Timeouts et retries d'API : limites raisonnables pour les appels tiers
Les timeouts et retries d'API empêchent qu'une API tierce lente ne fige votre application. Définissez des timeouts raisonnables, un backoff exponentiel, des limites de retry et des valeurs par défaut sûres.
Pourquoi des API tierces lentes peuvent geler votre app
Un appel à une API tierce semble anodin jusqu'à ce que chaque requête en dépende. Quand ce fournisseur ralentit, votre app commence à attendre, et attendre. Les utilisateurs voient des spinners sans fin. Les jobs en arrière-plan ne se terminent plus. Rien ne « plante », mais tout paraît bloqué.
La plupart des apps fonctionnent avec une capacité limitée : un nombre fixe de threads web, des créneaux de concurrence serverless, ou des workers de file. Quand une requête bloque sur un fournisseur lent, elle prend en otage cette capacité. Une poignée d'appels lents peut devenir un embouteillage où le nouveau travail ne peut même pas démarrer.
Les requêtes bloquées se manifestent généralement par un schéma :
- Les requêtes web restent en attente jusqu'à ce que le navigateur time out, même si vos serveurs semblent « up ».\n- Les workers restent occupés mais n'achèvent pas les jobs, donc la file grossit.\n- Un endpoint commence à consommer la plupart de vos threads (ou connexions DB) parce qu'il attend un appel externe.\n- Les retries s'enclenchent aveuglément, répétant le même appel lent et accélérant l'accumulation.
Les timeouts et les retries ont un but : échouer vite, retenter en sécurité, et récupérer proprement. Un timeout clair empêche un fournisseur lent de geler tout le système. Des retries conservateurs vous aident à vous remettre de petits incidents sans créer une panne auto-infligée.
C'est surprenant parce que les valeurs par défaut des clients HTTP sont souvent trop permissives. Certaines sont réglées sur de très longs timeouts, et d'autres attendent effectivement indéfiniment sauf si vous définissez à la fois les timeouts de connexion et de lecture. Beaucoup de prototypes générés par IA sortent avec ces paramètres, donc le système fait exactement ce qu'on lui a dit : continuer d'attendre.
Une fois que vous traitez chaque appel tiers comme un goulet potentiel, vous pouvez concevoir l'app pour qu'elle se dégrade proprement : afficher un message utile, mettre la tâche en file pour plus tard, ou basculer sur un fallback au lieu de laisser tout s'engorger.
Termes clés : timeouts, retries, backoff et limites
Si vous voulez des intégrations tierces fiables, soyez clair sur quatre bases : combien de temps vous attendez, si vous retentez, comment vous espacez les tentatives, et quand vous abandonnez.
Timeouts (les différentes « horloges »)
Un timeout est une règle stricte : « Si nous n'avons pas progressé après X secondes, arrêtez et rendez la main à l'app. » Types courants :
- Connect timeout : combien de temps attendre pour ouvrir une connexion (DNS, handshake, chemin réseau). Cela détecte vite les réseaux morts.\n- Read timeout : combien de temps attendre des données une fois la connexion établie. C'est là que les fournisseurs lents vous pénalisent souvent.\n- Total/request timeout : le temps maximum pour tout l'appel, du début à la fin. C'est votre filet de sécurité final.
Sans timeouts, un fournisseur lent peut bloquer des threads serveurs ou des workers jusqu'à ce que tout s'accumule.
Retries (réessayer) vs. timeouts (arrêter)
Un retry est une nouvelle tentative après un échec. Les retries ne remplacent pas les timeouts. Des retries sans timeouts peuvent être pires que pas de retries du tout, car vous pouvez accumuler plusieurs requêtes bloquées au lieu d'une seule.
Les retries aident pour des problèmes temporaires : timeouts brefs, erreurs 502/503, et pépins réseau. Ils sont risqués pour les échecs « réels » comme des identifiants incorrects ou des requêtes invalides, où répéter ne résoudra rien.
Backoff et jitter (attendre intelligemment)
Backoff signifie attendre plus longtemps entre chaque retry (par exemple : 1s, puis 2s, puis 4s). Jitter signifie ajouter un petit délai aléatoire pour que plusieurs clients ne relancent pas exactement en même temps et ne surchargent pas à nouveau le fournisseur.
