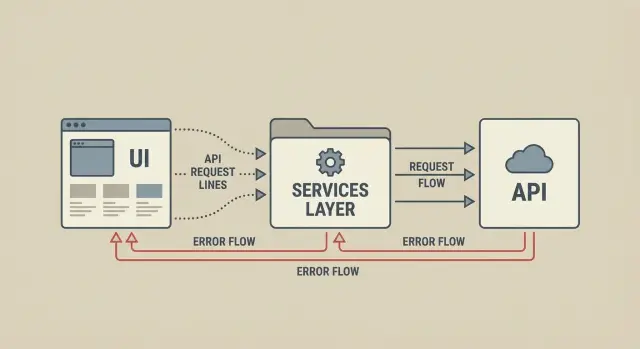
Couche service frontend : séparer les appels API des composants UI
Apprenez comment une couche service frontend déplace la logique fetch hors des composants, standardise les erreurs et rend les changements plus sûrs et plus rapides.
Pourquoi les appels API dans les composants deviennent des bugs
Un pattern courant en React (ou similaire) est un composant UI qui fait tout : il affiche l'écran, appelle fetch, construit les en-têtes, parse le JSON, gère les codes de statut et décide quel texte d'erreur afficher. Ça marche pour le premier endpoint, puis ça devient un fouillis à mesure que l'app grandit.
Quand chaque écran implémente sa propre logique de requête, vous dupliquez de petites décisions qui devraient être cohérentes. Un composant fait un retry sur 401, un autre déconnecte l'utilisateur. L'un envoie Content-Type: application/json, un autre l'oublie. L'un considère une réponse vide comme un succès, un autre plante sur await res.json().
C'est pour cela qu'une couche service frontend est importante. Elle vous donne un endroit unique pour définir comment votre appli parle à l'API, au lieu de redécider à chaque composant.
Un autre problème est le couplage caché. L'UI commence à dépendre de détails d'endpoints qui devraient être privés : URLs exactes, params de query, forme des en-têtes et formats de réponse. Plus tard, si le backend change user_id en id, vous ne modifiez pas un seul appel. Vous parcourez écrans, modaux et hooks en espérant ne rien avoir raté.
Les symptômes ressemblent souvent à ceci :
- Des en-têtes difficiles à mettre à jour (token d'auth, version de l'app, id du tenant)
- Des messages d'erreur aléatoires qui diffèrent selon les écrans
- Des bugs d'auth qui n'arrivent que dans certains parcours
- Des états de chargement bloqués après une exception
- Un comportement API qui “marche sur une page” seulement
Un petit exemple : un écran profil et un écran facturation récupèrent tous deux /me. L'un ajoute l'en-tête auth depuis le stockage local, l'autre utilise une valeur mémoire obsolète. Les utilisateurs voient “Please log in” sur facturation, mais le profil charge encore.
Si vous avez hérité d'un prototype généré par IA, c'est particulièrement courant : des fetch dispersés qui semblent corrects en démonstration, puis qui échouent en production dès que l'auth, les formats d'erreur et les cas limites apparaissent.
Qu'est-ce qu'une couche service (en clair)
Une couche service est un petit ensemble de fichiers qui gère la communication avec votre backend. Au lieu que chaque composant construise sa propre URL, ses en-têtes et son fetch, votre app fait des requêtes via des fonctions partagées comme getUser(), updateProfile() ou createInvoice().
Ce n'est pas un framework, et ça n'a pas besoin de dépendances supplémentaires. Pensez-y comme des modules JavaScript ou TypeScript simples qui se placent entre votre UI et le backend. Vous pouvez commencer par un seul fichier (par exemple apiClient.ts) et en ajouter d'autres à mesure que l'app grandit (par exemple authService.ts, billingService.ts).
Le but est simple : une manière cohérente d'appeler les APIs et une manière cohérente de traiter les résultats. Cela inclut les parties ennuyeuses qui causent la plupart des bugs : timeouts, en-têtes d'auth manquants, formes de réponse incohérentes et messages d'erreur qui changent d'une page à l'autre.
