Corriger les problèmes de configuration « ça marche sur ma machine » pour dev, staging et prod
Corrigez les problèmes « ça marche sur ma machine » avec une séparation claire dev/staging/prod, validation des variables d'environnement et vérifications simples pour éviter les surprises en production.
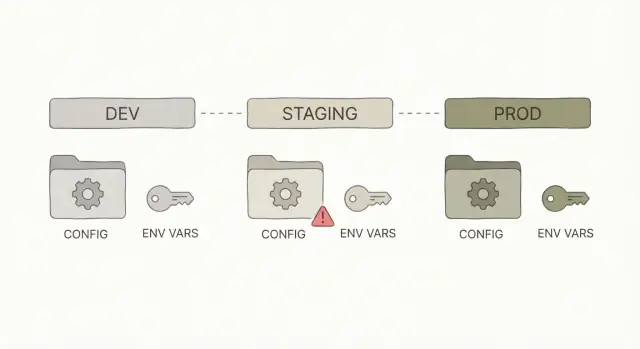
Ce que signifie généralement « ça marche sur ma machine »
Quand quelqu'un dit « ça marche sur ma machine », cela veut dire que l'application tourne bien sur son ordinateur mais plante après le déploiement. Le code peut être identique, mais l'environnement autour est différent.
La plupart du temps, ce n'est pas un « bug logique ». C'est de la configuration : l'application reçoit des entrées différentes selon l'endroit où elle tourne. En local, votre machine comble discrètement les manques (logins enregistrés, fichiers locaux, bases de données pré-remplies, tokens en cache). En staging ou en production, ces béquilles n'existent pas.
Causes courantes :
- Variables d'environnement manquantes ou incorrectes (clés API, URL de base de données, URL de callback d'auth)
- Services externes différents (SQLite local vs Postgres hébergé, Stripe sandbox vs Stripe live)
- URLs et redirections différentes (localhost vs un vrai domaine)
- Paramètres de build et d'exécution différents (version de Node, port, feature flags)
- Secrets copiés dans le code ou dans des fichiers
.envet jamais configurés en production
Les problèmes de config se manifestent souvent par des symptômes confus : la connexion marche en local mais échoue après le déploiement, les paiements expirent, les images ne se téléchargent pas, ou les jobs en arrière-plan ne tournent jamais. Le flux de code est le même, mais l'application pointe au mauvais endroit ou manque une valeur requise.
L'objectif est d'avoir des exécutions reproductibles dans chaque environnement. Dev, staging et prod peuvent utiliser des valeurs différentes, mais elles doivent suivre les mêmes règles. Si une variable est requise en prod, traitez-la comme requise partout. Si staging utilise une base différente, elle doit quand même utiliser le même schéma et le même type de connexion.
Exemple : une app générée par IA est déployée et crashe immédiatement avec « DATABASE_URL is undefined. » En local, le dev l'avait dans un fichier .env privé. En production, il n'a jamais été défini. La correction n'est pas de fouiller le code. C'est définir la config requise, la valider au démarrage, et la configurer dans chaque environnement.
Dev vs staging vs prod : ce qui change et ce qui ne doit pas changer
Dev, staging et prod sont la même application à trois endroits différents.
- Dev est l'endroit pour construire et tester rapidement sur votre laptop.
- Staging est une répétition qui devrait se comporter comme la production, mais sans vrais clients.
- Prod est le système en ligne dont dépendent les utilisateurs.
Certaines choses doivent différer entre les environnements parce qu'elles pointent vers des services ou des données différents. D'autres choses doivent rester identiques pour que vous testiez vraiment ce que vous allez livrer.
Ce qui devrait changer
Conservez le même code, mais changez les valeurs autour :
- URLs de services (base API, callback OAuth, URL de webhook)
- Clés et secrets (identifiants différents par environnement)
- Sources de données (bases et buckets séparés, ou au moins des schémas séparés)
- Feature flags (par défaut sûrs en prod, plus de bascules en dev)
- Niveau de logs (plus verbeux en dev, moins de bruit en prod)
L'environnement doit décider de ces valeurs, pas la machine locale d'un développeur.