Limites de retry (quand abandonner)
Une limite de retry plafonne les tentatives. « Abandonner » doit être un résultat propre : afficher un message comme « Ce service est lent en ce moment, réessayez plus tard », préserver l'état utilisateur (panier, brouillon, données de formulaire), et logger l'échec pour le suivi au lieu de tourner en boucle.
Choisir des valeurs de timeout sensées
Les timeouts ne sont pas un seul chiffre à copier partout. Choisissez-les par fournisseur et par type d'appel, en fonction de ce qui est acceptable pour les utilisateurs et de ce que votre système peut tolérer quand un fournisseur ralentit.
Un point de départ pratique consiste à séparer « puis-je me connecter ? » de « puis-je obtenir une réponse ? » Beaucoup de clients HTTP permettent de régler les deux.
Plages typiques de départ :
- Connect timeout : 0,2 à 1s pour la plupart des API publiques, jusqu'à 2s si vous prévoyez des lenteurs réseau occasionnelles.\n- Read/response timeout : 2 à 10s pour les requêtes typiques ; 15 à 30s seulement pour des endpoints connus pour être longs (rapports, exports).\n- Appels d'écriture (créer un prélèvement, créer une commande) : gardez des timeouts modestes (souvent 5 à 10s) et comptez sur des règles de retry sûres plutôt que d'attendre indéfiniment.\n- Polling/vérifications de statut : timeouts courts (2 à 5s) et moins de retries.
Les requêtes côté utilisateur doivent être plus strictes que les jobs en arrière-plan. Si une page de checkout attend, limitez l'appel tiers à 3–5 secondes et affichez un message de repli clair. Si une synchronisation nocturne s'exécute en background, elle peut attendre plus longtemps, mais elle doit quand même avoir des limites pour ne pas accumuler des workers bloqués.
Fixez aussi un délai global pour l'opération entière, y compris les retries. Par exemple : « Tenter au total pendant 20 secondes, puis échouer. » Sans cela, des retries peuvent prolonger discrètement un appel de 5 secondes en un problème de 2 minutes.
Écrivez vos hypothèses pour que la personne suivante ne doive pas deviner :
- Latence typique observée chez le fournisseur (p50 et p95)\n- Tolérance UX (combien de temps un utilisateur attendra avant d'abandonner)\n- Temps total maximum que vous consacrerez incluant les retries\n- Quels endpoints peuvent être plus lents, et pourquoi
Quand retenter (et quand ne pas le faire)
Les retries servent pour des problèmes qui ont de bonnes chances de se résoudre rapidement. Si la requête est incorrecte, retenter ne fait que perdre du temps et peut aggraver la panne.
Les retries ont du sens pour des échecs transitoires : connexion tombée, pépin DNS, ou timeout. Ils peuvent aussi convenir pour du throttling (429) et certains 5xx, car le fournisseur peut être surchargé.
Règle simple :
- Retenter sur erreurs réseau, timeouts, 429 et certains 5xx (502/503/504).\n- Ne pas retenter la plupart des 4xx (400, 401/403, 404) tant que quelque chose ne change pas.\n- Respecter le header Retry-After quand l'API le fournit.\n- Arrêter tôt si vous obtenez un message d'erreur permanent clair.
Soyez prudent avec les requêtes à « issue inconnue ». Si vous timez out après l'envoi d'un prélèvement, retenter peut créer des doublons à moins d'utiliser des clés d'idempotence ou un token de commande.
Une approche pratique sépare deux patterns :
- Un retry rapide pour de faibles incidents (un seul retry rapide après ~100–200 ms).\n- Une courte séquence de backoff pour du throttling ou des pannes partielles (quelques tentatives avec délais croissants).
Cela garde l'app réactive tout en permettant de récupérer quand le fournisseur a juste besoin d'un moment.
