées aux utilisateurs. L'une des premières corrections est de déplacer le détail technique dans les logs tout en gardant le message UI clair et cohérent.
Mapper les erreurs serveur vers des états UI (un tableau simple qui marche)
Les utilisateurs ne pensent pas en codes statut. Ils pensent en résultats : « Je peux corriger ça », « Je dois me reconnecter », ou « Quelque chose est en panne ». Choisissez un petit ensemble d'états UI et mappez chaque échec sur l'un d'eux.
Un mapping simple que vous pouvez réutiliser
Utilisez le même mapping sur le web, mobile et les outils admin pour que le comportement reste cohérent.
| Ce qui s'est passé | Code typique | État UI | Ce que l'UI doit faire |
|---|---|---|---|
| Requête incorrecte (votre appli a envoyé quelque chose de faux) | 400 | Fixable input | Sur-ligner le champ ou afficher un message clair. Ne pas proposer de réessai. |
| Non connecté / session expirée | 401 | Re-auth required | Envoyer vers la connexion, conserver le travail de l'utilisateur si possible. |
| Connecté mais pas autorisé | 403 | No permission | Expliquer que l'accès est bloqué, proposer « contacter l'admin » ou changer de compte. |
| Introuvable | 404 | Missing resource | Afficher « introuvable » et proposer une navigation de retour. |
| Conflit (déjà existe, mismatch de version) | 409 | Resolve conflict | Proposer un rafraîchissement, renommer, ou « réessayer » après synchronisation. |
| Validation échouée | 422 | Fixable input | Afficher des messages par champ et conserver l'état du formulaire. |
| Limite de débit | 429 | Wait and retry | Dire d'attendre, désactiver brièvement le bouton, puis réessayer. |
| Bug/indisponibilité serveur | 500 | Temporary failure | S'excuser, permettre le réessai, et afficher une option de support. |
Les échecs réseau et les timeouts sont à part des réponses serveur. Traitez-les comme « hors-ligne/connexion instable » : gardez l'utilisateur sur le même écran, affichez un bouton Réessayer, et évitez d'affirmer « votre mot de passe est incorrect » quand la requête n'a jamais abouti.
Une règle pratique : si l'utilisateur peut corriger, gardez-le dans le contexte (le formulaire reste rempli). S'il ne peut pas, passez à un état sûr (re-login, lecture seule, ou contact support).
Étape par étape : implémenter des erreurs cohérentes sans tout réécrire
Vous n'avez pas besoin de reconstruire toute votre API pour améliorer les erreurs. Ajoutez une fine couche cohérente autour de ce que vous avez déjà.
Commencez par choisir un petit ensemble de codes d'erreur que vous supporterez partout. Écrivez des définitions courtes et claires afin que les équipes backend et frontend les utilisent de la même façon.
Implémentez le changement en un seul endroit de chaque côté :
- Choisissez 8–15 codes d'erreur (comme
AUTH_REQUIRED,INVALID_INPUT,NOT_FOUND,RATE_LIMITED,CONFLICT,INTERNAL). Décrivez ce que chacun signifie et ce que l'utilisateur doit voir. - Ajoutez un formateur d'erreur côté serveur (middleware/filtre) qui renvoie la même forme JSON pour tous les endpoints, même quand l'exception est inattendue.
- Ajoutez un gestionnaire d'erreur côté client qui lit cette forme et la mappe sur vos états UI (erreur champ, bannière, toast, page d'erreur complète).
- Migrez progressivement : mettez à jour d'abord les flux les plus utilisés (connexion, inscription, checkout, sauvegarde). Laissez le reste pour plus tard.
- Verrouillez la forme avec quelques tests pour que des changements futurs ne cassent pas les clients.
Une approche de migration pratique est de supporter brièvement les deux formats : si un endpoint renvoie déjà du JSON d'erreur personnalisé, laissez-le passer. Sinon, enveloppez-le dans le nouveau format. Cela réduit le risque.
Exemple : corriger la connexion d'abord. Le serveur cesse de renvoyer des traces brutes et renvoie un code d'erreur stable avec un message sûr. Le client voit INVALID_CREDENTIALS et affiche un message inline près du champ mot de passe. S'il voit INTERNAL, il affiche une bannière générique et propose de réessayer.
Ceci est particulièrement utile dans les codebases générées par IA où chaque endpoint jette des erreurs différemment. Un formateur central et un mappeur central peuvent rendre l'application cohérente rapidement.