Ce qui ne doit pas changer
Le build et l'exécution doivent correspondre entre staging et prod : mêmes dépendances, même étape de build, même commande de démarrage, même version d'exécution. Si staging utilise node 20 mais prod node 16, vous testez une application différente.
Évitez les « petites modifications rapides » en production, comme éditer un fichier de config sur le serveur ou ajouter une variable d'env manquante à la main sans l'enregistrer. Ces corrections ponctuelles créent des échecs impossibles à reproduire plus tard. Un exemple courant : quelqu'un corrige à chaud une URL de redirect d'auth en production, staging reste obsolète, et le prochain déploiement casse la connexion.
Variables d'environnement 101 (sans jargon)
Une variable d'environnement (env var) est un réglage que votre app lit au démarrage. Elle vit en dehors du code, fournie par le terminal, le service d'hébergement ou l'outil de déploiement.
Pensez aux env vars comme aux entrées de votre app. Traitez-les comme des exigences, pas des suggestions. Si une valeur manque, l'app devrait échouer vite avec un message clair, pas continuer laborieusement et casser plus tard.
Une façon simple de décider où mettre quoi :
- Env vars : valeurs qui changent par environnement ou sont sensibles. Exemples :
DATABASE_URL,JWT_SECRET,STRIPE_API_KEY,S3_BUCKET,APP_ENV. - Code : valeurs par défaut et logique qui doivent être identiques partout. Exemple : « les sessions expirent après 7 jours. »
- Fichiers de config (commités) : réglages non secrets que vous voulez relire et versionner. Exemple : feature flags sûrs à exposer, libellés UI, origines CORS autorisées (seulement si non sensibles).
Le nommage est souvent source de confusion. Choisissez une convention et tenez-vous-y : MAJUSCULES, mots séparés par des underscores, et un préfixe commun si vous avez plusieurs services. Évitez les quasi-duplications comme DB_URL, DATABASE et DATABASE_URL dans différentes parties de l'app.
Un piège courant est la variable « optionnelle » qui désactive silencieusement des fonctionnalités. Par exemple, une app générée par IA peut envelopper l'envoi d'emails dans if (process.env.SMTP_PASSWORD) sans avertir quand c'est manquant. Résultat : les inscriptions fonctionnent en local, mais les réinitialisations de mot de passe n'arrivent jamais en production.
Meilleure règle : si une fonctionnalité est activée dans cet environnement, ses env vars requises doivent être présentes, sinon l'app doit s'arrêter et indiquer ce qui manque.
Étape par étape : mettre en place une structure de config simple et cohérente
La plupart des bugs « ça marche sur ma machine » viennent d'une config éclatée. Quelqu'un met des valeurs dans un fichier local, un autre dans le tableau de bord d'hébergement, et l'app choisit discrètement la première valeur qu'elle voit. Décidez d'une structure et respectez-la.
1) Choisir une source de vérité unique
Pour la plupart des apps web, la règle la plus propre est : les variables d'environnement sont la source de vérité. Un fichier .env local peut être pratique pour le développement, mais votre code doit lire la config de la même façon partout.
Si vous devez supporter à la fois un fichier de config et des env vars, définissez une priorité claire (par exemple : les env vars écrasent les valeurs du fichier) et consignez-la pour éviter les surprises.
2) Ajouter un indicateur d'environnement explicite
Faites annoncer à l'app dans quel environnement elle pense tourner. Utilisez une variable comme APP_ENV avec trois valeurs autorisées : development, staging, production. Évitez de deviner d'après les domaines ou « si debug est vrai ».
Quand l'environnement est explicite, vous pouvez faire des choix sûrs par défaut, comme des logs verbeux en dev et plus discrets en prod.
Une configuration pratique pour la plupart des équipes :
- Gardez un fichier modèle commité comme
.env.examplequi liste toutes les variables requises (sans secrets réels). - Utilisez un
.envlocal pour la commodité et ignorez-le du versionnement. - Stockez les valeurs de staging et production dans les réglages d'environnement de votre hébergeur.