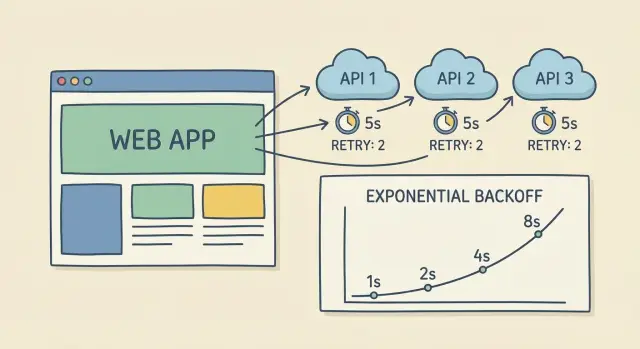
Backoff exponentiel avec jitter, expliqué simplement
Quand un appel échoue ou time out, relancer immédiatement aggrave souvent la situation. Le backoff exponentiel signifie attendre un peu, puis de plus en plus longtemps à chaque fois. Cela réduit la pression sur le fournisseur et lui donne le temps de récupérer.
Une progression simple (avec un plafond pour ne pas traîner) :
- Essai 1 : attendre 0,25s\n- Essai 2 : attendre 0,5s\n- Essai 3 : attendre 1s\n- Essai 4 : attendre 2s (plafond)
Le jitter ajoute un petit offset aléatoire. Sans lui, des milliers de clients peuvent relancer aux mêmes instants (exactement une seconde plus tard), créant un nouveau pic et une nouvelle vague d'échecs. Avec du jitter, un client attendra 0,8s pendant qu'un autre attend 1,3s, donc les retries se répartissent.
Deux garde-fous importent :
- Plafonner le délai maximum (souvent 2 à 5 secondes).\n- Garder peu d'essais et prévisibles, généralement 2 à 4 retries.
Ainsi, le pire scénario est facile à raisonner et on évite des files cachées de travail bloqué.
Rendre les retries sûrs : idempotence et prévention des doublons
Les retries peuvent vous sauver lors de pépins réseau, mais ils peuvent aussi créer du bazar. Si vous retentez une action non idempotente (comme « prélever une carte » ou « créer une commande »), le même clic peut s'exécuter deux fois. C'est comme ça qu'on obtient des doubles prélèvements, des comptes dupliqués, ou deux expéditions.
Règle simple : ne retentez que les appels sûrs à répéter. Les lectures (GET) sont généralement sûres. Les écritures (POST qui crée ou prélève) nécessitent des protections avant d'activer les retries.
Utiliser des clés d'idempotence quand le fournisseur les propose
Beaucoup d'API de paiement, messagerie et commande acceptent une clé d'idempotence. Générez une clé unique pour l'action utilisateur (par exemple une tentative de checkout) et réutilisez-la à chaque retry. Le fournisseur renverra alors le même résultat au lieu d'exécuter l'action une nouvelle fois.
Conservez cette clé avec la réponse, et gardez-la stable même si l'utilisateur rafraîchit la page.
Ajouter votre propre déduplication quand le fournisseur ne le fait pas
S'il n'y a pas de mécanisme d'idempotence, vous pouvez quand même éviter les doublons côté serveur. Faites simple :
- Créez un « enregistrement de requête » avec un
request_idunique avant d'appeler le fournisseur.\n- Appliquez une contrainte d'unicité (par ex.user_id + cart_id + action_type).\n- Stockez la réponse du fournisseur (succès ou échec) et réutilisez-la sur les retries.\n- Ajoutez une courte TTL pour ne pas bloquer des achats légitimes ultérieurs.\n- Loggez un ID de requête stable pour que le support puisse tracer bout en bout.
Exemple : lors du checkout, la première tentative de prélèvement time out mais le fournisseur le traite ensuite. Si vous retentez sans idempotence ni déduplication, vous risquez de prélever deux fois. Avec un request_id stable, vous pouvez retenter en sécurité et afficher un résultat final unique.
Stopper les échecs qui s'emballent : caps, circuit breakers et fallbacks
Les retries aident quand un fournisseur a un bref incident. Si le fournisseur est down ou très lent, les retries peuvent transformer un petit problème en une inondation de requêtes bloquées. L'objectif n'est pas « ne jamais échouer », mais « échouer de façon contrôlée » pour que votre app reste utilisable.
