Débogage des Web Vitals pour frontends générés par l'IA : corrections ciblées
Dépannage Web Vitals concret : identifier LCP, CLS et INP au niveau des composants, corriger les sauts de mise en page et vérifier les gains après chaque modification.
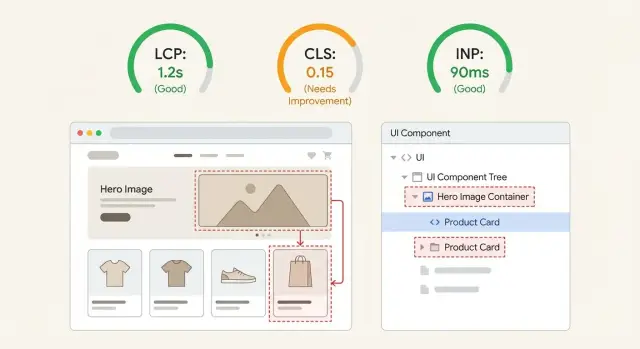
À quoi ressemblent les problèmes Web Vitals dans les applis réelles
De mauvais Web Vitals ne se ressentent pas souvent comme « un chiffre qui déconne ». On a plutôt l'impression que le site semble prêt, mais en fait ne l'est pas.
Quand LCP est mauvais, l'utilisateur regarde une zone vide ou un placeholder de mauvaise qualité trop longtemps, puis le contenu principal apparaît d'un coup. Parfois c'est visible, comme un titre hero qui s'affiche tard. Parfois c'est subtil, comme l'image produit qui met une éternité à charger alors que le reste est déjà visible.
Quand CLS est mauvais, la page bouge sous l'utilisateur. Vous essayez d'appuyer sur un bouton, et il se décale parce qu'une bannière s'est chargée, une police a été swapée, ou une image a enfin obtenu sa hauteur.
Quand INP est mauvais, la page a l'air chargée mais donne une impression de lenteur. Les taps et clics répondent après un temps, les saisies buggent, et les menus s'ouvrent en retard.
Les frontends générés par l'IA régressent souvent après de petites modifications parce que layout, fetchs de données et effets secondaires se retrouvent emmêlés dans les mêmes composants. Un changement « minime » comme ajouter un badge, swapper une police ou rendre conditionnellement une promo peut déplacer la mise en page initiale, retarder le plus grand élément, ou ajouter du travail pile au moment où l'utilisateur interagit.
L'objectif est simple : quand une métrique monte, vous voulez pouvoir dire « c'est cet élément dans ce composant, et c'est pire depuis ce changement ». Ça rend les corrections plus sûres, plus faciles à répéter et à vérifier.
Mettre en place une baseline répétable avant tout changement
Le travail de perf n'a d'intérêt que si vous pouvez prouver que vous avez amélioré les choses.
Commencez par garder votre setup constant : Chrome (stable), DevTools, et une build proche de la production (minifiée, mêmes feature flags, mêmes endpoints API si possible). Choisissez une page de test stable où le contenu ne change pas beaucoup entre les runs. Si votre app nécessite une connexion, créez un compte test dédié avec des données constantes.
Limitez le périmètre à 1–3 pages à fort impact. Pour beaucoup de frontends générés par l'IA, c'est une page publique d'atterrissage (première impression), une page pricing (conversion), et un flux « payant » comme le checkout ou un écran clé du dashboard. Si vous essayez de tout corriger en même temps, difficile de savoir ce qui a aidé.
Gardez les runs comparables. Utilisez le même appareil à chaque fois, le même profil réseau dans DevTools, et les mêmes étapes (onglet neuf, reload complet, mêmes clics). Même de petites différences, comme une extension injectant des scripts ou un dataset différent, peuvent faire varier INP et CLS par hasard.
Notez votre baseline en langage simple :
- Date, page, build/commit
- Nombres LCP/CLS/INP observés
- Une phrase sur ce qui semblait erroné (ex : « l'image hero apparaît en poussant le titre vers le bas »)
Cette note est votre réalité plus tard, surtout sur des UIs générées par l'IA où un « fix » peut déplacer le problème vers un autre composant.