Les composants deviennent aussi plus simples. Ils ne s'occupent plus des détails HTTP. Ils demandent des données ou lancent des actions, puis affichent selon le résultat.
Au lieu de ce genre de code dans un composant :
const res = await fetch(`/api/users/${id}`, {
method: "GET",
headers: { Authorization: `Bearer ${token}` }
});
const data = await res.json();
if (!res.ok) throw new Error(data.message || "Failed");
Vous obtenez du code UI qui ressemble au flux utilisateur :
const user = await userService.getUser(id);
Cette différence compte surtout quand il faut changer quelque chose globalement (ajouter un en-tête, gérer un nouveau format d'erreur, changer d'endpoints). Avec une couche service, on change une fois, pas dans 15 composants.
Ce qui appartient à l'UI vs la couche service
Une règle simple : l'UI décide quoi afficher, et la couche service décide comment parler au serveur. Quand ces rôles se mélangent, les composants deviennent plus difficiles à lire et faciles à casser.
Dans l'UI, gardez le travail lié à l'écran : état local (loading, data, error), déclencher des actions au clic ou au chargement de la page, et afficher des retours comme toasts, erreurs inline et états vides. Le composant ne doit pas se soucier si la requête utilise fetch, quels en-têtes sont nécessaires, ou comment interpréter une erreur backend étrange.
Dans la couche service, mettez les parties qui doivent être cohérentes partout :
- Construction des requêtes (URL, méthode, en-têtes, token d'auth, body)
- Parsing des réponses (JSON vs corps vide, codes de statut)
- Conversion des échecs en un petit ensemble de types d'erreur que votre UI comprend
- Retourner une forme de résultat prévisible pour que chaque écran la gère de la même façon
Décidez tôt comment représenter les résultats. Une option courante : le service retourne soit { data } soit { error }, et l'UI gère l'état loading. Cela garde les services concentrés et la logique UI prévisible.
Le nommage compte aussi. Choisissez un style et gardez-le, par exemple userService.getProfile() (ce qu'il fait) ou ordersApi.create() (la ressource ciblée). Mélanger les styles rend le code plus difficile à retrouver plus tard.
Un exemple concret : si un formulaire de connexion doit afficher “Wrong password” vs “Network error”, le service devrait traduire les réponses brutes en INVALID_CREDENTIALS ou NETWORK. L'UI choisit ensuite le bon message.
Étape par étape : refactorer un appel API sans casser l'UI
Commencez petit. Choisissez un endpoint qui apparaît à plusieurs endroits, comme “get current user” ou “load projects”. Ils sont idéaux car vous pouvez prouver que le changement fonctionne en vérifiant deux écrans.
Supposons que vous avez fetch('/api/me') dupliqué dans un header et une page de paramètres. Votre objectif est de garder le comportement UI identique tout en déplaçant les détails réseau dans la couche service.
1) Déplacer le fetch dans une fonction de service
Créez un fichier comme services/userService.ts (le nom importe peu, cohérence oui).
// services/userService.ts
export async function getMe() {
const res = await fetch('/api/me', { credentials: 'include' });
const data = await res.json().catch(() => null);
if (!res.ok) {
return { ok: false, error: data?.error || 'Request failed', status: res.status };
}
return { ok: true, data };
}
Remarquez que la forme de retour est toujours prévisible : { ok: true, data } ou { ok: false, error }. Cette décision évite beaucoup de bugs du type “qu'est-ce que je vérifie ici ?”.
2) Remplacer les blocs anciens et garder le rendu UI identique
Mettez à jour chaque composant pour appeler getMe() et conservez les mêmes états de chargement, succès et erreur qu'avant.