Mettre des caps stricts sur chaque appel
Chaque appel externe a besoin de limites qui coupent le problème rapidement. Gardez la liste courte et appliquez-la systématiquement :
- Tentatives max (par exemple, 3 tentatives au total)\n- Temps écoulé max (par exemple, arrêter après 10 secondes au total)\n- Appels concurrents max (éviter 500 requêtes qui s'accumulent en même temps)\n- Définition stricte de ce qui est retentable (seules les erreurs qu'on s'attend à récupérer)
Ces caps empêchent un fournisseur lent de geler votre serveur web, d'accumuler la file ou d'épuiser vos quotas.
Utiliser un circuit breaker quand un fournisseur échoue
Un circuit breaker est une règle simple : si trop d'appels échouent dans une courte fenêtre, pausez les appels pendant un moment. Pendant la pause, renvoyez une réponse contrôlée immédiatement au lieu d'attendre des timeouts. Après un refroidissement, autorisez un petit nombre d'appels tests pour vérifier si le fournisseur est revenu.
Cela aide à isoler une panne fournisseur du cœur de votre app. Les utilisateurs peuvent toujours se connecter, naviguer, et sauvegarder leurs progrès même si une intégration est malsaine.
Ajouter des fallbacks qui maintiennent le parcours utilisateur
Les fallbacks peuvent être aussi simples que des données mises en cache, un message « réessayez dans une minute », ou un mode dégradé qui saute une fonctionnalité non critique.
Exemple : si les tarifs d'expédition time out pendant le checkout, affichez un tarif par défaut ou permettez de passer la commande et confirmer l'expédition plus tard.
Étape par étape : ajouter timeouts et retries à une app existante
Commencez par rendre le comportement cohérent. Si chaque ingénieur définit des timeouts différemment (ou les oublie), un fournisseur lent peut encore bloquer toute l'app.
1) Centraliser vos valeurs par défaut HTTP
Créez un client HTTP partagé (ou un wrapper) et forcez tous les appels externes à passer par lui. Donnez-lui des valeurs par défaut sûres : timeout de connexion, timeout de réponse, et un plafond sur le temps total passé (y compris les retries). Loggez chaque requête avec le nom du fournisseur pour repérer les motifs.
Puis ajoutez une couche de politique par fournisseur. Paiements, email, cartes et modèles IA se comportent différemment, donc les mêmes règles de retry ne conviennent rarement à tous.
2) Ajouter des overrides par fournisseur qui correspondent à la réalité
Pour chaque fournisseur, définissez :
- Timeouts (courts pour endpoints rapides, plus longs uniquement si nécessaire)\n- Règles de retry (quels codes et erreurs réseau comptent)\n- Limites de retry (tentatives max et temps total max)\n- Gestion du rate-limit (respectez 429 et Retry-After avec un nombre limité de retries)
Gardez les retries conservateurs. Un fournisseur cassé doit échouer vite et libérer votre app.
3) Mesurer ce que ressent l'utilisateur
Suivez quelques métriques et révisez-les régulièrement : taux de timeout, retries par requête, succès après retry, et latence totale (incluant les attentes). Si les retries « fonctionnent » mais ajoutent 8 secondes au checkout, les utilisateurs le ressentent quand même.
4) Vérifier en forçant la lenteur
Testez en staging en simulant des réponses lentes et des connexions instables. Faites dormir un appel fournisseur 10 secondes et confirmez que votre app time out à 2 secondes, retry avec backoff, puis s'arrête à la limite. Testez aussi des pannes partielles où une requête sur trois échoue.
Erreurs courantes qui causent des requêtes bloquées
Les requêtes bloquées viennent souvent d'un problème racine : il n'y a pas de limite claire sur la durée pendant laquelle l'app continue d'essayer. Quand un fournisseur ralentit, les workers restent en attente et la file grossit jusqu'à ce que tout paraisse gelé.
Voici les motifs qui créent des accumulations en silence :
- Nombre de retries tellement élevé qu'il est presque infini.\n- Retries immédiats sans pause, surtout sous charge.\n- Pas de deadline globale, donc l'utilisateur attend plus longtemps pendant que vos serveurs restent pris.\n- Retenter des erreurs permanentes (clé API invalide, permissions manquantes, payload invalide) au lieu de corriger la requête.\n- Ignorer les rate limits (429), ce qui mène souvent à un throttling plus sévère.