Données de terrain vs données de labo : quand utiliser chacune
Le débogage va plus vite quand vous séparez deux questions : « qu'est‑ce que ressentent les vrais utilisateurs ? » et « qu'est‑ce que je peux reproduire et corriger aujourd'hui ? ». Les données de terrain répondent à la première. Les données de labo à la seconde. Vous avez généralement besoin des deux pour ne pas courir après la mauvaise chose.
Les données de terrain (RUM, analytics ou type Chrome UX Report) montrent les tendances sur appareils, réseaux, routes et comportements. C'est la meilleure façon de confirmer si LCP, CLS ou INP sont réellement mauvais en production, et pour quelles pages.
Les données de labo (Lighthouse, enregistrements Performance dans DevTools, tests réseau throttlés) sont là où vous faites le travail. Elles permettent de rejouer le même scénario, d'inspecter ce qui a peint, et de voir quelle tâche a bloqué l'entrée. Les résultats de labo peuvent être bruyants, mais ils sont contrôlables.
Une façon pratique de les combiner :
- Utilisez les données de terrain pour choisir le template de page le plus impactant et la métrique la plus mauvaise (par ex. CLS mobile sur la landing).
- Reproduisez en labo et enregistrez jusqu'à pouvoir déclencher le même type de saut ou retard.
- Corrigez une seule chose à la fois : un composant, une image, ou un comportement de script.
- Vérifiez deux fois : le labo doit s'améliorer immédiatement, le terrain s'améliorera au fil du temps quand les utilisateurs auront la nouvelle version.
Si vous ne pouvez choisir qu'une source pour décider quoi livrer, faites confiance d'abord à un problème reproductible en labo et utilisez le terrain comme confirmation.
Comment tracer le LCP jusqu'à l'élément exact et au composant
Le LCP est souvent une grosse chose que l'utilisateur attend : une image hero, un titre, une carte produit, ou un bloc d'en‑tête complet. Le travail consiste à identifier cet élément précis, puis remonter au composant et à ce dont il dépend.
Trouver l'élément LCP dans un trace Performance
Dans Chrome DevTools, enregistrez un trace Performance en chargeant la page (incognito aide, et utilisez un profil réseau normal). Dans le trace, cherchez le marqueur LCP, puis cliquez‑le pour voir l'élément reporté.
Un flux simple qui marche sur la plupart des frontends IA :
- Démarrez l'enregistrement Performance, puis rechargez la page.
- Trouvez le marqueur LCP sur la timeline.
- Cliquez‑le et notez l'élément LCP (balise, taille, et toute URL d'image).
- Utilisez le nœud surligné pour y sauter dans le DOM.
- Identifiez à quel bloc UI il appartient (hero, header, carte au‑dessus du pli).
Le mapper au composant et à ses dépendances
Une fois l'élément connu, demandez‑vous où il est rendu. Dans des apps React/Next.js, c'est souvent un composant Hero qui récupère des données, charge une image et applique des styles.
Si l'élément LCP est une image, vérifiez si elle est servie à la bonne taille et si elle commence à se télécharger assez tôt. Si c'est du texte, faites attention aux polices et au CSS.
Dressez ensuite la liste de ce dont le composant a besoin avant de pouvoir rendre. Causes courantes :
- Une image hero surdimensionnée, ou une image sans dimensions
- CSS bloquantes ou fichiers de polices volumineux retardant le paint du texte
- Un fetch côté client qui bloque le hero (un état de chargement devient le « contenu »)
- Beaucoup de JavaScript au premier affichage (l'hydratation bloque le rendu)
Un pattern commun généré par l'IA est de construire le hero depuis un fetch client vers un CMS, ce qui fait que le hero attend du JavaScript et des données. Corriger cette dépendance peut faire chuter le LCP sans toucher le reste de la page.
Comment trouver la source des sauts de mise en page (CLS)
Le CLS est le score des « sauts » de page. Il survient quand quelque chose change de taille après que la page semble chargée. Le navigateur calcule la mise en page, puis un élément tardif apparaît (ou grandit) et tout ce qui est en dessous est repoussé.
