Checklist de parité pour la préproduction : prévoir les problèmes en production
Utilisez cette checklist de parité pour la préproduction afin d'aligner auth, webhooks, stockage, cron et flags et faire en sorte que les échecs en préproduction reflètent ceux de la production avant la release.
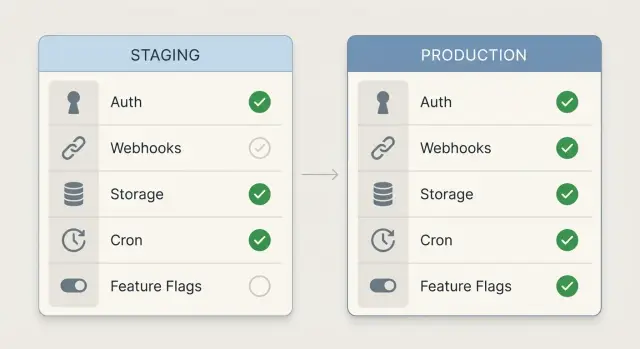
Pourquoi la préproduction ne prédit pas la production par défaut
La parité est simple : la préproduction doit se comporter comme la production sur les points qui peuvent casser une release. Si la même requête, action utilisateur ou tâche en arrière-plan s'exécute en préproduction, elle doit échouer ou réussir pour les mêmes raisons que en production.
La préproduction « passe » quand vous testez accidentellement un monde différent. Peut‑être que la préproduction utilise une application OAuth différente, des paramètres de cookie assouplis, des émetteurs de webhooks factices, un bucket de stockage ouvert, ou des jobs en arrière-plan qui ne tournent jamais. Tout semble correct jusqu'à ce que le trafic réel atteigne des services réels avec de vraies règles.
Les échecs en production qui passent la préproduction proviennent souvent de quelques coupables récurrents : différences de domaine et de redirection (callbacks OAuth), signatures et stratégies de retry des webhooks, permissions et dérive de CORS sur le stockage, workers désactivés, et feature flags qui ne correspondent pas.
Parité ne signifie pas copier les données de production en préproduction. Vous pouvez garder la préproduction sûre en utilisant des utilisateurs de test, des paiements factices et des enregistrements échantillons nettoyés. L'objectif est d'aligner la configuration et le comportement, pas d'exposer des informations clients.
Un exemple courant : une équipe teste la connexion en préproduction avec une application OAuth qui accepte n'importe quelle URL de redirection. La production est stricte, donc le même flux de connexion échoue pour les vrais utilisateurs.
Commencez par les bases : versions, configs et domaines
La plupart des surprises en préproduction ont une raison ennuyeuse : vous ne lancez pas la même application.
D'abord, confirmez que la version déployée et les paramètres de build correspondent. Les équipes testent souvent un commit récent en préproduction alors que la production tourne encore sur la version de la semaine précédente, ou elles publient avec des flags de build différents qui changent le comportement (mode debug, choix de la base API, minification).
Traitez les variables d'environnement de la même manière. Vous n'avez pas besoin des mêmes valeurs secrètes, mais vous avez besoin des mêmes noms et formats. Un nom réservé à la préproduction comme STRIPE_KEY_TEST peut masquer l'absence de STRIPE_SECRET_KEY jusqu'au jour de la release.
Les domaines créent une autre division silencieuse. Si la production est sur app.example.com et la préproduction sur un hôte aléatoire, les redirections et les cookies peuvent se comporter différemment, surtout avec HTTPS et des règles de sécurité strictes. Vérifiez que les redirections, le TLS et les URL de callback pointent vers le bon domaine pour chaque environnement, avec les mêmes règles.
Enfin, vérifiez les différences d'exécution qui changent les résultats sans modifier le code : versions Node/Python, images OS de base, versions de base de données et paramètres de région. Ceux‑ci peuvent affecter la gestion des dates, les chemins de fichiers et la latence.
