Carte des frontières de service : arrêter le couplage accidentel dans votre code
Créez une carte des frontières de service pour documenter domaines, propriété des données et dépendances afin que les équipes livrent sans couplage accidentel.
Pourquoi le couplage accidentel revient sans cesse
Le couplage accidentel, c’est quand des parties de votre application dépendent les unes des autres sans que personne ne l’ait voulu. Concrètement, ça donne des petits changements qui se transforment en pannes surprises, des rapports de bugs confus et des journées de release interminables.
Vous le voyez quand quelqu’un touche une fonctionnalité et que trois autres vacillent. Un ajustement des prix bloque les inscriptions. Une modification d’un modèle d’email casse les réinitialisations de mot de passe. Mettre à jour une règle de checkout fait planter le tableau de bord admin. Rien dans le code n’explique ces liens, donc on les découvre à la dure.
Une cause fréquente : du code partagé qui grossit parce que c’est pratique. Un module utilitaire, une table de base de données ou un service « commun » devient l’endroit où tout le monde ajoute « encore une chose ». Avec le temps, cet endroit partagé devient un nœud serré. Ce n’est pas que l’équipe est négligente : la base de code apprend silencieusement à tout le monde à coupler les choses.
Ça empire généralement quand plus de personnes touchent le code. Les nouveaux contributeurs ne connaissent pas les règles cachées, donc ils copient les patterns existants. Sous pression, ils prennent le chemin le plus court : réutiliser une fonction, lire des données dans une table déjà là, appeler un endpoint interne parce que ça marche. Chaque quick fix ajoute un fil invisible entre des parties du système.
Une propriété floue multiplie le problème. Quand personne ne peut dire « ce service possède les emails client » ou « ce module possède les règles de tarification », les revues deviennent de la spéculation. Les gens approuvent des changements qu’ils ne comprennent pas complètement, ou bloquent des releases par sécurité. Dans tous les cas, livrer devient risqué.
Quelques signes que vous vivez avec du couplage accidentel :
- Des bugs apparaissent loin du changement qui les a causés
- Les releases nécessitent beaucoup de tests manuels « pour être sûrs »
- Les équipes se disputent sur l’endroit où doit vivre une logique
- Vous évitez les refactorings parce que tout semble fragile
- Les correctifs nécessitent plusieurs reviewers car la propriété est floue
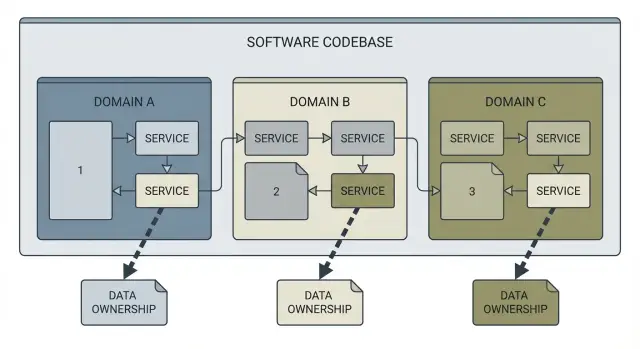
Qu’est-ce qu’une carte des frontières de service (en termes simples)
Une carte des frontières de service est une image simple de votre système qui répond à trois questions : quels sont les domaines (les grandes responsabilités), qui possède chaque donnée, et qui appelle quoi. Pensez-y comme un croquis étiqueté de la base de code, pas une muraille de diagrammes.
Une bonne carte inclut généralement les domaines principaux (comme Comptes, Facturation, Projets), les données que chaque domaine possède (tables, documents, entités clés), les dépendances entre domaines (appels API, événements, bibliothèques partagées) et les points d’intégration vers l’extérieur (paiements, email, stockage).
Ce que ce n’est pas : une réécriture complète de l’architecture ou un plan microservices parfait. Vous pouvez faire une carte pour un monolithe, un tas de fonctions serverless ou un prototype à moitié fini. L’objectif, c’est la clarté, pas « l’architecture idéale ».
La vraie valeur, ce sont les décisions qu’elle permet. Avec une carte, vous pouvez répondre à des questions comme :
- Où doit vivre cette nouvelle fonctionnalité ?
- Qui possède ces données ?
- Si on change ça, qu’est-ce qui casse ailleurs ?
