Compteurs fiables sous concurrence : empêchez la dérive des métriques
Apprenez à garder des compteurs fiables sous concurrence grâce aux mises à jour atomiques, aux clés d'idempotence et aux écritures par lots pour que les métriques restent exactes en production.
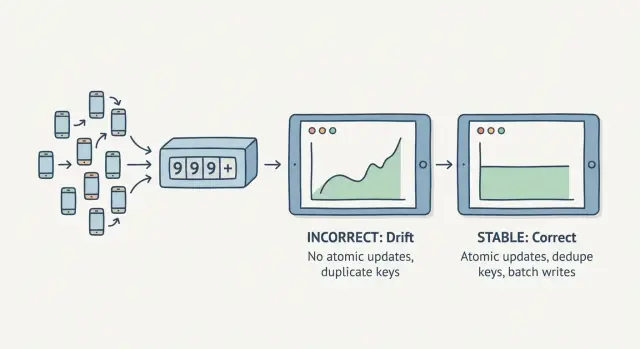
Pourquoi les compteurs dérivent quand le trafic arrive en même temps
Un compteur dérive quand vous ne pouvez pas lui faire confiance pour rester cohérent. Vous actualisez un tableau de bord et le total change alors que rien de nouveau ne s'est produit. Ou le nombre bondit après un pic court. C'est difficile à attraper en test parce que ça demande généralement une vraie concurrence.
La dérive ressemble souvent à ceci :
- Le même rapport affiche des totaux différents à chaque actualisation.
- Les comptes sautent après une rafale de trafic ou un déploiement.
- Les totaux d'un endroit (base de données) ne correspondent pas à un autre (analytics).
La cause habituelle est une condition de course : de nombreuses requêtes essaient de mettre à jour le même nombre en même temps. Si votre code fait « lire la valeur actuelle, ajouter 1, réécrire », deux requêtes peuvent toutes deux lire 10, ajouter 1 et écrire 11. Un incrément disparaît.
C'est pourquoi ça apparaît souvent seulement après le lancement. Sur un portable ou en staging calme, les requêtes arrivent une par une. Après une campagne, une fonctionnalité populaire ou des jobs en arrière-plan s'exécutant en parallèle, ces mises à jour se percutent.
Il y a aussi un arbitrage entre exactitude et fraîcheur. Mettre à jour un compteur à chaque requête peut être précis, mais uniquement si la mise à jour est vraiment sûre en concurrence. Beaucoup d'équipes choisissent la quasi-temps réel : collecter les événements rapidement, puis mettre à jour les totaux en petits lots toutes les quelques secondes. Le nombre est un peu retardé, mais il est généralement plus stable et plus simple à rendre correct.
Un exemple simple : deux utilisateurs cliquent sur « Acheter » à la même seconde. Si les deux requêtes calculent et écrivent le nouveau total séparément, votre compteur d'achats peut sous-dénommer même si les deux commandes ont réussi.
Choisir le bon type de métrique avant de coder
Beaucoup de « problèmes de compteurs » sont en réalité des « problèmes de définition ». Si vous choisissez le mauvais type de métrique, corriger l'incrément ne stabilisera pas vos analytics.
Quand quelqu'un dit qu'il veut « un compteur », il veut généralement l'un de ceux-ci :
- Compteur : combien de fois quelque chose s'est produit (vues de page, clics sur un bouton)
- Somme : montant total sur les événements (revenu, minutes regardées)
- Comptage unique : combien d'utilisateurs/objets distincts ont fait quelque chose (inscriptions uniques, acheteurs uniques)
- Taux : un ratio dans le temps (inscriptions par heure, taux de conversion)
Un +1 simple suffit souvent pour des événements peu sensibles et à fort volume comme les vues de page. Un peu de bruit dû aux doublons importe peu.
Mais dès que de l'argent, l'état utilisateur ou la messagerie est impliqué, vous avez besoin d'une définition plus stricte de la « vérité ». Inscriptions, achats, emails de réinitialisation de mot de passe, invitations et événements « essai démarré » sont plus souvent réessayés qu'on ne le croit (clients, jobs en arrière-plan, fournisseurs de paiement). Compter les retries comme de nouveaux événements est la façon dont les tableaux de bord gonflent.