- Chargez la config en un seul endroit (un module de config unique) et importez-le partout.
3) Faire de bons choix par défaut
Les valeurs par défaut conviennent pour le développement (comme une URL de base de données locale). En production, évitez les valeurs par défaut pour tout ce qui est sensible. Un DATABASE_URL manquant en production doit faire échouer l'app rapidement, pas retomber silencieusement sur quelque chose d'inattendu.
4) Documenter ce dont les coéquipiers ont besoin pour lancer l'app
Mettez les variables requises en un seul endroit (généralement .env.example + une courte note dans le README). C'est d'autant plus important pour les apps générées par IA, où la config a tendance à croître de façon aléatoire et à se retrouver répartie entre code, fichiers et tableaux de bord.
Valider les env vars au démarrage pour éviter les surprises
Beaucoup de problèmes « ça marche sur ma machine » surviennent parce que l'app démarre avec des réglages manquants ou erronés, puis échoue plus tard quand un utilisateur atteint une page précise. Une correction simple consiste à valider les variables d'environnement au démarrage et refuser de tourner si quelque chose cloche.
Échouer vite avec des vérifications claires
Traitez la config comme des données d'entrée. Si des valeurs requises sont absentes, arrêtez l'app et affichez une erreur qui indique exactement quoi définir (sans divulguer de secrets).
Ce qu'il vaut la peine de valider tôt :
- Présence : valeurs requises comme
DATABASE_URL,AUTH_SECRET,PORT - Type :
PORTest un nombre,DEBUGest un booléen, les timeouts sont des entiers - Format : les URLs ressemblent à des URLs, les emails ressemblent à des emails
- Règles entre champs : si
FEATURE_X=true, exiger aussiFEATURE_X_KEY - Valeurs autorisées :
APP_ENVest l'un dedevelopment,staging,production
Après validation, loggez un court résumé de démarrage comme le nom de l'environnement, la version de l'app, et les fonctionnalités optionnelles activées. N'affichez pas de secrets, de chaînes de connexion complètes ni de tokens. Si vous avez besoin d'une confirmation, loggez seulement qu'une valeur est configurée, ou un fingerprint sûr (par exemple les 4 derniers caractères).
Ajouter une commande d'auto-test de la config
Un auto-test léger rend les déploiements plus sûrs car vous pouvez l'exécuter avant de démarrer le serveur.
Par exemple :
config:testcharge les env vars, les valide, et sort avec un code 0/1- Il affiche des erreurs exploitables (clés manquantes, types incorrects, URLs invalides)
- Il peut confirmer la connectivité quand c'est sûr (par exemple, peut-il joindre l'hôte de la base) sans divulguer les identifiants
Garder les secrets hors du code (et hors des logs)
Un « secret » est tout ce qui donne un accès : clés API, secrets clients OAuth, clés de signature de session, mots de passe de base, clés privées, secrets de signature de webhook, et même certains tokens internes. Si quelqu'un l'obtient, il peut usurper votre application.
Les apps générées par IA fuient souvent des secrets à deux endroits : le code et les logs. Une clé est codée en dur « juste pour tester », une chaîne de connexion finit dans un commit, ou quelqu'un imprime process.env pour déboguer et oublie de supprimer avant livraison.
Règles qui évitent la plupart des incidents :
- Ne commettez jamais de secrets dans le repo, même « temporaires ».
- N'envoyez jamais de secrets au navigateur ou au client mobile. Si l'utilisateur peut le voir, ce n'est pas un secret.
- Ne loggez jamais de secrets ni d'en-têtes complets. Rédigez/masquez les tokens et mots de passe.
- Préférez des tokens à courte durée de vie quand c'est possible.
Si vous suspectez qu'une clé a été exposée, considérez-la compromise. Faites-la tourner, puis vérifiez que l'ancienne valeur est bien invalidée (beaucoup de plateformes gardent d'anciennes clés actives jusqu'à désactivation). Vérifiez aussi l'historique de déploiement, les logs et les captures d'écran partagées.