- Qu’est-ce qu’on doit isoler en premier pour réduire le risque ?
C’est ainsi qu’on stoppe le couplage accidentel : on empêche le travail de traverser des frontières sans le remarquer.
Un exemple concret : quelqu’un demande « ajouter les invitations d’équipe ». Sans carte, une PR unique peut toucher l’authentification, les profils utilisateur, l’envoi d’emails et les vérifications de facturation, avec des écritures partagées partout. Avec une carte, on contient ça : les invitations appartiennent aux Comptes, les emails passent par un point d’intégration unique, et les règles de facturation restent la responsabilité de Facturation.
Ce n’est pas réservé aux ingénieurs. Les fondateurs l’utilisent pour comprendre pourquoi des « petits changements » prennent plus de temps que prévu. Les agences qui héritent d’une base de code en désordre s’en servent pour planifier sans empirer la situation.
Ce qu’il faut rassembler avant de commencer
Une carte des frontières vaut ce que valent les informations utilisées pour la construire. Avant de dessiner des boîtes et des flèches, collectez les faits de base pour cartographier la réalité, pas les opinions.
1) Définir la portée (pour que la carte reste utile)
Choisissez une portée qui correspond aux décisions que vous devez prendre ensuite. Si l’objectif est d’empêcher les nouvelles fonctionnalités de créer du couplage, vous n’avez pas toujours besoin de tout le système dès le premier jour.
Portées courantes :
- Un dépôt
- Une zone produit
- Le système entier
- Un flux à risque unique (auth, facturation, onboarding)
Écrivez la portée en une phrase. Ça fait raccourcir les débats.
2) Rassembler les éléments qui montrent comment le système tourne réellement
Cherchez toutes les façons dont le code est déclenché et tous les endroits où les données franchissent une frontière. Rassemblez :
- Points d’entrée : routes, endpoints, webhooks
- Travaux non liés aux requêtes : jobs en arrière-plan, files, tâches cron, planificateurs
- Intégrations tierces : paiements, email, analytics, stockage, fournisseurs d’auth
- Stockages de données : bases, caches, buckets (tables et entités au niveau élevé)
- « Colle » actuelle : bibliothèques partagées, config partagée, scripts admin partagés
Restez haut niveau. Vous n’avez pas besoin de chaque colonne de chaque table. Il faut juste assez pour voir la propriété et les collisions.
Format et limite de temps
Choisissez un format que l’équipe mettra à jour : photo d’un tableau blanc, doc avec titres, ou un outil de diagramme simple.
Limitez le temps pour que ça n’entraîne pas de glissement. Un bon départ : 60 à 90 minutes pour collecter les éléments, puis une session de suivi pour combler les lacunes.
Trouver les domaines et les vraies frontières
Commencez par ce que les utilisateurs peuvent faire, pas par l’apparence du repo. Une bonne carte commence souvent par des capacités que quelqu’un décrirait en langage courant : s’inscrire, se connecter, gérer la facturation, chercher, envoyer des messages, tâches admin. Ce sont des indices des vrais domaines.
Un test simple : si vous pouvez décrire une partie du système en une phrase sans mots techniques, c’est probablement un domaine. Si vous avez besoin de trois phrases et d’un diagramme, c’est peut‑être deux domaines collés ensemble.
Grouper par sens, pas par dossiers
Les noms de dossiers reflètent souvent l’histoire, pas l’intention. Scannez plutôt les noms et verbes métier dans le code, les tickets et les libellés de l’UI. Ensuite, groupez composants, routes, jobs et tables par ce qu’ils signifient.
Rédigez une phrase‑but stricte pour chaque domaine :
- « Comptes gère l’inscription, la connexion et les paramètres d’identité. »
- « Facturation gère les plans, les factures, les paiements et le statut d’abonnement. »
- « Messagerie gère les conversations, la livraison et le statut lu. »
Si vous vous surprenez à ajouter « et aussi », vous avez trouvé un problème de frontière.
Séparer les utilitaires partagés de la logique métier partagée
Partager un formateur de date, c’est acceptable. Partager les « règles d’abonnement » entre trois zones, c’est comme ça que le couplage se propage.
Un contrôle rapide quand vous voyez du code partagé :
- Les helpers purs (formatage, logging, client HTTP) peuvent être partagés.