Pour l'attraper, utilisez la visualisation des layout shifts du navigateur. Dans Chrome DevTools, enregistrez un trace Performance pendant un reload et un petit scroll. Vous verrez des événements « Layout Shift » sur la timeline, avec des zones surlignées montrant ce qui a bougé. Cliquez un événement et regardez les détails « Moved from / Moved to » et l'élément déclencheur.
Une fois l'élément identifié, demandez : qu'est‑ce qui a changé sa taille tardivement ?
La plupart des bugs CLS proviennent d'un petit ensemble de motifs :
- Médias sans dimensions (images, vidéos embarquées, iframes)
- Swaps de polices qui modifient la largeur et les césures
- Bannières tardives (consentement cookie, promos, widgets de chat) injectées après le premier paint
- Blocs asynchrones (avis, recommandations, sections personnalisées)
- États qui se déplient (erreurs de validation, accordéons) qui apparaissent sans espace réservé
Choisissez la correction selon la cause. Si le contenu doit apparaître, réservez de l'espace avec des dimensions explicites, aspect-ratio, ou une boîte placeholder. Si c'est de l'UI optionnelle (comme une promo), affichez‑la sans pousser la mise en page, ou delayez‑la jusqu'à ce que le contenu principal soit stable.
Exemple : une landing charge une image hero sans dimensions, puis injecte une barre « Obtenez 10% » après 2 secondes. Le trace montrera deux shifts : un lié à l'élément image hero, un autre lié au conteneur de la bannière. Réserver l'espace du hero et afficher la bannière en overlay résout généralement les deux.
Comment isoler les délais d'interaction (INP)
L'INP est le temps entre une action utilisateur (click, tap, keypress) et une réponse visible sur la page. Si quelqu'un clique et que rien ne se passe pendant un moment, cet écart est ce que l'INP capture.
La façon la plus rapide de trouver la cause est d'enregistrer une interaction réelle et chercher le travail qui bloque le thread principal.
Ouvrez DevTools Performance, commencez un enregistrement, puis réalisez l'action qui semble lente (ouvrir un menu, taper dans une recherche, ouvrir un modal). Arrêtez l'enregistrement et cherchez un long gap juste après l'événement d'entrée, souvent montré comme des longues tâches (souvent 50ms+).
Quand vous repérez une longue tâche, reliez‑la au code en regardant ce qui s'est passé pendant cette fenêtre. Coupables fréquents dans les UIs IA :
- Rendu lourd (toute la page rerend pour un petit changement d'état)
- Listes ou tables volumineuses (centaines de lignes à la fois)
- Mises à jour d'état coûteuses (clonages profonds, tri/filtrage à chaque frappe)
- Scripts tiers (analytics, chat) s'exécutant durant les interactions
- Thrashing de layout (JS lisant et écrivant le layout en boucle)
Un triage rapide aide car la correction diffère :
- Un lag sur la première interaction pointe souvent vers du code lazy, le chargement de polices, ou un gros composant qui monte pour la première fois.
- Un lag à chaque interaction signifie généralement du rendu répété, un état bruyant, ou des handlers faisant trop.
Exemple : cliquer sur « Ajouter au panier » rerend toute la grille produit parce que l'état du panier est trop haut dans l'arbre. L'INP s'améliore lorsque vous isolez l'état du panier au widget concerné et empêchez la grille de rerender à chaque clic.
Corrections pratiques qui réduisent rapidement le CLS
Le CLS baisse généralement vite lorsque vous empêchez la page de changer de taille après l'apparition initiale. Les gains les plus rapides sont souvent ennuyeux : réservez l'espace, stabilisez la typographie, et empêchez l'UI surprise d'apparaître.
Réserver de l'espace pour tout ce qui charge plus tard
Si une image, une vidéo, un slot pub ou iframe arrive sans boîte définie, le navigateur devine puis corrige, et tout saute.
Définissez des dimensions explicites quand vous pouvez. Utilisez width et height sur les images, ou le CSS aspect-ratio pour que le navigateur connaisse la forme avant le téléchargement. Si vous utilisez des skeleton loaders, donnez‑leur une hauteur fixe correspondant au contenu réel.