Un contrôle « bases » rapide :
- Même commit git (ou tag de release) et même commande de build
- Même clés de variables d'environnement et mêmes types (string vs JSON), les valeurs peuvent différer
- Même patterns de domaine, même comportement HTTPS et mêmes règles de redirection
- Même versions runtime et même image de conteneur
- Même paramètres régionaux (fuseau horaire, locale) là où c'est important
Parité d'authentification : fournisseurs, redirections, cookies et sessions
L'authentification est l'endroit où « ça marche en préproduction » échoue le plus souvent. Considérez la connexion comme un système complet, pas comme un bouton qui ouvre une popup.
Alignez les fournisseurs d'identité que vous supportez. Si la préproduction n'a que Google d'activé mais que la production a aussi GitHub ou Auth0, vous ne testez pas la vraie application. Les différences de fournisseur modifient les champs de profil, le comportement de vérification d'email et les règles de rafraîchissement de token.
Comparez ensuite les réglages OAuth un par un. Les URI de redirection et les origines autorisées doivent correspondre exactement, y compris le protocole et le sous-domaine. Échecs fréquents :
- La préproduction autorise
http://localhostmais la production exige HTTPS - Un mismatch www vs non‑www bloque le callback
- Le fournisseur a encore d'anciennes URI de redirection enregistrées depuis un précédent domaine de préproduction
Les cookies et les sessions ont aussi besoin des mêmes paramètres de sécurité. De petits flags changent tout : Secure, HttpOnly, SameSite, domaine du cookie et durée de session. Si la préproduction est en HTTP non sécurisé ou sous un domaine de premier niveau différent, le comportement des cookies peut sembler « correct » alors que la production casse la connexion après login.
Avant une release, exécutez une vérification d'auth qui ressemble à un usage réel :
- Connectez‑vous avec chaque fournisseur que vous supportez, puis rafraîchissez la page et confirmez que la session persiste
- Complétez le reset de mot de passe et la vérification d'email de bout en bout (y compris le lien dans l'email)
- Testez en fenêtre incognito et sur mobile Safari (les règles de cookie diffèrent)
- Confirmez que la déconnexion efface la session et les tokens, pas seulement l'état de l'UI
- Déclenchez des limites de taux avec des tentatives répétées et vérifiez que l'erreur est gérée
N'oubliez pas les protections propres à la production : blocages d'IP, règles WAF, détection de bots et limites de taux fournisseurs. La préproduction ne vous alertera pas à leur sujet à moins que vous ne les testiez.
Parité des webhooks : endpoints, signatures et retries
Les webhooks sont un autre endroit où la préproduction peut « mentir ». En préproduction, le fournisseur peut pointer vers la mauvaise URL, utiliser un secret différent, ou envoyer un ensemble d'événements différent de la production. Ensuite, paiements, inscriptions ou notifications échouent pour de vrais utilisateurs.
Commencez par lister chaque émetteur de webhook et les événements exacts dont votre app dépend (Stripe, GitHub, Slack, Zapier, services internes). Tirezz ces informations depuis les dashboards fournisseurs et le code, pas de mémoire.
Assurez‑vous que chaque fournisseur a l'endpoint de préproduction enregistré et actif. Une erreur courante : « URL de préproduction ajoutée », mais l'ancien endpoint est toujours sélectionné, désactivé, ou configuré pour un autre ensemble d'événements.
Traitez les signatures comme un contrat strict. La préproduction doit vérifier les signatures de la même façon que la production : même nom d'en‑tête, même algorithme de hachage, même gestion du corps brut. Beaucoup de frameworks cassent la vérification s'ils parsent le JSON avant de vérifier. Si la préproduction saute la vérification « pour aller plus vite », vous testez une application différente.
Un contrôle pratique des webhooks :
- Rejouez une vraie charge utile de production (avec données sensibles supprimées) en préproduction et comparez le statut HTTP et le temps de réponse
- Confirmez que le secret de signature en préproduction correspond à celui que le fournisseur utilise pour l'endpoint de préproduction
- Forcez une erreur (retour 500) et confirmez que le fournisseur retente comme prévu
- Vérifiez l'idempotence : le même événement reçu deux fois ne doit pas facturer, créer ou envoyer deux fois
- Enregistrez un ID de requête stable pour tracer les duplications entre les retries
Exemple : Stripe retente un webhook payment_succeeded après un timeout. L'app crée deux commandes parce que le handler n'a pas d'idempotence. Le correctif dans le code est souvent petit, mais l'impact en production est important.