Flux courants et comment présenter les erreurs dans l'UI
Les gens n'expérimentent pas « une erreur API ». Ils vivent un formulaire qui ne se soumet pas, une session qui expire ou un paiement qui échoue. Si votre UI traite chaque échec de la même façon, les utilisateurs devinent, réessaient aveuglément ou partent.
Formulaires : la validation doit paraître locale
Quand le serveur dit qu'une saisie est invalide, affichez le message à côté du champ exact. Une bannière en haut « Quelque chose s'est mal passé » pousse l'utilisateur à scanner et retaper.
Bonnes pratiques :
- Sur-ligner le champ, conserver les valeurs saisies et mettre le focus sur le premier champ invalide.
- Utiliser un langage simple comme « Le mot de passe doit contenir au moins 12 caractères » plutôt que des codes.
- S'il y a aussi une erreur générale (par exemple « Email déjà utilisé »), l'afficher près du bouton de soumission.
Auth : être clair sur ce que l'utilisateur peut faire
Pour les sessions expirées, adoptez une règle unique et tenez-vous-y. Si vous pouvez rafraîchir en arrière-plan en toute sécurité, faites-le silencieusement une fois et continuez. Si vous ne le pouvez pas (rafraîchir échoue ou l'action est sensible), montrez une invite claire : « Veuillez vous reconnecter pour continuer. » Évitez de laisser l'utilisateur sur un écran d'erreur vide.
Les paiements et conflits demandent un soin supplémentaire. Dites ce qui s'est passé et quelle action est sûre : « Votre carte n'a pas été débitée. Veuillez réessayer. » Pour les conflits (quelqu'un d'autre a modifié les données), expliquez : « Cet élément a été mis à jour ailleurs. Rafraîchir pour voir la dernière version. »
Les uploads de fichiers doivent répondre à une question : qu'est-ce qui a réussi et qu'est-ce qui a échoué ? Affichez la progression, conservez la liste des fichiers réussis, et proposez un réessai simple pour les échoués. Si un réessai peut créer des duplicatas, dites-le avant que l'utilisateur clique.
Scénario d'exemple : un échec de connexion correctement traité
Un utilisateur ouvre votre appli après quelques jours et tente de se connecter. Son token de session sauvegardé est expiré, donc le serveur ne l'accepte plus. C'est normal, mais l'expérience dépend de la façon dont vous le signalez.
Voici une réponse simple qui suit les bonnes pratiques et reste sûre :
{
"error": {
"code": "AUTH_TOKEN_EXPIRED",
"message": "Your session expired. Please sign in again.",
"requestId": "req_7f3a1c9b2d"
}
}
Utilisez un statut HTTP clair (souvent 401 Unauthorized pour un token manquant ou expiré). Le code reste stable pour l'UI et le support. Le message est rédigé pour un humain et n'expose pas de détails comme quelle partie de l'auth a échoué ou quelle bibliothèque vous utilisez.
Côté UI, affichez une étape suivante calme : « Votre session a expiré. Connectez-vous à nouveau. » Ajoutez un bouton unique qui ramène à l'écran de connexion. N'affichez pas de traces, de JSON brut ou de mots effrayants comme « invalid signature ». Si l'utilisateur éditait quelque chose, conservez son travail en place et ne forcez la ré-auth que lors du nouvel envoi.
Pour le support, affichez un petit détail d'aide ou un bouton copier avec le requestId (ou le code d'erreur). Cela donne à votre équipe quelque chose d'actionnable : « Merci de partager le requestId req_7f3a1c9b2d », qu'ils pourront retrouver dans les logs.
Logging et monitoring qui correspondent à vos codes d'erreur
Si votre API renvoie un code d'erreur clair mais que vos logs ne le font pas, vous perdez le principal bénéfice. La règle la plus simple est de logger le même error.code que vous envoyez au client, à chaque fois.
Une bonne entrée de log est courte mais complète. Capturez assez pour déboguer sans déverser des données sensibles :
error.codeet le statut HTTP (ex :AUTH_INVALID_PASSWORD, 401)requestId(correlation ID) pour suivre une requête de bout en bout- contexte utilisateur sûr (userId, pas d'email ou de tokens)
- l'écran ou l'action (nom de route, endpoint, méthode)
- détails internes pour les développeurs (trace, erreur en amont), gardés côté serveur uniquement
Générez un requestId à la frontière (ou acceptez-en un venant du client) et renvoyez-le dans la réponse. Quand une erreur bloque un utilisateur, affichez un message court plus « Référence : X » afin que le support trouve le log exact rapidement.