Un chemin de refactor sûr :
- Remplacez le
fetchinline parawait getMe() - Mappez les anciennes mises à jour d'état vers le nouveau résultat (
if (result.ok) setUser(result.data) else setError(result.error)) - Conservez les mêmes spinners, toasts et états vides
- Testez les deux endroits qui utilisent l'endpoint
- Supprimez l'ancien code
fetchseulement ensuite
Avant de passer au endpoint suivant, confirmez que rien n'a changé pour l'utilisateur. Si vous héritez d'un prototype, c'est souvent là que des incohérences cachées apparaissent (formes JSON mélangées, hypothèses d'auth fragiles).
Standardiser la construction des requêtes
Quand chaque composant construit sa propre requête, de petites différences s'accumulent : l'un oublie l'en-tête auth, un autre envoie le mauvais content-type, un autre utilise une base URL légèrement différente. Une couche service règle ça en vous donnant une porte unique vers l'API.
Commencez par un wrapper de requête unique (un client API) qui gère les détails ennuyeux. Les composants ne devraient fournir que ce qui est unique : endpoint, méthode et données éventuelles.
Un bon constructeur de requêtes gère en général, en un seul endroit :
- URL de base et en-têtes communs (comme
Accept: application/json) - Tokens d'auth (lecture depuis le stockage, attachement à l'en-tête, rafraîchissement optionnel)
- Timeouts et IDs de requête (pour éviter les appels bloqués et pouvoir tracer les problèmes)
- Query params (encodés de façon cohérente)
- Corps JSON (stringifié de façon cohérente, avec le bon content-type)
L'auth est souvent le plus grand gain. Au lieu d'éparpiller la logique Authorization dans l'UI, faites en sorte que le client attache automatiquement le token. Si votre token peut expirer, gardez le comportement de refresh dans le client aussi. Ainsi, un écran profil et un écran facturation se comportent pareil, et un changement d'auth devient une seule modification.
Soyez strict sur la façon de passer params et body. Par exemple, décidez que les requêtes GET prennent params et que les POST/PUT prennent body, et que le client l'impose. Cela évite le bug courant “pourquoi le serveur reçoit un body vide ?”.
Exemple concret : un champ “Search users” pourrait appeler searchUsers({ q, page }). L'UI fournit juste q et page. Le client transforme ça en GET /users/search?q=...&page=..., ajoute les en-têtes, attache l'auth, applique un timeout et ajoute un request ID. Si vous déplacez ensuite l'API vers un nouveau domaine, seule l'URL de base change.
Standardiser les réponses et la gestion des erreurs
Quand chaque composant décide ce que signifie “succès”, l'UI finit pleine de petites règles : parfois on lit data, parfois user, parfois on vérifie ok. Une couche service fonctionne mieux quand elle retourne toujours la même forme à l'UI, pour que les composants restent simples.
Normaliser les réponses réussies
Choisissez un contrat pour ce que l'UI reçoit. Les fonctions de service devraient soit retourner la charge utile parsée directement, soit retourner une enveloppe cohérente comme { data, meta }. La plupart des équipes gardent le code UI plus propre en retournant directement la payload.
Soyez strict à ce sujet. Si un endpoint renvoie { user: {...} } et qu'un autre renvoie { data: {...} }, normalisez-les dans le service afin que le composant reçoive toujours le même type de valeur.
Créer un format d'erreur unique que l'UI peut afficher
Ne lancez pas des chaînes aléatoires à un endroit et des objets Response à un autre. Définissez un seul objet d'erreur que l'UI peut rendre sans deviner.
export type ApiError = {
kind: "auth" | "forbidden" | "not_found" | "rate_limited" | "server" | "network" | "unknown";
message: string;
status?: number;
requestId?: string;
};
Ensuite, mappez les codes de statut courants en un seul endroit pour que toute l'app se comporte de manière cohérente :
- 401 : demander à l'utilisateur de se reconnecter (kind:
auth) - 403 : afficher “Vous n'avez pas accès” (kind:
forbidden) - 404 : afficher “Introuvable” et arrêter les retries (kind:
not_found) - 429 : afficher “Trop de requêtes” et suggérer d'attendre (kind:
rate_limited) - 500+ : afficher un fallback calme et permettre une tentative (kind:
server)
Pour le débogage, loggez un contexte utile comme le statut, le nom de l'endpoint et un header request id si vous en avez un. Ne loggez pas les tokens ni les payloads qui pourraient contenir des secrets. Les utilisateurs doivent recevoir un message convivial, et les développeurs doivent avoir les détails.