- Les règles (qui peut rembourser, qu’est‑ce qui compte comme actif) doivent appartenir à un domaine.
- Si deux domaines ont besoin de la même règle, exposez‑la via une API ou un événement, pas un fichier partagé.
Marquez aussi les hotspots : parties qui changent chaque semaine, font échouer les tests ou déclenchent des PR « petites » qui touchent beaucoup de fichiers. Les hotspots signifient généralement des responsabilités mélangeées.
Documenter la propriété des données pour que les changements cessent de rentrer en collision
La plupart des problèmes de couplage commencent par une erreur simple : deux parties du système écrivent sur les mêmes données. C’est plus rapide au début, mais ça transforme chaque changement en négociation.
Commencez par choisir un domaine (Comptes, Facturation, Contenu) et nommez les données qu’il possède. Soyez précis. « Données utilisateur » est vague. « table users, table password_reset_tokens, fichiers profile_images » est assez clair pour que les gens s’y retrouvent.
Écrivez ensuite une règle et tenez‑y‑vous : le propriétaire écrit, tous les autres lisent via une frontière. Cette frontière peut être un appel API, un message/événement ou une vue en lecture seule contrôlée par le propriétaire. La technique compte moins que la discipline.
Un modèle simple pour chaque domaine :
- Données possédées (tables, collections, fichiers/buckets)
- Règle d’écriture (qui peut écrire et comment)
- Chemin de lecture (API, événement, vue de reporting, job d’export)
- Champs sensibles (PII, tokens d’auth, détails de paiement, secrets)
- Propriétaire clair (nom d’équipe ou rôle nommé)
Les tables partagées sont un point chaud de couplage. Si vous trouvez une table que « tout le monde utilise » (souvent users, subscriptions, permissions, audit_logs), ne l’acceptez pas comme normale. Marquez‑la comme partagée, nommez qui devient le vrai propriétaire et convenez d’un plan de transition. Parfois le plan consiste à « déplacer les écritures derrière une API d’abord, scinder la table ensuite. » Ça suffit souvent à arrêter l’accumulation de nouveau couplage.
Les données sensibles méritent une attention supplémentaire. Si des tokens d’auth, des hashes de mot de passe ou des informations de paiement sont stockés à plusieurs endroits, vous aurez des bugs de sécurité et des corrections compliquées. Un seul propriétaire doit contrôler le stockage et l’accès ; les autres domaines doivent demander ce dont ils ont besoin sans copier les secrets.
Cartographier les dépendances et les points d’intégration
Une fois les domaines identifiés, le prochain problème de couplage se cache souvent dans les connexions entre eux. Une carte n’aide que si elle montre comment le code parle réellement à l’autre code.
Commencez par les appels directs : routes HTTP, imports de modules internes qui traversent une frontière, clients SDK utilisés pour les paiements ou l’email, et bibliothèques partagées qui deviennent discrètement un « paquet dieu ».
Puis capturez aussi les appels indirects. Un flux d’inscription peut mettre en file un job, déclencher un webhook et lancer une tâche planifiée qui met à jour la facturation plus tard. Rien ne plante immédiatement, mais la dépendance est réelle.
Pour chaque point d’intégration, notez :
- Direction : qui dépend de qui
- Contrat : schéma de l’API, nom d’événement, payload du webhook, table/vue frontière
- Raccourcis : lectures directes en base, vars d’environnement partagées, middleware d’auth partagé
- Type de déclencheur : requête synchrone, job asynchrone, webhook, tâche planifiée
- Propriétaire : qui répare quand ça casse
Les contrats sont du couplage sain. Les raccourcis sont du couplage accidentel. « Il suffit d’importer le modèle user » ou « il suffit de lire cette table » marche jusqu’à la refactorisation qui casse tout.
Enfin, signalez les chaînes risquées. Cherchez les appels en étoile où une action touche beaucoup de services/modules et où les échecs se propagent. Exemple : une seule requête « Create Project » appelle auth, écrit dans deux bases, poste sur Slack, démarre un job d’onboarding et ping l’analytics. C’est difficile à tester et facile à casser.
Comment créer la carte pas à pas
Une carte des frontières n’aide que si elle reste simple. Dessinez la plus petite image qui empêche les gens d’introduire des changements qui lient silencieusement des parties du système.