Le monitoring consiste surtout à compter et regrouper, mais il doit correspondre au fonctionnement de l'UI. Suivez les erreurs par code et par écran pour repérer des tendances comme « PAYMENT_DECLINED apparaît surtout au checkout » ou « RATE_LIMITED a grimpé après une release ».
Décidez à l'avance sur quoi vous alerter pour éviter le bruit :
- pics soudains de 500 (erreurs serveur)
- échecs d'auth répétés (bug ou abus)
- augmentation des limites atteintes (capacité ou bug client)
- un code d'erreur dominant un endpoint ou un écran
Les équipes qui corrigent des backends générés par IA trouvent souvent des codes non assortis et des request IDs manquants. Nettoyer cela d'abord accélère toutes les corrections ultérieures.
Erreurs courantes et pièges à éviter
Beaucoup de mauvaises expériences viennent de petites incohérences. Même si chaque endpoint est « correct » pris isolément, le produit paraît aléatoire quand les erreurs sont désordonnées ou dangereuses.
Pièges fréquents :
- Retourner des formes d'erreur différentes selon les endpoints. Le frontend devient une accumulation de cas spéciaux (
messageici,errorlà,errors[0]ailleurs). - Utiliser le texte du message comme « code ». Ça marche jusqu'à ce que quelqu'un édite le wording pour la clarté, le ton ou la traduction, et alors la logique UI casse.
- Fuir des traces, bouts de SQL, IDs internes ou valeurs secrètes. Les utilisateurs ne peuvent rien en faire, et des attaquants si.
- Traiter chaque erreur comme un toast « Quelque chose s'est mal passé ». Si l'utilisateur peut corriger, dites-lui comment. S'il ne peut pas, dites-lui quoi faire ensuite.
- Retenter automatiquement des actions dangereuses. Retenter une lecture sûre est généralement OK. Retenter une écriture peut créer des doublons ou des doubles prélèvements.
Les équipes rencontrent souvent ces problèmes dans des backends générés par IA. Chez FixMyMess, nous voyons souvent des endpoints qui renvoient plusieurs formats et exposent accidentellement des secrets dans la sortie d'erreur.
Checklist rapide avant de déployer
Passez ceci juste avant une release. Cela attrape les petites lacunes qui se transforment en tickets mécontents.
Vérifications de sortie API
Confirmez que chaque endpoint parle la même « langue d'erreur ». Même si la cause diffère, la réponse doit être familière au client et facile à logger.
- Chaque endpoint renvoie-t-il la même forme d'erreur au top (par exemple :
error.code,error.message,requestId) ? - Les codes d'erreur sont-ils stables (ne changeront pas la semaine prochaine) et documentés en termes simples ?
- Y a-t-il toujours un message utilisateur sûr, plus un détail interne (dans les logs) quand il le faut ?
- Chaque erreur inclut-elle un
requestIdpour que le support retrouve rapidement la trace ?
Vérifications du comportement UI
Assurez-vous que l'appli réagit de manière cohérente. Les utilisateurs mémorisent des patterns.
- Le client mappe-t-il les erreurs serveur sur un petit ensemble d'états UI (validation, auth required, not found, conflict, retry later) ?
- Chaque message évite-t-il les détails internes (traces, SQL, noms de fournisseurs) et propose-t-il une étape claire ?
- Quand une erreur est actionnable, l'UI pointe-t-elle vers le champ ou l'étape à corriger ?
- Quand elle n'est pas actionnable (serveur down, timeout), l'UI indique-t-elle que c'est de votre côté et propose-t-elle un réessai ?
Si votre projet est un prototype généré par IA, ces basiques manquent souvent ou sont incohérents entre endpoints. FixMyMess peut auditer le code et aider à rendre la gestion des erreurs prévisible sans tout réécrire.
Prochaines étapes (et quand demander de l'aide pour corriger le code)
Choisissez un flux critique et faites-en votre « gold standard » d'abord. Connexion, checkout ou onboarding sont de bons choix car ils couvrent auth, validation et appels tiers.
Avant de changer quoi que ce soit, collectez environ 10 exemples réels d'erreurs depuis la production (ou depuis les logs et rapports de bugs). Réécrivez-les pour qu'ils correspondent à votre nouveau standard : mêmes champs, mêmes noms, même niveau de détail. Cela vous donne une cible claire et évite les débats sans fin.
Une approche pratique qui fonctionne souvent :
- Ajoutez un formateur côté serveur partagé qui transforme toute erreur lancée en votre forme standard.
- Ajoutez un mappeur côté client partagé qui transforme cette forme en états UI pris en charge (réessayer, corriger input, se reconnecter, contacter le support).