Retries, caching et annulation sans encombrer l'UI
Une fois que les appels API vivent au même endroit, vous pouvez ajouter des fonctionnalités « qualité de vie » sans toucher chaque écran. L'UI reste concentrée sur les états de chargement et le rendu, tandis que le service gère les parties pénibles.
Cache simple pour éviter les doubles requêtes
Toutes les requêtes n'ont pas besoin de cache, mais un petit cache peut stopper des ennuis communs comme la requête répétée du même profil utilisateur à chaque changement d'onglet. Une approche pratique est un petit cache en mémoire avec une courte durée (par exemple 10 à 30 secondes) pour les lectures qui ne changent pas souvent.
Exemple concret : votre tableau de bord et la page de paramètres demandent tous deux /me. S'ils montent à proximité temporelle, vous pouvez retourner le résultat en cache au lieu d'envoyer deux requêtes et de laisser les réponses se concurrencer.
Retries, mais seulement quand c'est sûr
Les retries doivent être l'exception, pas la règle. Retenter une requête « lecture » (GET) après un problème réseau est généralement acceptable. Retenter une écriture (POST, PUT, DELETE) peut créer des doublons ou des changements non désirés.
Gardez les règles de retry dans la couche service pour que les composants n'inventent pas leur propre comportement :
- Retry uniquement sur les méthodes sûres (généralement GET) et seulement sur erreurs réseau ou réponses 5xx.
- Utilisez une petite limite (1 à 2 retries) et un court délai.
- Ne retentez jamais automatiquement les échecs d'auth (401).
Annulation pour navigation rapide et recherche
Si un utilisateur tape dans une barre de recherche ou navigue rapidement, les anciennes requêtes doivent s'arrêter. Sinon vous obtenez des résultats obsolètes qui clignotent à l'écran.
Utiliser AbortController dans la couche service garde l'annulation cohérente :
export function searchUsers(query, { signal } = {}) {
return api.get('/users/search', { params: { q: query }, signal });
}
Les composants passent simplement un signal et ignorent le reste. Le résultat est moins de conditions de course, moins d'avertissements sur les mises à jour d'état après démontage, et un code UI plus propre.
Erreurs courantes à éviter
Une couche service est censée simplifier votre UI. La plupart des problèmes surviennent quand elle grandit sans frontière claire et que les gens perdent confiance.
Un piège courant est de transformer la couche service en dépôt général. Si votre “service” commence à décider quel bouton doit être désactivé ou à définir l'apparence d'un écran, ce n'est plus un service. Gardez-le focalisé sur la communication avec le serveur et la mise en forme des données en quelque chose que l'app peut utiliser.
Une autre erreur est de retourner les objets Response bruts du fetch à l'UI. Cela force chaque composant à se souvenir quand appeler json(), comment vérifier ok et que faire des codes de statut. L'UI doit recevoir des données simples (ou une erreur claire), pas un objet réseau bas-niveau.
Surveillez la dérive des noms et des formes. Si une fonction retourne { user }, une autre { data: user } et une troisième user directement, les bugs deviennent invisibles jusqu'à l'exécution. Choisissez un pattern et tenez-vous-y à travers les fichiers.
Les erreurs sont l'endroit où beaucoup d'apps deviennent confuses. Si le service attrape les erreurs et retourne null ou un tableau vide “pour être sûr”, l'UI ne peut pas réagir correctement. L'UI doit connaître la différence entre “aucun résultat” et “requête échouée”.
Enfin, évitez de coupler les services à un écran unique. Si vous nommez des fonctions d'après des pages (comme getSettingsPageData) ou glissez des hypothèses UI dans les paramètres, la réutilisation devient plus difficile et les refactors plus lents.