Étape 1 : Dessinez les domaines en boîtes
Commencez avec une page blanche et dessinez 4 à 8 boîtes. Nommez chaque boîte comme les gens parlent du métier, pas comme le repo est organisé.
Sous chaque boîte, écrivez une phrase décrivant l’issue dont elle est responsable. Par exemple : « Facturation crée des factures et enregistre les paiements. » Si vous ne pouvez pas le dire en une phrase, la boîte est probablement trop grosse.
Étape 2 : Attachez les données possédées à chaque boîte
Pour chaque boîte, listez les données qu’elle possède en termes simples, courts et concrets : « Factures », « Moyens de paiement », « Profils utilisateur », « Projets », « Clés API. »
Les données possédées signifient que ce domaine est le seul autorisé à écrire dedans. Les autres ne lisent que via un chemin convenu (un appel, une vue, ou un événement exporté).
Étape 3 : Ajoutez des flèches pour les appels et les événements
Dessinez des flèches entre les boîtes pour chaque interaction connue : appels API, événements message, jobs en arrière‑plan, tâches planifiées, tout ce qui déplace des données.
Si vous travaillez sur un prototype généré par IA, ne faites pas confiance à la structure des dossiers. Trouvez les interactions réelles en scannant les appels HTTP internes, les accès directs à la base depuis le mauvais module, les jobs planifiés et les handlers de webhooks.
Étape 4 : Étiquetez chaque flèche par ce qui est échangé
Sur chaque flèche, écrivez ce qui est échangé, pas comment c’est codé. Bonnes étiquettes : « Créer facture », « Récupérer profil utilisateur », « Paiement réussi (événement) », « Synchroniser statut du projet. » Le sens doit rester stable même si le code change.
Étape 5 : Marquez les signaux d’alarme sur la carte
Marquez les patterns qui créent du couplage accidentel :
- Écritures partagées (deux domaines mettent à jour les mêmes données)
- Appels circulaires (A appelle B et B appelle A)
- Cron jobs cachés qui mettent à jour les données « par le côté »
- Une boîte qui sait tout (service dieu)
- Données copiées en plusieurs endroits sans source de vérité
Étape 6 : Écrivez 3 à 5 règles de frontière à respecter
Ajoutez une petite note à côté de la carte avec des règles mémorables :
- Seul le domaine propriétaire écrit ses données.
- Les lectures inter-domaines se font via une API définie ou une vue exportée, pas par accès direct à la base.
- Les événements décrivent des faits (« Paiement réussi »), pas des commandes (« Mettre à jour la facturation »).
- Pas de dépendances circulaires.
- Les tâches planifiées vivent dans le domaine qu’elles affectent et figurent sur la carte.
Exemple : transformer un prototype emmêlé en domaines clairs
Imaginez un prototype courant : inscription et login, page de profil utilisateur, écran de facturation et panneau admin. Ça marche pour les démos, mais chaque changement casse quelque chose d’autre.
Un problème racine fréquent : une seule table users surchargée que toutes les fonctionnalités touchent. Le code de login écrit dedans. Le panneau admin l’édite directement. La facturation y stocke le statut du plan. Les paramètres du profil y vivent aussi. Une simple demande « ajouter une colonne » devient une migration risquée qui affecte quatre parties de l’app, plus une collection de helpers partagés.
Une carte des frontières rend visible le couplage caché, puis le remplace par une propriété claire.
Ce que change la carte
Vous pouvez garder la même base de données au départ, mais arrêter de la traiter comme un seul seau partagé. Définissez quelques domaines et responsabilisez chacun pour ses données :
- Auth possède les identifiants et sessions (hashs de mots de passe, liens OAuth, refresh tokens).
- Profiles possède les paramètres visibles par l’utilisateur (nom d’affichage, préférences, choix de notification).
- Billing possède l’argent et les droits (clients, factures, historique des plans, statut de paiement).
- Admin possède la modération et les outils internes (flags, logs d’audit, affectations de rôles).
Puis rendez la règle explicite : les autres domaines n’écrivent pas dans des tables qu’ils ne possèdent pas. Si Billing a besoin de savoir « est-ce que cet utilisateur est actif ? », il interroge Auth ou lit une vue explicite d’entitlements contrôlée par Billing.