Stabiliser les polices pour éviter la reflow du texte
Les swaps de polices tardifs changent les césures et poussent les boutons. Gardez la police fallback proche en taille et espacement, et évitez de changer le poids après le premier paint. Si un titre saute quand la webfont charge, choisissez un fallback aux métriques similaires et conservez des styles initiaux cohérents.
Retirer ou dompter les injections UI tardives
Toasts, bannières cookie, widgets de chat et barres « nouveau message » apparaissent souvent après que la page soit visible. Placez‑les dans un emplacement réservé depuis le départ, ou affichez‑les en overlay plutôt qu'en poussant le contenu.
Si vous voulez un passage court et efficace, concentrez‑vous sur :
- Dimensions (ou
aspect-ratio) pour les médias au‑dessus du pli - Hauteur minimale fixe pour les sections hero et les skeletons
- Bannières/widgets qui rendent dans un conteneur réservé
- Éviter d'insérer du contenu nouveau au‑dessus du pli après le premier paint
Changements qui améliorent souvent LCP et INP sans réécrire tout
Quand une UI générée par l'IA semble lente, c'est souvent parce que trop de travail survient avant que le premier écran soit pleinement visible. Concentrez‑vous sur deux objectifs : alléger la première vue (LCP) et faire en sorte que les taps et clics déclenchent moins de travail (INP).
Un pattern courant est un hero entouré de multiples conteneurs, plus un carrousel, une vidéo de fond, et plusieurs scripts tiers qui démarrent immédiatement. Ça peut sembler correct sur un laptop rapide, mais sur un téléphone de gamme moyenne le thread principal est saturé et tout arrive en retard.
Changements qui aident généralement sans changer toute l'architecture :
- Réduire l'élément LCP. Si c'est une image, compressez‑la, utilisez WebP/AVIF et servez la bonne taille selon l'écran. Si c'est du texte dans un wrapper lourd, retirez les couches inutiles et les effets coûteux.
- Simplifier au‑dessus du pli. Coupez animations non essentielles, ombres, flous et widgets complexes dans le premier viewport. Rendez d'abord la version la plus simple, puis améliorez après.
- Différer les scripts non critiques. Chargez analytics, chat et outils A/B après le rendu initial.
- Fractionner les longues tâches. Si un clic lance un gros calcul ou un rerender, scindez le travail pour que le navigateur puisse répondre rapidement.
- Réduire les rerenders. Consolidez l'état, memoïsez les parties coûteuses et évitez de rerender toute la page pour un petit changement UI.
Pour l'INP, surveillez de près les handlers de clic. Si un bouton fait des appels réseau, validation et mises à jour UI dans un même bloc, l'utilisateur attend. Affichez d'abord la réponse UI (ouvrir le drawer ou modal), puis effectuez le travail lourd.
Mesurer les améliorations après chaque changement (sans se duper)
Il est facile de perdre des heures en changeant quelque chose, en voyant un run favorable, puis en s'arrêter. Les Web Vitals sont bruyants. Le timing réseau, la charge CPU, les extensions et les caches chauds peuvent faire paraître un changement meilleur (ou pire) qu'il ne l'est.
Traitez chaque ajustement comme une mini‑expérience : changez une chose, puis mesurez. Si vous regroupez plusieurs changements (fréquent dans des frontends IA), vous ne saurez pas ce qui a aidé.
Un journal simple suffit :
- Ce qui a changé (une petite modification)
- Où (page/route, composant)
- Comment vous avez testé (appareil, throttling, cold vs warm load)
- Résultats (LCP, CLS, INP) en utilisant la médiane de 3 runs
- Preuves sauvegardées (captures de trace)
Comparez des médianes, pas des meilleurs runs. Un meilleur run est souvent de la chance.
Surveillez aussi les compromis. Vous pouvez corriger le CLS en réservant de l'espace, puis empirer le LCP en chargeant plus de CSS tôt. Ou améliorer l'INP en scindant un composant, puis introduire une image chargée tard qui devient le nouveau LCP. Si un correctif améliore une métrique et en détériore une autre, décidez quelle douleur utilisateur est la plus importante et ajustez.