Checklist rapide avant de merger
Faites une passe rapide pour la cohérence. Une couche service ne paye que si tout le monde suit les mêmes règles, même sur de petits changements.
- Les composants UI appellent une fonction de service, pas
fetchou un client brut directement. - Chaque fonction de service a un contrat évident : entrée claire et forme de sortie unique.
- Les erreurs sont traduites en un petit ensemble de types ou messages applicatifs en un seul endroit.
- Les détails partagés de requête vivent dans un seul endroit : URL de base, en-têtes d'auth, params communs, timeouts.
- Rien de sensible n'est hardcodé dans le frontend (tokens, clés API, identifiants temporaires).
Un contrôle simple : ouvrez un composant mis à jour et demandez-vous « Pourrais-je changer l'endpoint sans toucher ce fichier UI ? ». Si la réponse est non, la frontière fuit probablement.
Exemple : nettoyer un prototype avec des fetch dispersés
Un pattern courant dans les prototypes générés par IA (avec des outils comme Lovable, Bolt, v0, Cursor ou Replit) est le même bloc fetch copié dans de nombreux composants. Un écran a un en-tête légèrement différent. Un autre parse le JSON différemment. Un troisième affiche un toast pour les erreurs, les autres échouent silencieusement. Tout marche en demo, puis casse dès que vous ajoutez une vraie auth, de vraies erreurs et de vrais utilisateurs.
Dans un prototype, fetch était dupliqué dans 12 composants. Les bugs étaient petits mais constants :
- Dérive des en-têtes d'auth : certains appels utilisaient
Authorization, d'autres un header custom, quelques-uns l'oubliaient. - Parsing incohérent : un appel attendait
{ data: ... }, un autre utilisait le JSON brut, un autre ne vérifiait jamaisres.ok. - Messages utilisateurs aléatoires : certains écrans affichaient “Something went wrong”, d'autres diffusaient le texte du serveur, d'autres ne faisaient rien.
Le premier refactor a été volontairement petit. Au lieu de réécrire l'app, nous avons créé un apiClient puis deux services ciblés : authService (login, refresh, utilisateur courant) et projectService (list, create, update).
Avant, un composant ressemblait à ceci (simplifié) :
useEffect(() => {
fetch('/api/projects', {
headers: { Authorization: `Bearer ${token}` }
})
.then(r => r.json())
.then(setProjects)
.catch(() => toast('Error'));
}, [token]);
Après, l'UI ne demande que les données et gère l'état de chargement :
useEffect(() => {
projectService.list().then(setProjects).catch(showError);
}, []);
Le gain apparaît vite. L'UI est plus courte, et les règles vivent en un seul endroit : comment les en-têtes sont construits, comment le JSON est parsé et comment les erreurs sont formées. Quand le backend change (par exemple il commence à renvoyer items au lieu de data), vous corrigez une seule fois dans la couche service et tous les écrans se mettent à jour ensemble.
Étapes suivantes : rester cohérent et demander de l'aide au besoin
Une couche service ne paye que si tout le monde l'utilise. La façon la plus rapide de maintenir les bénéfices est d'en faire le chemin par défaut pour tout nouveau travail sur l'API. Si quelqu'un a besoin de données, il doit regarder la fonction de service, pas écrire un nouveau fetch dans un composant.
Écrivez de petits tests pour les fonctions de service. Vous n'avez pas besoin d'une grosse suite. Vous voulez juste une preuve que le chemin heureux fonctionne et que les erreurs prennent la forme attendue par l'UI.
La documentation peut être légère, mais elle doit être facile à suivre. Une courte liste de noms de fonctions approuvés évite les doublons comme getUser, fetchUser et loadUser qui font la même chose avec des comportements légèrement différents.
