Corriger un schéma de base de données désordonné d'une application IA, étape par étape
Apprenez à corriger un schéma de base de données désordonné d'une app générée par l'IA avec un flux de triage sûr : cartographier les entités, supprimer les doublons, normaliser les tables et ajouter des contraintes.
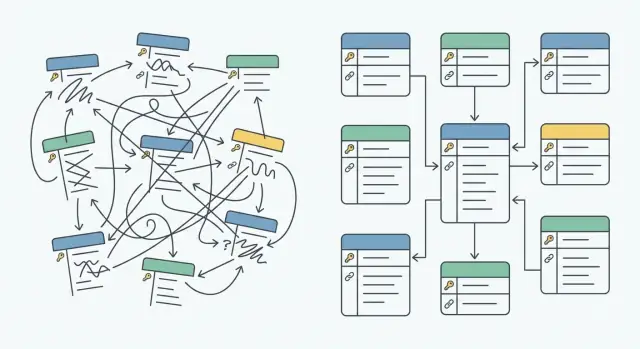
À quoi ressemble un schéma désordonné dans les apps générées par l'IA
Un schéma désordonné ne paraît généralement pas faux au premier abord. L'app tourne, les pages se chargent et les données apparaissent. Les problèmes commencent quand vous essayez de changer quelque chose et que vous réalisez que vous ne savez pas quelle table est la source de vérité.
Les prototypes générés par l'IA créent souvent des tables à la va-vite : une par écran, fonctionnalité ou prompt. Les noms dérivent avec le temps (User, Users, user_profiles). Les formats d'ID varient (entier ici, UUID là). Les relations sont implicites dans le code au lieu d'être appliquées par la base de données.
Signes courants que votre schéma vous coûte déjà cher :
- Tables dupliquées stockant la même chose avec des colonnes légèrement différentes
- Identifiants confus (plusieurs champs
id, ou des clés étrangères stockées en texte brut) - Nommage incohérent (
createdAtvscreated_at,statusvsstate) - Colonnes qui mélangent des préoccupations (nom, email et JSON brut entassés ensemble)
- « Relations molles » (
order.userIdexiste, mais rien ne garantit qu'il corresponde à un vrai utilisateur)
Ce qui casse n'est rarement « la base de données » isolément. Ce sont les fonctionnalités qui y sont liées : sessions de connexion qui ne correspondent plus aux utilisateurs, enregistrements de paiement qui ne se joignent plus correctement, rapports qui comptent double, et écrans admin qui dépendent d'un ancien nom de colonne.
Un petit exemple : un prototype peut avoir à la fois customers et users, et les commandes pointent parfois vers customers.id et parfois vers users.email. Nettoyer ça est possible, mais la priorisation consiste à réduire le risque d'abord : cartographier ce qui existe, confirmer ce que l'app lit et écrit, puis améliorer la structure par petites étapes.
Mettez en place des garde-fous avant de toucher quoi que ce soit
Avant de lancer des migrations, créez des protections pour qu'une mauvaise manipulation ne provoque pas une panne. Beaucoup d'apps générées par l'IA fonctionnent « juste assez » parce que les données sont incohérentes, pas parce que le schéma est sain. Votre travail est de rendre le tout plus sûr sans casser ce que les gens utilisent déjà.
Commencez par une sauvegarde complète, puis prouvez que vous pouvez la restaurer. Ne présumez pas. Restaurez dans une base distincte et exécutez l'app dessus. Si vous ne pouvez pas restaurer, vous n'avez pas de filet de sécurité.
Ensuite, créez une copie de staging qui ressemble le plus possible à la production. Utilisez le même schéma, un snapshot récent des données, et la même version de l'app. C'est en staging que vous testerez les migrations, vérifierez les écrans clés et observerez les performances des requêtes avant de toucher les utilisateurs réels.
Notez les quelques parcours applicatifs qui doivent rester fonctionnels pendant les refactors. Restez bref et spécifique. Par exemple : « inscription -> vérification email -> création de projet », « validation panier -> paiement réussi -> reçu », « tableau de bord admin se charge en moins de 3 secondes ».