Remplacer les écritures directes en base par une frontière API basique
Dans le prototype emmêlé, la page de facturation pouvait mettre à jour directement users.plan = 'pro'. Après cartographie, Billing appelle quelque chose comme Billing.createSubscription(userId, planId) et met à jour ses propres enregistrements. Si Auth doit appliquer des contrôles d’accès, il interroge Billing via un point d’intégration petit et défini.
Pour éviter que le nouveau travail réintroduise du couplage, posez des attentes pour les demandes de fonctionnalités :
- Ajouter des champs uniquement dans le domaine propriétaire.
- Si vous avez besoin de données d’un autre domaine, ajoutez une API de lecture, pas une écriture partagée.
- Évitez « juste une colonne de plus sur users » à moins qu’Auth en soit vraiment propriétaire.
Erreurs courantes qui maintiennent le couplage
Le couplage accidentel n’apparaît généralement pas parce que les gens sont négligents. Il arrive parce que les équipes choisissent une frontière qui semble propre en surface, puis continuent de livrer sans vérifier si les frontières reflètent la réalité.
Un piège courant : prendre l’arborescence des dossiers comme modèle de domaine. Beaucoup de bases de code (surtout générées par IA) regroupent les fichiers selon les conventions du framework, pas selon le sens métier. Si votre carte reflète les dossiers actuels, vous risquez de documenter un désordre au lieu de trouver des coutures propres.
Un autre piège : aller trop petit trop tôt. Diviser en plein de petits services peut sembler être du progrès, mais si la propriété des données n’est pas réglée, vous créez plus d’appels, plus de modes de défaillance et plus de débats. Corrigez d’abord les frontières de données, puis décidez ce qui mérite un déploiement séparé.
Erreurs récurrentes :
- Utiliser les noms de paquet comme frontière, même quand une fonctionnalité touche trois « domaines »
- Scinder en nombreux services avant de s’accorder sur la propriété des données et des règles
- Laisser plusieurs domaines écrire indéfiniment dans la même table de base
- Cartographier seulement les API requête‑réponse et oublier jobs, cron, queues et webhooks
- Traiter la carte comme un artefact d’un atelier au lieu d’un document vivant
La cartographie des dépendances échoue aussi quand elle ignore les chemins discrets. Exemple : une page Billing appelle une API de paiements, mais un job nocturne met à jour les factures et un webhook marque les paiements comme réglés. Si ces chemins ne figurent pas sur la carte, les gens livrent des changements qui semblent sûrs dans l’UI mais cassent la compta le lendemain matin.
Checklist rapide et prochaines étapes
Utilisez ceci comme contrôle après avoir ébauché votre carte. Si vous ne pouvez pas répondre à une de ces questions en une phrase, c’est généralement là que le couplage accidentel se cache.
Checklist rapide
- Chaque jeu de données a un propriétaire clair, et les autres le lisent via une interface convenue
- Il n’y a pas de dépendances circulaires entre services ou modules
- Les contrats sont écrits (même sous forme de note courte) : ce qu’un appel attend, ce qu’il retourne, ce que signifient les erreurs
- Les points d’intégration sont visibles : queues, webhooks, cron jobs, bibliothèques partagées, accès direct à la base
- L’impact des changements est prévisible : vous pouvez nommer ce qui doit changer quand un champ ou une règle évolue
Une façon simple de garder la carte utile : traitez‑la comme du code. Quand quelqu’un ajoute une dépendance, une table ou une intégration, il met à jour la carte dans la même PR. Si ça semble lourd, restez léger : une capture d’écran ou un court paragraphe suffit souvent.
Prochaines étapes qui réduisent réellement le couplage
Choisissez une cible de refactorisation basée sur le risque, pas sur la convenance. La meilleure première cible est souvent l’endroit où un petit changement provoque des pannes, des problèmes de sécurité ou des révisions répétées.
- Choisissez le point de couplage le plus à risque (tables partagées, logique d’auth utilisée partout, ou un service dieu)
- Écrivez une règle de frontière que vous ferez respecter la semaine suivante (par exemple : « aucun service n’écrit dans les tables d’un autre service »)
- Ajoutez une petite vérification de frontière pour faire apparaître les cassures tôt (test de contrat, validation de schéma, ou un simple garde)
Si votre base de code a été générée par des outils IA et s’est vite enchevêtrée, les frontières sur le papier ne correspondent souvent pas au comportement réel du code. Si vous voulez un second avis, FixMyMess (fixmymess.ai) propose un audit de code gratuit et peut aider à identifier les dépendances cachées, les conflits de propriété des données et les problèmes de sécurité avant d’engager une grosse refonte.