Parité du stockage : permissions, CORS et workflows de fichiers
Si votre app manipule des fichiers, le stockage est un endroit facile où la préproduction peut vous induire en erreur. Un build qui fonctionne avec le disque local et des permissions larges peut échouer dès qu'il atteint un bucket réel avec des règles plus strictes.
Alignez le type de stockage et le modèle d'accès. Si la production utilise S3 ou GCS avec des objets privés, la préproduction devrait en faire autant. Les différences de policy de bucket, de rôles IAM ou d'accès public se traduisent souvent par des 403 « aléatoires » qui ressemblent à des bugs applicatifs.
Le CORS est le piège suivant. Un upload qui marche dans un environnement peut échouer dans l'autre si les origines autorisées, en‑têtes ou méthodes diffèrent. Vérifiez que les deux environnements autorisent les mêmes domaines et le même flux d'upload (direct vers le bucket vs via votre API).
Testez aussi le workflow, pas seulement les permissions. Utilisez des tailles et types de fichiers réels, pas de petites images démo. Beaucoup d'échecs viennent de la gestion des types MIME, des limites serveur ou de règles de stockage qui rejettent certaines extensions.
Un contrôle stockage rapide :
- Téléversez un fichier volumineux et confirmez que l'UI gère la progression et les timeouts
- Téléchargez‑le depuis le chemin UI que les utilisateurs utiliseront (pas un raccourci dev)
- Supprimez‑le et confirmez que l'enregistrement et l'objet sont tous deux supprimés
- Générez un lien expiré et vérifiez qu'il expire au bon moment
- Lancez tout traitement (miniatures, OCR, scan antivirus) de bout en bout
Cron et jobs en arrière‑plan : planning, runners et alertes
Le travail programmé échoue souvent silencieusement. Un parcours de checkout peut sembler correct dans le navigateur, mais si le job de facture nocturne, la tâche de nettoyage ou l'envoi d'emails se comporte différemment, la production casse plus tard et ça semble aléatoire.
Dressez la liste de chaque job planifié et ce qui le déclenche : cron schedules, workers de queue, et timers « run every X minutes » dans l'app. Si un job existe en production mais pas en préproduction, la préproduction ne peut pas prédire l'échec.
Les paramètres temporels sont un piège classique. Alignez fuseau horaire, comportement DST et ce que « minuit » signifie. Un job qui tourne à 00:05 en production peut s'exécuter à une autre heure locale en préproduction, touchant ainsi des données différentes et créant des cas limites.
Confirmez que le runner de job est bien activé en préproduction. Beaucoup d'équipes déploient l'app web mais oublient d'activer le scheduler, le dyno worker ou le conteneur. Le résultat est un succès silencieux : pas d'erreurs, parce que rien n'a tourné.
Avant une release :
- Listez chaque job, son planning et le fuseau horaire utilisé
- Confirmez que le processus scheduler/worker est activé et a les mêmes vars d'environnement
- Lancez manuellement les jobs clés en préproduction avec un volume de données proche de la production
- Cassez volontairement un job pour confirmer que retries, backoff et alertes fonctionnent
- Vérifiez les dépendances externes : queues, email/SMS, APIs de paiement et limites de taux
Feature flags : mêmes valeurs par défaut, règles et comportements de secours
Les feature flags sont utiles jusqu'à ce que la préproduction et la production ne soient pas d'accord sur ce qui est « activé ». Traitez les flags comme du code : même source, mêmes règles et même comportement en cas d'échec.
Inventoriez chaque flag que votre app lit et sa valeur par défaut prévue. Les équipes changent souvent les valeurs par défaut en préproduction pour des démos, puis oublient. C'est ainsi qu'une release « sûre » se transforme en lancement surprise.
Comparez la façon dont les flags sont évalués : ciblage utilisateur, ciblage organisation, rollouts en pourcentage, et « activé seulement pour les emails internes ». Un petit ensemble d'utilisateurs en préproduction peut contourner des chemins de règles importants.