Enfin, décidez d'un plan de rollback pour chaque changement. Si une migration échoue à mi-parcours, vous devez savoir si vous allez appliquer un roll-forward (terminer la correction) ou un roll-back (restaurer et revenir sur le code). Une checklist simple aide :
- Sauvegarde créée, restauration testée et horodatage enregistré
- Copie de staging rafraîchie et app connectée à celle-ci
- 5–10 flux utilisateurs critiques documentés et propriétaires assignés
- La migration est réversible (ou un plan de roll-forward clair existe)
- Notes de monitoring : quels métriques ou logs confirmeront le succès
Étape 1 : Cartographier les entités et relations
Avant de modifier des tables, obtenez une carte claire de ce que l'app suppose que les données signifient. Les apps générées par l'IA créent souvent des tables en double qui semblent similaires mais représentent la même chose, ou mélangent plusieurs concepts dans une table. Une carte simple vous évite de « réparer » la mauvaise partie.
Commencez par lister les entités centrales en langage clair. Pensez aux utilisateurs, comptes, équipes, commandes, paiements, abonnements, factures, messages. Si vous ne pouvez pas décrire une table en une phrase, elle fait généralement trop de choses.
Ensuite, trouvez la clé primaire de chaque table. Notez quelle colonne est utilisée comme identifiant réel (souvent id), et signalez là où elle manque ou est peu fiable. Méfiez-vous des tables qui utilisent l'email, le nom d'utilisateur ou une combinaison de champs comme identifiant — elles engendrent des doublons.
Esquissez les relations
Esquissez comment les choses se connectent :
- Un-à-plusieurs : un utilisateur a plusieurs commandes
- Plusieurs-à-plusieurs : les utilisateurs peuvent appartenir à plusieurs équipes (nécessite généralement une table de jointure)
- Liens optionnels : une commande peut avoir un coupon, mais pas toujours
Si vous voyez des relations plusieurs-à-plusieurs stockées comme des IDs séparés par des virgules ou des tableaux JSON, marquez-les dès le départ. Cela impactera chaque étape suivante.
Suivez les lectures et écritures
Notez où l'app lit et écrit chaque table : quels écrans, quelles API, et quels jobs en arrière-plan ou tâches planifiées. Un moyen rapide est de chercher les noms de tables et les colonnes clés dans la base de code.
Exemple : si l'écran de paiement écrit à la fois dans orders et user_orders, vous avez probablement trouvé des sources de vérité concurrentes. Ne fusionnez rien tout de suite. Capturez l'information sur la carte.
Étape 2 : Identifier les duplications et sources de vérité conflictuelles
Les apps générées par l'IA créent souvent le même concept deux fois. Vous pouvez avoir customer et user, ou team et org, chacune avec sa table et des champs légèrement différents. Tout semble correct jusqu'à ce que vous essayiez de faire un rapport, appliquer des permissions ou corriger un bug et que vous réalisiez qu'il n'existe pas de vérité unique.
Parcourez votre carte de schéma de l'étape 1 et regroupez les tables par sens, pas par nom. Récupérez quelques lignes de chaque table candidate. Vous cherchez des endroits où deux tables stockent la même entité du monde réel.
Les duplications communes incluent les tables d'identité (customer vs user, profile vs user_details), les tables d'organisation (team vs org vs workspace), les tables de facturation (invoice vs bill vs payment_request), et les adresses répétées à plusieurs endroits.
Puis cherchez plusieurs identifiants faisant référence à la même entité. Les outils d'IA ajoutent souvent de nouveaux IDs en cours de développement, vous vous retrouvez donc avec id, user_id, uid et external_id. Les bugs commencent quand une partie de l'app joint sur uid et une autre sur id, et les données se scindent silencieusement.
Surveillez aussi le même champ stocké sous différents noms et formats (createdAt vs created_at, téléphone stocké en texte et en nombre). Même si les valeurs correspondent aujourd'hui, elles dériveront.
Choisissez une source de vérité par entité et écrivez-la. Par exemple : « users.id est la seule clé interne utilisateur ; external_id est optionnel et unique ; la table customers sera fusionnée dans users. » Vous ne changez rien pour l'instant. Vous décidez simplement qui gagne en cas de conflit.
Étape 3 : Normaliser les tables progressivement
La normalisation consiste à faire en sorte que chaque table ne signifie qu'une seule chose. Dans les apps générées par l'IA, le gain le plus rapide est d'enlever les éléments qui créent des données conflictuelles tout en gardant l'app fonctionnelle.