Questions Fréquentes
À quoi ressemble le couplage accidentel dans une vraie application ?
Le couplage accidentel, c’est lorsque deux parties de votre application dépendent l’une de l’autre de manière non planifiée et non documentée. Le résultat : un « petit » changement dans une zone provoque des bugs ou des pannes ailleurs, et la connexion n’est pas évidente depuis le code ou le design.
Pourquoi le code partagé devient-il un point chaud de couplage ?
Ça attire de la logique non liée : tout le monde ajoute « juste une chose de plus » parce que c’est déjà là et que ça marche. Avec le temps, cet endroit partagé se transforme en un nœud où beaucoup de fonctionnalités s’appuient sur les mêmes fonctions, tables ou configurations, et le modifier en toute sécurité devient lent et risqué.
Comment décider quels sont les « domaines » pour la carte ?
Commencez par ce que font les utilisateurs et les résultats attendus, pas par la structure des dossiers. Si vous pouvez décrire une zone en une phrase simple sans termes techniques, c’est généralement un bon candidat pour un domaine ; si vous ajoutez sans cesse « et aussi », c’est probablement deux domaines collés l’un à l’autre.
Quelle taille doit avoir la première carte de frontières de service ?
Écrivez la portée en une phrase et gardez-la assez petite pour être terminée en une séance de travail. Un bon choix par défaut est un dépôt unique ou un flux à haut risque comme l’auth, la facturation ou l’onboarding, car ce sont souvent les zones où les dépendances cachées causent le plus de dégâts.
Que signifie « propriété des données » et pourquoi est-ce si important ?
Les données possédées sont celles qu’un domaine est autorisé à écrire ; les autres doivent les lire via une frontière convenue. Une règle simple par défaut : « le propriétaire écrit ; les autres demandent », via une API interne, un événement ou une vue en lecture seule. C’est la discipline qui compte plus que la technologie exacte.
Que faire si plusieurs parties de l’application écrivent dans la même table ?
Quand plusieurs domaines écrivent dans la même table ou le même document, chaque changement devient une négociation et les migrations deviennent effrayantes. Choisissez un propriétaire unique pour ce jeu de données et faites passer les nouvelles écritures derrière la frontière de ce propriétaire en premier ; vous pourrez scinder la table plus tard une fois la situation stabilisée.
Quelles dépendances les équipes oublient-elles généralement de cartographier ?
Incluez tous les chemins non liés aux requêtes : jobs en arrière-plan, tâches planifiées, files d’attente et handlers de webhooks. Ce sont des sources courantes de « ça marchait dans l’UI » qui cassent plus tard, car ils modifient les données ensuite ou par côté, souvent en contournant les mêmes vérifications que les handlers de requêtes.
Comment distinguer une dépendance saine d’un raccourci risqué ?
Un contrat sain est une interaction clairement définie comme « créer une facture » ou « paiement réussi », avec un propriétaire connu et des entrées/sorties attendues. Un raccourci est tout ce qui contourne la frontière, comme des lectures directes de la base de données d’un autre domaine ou l’import de modèles internes entre domaines, car cela lie les équipes en silence.
Quelles règles de frontière vaut-il la peine d’écrire à côté de la carte ?
Restez court et actionnable, généralement trois à cinq règles faciles à retenir pendant les revues. Les trois plus utiles : seul le domaine propriétaire écrit ses données, les lectures inter-domaines passent par une interface définie, et pas de dépendances circulaires — ces trois règles évitent la plupart des nouveaux couplages.
Comment empêcher la carte de devenir obsolète après l’atelier initial ?
Mettez-la à jour chaque fois que vous ajoutez une nouvelle dépendance, une nouvelle table ou une nouvelle intégration, comme vous mettez à jour du code quand le comportement change. Si le code a été généré par IA ou semble fragile, un audit externe peut rapidement révéler les couplages cachés et les problèmes de sécurité ; FixMyMess peut analyser le dépôt et identifier les conflits de propriété et les chaînes de dépendances risquées avant d’engager une grosse refonte.