Une façon pratique de décider est de choisir votre source de vérité :
- Événements append-only : stocker chaque événement une fois, puis calculer les totaux à partir des événements.
- Totaux stockés : garder un nombre courant et le mettre à jour quand les événements arrivent.
Les logs d'événements sont plus faciles à auditer et à recalculer. Les totaux stockés sont plus rapides à lire, mais ne fonctionnent que si les mises à jour sont correctes et les doublons bloqués.
Exemple : un checkout reçoit payment_succeeded deux fois parce que la première réponse au webhook a expiré. Si votre métrique « achats » est un simple compteur, elle augmente de 2. Si votre vérité est « un achat par payment_id », vous mesurez les IDs de paiement uniques, pas les livraisons brutes de webhooks.
Mises à jour atomiques : la façon la plus sûre d'incrémenter
Quand vous avez besoin de compteurs fiables sous concurrence, utilisez des mises à jour atomiques. « Atomique » signifie que le changement se produit en une seule opération : il s'applique une fois, ou pas du tout. Pas d'état partiel, pas de deux requêtes qui s'écrasent mutuellement.
Le bug classique est lire-modifier-écrire : lire 100, ajouter 1 dans le code applicatif, écrire 101. Deux requêtes peuvent toutes deux lire 100 et écrire 101.
Les mises à jour atomiques font l'incrément à l'intérieur de la base ou du store, où il peut être appliqué en toute sécurité même quand beaucoup de requêtes arrivent à la fois :
UPDATE counters
SET value = value + 1
WHERE name = 'signups';
INCR signups
Un contrôle rapide : si votre appli lit la valeur du compteur juste pour l'incrémenter, vous êtes probablement retombé dans le lire-modifier-écrire.
Les incréments atomiques ne sont pas gratuits. Si une seule ligne/clé est mise à jour constamment (une « hot key » comme un compteur global de pages vues), vous pouvez rencontrer :
- contention de verrous ou mises à jour plus lentes
- latence plus élevée lors des pics
- décalage de réplication si vous lisez depuis des replicas
- timeouts qui déclenchent des retries
Clés de déduplication : arrêter le double comptage dû aux retries et replays
L'idempotence signifie que soumettre la même action deux fois a le même effet que la soumettre une fois. Pour les compteurs, c'est la différence entre « à peu près correct » et digne de confiance.
Les duplicatas sont fréquents :
- Un utilisateur clique deux fois sur « Payer maintenant ».
- Un client mobile perd la connexion et réessaie.
- Un fournisseur de webhooks renvoie après un 500.
- Une queue re-livre un job.
Une clé de déduplication est généralement un event_id qui identifie de façon unique l'événement réel que vous comptez. Elle peut venir d'un ID de webhook fournisseur, d'un UUID généré côté client, d'un ID généré côté serveur, ou d'une clé déterministe vraiment unique comme order_id + event_type.
Une fois que vous avez event_id, stockez-le et refusez de compter le même événement deux fois. La règle de base : insérez d'abord le event_id, puis incrémentez, ou faites les deux dans une même transaction.
Options de stockage courantes :
- Une table de base de données d'événements traités avec une contrainte UNIQUE sur
event_id - Un index UNIQUE sur votre table analytics/événements
- Un cache (comme Redis) avec un TTL pour des fenêtres de déduplication de courte durée
Exemple : un webhook d'achat arrive, votre handler expire et le fournisseur le rejoue. Sans déduplication, vous enregistrez deux achats et incrémentez le revenu deux fois. Avec un event_id unique, la seconde tentative devient une opération nulle.
Écritures par lots : moins de hits en base, analytics plus stables
Sous charge, les écritures sur une seule ligne peuvent s'accumuler. Cela augmente le temps de verrou, ralentit les réponses et augmente le risque de timeouts ou d'échecs partiels. Le batching coupe les allers-retours vers la base et peut rendre les analytics plus stables.
Un modèle mental simple : capturez les événements rapidement, puis écrivez des résumés en moins d'opérations mais plus grosses. Les approches courantes incluent le buffering puis flush toutes les N secondes, mettre en queue les événements et agréger dans des workers, rollups planifiés (horaire/journalier), ou un hybride (petits compteurs temps réel plus backfills périodiques).