Pièges courants lors du débogage des Web Vitals dans des UIs IA
Les travaux de Web Vitals partent en sucette quand le code a l'air « correct » mais se comporte différemment en production. L'erreur la plus fréquente est d'optimiser le score au lieu de l'expérience sur les pages réellement utilisées.
Pièges qui font perdre du temps et créent de faux wins :
- Courir après des points Lighthouse sur un seul run pendant que les vrais utilisateurs souffrent sur login, checkout ou pricing.
- Tester en mode dev et supposer que ces chiffres correspondent à la prod.
- Cacher du contenu, ajouter des délais ou montrer des skeletons trop longtemps pour améliorer la métrique alors que la page devient pire.
- Laisser une refactorisation IA toucher des dizaines de fichiers à la fois, de sorte que lorsqu'un LCP ou INP change vous ne savez pas pourquoi.
- Accélérer une page sans re‑vérifier les layouts partagés et les flux d'auth.
Exemple : une landing « corrige » le CLS en faisant apparaître le hero par fondu après 800 ms. Le CLS s'améliore, mais les utilisateurs regardent une section vide et cliquent au mauvais endroit quand le contenu apparaît. C'est un gain métrique avec une perte produit.
Quelques garde‑fous utiles :
- Mesurez la même route, profil d'appareil et réseau à chaque fois.
- Livrez un changement à la fois et confirmez que la navigation et la connexion fonctionnent toujours.
- Traitez tout fix qui cache du contenu ou retarde le rendu avec suspicion jusqu'à ce que vous confirmiez qu'il aide les utilisateurs.
Checklist rapide pour une passe Web Vitals en 30 minutes
Choisissez une page et un profil d'appareil pour aujourd'hui. Tester trois pages et deux tailles d'écran brûle du temps et donne des résultats flous.
Faites un run et notez ce que vous observez avant de toucher le code. Votre travail est d'identifier la plus grosse cause de douleur unique pour LCP, CLS et INP sur cette page.
- Baseline : enregistrez le temps LCP et l'élément LCP exact (image, titre, section hero).
- CLS : capturez les 1–2 principaux layout shifts et ce qui a bougé (hero, bannière, swap de police, widget injecté).
- INP : enregistrez l'interaction la plus lente reproductible et la longue tâche juste après.
- Balayage rapide : vérifiez que les médias hero ont des dimensions fixes, que bannières/toasts ont de l'espace réservé, et que les scripts tiers ne bloquent pas le premier rendu.
- Un changement, un rerun : faites une correction unique, relancez le même test et notez les nouveaux chiffres.
Si l'élément LCP est l'image hero et que la page saute quand une bannière cookie apparaît, corrigez d'abord l'espace de la bannière (CLS), puis verrouillez les dimensions et le comportement de chargement du hero (LCP). Ne mélangez pas cinq « petites corrections » dans un seul commit, sinon vous ne saurez pas ce qui a aidé.
Arrêtez quand les améliorations deviennent faibles, ou quand la correction suivante nécessite un refactor. Si l'UI a été générée par un outil IA et que le code est emmêlé, planifiez le prochain goulot comme un bloc de travail séparé.
Exemple : transformer une landing page IA sautillante en une page stable
Une landing IA typique paraît correcte en capture d'écran, puis saute quand on la charge réellement : une grande image hero en haut, des cartes pricing dessous, et un slider de témoignages qui apparaît tard.
Sur un projet comme celui‑ci, l'histoire s'est éclaircie après mesure : le LCP était l'image hero, le CLS venait d'un swap de police plus le slider qui changeait de hauteur quand il chargeait, et l'INP était pénalisé par une grosse librairie d'animations qui tournait tôt.
La séquence qui a corrigé le tout sans réécriture :
- Verrouiller la taille de l'image hero avec des dimensions explicites ou
aspect-ratio. - Réserver de l'espace pour le slider de témoignages avec une hauteur fixe (ou un min-height prévisible).
- Retarder ou réduire les animations précoces pour que les taps et le scroll soient réactifs.