- Mettez à jour uniquement le flux choisi de bout en bout, avec des tests et quelques échecs simulés.
- Déployez le pattern endpoint par endpoint plutôt que d'essayer de tout corriger en une release.
- Gardez un petit ensemble de règles pour les messages (ce que les utilisateurs voient, ce qui reste interne).
Si votre appli a été générée par des outils comme Lovable, Bolt, v0, Cursor ou Replit, prévoyez du temps supplémentaire. Ces projets ont souvent des handlers incohérents entre routes, des middlewares dupliqués, et des objets d'erreur bruts fuyant vers le client. Le gain le plus rapide est généralement un formatage central et la suppression des réponses ad hoc.
Demandez de l'aide quand les erreurs sont liées à des problèmes plus profonds : flux d'auth brisés, secrets exposés, risques d'injection SQL, ou « ça marche en local mais pas en production ». FixMyMess (fixmymess.ai) se concentre sur le diagnostic et la réparation de codebases générées par IA, y compris la gestion des erreurs, le renforcement de la sécurité et la préparation au déploiement.
Si vous ne faites qu'une chose cette semaine, rendez un flux cohérent et mesurable. C'est ainsi que des erreurs plus claires se traduisent par moins de tickets support et des utilisateurs plus sereins.
Questions Fréquentes
What should every API error response include?
Un bon point de départ est un code d'erreur stable, un court message sûr pour l'utilisateur et un identifiant de requête. Le code permet à l'interface de réagir de manière cohérente, le message indique à l'utilisateur la prochaine étape, et l'identifiant de requête permet au support de retrouver l'entrée de log exacte.
Should I rely on HTTP status codes or custom error codes?
Conservez un sens pour les codes HTTP, mais ne vous fiez pas uniquement à eux. Utilisez le statut pour des catégories larges (auth, validation, erreur serveur) et votre propre error.code pour des cas spécifiques afin que l'interface n'ait pas à deviner.
How do I make errors feel consistent across the whole app?
Choisissez un petit ensemble d'états UI et mappez chaque code d'erreur sur l'un d'eux. Lorsque le même problème survient sur différents écrans, l'application doit réagir de la même manière, avec le même ton et la même prochaine étape.
How do I write error messages that users actually understand?
Expliquez ce qui s'est passé en langage clair, dites à l'utilisateur la prochaine étape, et rassurez-le si nécessaire (par exemple, s'il a été facturé ou non). Évitez le jargon comme « unauthorized » et n'accusez pas l'utilisateur.
What details should never appear in user-facing errors?
N'affichez pas de traces de pile, chemins de fichiers internes, SQL brut, secrets, tokens ou noms détaillés de services internes. Ces détails désorientent les utilisateurs et peuvent créer des risques de sécurité ; conservez-les dans les logs serveur liés à l'identifiant de requête.
What’s the best way to handle validation errors in forms?
Considérez la validation comme « needs action » et affichez les messages à côté des champs concernés. Conservez le formulaire rempli, faites le focus sur le premier champ invalide et évitez les bannières génériques qui forcent l'utilisateur à chercher quoi corriger.
How should my app handle expired sessions (401 errors)?
Pour les sessions expirées, affichez une invite claire pour se reconnecter et essayez de préserver le travail de l'utilisateur. Adoptez une règle unique partout afin que les utilisateurs sachent à quoi s'attendre, et n'affichez pas de texte technique effrayant comme des erreurs de signature ou de token.
How should I handle rate limits (429) and retries?
Dites par défaut à l'utilisateur d'attendre un instant puis d'essayer de nouveau, et envisagez un court refroidissement côté UI pour éviter les répétitions rapides. Ne proposez pas de retry pour des problèmes que l'utilisateur doit corriger (input invalide, permission manquante).
When is it safe to automatically retry a failed request?
Supposez que les retentatives peuvent créer des duplications pour des opérations en écriture, sauf si vous avez conçu l'idempotence. Si vous ne pouvez pas garantir la sécurité, ne relancez pas automatiquement ; proposez à l'utilisateur de relancer en expliquant ce qui se passera pour éviter les doubles soumissions ou facturations.
How can I improve error handling without rewriting my whole API?
Commencez par ajouter un formateur côté serveur qui impose à chaque endpoint la même forme d'erreur, puis un gestionnaire côté client qui mappe les codes sur les états UI. Si le backend est généré par IA et incohérent, FixMyMess peut auditer et corriger les exceptions fuitées, les flux d'auth brisés et les réponses instables afin que l'application devienne prévisible.