Commencez par repérer les colonnes qui mélangent plusieurs idées. Exemples courants : un champ address unique contenant rue, ville et code postal, ou un champ status qui combine « payé+expédié+remboursé ». Ces champs sont difficiles à valider et pénibles pour les rapports.
Ensuite, cherchez les données répétées mal placées. Une odeur classique : une table orders avec item1_name, item1_qty, item2_name, ou un blob JSON d'items. Ça marche pour une démo puis s'effondre quand il faut gérer des retours, des envois partiels ou des totaux précis.
Priorisez la normalisation là où ça fait mal :
- Incohérence des données (même nom utilisateur stocké à trois endroits, totaux qui ne correspondent pas)
- Besoins de reporting (requêtes finance/ops lentes ou incorrectes)
- Auth et permissions (rôles copiés entre tables)
- Tout ce qui empêche d'ajouter des contraintes (vous ne pouvez pas encore ajouter de clés étrangères)
- Tables à forte croissance (logs, events, commandes)
Allez-y progressivement pour éviter de casser les fonctionnalités. Créez de nouvelles tables en parallèle, backfillez les données, puis basculez les lectures en petites étapes. Par exemple, ajoutez order_items tout en conservant les anciens champs d'items. Écrivez temporairement dans les deux endroits, vérifiez que les totaux correspondent, puis faites lire l'app depuis order_items uniquement.
Étape 4 : Ajouter les contraintes dans un ordre sûr
Les contraintes marquent la frontière entre un nettoyage « propre » et un changement sûr. Elles transforment des suppositions en règles que la base de données applique. La clé est de les ajouter dans un ordre qui reflète la réalité d'aujourd'hui, pas le modèle parfait de demain.
Commencez par des règles à faible risque qui sont déjà vraies pour la plupart des lignes. Si une colonne est remplie pratiquement tout le temps, la rendre NOT NULL permettra souvent de détecter de vrais bugs sans surprendre l'app. Des contraintes CHECK légères peuvent aussi être utiles, tant qu'elles reflètent le comportement actuel de l'app (par exemple, « status doit être l'une de ces valeurs »).
Avant d'ajouter des clés étrangères, nettoyez les lignes incorrectes existantes. Les clés étrangères échouent si vous avez des enregistrements orphelins, comme un orders.user_id pointant vers un utilisateur inexistant. Comptez le nombre de lignes qui échoueraient, corrigez-les d'abord, puis appliquez la relation.
Les contraintes d'unicité viennent ensuite. Elles empêchent les doublons futurs, mais peuvent casser les flux d'inscription ou les imports si vos données contiennent encore des doublons. Dédoubez d'abord (Étape 2), puis n'ajoutez l'unicité que là où c'est une règle métier réelle (par exemple, une adresse email par utilisateur).
Si vous avez besoin d'une nouvelle colonne requise, déployez-la en phases :
- Ajoutez la colonne nullable avec une valeur par défaut pour les nouvelles lignes
- Backfillez les lignes existantes de manière contrôlée
- Mettez à jour l'app pour écrire la nouvelle colonne
- Puis passez à
NOT NULL
Exemple : une app générée par l'IA peut avoir users.email parfois vide, alors que l'UI la considère comme obligatoire. Backfillez ou corrigez les valeurs manquantes, puis ajoutez NOT NULL, et seulement après ajoutez la contrainte d'unicité sur email.
Étape 5 : Mettre à jour les requêtes de l'app sans casser les fonctionnalités
La plupart des pannes surviennent ici, pas lors de la migration SQL. L'app continue de demander d'anciennes colonnes, ou elle écrit des données au mauvais endroit.
Commencez par les lectures. Mettez à jour les SELECT et les réponses d'API pour qu'ils puissent gérer les deux structures (ancienne et nouvelle) pendant une courte période. Cela peut être aussi simple que lire d'abord dans les nouvelles tables, puis revenir aux anciennes colonnes si les nouvelles données manquent.