Si vous traitez une base de code générée par IA avec des fetch dispersés, une auth incohérente ou des problèmes de sécurité (comme des secrets exposés), FixMyMess (fixmymess.ai) peut aider. Ils se spécialisent dans le diagnostic et la réparation d'apps générées par IA, y compris le refactoring des couches de requêtes, le durcissement de la sécurité et la préparation des projets pour la production.
Questions Fréquentes
Pourquoi les appels API dans les composants UI causent-ils autant de bugs ?
Parce que chaque composant finit par prendre des décisions légèrement différentes sur les en-têtes, le parsing, les retries et les messages d'erreur. Ces petites différences créent des bugs qui n'apparaissent que sur certains écrans ou parcours, surtout autour de l'auth et des cas limites.
Qu'est-ce qu'une couche service frontend, en termes simples ?
Une couche service est un petit ensemble de fonctions partagées qui s'occupent de parler au backend, comme getMe() ou createInvoice(). Les composants appellent ces fonctions et se concentrent sur l'état et le rendu plutôt que sur les détails HTTP.
Qu'est-ce qui appartient à l'UI vs la couche service ?
L'UI doit gérer le comportement de l'écran : états de chargement, clics de boutons et quel message afficher. La couche service doit gérer la construction des requêtes, le parsing des réponses et la traduction des échecs en une forme d'erreur prévisible que l'UI peut traiter.
Quelle est la façon la plus sûre de refactorer un appel API en service sans casser l'UI ?
Commencez par un endpoint utilisé à plusieurs endroits, comme /me ou la liste de projets. Déplacez le fetch dans une fonction de service qui retourne toujours un résultat prévisible, puis remplacez progressivement chaque composant pour qu'il l'utilise tout en conservant le même rendu.
Quelle forme de retour les fonctions de service devraient-elles utiliser ?
Utilisez une forme de retour cohérente partout, par exemple { ok: true, data } et { ok: false, error, status }. Le grand avantage est que les composants n'ont plus à deviner quoi vérifier, donc les flux d'erreur et de succès restent cohérents entre les écrans.
Comment standardiser les en-têtes, l'URL de base et la gestion de l'auth ?
Créez un wrapper de requête unique (un client API) qui gère l'URL de base, les en-têtes communs, l'attachement du token d'auth, l'encodage JSON et les timeouts. Ensuite, toutes les fonctions de service appellent ce wrapper pour que vous changiez le comportement partagé à un seul endroit au lieu de multiples composants.
Comment gérer les formes de réponse backend incohérentes ?
Normalisez les réponses dans la couche service pour que l'UI reçoive toujours le même type de payload, même si le backend renvoie des formes différentes selon les endpoints. Cela évite aux composants de coder en dur des détails backend comme data vs user vs items.
Quelle est une bonne façon de standardiser la gestion des erreurs ?
Définissez un objet d'erreur au niveau de l'app et mappez les erreurs HTTP et réseau vers cet objet en un seul endroit. Ainsi, l'UI peut afficher le bon message sans deviner, et vous évitez de lancer des chaînes aléatoires ou de fuir des objets bas-niveau Response dans les composants.
Dois-je ajouter des retries, du cache et l'annulation des requêtes dans la couche service ?
Les retries sont généralement sûrs uniquement pour les requêtes en lecture (GET) et seulement pour des erreurs réseau ou des 5xx, avec une petite limite. La cancellation vaut le coup pour la recherche et la navigation rapide ; garder la gestion d'AbortController dans la couche service évite les résultats obsolètes et les warnings de mise à jour d'état après démontage.
Comment FixMyMess aide-t-il si mon prototype généré par IA a des fetch dispersés et des bugs d'auth ?
Ce pattern est très courant : des blocs fetch copiés dans de nombreux composants avec dérive dans les en-têtes, le parsing et les hypothèses d'auth qui ne fonctionnaient qu'en démonstration. Si vous avez hérité d'une app générée par IA, FixMyMess peut auditer le code gratuitement et refactorer rapidement la couche de requêtes, corriger les bugs d'auth et durcir la sécurité pour la production.