Une modélisation utile : les retries sont pour des problèmes temporaires, pas pour des problèmes permanents. Quand un fournisseur est down ou lent, vous voulez moins d'essais, mais plus intelligents, pas l'inverse.
Ce que « sûr » signifie souvent : 2 à 3 essais supplémentaires, backoff exponentiel avec jitter, et un plafond strict pour l'opération entière (par exemple « arrêter après 10 secondes au total, quoi qu'il arrive »). Pour les 429, considérez le temps d'attente demandé par le fournisseur comme faisant partie du contrat.
Exemple réaliste : un fournisseur ralentit pendant le checkout
Imaginez un flux de checkout avec trois appels tiers : une API de paiement pour prélever la carte, une API d'expédition pour obtenir des tarifs en direct, et un fournisseur d'email pour envoyer le reçu.
Un après-midi, le fournisseur d'expédition ralentit. Votre app demande les tarifs, mais la requête reste bloquée 25–30 secondes. Le client regarde un spinner. Si votre serveur garde cette requête ouverte, vous bloquez des threads et d'autres checkouts s'accumulent derrière. Un fournisseur lent peut rendre tout le site inutilisable.
Un flux plus sûr :
- Paiements : timeout court ; ne pas retenter automatiquement après une tentative de prélèvement à moins de pouvoir prouver que c'est sûr.\n- Tarifs d'expédition : timeouter rapidement (par ex. 2–3s), retenter un petit nombre de fois avec backoff, puis arrêter.\n- Fallback : si l'expédition reste lente, afficher un tarif standard ou permettre à l'utilisateur de continuer et confirmer l'expédition plus tard.\n- Message utilisateur : « Nous n'avons pas pu charger les tarifs en direct. Vous pouvez toujours passer la commande, nous confirmerons l'expédition par email. »
Où les retries se produisent importe. Sur la page de checkout, gardez des timeouts serrés pour donner rapidement une réponse au client. Après la création de la commande, vous pouvez effectuer des retries plus longs en background (toujours avec des limites strictes) pour obtenir un tarif final et mettre à jour la commande sans retenir l'utilisateur.
Checklist rapide avant le déploiement
Avant de déployer, passez en revue chaque appel tiers (paiements, email, cartes, auth, expédition, fournisseurs IA). Le but est simple : un fournisseur lent ne doit pas geler votre app, et une brève panne ne doit pas générer une pile de requêtes bloquées.
Assurez-vous que chaque appel a :
- Un connect timeout court\n- Un read timeout raisonnable\n- Une deadline totale pour l'opération (incluant les retries)
Pour les retries :
- Retenter uniquement les échecs transitoires (timeouts, erreurs réseau temporaires, 429/5xx clairs)\n- Utiliser backoff exponentiel + jitter\n- Faire respecter les tentatives max et le temps écoulé max partout (client HTTP, file de jobs, workers)
Enfin, rendez les retries sûrs. Si une opération peut créer des doublons (prélèvements, commandes, création de compte), ajoutez des clés d'idempotence ou de la déduplication avant d'activer les retries.
La surveillance doit vous dire ce qui se passe par fournisseur : taux de timeout, taux de retry, et latence moyenne. C'est ainsi que vous détectez les problèmes tôt, avant qu'ils ne deviennent un gel côté utilisateur.
Prochaines étapes : stabiliser vos intégrations sans sur-ingénierie
Commencez par trouver les appels qui peuvent attendre indéfiniment. Recherchez les requêtes sans timeout explicite, les jobs en background qui retentent « jusqu'au succès », et les workers qui n'abandonnent jamais. Ce sont ceux qui s'accumulent en silence et transforment une petite lenteur fournisseur en panne.
Choisissez une ou deux API tierces critiques et terminez le pattern de bout en bout avant de toucher au reste. Critique signifie généralement flux d'argent, connexion, messagerie, ou tout ce qui bloque une action utilisateur. Implémentez un timeout clair, une politique de retry avec backoff, et une limite stricte de retry. Ajoutez des logs basiques pour pouvoir répondre : combien de fois avons-nous retenté, combien de temps avons-nous attendu, et avons-nous finalement réussi ?