Utilisez des identifiants séparés par environnement. Dev, staging et prod ne doivent pas partager le même user de base de données, la même clé API ou le même secret de signature. Ainsi, une fuite en staging n'ouvre pas automatiquement la production.
Faire en sorte que staging ressemble à production (suffisamment)
Staging sert à attraper les problèmes qui n'apparaissent qu'après déploiement, mais cela ne fonctionne que si il se comporte comme la production sur les points importants.
Commencez par des builds reproductibles. Si staging utilise Node 20 mais production Node 18, ou si un environnement installe des versions de dépendances différentes, vous ne testez pas la même appli. Figez votre runtime et vos dépendances (pincez les versions, commitez le lockfile et utilisez la même commande de build partout). Évitez les étapes d'installation spécifiques à un environnement qui changent le comportement ou sautent des vérifications.
Gardez staging proche de prod sur les chemins critiques : même type de base de données, même cache ou queue si vous en utilisez, et même séquence de démarrage (migrations, étapes de seed, jobs en arrière-plan). Il n'a pas besoin de l'échelle ou des données réelles, mais il doit utiliser les mêmes services et le même ordre d'opérations.
Les health checks sont votre système d'alerte précoce. Un bon déploiement en staging doit échouer vite s'il ne peut pas joindre la base, si des migrations sont en attente, ou si des env vars requises sont manquantes.
Un standard simple :
- Même runtime et même lockfile de dépendances en dev, staging et prod
- Même artefact de build promu de staging à prod (pas reconstruit différemment)
- Mêmes étapes de démarrage (migrer, puis démarrer le processus web, puis les workers)
- Un health check de base qui vérifie la connexion DB et quelques endpoints clés
- Un fingerprint de config enregistré par déploiement (quels noms d'env vars étaient définis, flags activés/désactivés), sans valeurs
Erreurs courantes qui provoquent des pannes à l'exécution
La plupart des bugs « ça marchait hier » ne sont pas aléatoires. Ils viennent généralement d'une dérive de config : quelqu'un a changé un réglage, ajouté une correction à chaud, ou modifié un secret à un endroit, puis oublié de le documenter. Une semaine plus tard, un déploiement remet le code à un état antérieur mais pas les réglages, et l'app casse d'une manière qui semble mystérieuse.
Un autre échec classique est de s'appuyer sur des fichiers locaux qui n'existent pas en production. Votre laptop peut avoir un dossier uploads/ avec des permissions permissives, une base SQLite locale, ou un .env qui ne sera jamais sur le serveur. En production, le système de fichiers peut être en lecture seule, les conteneurs peuvent redémarrer à tout moment, et « ce fichier » n'existe tout simplement pas.
Erreurs qui tournent souvent en outage :
- Prendre les warnings pour négligeables : env vars manquantes, valeurs de repli, ou réglages « optionnels » qui deviennent plus tard requis
- Mélanger variables client et serveur dans les apps web, exposant des secrets ou cassant la build lorsque le navigateur ne peut pas lire des valeurs côté serveur
- Oublier d'enregistrer les URLs de callback OAuth ou de paiement pour un environnement donné
- Partir du principe que des chemins locaux existent partout (uploads, dossiers temporaires, fichiers DB locaux, certificats)
- Faire des changements de config d'urgence dans le tableau de bord d'hébergement et ne pas synchroniser le changement dans la documentation partagée
Petit exemple : un fondateur a un prototype généré par IA qui tourne bien en environnement dev hébergé, mais la connexion en production échoue. La cause est simple : l'app retombe sur une URL de callback dev parce que la variable de prod est manquante. Pas d'erreur claire, juste une boucle de redirection.
Checklist rapide avant de livrer
Une routine pré-ship courte attrape les problèmes de config les plus courants avant les utilisateurs. Exécutez-la contre l'environnement exact que vous livrez (staging pour la répétition, production pour le vrai déploiement).
- Confirmez que chaque variable d'environnement requise est définie (et non vide). Vérifiez deux fois les valeurs qui diffèrent par environnement : base URLs, clés API, réglages d'email.