Un ordre sûr :
- Ajoutez de nouvelles requêtes pour le nouveau schéma, mais laissez les anciennes fonctionner
- Basculez d'abord les chemins de lecture (idéalement derrière un petit feature flag)
- Migrez ensuite les écritures pour que les nouveaux enregistrements aillent dans les nouvelles tables
- Conservez une compatibilité brève (view, colonne de compatibilité, ou double-écriture temporaire)
- Supprimez les anciennes requêtes seulement après avoir monitoré le trafic réel et corrigé les cas limites
Pour les écritures, soyez strict sur la validation. Si votre nouveau schéma sépare une colonne en deux tables, assurez-vous que chaque appel de création et de mise à jour peuple les deux endroits correctement. En cas de double-écriture, limitez la durée et journalisez chaque divergence pour permettre des corrections.
Exemple : un prototype stocke le statut d'une commande dans orders.status et payments.status. Mettez à jour les lectures pour préférer la nouvelle source, mettez ensuite le code d'écriture pour n'actualiser que la nouvelle colonne, tandis qu'un trigger temporaire maintient l'ancienne en synchronisation.
Un flux de migration pratique et répétable
L'approche la plus sûre est de faire de petits changements que vous pouvez annuler. Pensez « un changement, une preuve » en cycles, pas une réécriture de week-end.
La boucle répétable
Commencez par une migration minuscule qui ajoute quelque chose de nouveau sans supprimer l'ancien. Prouvez que l'app fonctionne, puis passez à la suivante.
- Ajoutez la table/colonne/index souhaité(e) (laissez l'ancienne structure en place).
- Backfillez les données de manière contrôlée (en lots si la table est volumineuse).
- Vérifiez les comptes et relations (lignes copiées, clés étrangères correspondent, pas de NULL inattendus).
- Basculez d'abord les lectures (mettez l'app pour lire la nouvelle structure), puis surveillez.
- Basculez les écritures (double-écriture brève si nécessaire), puis supprimez l'ancien chemin.
Après chaque boucle, exécutez les actions utilisateurs principales en end-to-end sur staging : inscription/connexion, création de l'objet central (commande/projet/post), et toute étape de paiement ou d'email. Ces flux détectent les problèmes du type « la migration a fonctionné mais l'app est cassée ».
N'oubliez pas la performance
Le nettoyage peut silencieusement ralentir les choses. Après chaque changement, vérifiez les nouvelles requêtes lentes, les index manquants, et les requêtes qui ont cessé d'utiliser un index parce qu'un type de colonne a changé.
Gardez une note courte pour chaque migration avec (a) comment la rollbacker, et (b) ce que vous avez mesuré pour confirmer que tout est correct. Les équipes se bloquent quand elles changent trop de choses à la fois et ne peuvent pas savoir quelle étape a causé la panne.
Erreurs courantes qui causent des pannes pendant le nettoyage du schéma
Les pannes surviennent souvent quand la base devient plus stricte avant que les données ne soient prêtes. Si vous ajoutez des clés étrangères, des règles NOT NULL ou des index uniques trop tôt, la migration peut échouer sur les lignes existantes, ou l'app peut commencer à générer des erreurs après le déploiement.
Un autre piège est de changer la signification d'un ID. Les prototypes IA mélangent souvent IDs chaîne, entiers, et parfois emails comme identifiants. Passer user_id d'une chaîne à un entier (ou changer le format UUID) casse les jointures, les payloads API, les caches et tout code qui traite l'ID comme une chaîne. Si nécessaire, planifiez une transition avec des backfills soignés et une période de compatibilité.
Supprimer des tables « anciennes » trop tôt est aussi risqué. Même si l'UI principale est migrée, quelque chose lit souvent encore l'ancienne table : une page admin, un handler de webhook, ou un job nocturne.
Zones de casse faciles à manquer : jobs en arrière-plan, outils admin, pipelines d'analytics, imports/exports, et applications mobiles ou clients plus anciens appelant d'anciennes endpoints.
Les erreurs de sécurité peuvent aussi provoquer des pannes. Les prototypes stockent parfois des tokens d'auth, clés API ou liens de reset en clair. Plus tard, quelqu'un ajoute du chiffrement ou des règles d'expiration et les connexions échouent. Traitez les secrets comme des matières dangereuses : faites rotation, expirez et migrez avec un basculement clair.
Exemple : vous ajoutez une contrainte unique sur users.email, mais la table contient [email protected] et [email protected]. Les connexions en production échouent parce que l'étape de nettoyage (normalisation et dédoublonnage) a été sautée.