Le compromis est la fraîcheur. Votre tableau de bord peut être en retard de quelques secondes ou minutes, mais vous verrez généralement moins d'écritures échouées et moins de pics causés par des tempêtes de retry.
Choisissez la fenêtre de batch selon l'usage de la métrique :
- Secondes : flux en direct, limitation de débit, widgets « actif maintenant »
- Dizaines de secondes : tableaux de bord marketing et funnels d'inscription
- Minutes : revenus et la plupart des rapports d'administration
- Heures/jours : rapports et audits de niveau finance
Un schéma sûr pour compteurs et analytics
Traitez chaque incrément comme le résultat d'un événement spécifique. Le compteur n'est qu'un résumé.
Un schéma qui tient la charge :
-
Nommez l'événement et choisissez un identifiant unique stable. Utilisez quelque chose qui reste identique au travers des retries (par exemple :
order_id,payment_intent_id, ou unevent_idgénéré et passé dans le flux). -
Enregistrez l'événement (ou une ligne de déduplication légère) en premier. Stockez l'id dans une table
eventsoudedupeavec une contrainte unique. -
Incrémentez avec une mise à jour atomique. Utilisez une instruction d'incrément unique, pas « lire, ajouter, écrire ». Si possible, gardez l'insertion d'événement et la mise à jour du compteur dans une même transaction.
-
Rendez les retries sûrs. Si l'insertion de déduplication échoue parce que la clé existe déjà, considérez cela comme un succès et sautez l'incrément.
-
Batchez quand c'est pertinent, sans casser les règles. Mettez en buffer les incréments et flush périodiquement, mais seulement après que l'événement/la ligne de déduplication soit bien stocké(e).
Exemple : un utilisateur clique sur « Acheter », votre serveur crée un événement purchase_completed avec la clé de déduplication order_123. Si le fournisseur de paiement réessaie le webhook, la seconde insertion frappe la contrainte unique et vous n'ajoutez pas un second achat.
Retries, timeouts et queues de messages sans gonfler les compteurs
Beaucoup de systèmes livrent des événements avec une garantie « au moins une fois ». En clair : le même message peut apparaître deux fois.
Les timeouts sont la version la plus sournoise. Un client appelle votre API, attend, expire, et réessaie. Mais le serveur a peut-être terminé et commité la mise à jour du compteur. Vous vous retrouvez avec deux tentatives « réussies » pour une seule action réelle.
La règle : ne réessayez que du travail idempotent.
Un pattern de queue pratique :
- L'API crée un événement avec un
event_idunique (par exemplepurchase-<order_id>) et le met en file. - Un worker traite l'événement et écrit deux choses dans une seule transaction : (1) marquer le
event_idcomme traité, (2) incrémenter le compteur. - Si le message est redélivré, le worker voit que
event_idest déjà traité et saute l'incrément.
Pour le debug d'incidents, gardez des logs simples et cohérents :
event_id- timestamps (reçu et commité)
- source (API, queue, cron)
- résultat (traité, ignoré comme duplicata, échoué)
- nombre de retries
Erreurs communes qui causent la dérive des métriques
Ces problèmes se répètent à travers les produits.
Erreur 1 : Lire puis écrire les incréments
Deux requêtes peuvent lire la même valeur et écrire la même nouvelle valeur. Utilisez un incrément atomique en base pour que la mise à jour se fasse en une opération.
Erreur 2 : Compter avant que l'action ne réussisse vraiment
Si vous incrémentez quand la requête démarre, vous surcomptez quand l'action échoue ensuite (paiement refusé, envoi d'email raté, transaction rollbackée). Comptez après avoir reçu un vrai signal de succès.
Erreur 3 : Clés de déduplication sans application
Une clé de déduplication ne fonctionne que si vous imposez l'unicité au niveau de la base (contrainte/index unique). Sans cela, les duplicatas passent toujours via les retries et les workers parallèles.
Erreur 4 : Batch qui perd des données
Le batching réduit la charge, mais les buffers en mémoire peuvent disparaître au redémarrage. Rendez le comportement de flush explicite : flush basé sur le temps, sur la taille, et flush lors du shutdown.