Vérifiez aussi la plomberie : la préproduction doit utiliser le même service de flags et la même version du SDK que la production. Des versions différentes peuvent changer le cache, l'ordre d'évaluation et la façon dont les utilisateurs anonymes sont traités.
Un bon contrôle de flags :
- Comparez les états et valeurs par défaut actuels des flags dans les deux environnements
- Comparez les règles de ciblage (utilisateurs, orgs, segments, rollouts en pourcentage)
- Confirmez que le même fournisseur et la même version du SDK sont déployés
- Simulez une panne (bloquez le service de flags) et vérifiez que l'app se comporte de manière sûre
- Recherchez dans le code les overrides du type « if staging then… » codés en dur
Décidez du comportement de secours volontairement. Pour les paiements, l'auth ou les outils admin, laisser « open » (feature activée) peut être risqué.
Comment exécuter une vérification de parité pas à pas
Les vérifications de parité fonctionnent mieux quand la préproduction est une répétition générale, pas une supposition.
Choisissez un parcours utilisateur critique qui touche le plus de systèmes. Pour beaucoup d'apps, c'est : inscription, vérification d'email, upgrade, puis déconnexion et reconnexion.
Exécutez‑le en préproduction avec des comptes frais et de vrais navigateurs. Au fur et à mesure, notez chaque appel externe observable : auth, paiements, email, stockage, webhooks, analytics, feature flags. Confirmez que chaque dépendance a un équivalent en préproduction (ou un sandbox sûr) avec des réglages correspondants, pas « à peu près pareil ».
Après le parcours, capturez quelques éléments pendant qu'ils sont frais : quel fournisseur d'auth a été utilisé, quelles URL de redirection ont été appelées, si les vérifications de signature des webhooks ont tourné, et quels jobs en arrière‑plan se sont lancés ensuite.
Une victoire typique de parité : l'inscription en préproduction marche, mais l'« upgrade » ne débloque jamais de fonctionnalités. Les notes révèlent que le webhook de paiement pointe vers un ancien endpoint de préproduction, donc l'événement n'arrive jamais dans l'app.
Erreurs de parité courantes qui entraînent des rollbacks la nuit
La plupart des rollbacks commencent par un petit décalage qui semblait inoffensif en préproduction.
Les échecs d'authentification sont souvent « presque les mêmes » : une app OAuth différente, des URI de redirection manquantes, des domaines de cookies qui ne correspondent pas, ou un chemin de callback qui diffère d'un caractère. Tout fonctionne en local, la préproduction semble ok, puis la production échoue avec une boucle de redirection ou une session qui ne tient pas.
Les webhooks provoquent un autre type de dégâts. La préproduction pointe parfois par erreur vers la production, envoyant des événements de test dans de vraies données. Même quand les endpoints sont corrects, les secrets de signature ou les réglages de retry peuvent différer, donc la production se comporte plus agressivement que la préproduction.
Les secrets sont un autre classique de la nuit de release. Une clé prototype pratique finit dans le code client, dans la sortie de build ou dans les logs. Quand le trafic augmente, ces logs se propagent et le rayon d'impact s'agrandit.
Cinq erreurs qui passent les revues :
- Redirections d'auth et réglages de cookie qui diffèrent d'un domaine ou d'un protocole
- La préproduction touche par accident les webhooks, queues ou bases de données de production
- Des valeurs secrètes sont imprimées dans les logs ou intégrées dans le frontend
- Les cron et jobs en arrière‑plan sont désactivés en préproduction, donc les bugs temporels n'apparaissent jamais
- Les valeurs par défaut ou les règles de ciblage des feature flags diffèrent silencieusement entre environnements
Checklist rapide de parité à copier dans une note de release
Contrôles de parité avant release (préproduction correspond à la production) :
- Build + runtime identiques : mêmes versions runtime, même mode de build, mêmes clés d'env présentes (valeurs différentes autorisées), et même pattern de domaine/sous‑domaine.
- Flux de connexion vérifiés de bout en bout : URI de redirection/callback enregistrées, réglages de cookie équivalents (Secure, SameSite, domaine), sessions qui survivent aux rafraîchissements, et reset de mot de passe ou magic‑link qui se complètent.