Checklist rapide avant et après chaque changement
Le plus grand risque n'est pas le SQL. C'est de modifier les règles de données alors que l'app exécute encore des flux réels. Utilisez cette checklist à chaque modification de schéma, même si elle vous semble mineure.
Avant de changer quoi que ce soit
- La sauvegarde est confirmée, et un test de restauration a réussi (même si c'est sur une copie locale).
- Votre carte d'entités est à jour (tables, champs clés et relations) et quelqu'un d'autre l'a revue.
- Les doublons et sources de vérité conflictuelles sont supprimés ou clairement dépréciés (plus d'écritures nouvelles).
- Vous avez vérifié la propreté des données pour la contrainte suivante (NULLs, lignes orphelines, valeurs invalides).
- Un plan de rollback est rédigé pour ce changement précis (ce que vous annulez en premier, et comment vérifier la sécurité).
Prenez une minute pour écrire le rayon d'impact : quels écrans ou endpoints API cassent si cette migration échoue.
Après le changement
- Exécutez les flux utilisateurs clés de bout en bout : inscription, connexion, et la transaction centrale de l'app.
- Confirmez que l'app lit depuis la nouvelle source de vérité (et ne retombe pas silencieusement sur les anciennes colonnes).
- Vérifiez que les contraintes sont bien appliquées (essayez d'insérer une ligne invalide en environnement de test).
- Consultez les logs pour de nouvelles erreurs de requêtes et des requêtes lentes.
- Mettez à jour la carte d'entités pour que le prochain changement parte de la réalité.
Scénario exemple : nettoyer users et orders dans un prototype
Problème fréquent : vous ouvrez la base et trouvez users, customers et accounts qui contiennent tous email, nom et champs ressemblant à un mot de passe. Les commandes pointent parfois vers customers.id, parfois vers users.id, et parfois ne stockent qu'une chaîne email.
Commencez par choisir une source de vérité pour l'identité. Si l'app a une connexion, users est généralement l'ancre la plus sûre. Conservez les autres tables pour l'instant, mais traitez-les comme des profils à fusionner.
Pour cartographier les IDs en sécurité, ajoutez une colonne temporaire comme customers.user_id et backfillez-la en faisant correspondre une valeur stable (souvent l'email normalisé). Pour les enregistrements non appariés proprement, créez une liste de revue et corrigez-les manuellement avant d'ajouter des contraintes.
Ensuite, regardez les commandes. Les prototypes répètent souvent les champs d'items dans orders (comme item_1_name, item_2_price) ou stockent un blob JSON dont la forme change. Créez order_items avec order_id, product_name, unit_price, quantity, et backfillez depuis les données existantes. Conservez les anciennes colonnes temporairement pour que l'app continue de fonctionner pendant la mise à jour des requêtes.
Après le nettoyage et le mappage des données, ajoutez les contraintes calmement :
- Ajoutez
NOT NULLseulement sur les champs que vous avez entièrement backfillés - Ajoutez des contraintes d'unicité (comme
users.email) après avoir supprimé les doublons - Ajoutez des clés étrangères (
orders.user_id -> users.id,order_items.order_id -> orders.id)
Enfin, testez ce que les utilisateurs ressentent immédiatement : connexion et réinitialisation de mot de passe, inscription (y compris « email déjà utilisé »), création de commandes et d'items, totaux de paiement et page historique des commandes.
Étapes suivantes : quand faire appel à un expert en remédiation
Si le nettoyage est encore dans un bac à sable, vous pouvez avancer prudemment et apprendre en chemin. Une fois que de vrais utilisateurs et de vraies données sont impliqués, le risque change vite. Une migration apparemment inoffensive peut casser les connexions, corrompre des commandes ou exposer des données privées.
Faites appel à une aide experte si l'authentification ou les permissions sont concernées, si vous gérez des paiements ou des factures, si vous stockez des données sensibles, si l'app est en production et l'indisponibilité est inacceptable, ou si la logique base/app est embrouillée.
Si vous déléguez, vous obtiendrez des résultats plus rapides si vous pouvez fournir : un dump de schéma et une sauvegarde récente, une courte liste des flux critiques (inscription, checkout, remboursements, actions admin), les plus grosses erreurs observées (requêtes lentes, migrations cassées, totaux inconsistants), et tout incident connu (doublons, enregistrements manquants, soucis de sécurité).