- Vérifiez que l'app pointe vers la bonne base de données et le bon stockage (hôte/nom de DB, bucket de stockage, queue, cache). Une mauvaise valeur peut envoyer le trafic production vers staging.
- Vérifiez les réglages d'auth de bout en bout : URLs de redirect, domaine des cookies, réglages de session, origines CORS autorisées.
- Lancez la validation de config au démarrage avant la mise en production. L'app doit refuser de démarrer si quelque chose de critique manque ou est manifestement faux.
- Faites un flux de bout en bout réaliste en staging : inscription, connexion, réinitialisation de mot de passe, paiement, upload, export, invitation d'un coéquipier.
Si les tests en staging passent mais que la connexion en production échoue, la cause est souvent basique : URL de redirect qui pointe vers le mauvais domaine, domaine de cookie incorrect, ou secret d'auth requis non défini.
Exemple : nettoyage de config sur une app générée par IA
Un fondateur avait une app générée par IA qui fonctionnait en local mais tombait en panne dès le déploiement. Le problème n'était pas compliqué. En production, les noms de variables étaient différents, un secret manquait, et une URL pointait toujours vers localhost.
Ce qui a cassé après le déploiement
Les utilisateurs pouvaient ouvrir le site, mais la connexion échouait. Les symptômes variaient : parfois un écran vide, parfois une 500 générique.
Causes racines :
- URL de callback OAuth encore réglée sur
http://localhost:3000/... - Un secret d'auth requis (utilisé pour signer les sessions ou tokens) non défini en production
- Une URL de base de données de staging utilisée par accident en production
Comment nous avons corrigé (sans tâtonnements)
Nous avons d'abord audité les variables d'environnement : chaque valeur que l'app lit, d'où elle vient, et quel environnement en a besoin. Ensuite nous avons standardisé les noms et séparé proprement les valeurs entre dev, staging et prod.
Nous avons aussi ajouté des garde-fous pour que les échecs apparaissent immédiatement :
- Validation des variables requises au démarrage et listing de ce qui manque
- Validation des formats (par exemple, les URLs doivent être HTTPS en prod, les secrets doivent atteindre une longueur minimale)
- Blocage des valeurs par défaut dangereuses en production (pas de callbacks localhost, pas de clés placeholder)
- Logs avec indices sûrs seulement (ne jamais afficher des secrets)
Après cela, les déploiements sont devenus prévisibles. Staging s'est comporté comme la production là où c'était important, et les problèmes sont apparus au démarrage au lieu de pendant une connexion utilisateur.
Étapes suivantes : durcir votre config sans vous bloquer
N'essayez pas de tout perfectionner en une seule fois. Choisissez un petit changement qui réduit immédiatement les surprises, vérifiez-le en local et après déploiement, puis faites une passe de suivi avant la prochaine release.
Bons gains rapides :
- Ajoutez un
.env.examplequi liste chaque variable requise (avec valeurs placeholders sûres) - Ajoutez une validation au démarrage pour que l'app échoue vite quand une variable manque ou est malformée
- Retirez les clés, URLs et flags de debug codés en dur et déplacez-les dans la config d'environnement
- Arrêtez d'afficher des secrets dans les logs (même pour du debug temporaire)
- Renommez les variables confuses pour qu'elles correspondent à leur usage
Puis faites une passe de durcissement limitée dans le temps :
- Comparez les noms de variables entre dev, staging et prod et assurez-vous que seules les valeurs diffèrent
- Re-vérifiez les réglages d'auth par environnement (URLs de redirect, paramètres de cookie, callbacks OAuth)
- Confirmez que les secrets sont stockés dans le coffre de votre plateforme de déploiement, pas dans le repo
- Effectuez un déploiement propre depuis zéro pour attraper les variables manquantes et les suppositions
Si vous héritez d'un repo généré par IA et qu'il est en désordre, commencez par un audit de config et de secrets avant de toucher aux fonctionnalités. C'est généralement là que se cachent les valeurs par défaut, les fuites et les pannes spécifiques au déploiement.