Quand ça merde, la rapidité compte plus qu'un outillage parfait. Écrivez un petit playbook d'incident : comment désactiver temporairement un fournisseur (feature flag ou toggle de config), quoi afficher aux utilisateurs, quoi vérifier en premier (statut du fournisseur, taux d'erreur, profondeur des files), et quand réactiver.
Si vous avez hérité d'une codebase générée par IA avec des valeurs par défaut dangereuses, FixMyMess (fixmymess.ai) peut réaliser un audit de code gratuit pour repérer les timeouts manquants, les retries incontrôlés et les intégrations fragiles, puis aider à transformer le prototype en logiciel prêt pour la production avec des corrections vérifiées par des humains.
Questions Fréquentes
Pourquoi une seule API tierce lente peut-elle faire paraître toute mon application gelée ?
Votre application dispose d'une capacité limitée (threads web, créneaux serverless ou workers). Si une requête attend une API tierce lente sans timeout strict, elle occupe cette capacité et le nouveau travail ne peut pas démarrer, donc tout semble bloqué même si rien ne « plante » réellement.
Quels timeouts devrais-je définir pour la plupart des appels API tiers ?
Définissez un petit timeout de connexion et un timeout de lecture/response séparé, plus une durée totale maximale pour la requête. Un point de départ courant : 0,2–1s pour la connexion et 2–10s pour la réponse, à ajuster selon le fournisseur et la tolérance utilisateur.
Quelle est la différence entre un timeout et un retry ?
Un timeout arrête l'attente et rend la main à l'application. Un retry est une nouvelle tentative après un échec. En général, il vous faut les deux : des timeouts pour éviter les blocages et quelques retries pour récupérer des incidents brefs.
Quelles erreurs devrais-je retenter, et lesquelles éviter ?
Relancez uniquement les erreurs probablement temporaires : timeouts, problèmes réseau, 429 (rate limit) et certains 5xx. N'essayez pas de relancer la plupart des 4xx (mauvaise requête, clés invalides), car répéter n'arrangera rien.
Comment faire du backoff et du jitter sans empirer la situation ?
Utilisez un backoff exponentiel pour augmenter le délai entre les tentatives, et ajoutez du jitter pour éviter que tous les clients relancent en même temps. Gardez ça petit et prévisible : 2–4 retries avec un délai plafonné, afin de ne pas créer de longues attentes ou d'engorgements.
Pourquoi les retries peuvent-ils causer des doubles prélèvements ou des commandes dupliquées ?
Les retries peuvent répéter une action d'écriture si la première tentative a été réellement traitée par le fournisseur mais que vous n'avez pas reçu la réponse. Sans clés d'idempotence ou déduplication, vous risquez des doubles prélèvements, commandes en double, ou messages répétés.
Les timeouts doivent-ils être différents pour les requêtes web et les jobs en background ?
Pour des requêtes utilisateur (checkout), gardez des timeouts serrés et affichez une solution de repli claire si le fournisseur est lent. Pour les jobs en arrière-plan, vous pouvez attendre plus longtemps, mais avec des limites strictes pour éviter d'encombrer les workers.
Quand devrais-je ajouter un circuit breaker ?
Quand trop d'appels échouent dans une courte fenêtre, un circuit breaker suspend les appels pendant un temps. Pendant la pause, on renvoie une réponse contrôlée immédiatement au lieu d'attendre des timeouts à chaque fois. Utile quand un fournisseur est dégradé pour préserver le reste de l'app.
Pourquoi les prototypes générés par IA embarquent-ils souvent des paramètres HTTP dangereux par défaut ?
Beaucoup de clients HTTP ont des valeurs par défaut trop indulgentes, et certains attendent indéfiniment sauf si on définit explicitement les timeouts de connexion et de lecture. Les prototypes générés par IA conservent souvent ces valeurs, d'où des attentes interminables.
Quelle est la façon la plus rapide d'ajouter des timeouts et retries sensés à une application existante ?
Centralisez d'abord tous les appels sortants derrière un client partagé avec des valeurs sûres par défaut. Si vous héritez d'un code généré par IA et ne savez pas où manquent les timeouts/retries, FixMyMess peut effectuer un audit gratuit et corriger rapidement les intégrations avec des changements vérifiés par des humains.