Erreur 5 : Frontières de journée cassées dans les rollups
Les métriques journalières dérivent quand les services ne sont pas d'accord sur les fuseaux ou les frontières de jour. Choisissez une norme (souvent UTC), stockez les timestamps de façon cohérente et conservez les événements bruts assez longtemps pour recomputer les rollups.
Vérifications rapides pour valider que vos compteurs sont fiables
Si vous ne pouvez pas expliquer un incrément, vous ne pouvez pas prouver qu'il est correct. Même une simple table d'événements bruts suffit pour des contrôles ponctuels.
Un scan de sanity rapide :
- Pouvez-vous tracer chaque incrément jusqu'à un
event_idstocké avec l'événement brut ? - Faites-vous respecter l'unicité des clés de déduplication (index/contrainte unique) ?
- Les compteurs sont-ils mis à jour par des opérations atomiques (instruction unique), et non par du lire-modifier-écrire dans le code applicatif ?
- Rapprochez-vous les totaux avec les événements bruts (même une vérif quotidienne) ?
- Avez-vous des alertes sur des reset soudains ou des sauts inhabituels ?
Un test pratique : choisissez une métrique comme « nouvelles inscriptions », récupérez 50 event_id récents et vérifiez que chacun correspond exactement à un incrément. Puis rejouez la même requête/message quelques fois et confirmez que le compteur ne bouge pas.
Exemple : corriger les compteurs d'inscriptions et d'achats dans une vraie appli
Une petite appli d'abonnement suit les inscriptions, achats et « email de bienvenue envoyé ». Pendant des semaines le tableau de bord semble correct. Puis le trafic augmente et le support commence à entendre « j'ai été facturé deux fois » ou « j'ai cliqué une fois ». Les totaux s'écartent des rapports de paiement.
Ce qui se passe : double-clicks, retries clients après timeouts, et webhooks de paiement rejoués. Si votre code incrémente d'abord puis vérifie, les métriques dérivent.
Une correction stable combine trois actions :
- Déduplication par action :
signup:<user_id>,purchase:<payment_event_id>,email:<message_id>, stockées avec une contrainte unique. - Incréments atomiques : remplacer lire-modifier-écrire par un seul incrément en base.
- Batcher les mises à jour à fort volume : garder du temps réel là où c'est nécessaire, batcher là où ce n'est pas le cas.
Un plan de déploiement simple :
- Rejouez la même payload de webhook 5–10 fois en staging et confirmez que les compteurs ne bougent pas après la première.
- Déployez derrière un feature flag et activez pour une petite portion du trafic.
- Lancez un job de réconciliation pour comparer événements bruts vs compteurs et recompléter les différences.
- Surveillez les « hits de déduplication » pour confirmer que les retries sont captés.
Prochaines étapes : stabiliser les métriques sans tout réécrire
Vous n'avez généralement pas besoin d'une refonte complète. Vous avez besoin d'une carte claire d'où les comptes sont créés, où les retries peuvent se produire et où les duplicatas s'infiltrent.
Commencez par un inventaire de base :
- Où chaque compteur vit (base, cache, outil analytics)
- D'où proviennent les événements (endpoints, jobs, webhooks)
- Tous les chemins de retry (retries clients, retries de queue, redélivrés de webhooks)
- Comment vous identifiez un événement (
event_id,request_id,order_id) - Où se font les écritures (en un seul endroit ou plusieurs)
Puis corrigez dans cet ordre :
- Arrêter le double comptage (clés de déduplication et gestion idempotente sur les chemins les plus chauds)
- Rendre les incréments atomiques
- Améliorer la performance (batching, traitement asynchrone)
- Ajouter des contrôles continus (rapprochement événements bruts vs compteurs, alertes sur sauts étranges)
Si vous avez hérité d'une base de code générée par IA, supposez que la logique des compteurs a été copiée-collée et implémentée légèrement différemment à plusieurs endroits. Unifier ces chemins dans une fonction ou un service partagé est souvent le moyen le plus rapide de rendre les correctifs durables.
Si vous voulez un second avis, FixMyMess (fixmymess.ai) se concentre sur le diagnostic et la réparation de problèmes comme les mises à jour non atomiques, l'absence d'idempotence et les webhooks sensibles au replay dans les applications générées par IA. Un audit de code gratuit peut rapidement mettre en lumière les quelques endroits qui causent le plus de dérive sous trafic réel.