Si vous êtes bloqué, FixMyMess (fixmymess.ai) est spécialisé dans le diagnostic et la réparation des apps générées par IA, y compris la dérive de config, les échecs d'auth et la préparation au déploiement. Leur audit de code gratuit peut vous aider à voir ce qui manque et ce qu'il faut corriger en priorité.
Questions Fréquentes
Que veut dire « ça marche sur ma machine » ?
Cela signifie généralement que le code est correct, mais que l'environnement est différent après le déploiement. Quelque chose que votre portable fournissait automatiquement (variables d'environnement, fichiers locaux, tokens en cache, données seedées, une base de données différente) n'est pas présent en staging ou en production, donc l'application casse même si le dépôt n'a pas changé.
Par où commencer quand une app casse seulement après le déploiement ?
Commencez par vérifier la configuration, pas la logique métier. Comparez les variables d'environnement, les versions d'exécution (par exemple Node), et les endpoints de services entre le local et l'environnement déployé, puis reproduisez le problème avec les mêmes entrées que le serveur voit.
Quelle est l'erreur de configuration la plus courante qui cause des échecs de déploiement ?
Les variables d'environnement manquantes ou incorrectes sont la cause la plus fréquente. Un signe typique est une erreur comme « DATABASE_URL is undefined », ou des fonctionnalités qui échouent silencieusement parce qu'une clé n'a pas été configurée en production.
Qu'est-ce qui doit être différent entre dev, staging et production ?
Gardez une seule application avec trois ensembles de valeurs. Dev sert à aller vite, staging est une répétition qui doit se comporter comme la prod, et la prod est le système en production. Modifiez les URLs de service, les secrets et les sources de données selon l'environnement, mais conservez la même build, la même version d'exécution et les mêmes étapes de démarrage.
Qu'est-ce qui appartient aux env vars vs code vs fichiers de config ?
Considérez les variables d'environnement comme des entrées qui peuvent changer par environnement ou qui doivent rester secrètes. Mettez les règles métier et les valeurs par défaut immuables dans le code, et gardez les réglages non secrets et révisables dans des fichiers de configuration versionnés seulement s'ils sont sûrs à exposer.
Comment éviter la confusion « dans quel environnement suis-je ? »
Ajoutez un seul indicateur explicite comme APP_ENV et n'acceptez que des valeurs reconnues, par exemple development, staging, production. Ne devinez pas à partir du nom de domaine ou d'un toggle de debug, car cela crée des différences de comportement difficiles à reproduire.
Comment faire en sorte que les problèmes d'env vars échouent rapidement au lieu d'échouer plus tard ?
Validez au démarrage et refusez de lancer l'application si des valeurs requises sont manquantes ou malformées. Vous attraperez les problèmes avant que de vrais utilisateurs n'atteignent une page cassée, et le message d'erreur pourra indiquer exactement ce qu'il faut définir sans divulguer de secrets.
Est-ce utile d'ajouter une commande config:test à mon app ?
Oui. Un petit auto-test de config est l'une des étapes pré-déploiement les plus sûres. Il charge la configuration, valide types et formats, et sort proprement avec des erreurs exploitables, pour arrêter une mauvaise release avant de démarrer le serveur web.
Comment empêcher les secrets de fuir dans les apps générées par IA ?
Ne laissez pas les secrets dans le repo, dans le code côté client, ni dans les logs. Si vous pensez qu'un secret a été exposé, faites-le tourner immédiatement et assurez-vous que chaque environnement a des identifiants séparés afin qu'une fuite en staging ne débloque pas la production.
Quelle est la manière la plus rapide de stabiliser un prototype généré par IA qui ne tourne pas en production ?
Stabilisez d'abord la structure de la configuration : centralisez le chargement de la config, standardisez les noms de variables et ajoutez la validation au démarrage. Si vous héritez d'un repo généré par IA qui plante après déploiement, FixMyMess peut exécuter un audit de code gratuit et aider à réparer la dérive de config, les problèmes d'auth et la préparation au déploiement rapidement.