Si vous traitez un prototype IA cassé et avez besoin d'un examen de bout en bout (schéma, logique et sécurité ensemble), FixMyMess à fixmymess.ai se concentre sur la remédiation d'apps construites par l'IA et peut commencer par un audit de code gratuit pour identifier les problèmes les plus risqués avant toute migration.
Questions Fréquentes
Comment savoir si mon schéma est « désordonné » même si l'application fonctionne ?
Un schéma « désordonné » est celui pour lequel vous ne pouvez pas répondre avec certitude « quelle table est la source de vérité ? ». L'application peut fonctionner, mais toute modification devient risquée parce que les données sont dupliquées, les identifiants ne correspondent pas et les relations existent seulement dans le code au lieu d'être appliquées par la base de données.
Que faire avant d'exécuter des migrations sur une base prototype ?
Commencez par une sauvegarde complète et prouvez que vous pouvez la restaurer dans une base distincte. Ensuite, créez un environnement de staging qui reflète la production et exécutez vos flux utilisateurs critiques avant chaque migration pour détecter les régressions tôt.
Quels « flux critiques » faut-il tester pendant le nettoyage du schéma ?
Choisissez un petit ensemble de parcours utilisateurs de bout en bout qui représentent comment les utilisateurs obtiennent de la valeur : inscription/connexion, création de l'objet central, et toute étape de paiement ou d'email. Si ces flux passent en staging après chaque changement, vous avez beaucoup moins de chances d'envoyer une modification qui casse l'application.
Comment cartographier rapidement les entités et relations dans une app générée par IA ?
Faites une carte d'entités simple : listez les concepts centraux en langage clair, identifiez la clé primaire de chaque table, et esquissez comment les enregistrements se relient. Ensuite, suivez les lectures/écritures en cherchant les noms de tables et de colonnes dans le code pour savoir ce que l'application touche réellement.
Comment repérer des tables dupliquées ou des sources de vérité concurrentes ?
Repérez des tables qui représentent la même chose dans le monde réel avec des colonnes ou des noms légèrement différents, par exemple User vs Users vs user_profiles. Confirmez en échantillonnant des lignes et en vérifiant si la même personne/commande/équipe apparaît dans plusieurs tables sous des identifiants différents.
Quelle est la manière la plus sûre de corriger des IDs incohérents (UUID vs int, email comme ID, etc.) ?
Choisissez une clé interne et tenez-vous-y, généralement un champ unique comme users.id. Pour une transition, ajoutez une colonne de mappage temporaire, remplissez-la (backfill), mettez à jour le code pour utiliser la nouvelle clé, et conservez une période de compatibilité courte afin que l'ancien et le nouveau coexistent en sécurité.
Faut-il normaliser tout en une fois ou progressivement ?
Normalisez là où ça fait mal d'abord : les endroits qui provoquent des incohérences, des rapports erronés, des bugs d'auth/permissions, ou les tables qui croissent vite. Procédez graduellement : créez de nouvelles tables à côté des anciennes, backfillez, basculez les lectures puis les écritures, et ne supprimez l'ancien qu'après validation en trafic réel.
Quand dois-je ajouter des clés étrangères, NOT NULL et des contraintes d'unicité ?
Ajoutez les contraintes dans l'ordre qui reflète la réalité actuelle : commencez par des règles déjà vraies (comme NOT NULL si les données sont présentes), corrigez les lignes incorrectes avant d'ajouter des clés étrangères, et supprimez les doublons avant d'ajouter des contraintes d'unicité.
Pourquoi les nettoyages de schéma cassent-ils généralement à l'étape des requêtes/mises à jour et pas à la migration ?
Basculez d'abord les lectures pour que l'application puisse gérer brièvement les deux formes (ancienne et nouvelle), puis migrez les écritures quand les lectures sont stables. Si vous faites du double-écriture, gardez-la courte et enregistrez les divergences pour pouvoir les corriger avant de supprimer l'ancien chemin.
Quand dois-je faire appel à FixMyMess plutôt que de nettoyer le schéma moi-même ?
Faites appel à FixMyMess lorsque des utilisateurs réels ou de l'argent sont en jeu, notamment autour de l'authentification, des permissions, des paiements ou des données sensibles. Si vous héritez d'une base IA embrouillée, FixMyMess peut commencer par un audit de code gratuit, puis corriger le schéma, la logique et la sécurité avec une validation humaine.