- Webhooks comme en production : le fournisseur pointe vers le bon endpoint de préproduction, la vérification de signature est active, les retries ne créent pas de doublons, et les livraisons échouées sont visibles.
- Stockage de fichiers sous vraies règles : limites d'upload identiques, permissions correspondantes (public vs privé), CORS autorisant l'origine frontend exacte, et liens de téléchargement qui se comportent pareil.
- Travail en arrière‑plan prévisible : plannings identiques, fuseau horaire confirmé, workers activés, échecs qui alertent quelqu'un, et flags avec mêmes valeurs/règles et fallback sûr.
Un exemple réaliste : la release qui a cassé dès le jour 1
Un fondateur publie un prototype SaaS généré par IA (construit dans Cursor et Replit) qui semblait parfait en préproduction. Le matin du lancement, les inscriptions montent en flèche, puis arrive le premier message du support : « Je n'arrive pas à me connecter. »
La connexion marchait tout le temps en préproduction, mais les utilisateurs en production étaient renvoyés vers la page d'accueil après le callback OAuth. Le bug était simple : la production utilisait un domaine différent, mais le fournisseur d'auth avait encore l'ancienne URI de redirection enregistrée depuis la préproduction. Pour empirer les choses, les cookies production avaient une règle SameSite plus stricte, donc les sessions ne tenaient pas après la redirection.
Pendant que l'équipe panique, un deuxième problème apparaît. Les paiements sont « réussis », mais personne n'obtient l'accès. Le fournisseur de paiement envoie des webhooks, mais l'app ne les traite pas parce que l'endpoint de webhook de production n'avait jamais été enregistré. Les tests en préproduction avaient passé car l'équipe utilisait un toggle manuel « marquer payé » au lieu de vrais événements webhook.
Ensuite, les uploads de fichiers cassent uniquement pour les vrais clients. En préproduction, les uploads allaient dans un bucket permissif avec des règles CORS larges. En production, le rôle de stockage n'avait pas la permission d'écrire, et les origines autorisées n'incluaient pas le domaine live, donc les navigateurs bloquaient la requête d'upload.
Une répétition rapide de parité aurait attrapé les trois problèmes en forçant la vérification des intégrations exactes : URI de redirection et comportement des cookies, enregistrement et vérification des signatures des webhooks, et permissions de bucket + CORS.
Prochaines étapes pour garder préproduction et production synchrones
La parité est plus facile à maintenir quand vous la documentez, automatisez un petit contrôle et désignez quelqu'un responsable de corriger les dérives.
Gardez une source unique de vérité pour les variables d'environnement et les intégrations. Un tableau simple suffit : nom, objectif, où c'est défini, et à quoi ressemble un état « valide » en préproduction vs production.
Ajoutez un smoke test répétable qui s'exécute à chaque release : se connecter, déclencher un webhook, uploader un fichier, et confirmer qu'un job en arrière‑plan s'est exécuté. Si l'un de ces tests échoue en préproduction, arrêtez et corrigez avant d'apprendre la leçon en production.
Une manière pratique de décider ce qui doit être réel vs sandbox en préproduction :
- Auth : fournisseur réel, app/client séparé, domaine de callback de préproduction
- Paiements/email/SMS : sandbox quand possible, avec comptes de test clairs
- Webhooks : signature et comportement de retry réels, pointant vers des endpoints de préproduction
- Stockage : règles de bucket et CORS réels, mais un bucket de préproduction
- Cron/jobs : plannings réels, mais données et destinataires sûrs
Si vous avez hérité d'une base de code générée par IA et que la parité casse sans cesse, le problème est souvent plus profond qu'un réglage manquant : URLs codées en dur, secrets exposés, handlers de webhooks fragiles, ou workers jamais câblés correctement. FixMyMess (fixmymess.ai) aide les équipes à transformer des prototypes générés par IA en logiciels prêts pour la production en diagnostiquant et corrigeant des problèmes comme des mauvaises configurations d'auth, la fiabilité des webhooks et des valeurs par défaut non sécurisées.