Pour rester honnête, enregistrez les mêmes choses avant et après chaque changement :
| Étape | Ce que vous changez | Ce que vous enregistrez |
|---|---|---|
| Baseline | Rien | Élément LCP, CLS total, INP, plus un enregistrement écran |
| Après correction image | Taille du hero + comportement de chargement | Temps LCP et vérification si le LCP est toujours le hero |
| Après correction slider | Hauteur réservée | CLS et élément ayant bougé |
| Après changement animations | Délayer/réduire animations | INP et réactivité au premier tap |
Si vous avez réservé l'espace, supprimé les plus gros shifts et retardé le travail non essentiel mais que les métriques fluctuent encore car l'arbre de composants est emmêlé, il est souvent plus rapide de restructurer cette section que de continuer à traiter les symptômes.
Étapes suivantes si le frontend est trop désordonné pour optimiser en sécurité
Si vous ne pouvez pas mapper de façon fiable LCP, CLS ou INP à un élément spécifique et au composant qui l'a créé, vous avez probablement besoin d'un nettoyage avant d'affiner. Ce travail ne paie que si vous pouvez tracer une métrique à une cause concrète et vérifier l'impact après une petite modification.
Les frontends générés par l'IA ont souvent l'air corrects en surface mais cachent un bazar : composants dupliqués, styles inline partout, rerenders surprises, et changements de layout déclenchés par des données tardives. Dans ce cas, les « correctifs rapides » peuvent générer un nouveau layout shift, ou diminuer le LCP tout en aggravant l'INP.
Une voie plus sûre est une passe de triage courte :
- Choisissez une page qui compte (souvent la landing ou le flux d'inscription).
- Capturez une baseline : quelques traces Performance et une liste des plus gros éléments LCP et des principaux layout shifts.
- Identifiez ce que vous pouvez contrôler réellement (un composant, une route, un système de layout).
- Décidez : petit refactor d'abord, ou nettoyage plus profond avant de toucher aux métriques.
Voici un signal clair pour arrêter de bidouiller et refactorer : vous changez un composant hero pour corriger le LCP, mais l'en‑tête commence à sauter parce que l'espacement est défini en trois endroits (module CSS, style inline, div wrapper). Si vous ne pouvez pas prédire ce qui bougera, vous devinez.
Si vous héritez d'un code IA et avez besoin qu'il devienne assez stable pour que les correctifs de perf tiennent, FixMyMess travaille précisément sur ce type de remédiation : diagnostiquer des prototypes bâtis avec Lovable, Bolt, v0, Cursor et Replit, puis réparer et refactorer avec vérification humaine. Si vous voulez un deuxième avis avant d'investir dans une réécriture plus vaste, leur audit de code gratuit peut aider à pointer ce qui alimente LCP/CLS/INP sur vos pages clés.
Une fois la base de code à nouveau prévisible, revenez à la boucle simple : baseline, un changement, re‑mesure, répéter.
Questions Fréquentes
Que dois‑je faire en premier avant de commencer à réparer les Web Vitals ?
Commencez par une page et un profil d'appareil pour que vos résultats soient comparables. Utilisez une build proche de la production, gardez le même throttling réseau/CPU dans DevTools, et répétez les mêmes étapes à chaque run afin de pouvoir faire confiance aux changements observés.
Dois‑je faire plus confiance aux données de terrain ou à Lighthouse/DevTools ?
Utilisez les données de terrain pour décider où se situe la vraie douleur, puis les tests en laboratoire pour la reproduire et la corriger. Si vous ne pouvez pas la reproduire en lab, il est difficile de vérifier un correctif, donc priorisez les problèmes déclenchables à la demande.
Comment trouver l'élément LCP exact qui cause un chargement lent ?
Enregistrez un trace Performance dans DevTools pendant le chargement, puis trouvez le marqueur LCP et cliquez‑le pour voir l'élément exact choisi par le navigateur. Une fois l'élément identifié, remontez au composant qui le rend et vérifiez ce dont il dépend (image surdimensionnée, données tardives, gros travail d'hydratation, etc.).
Pourquoi ma section hero est‑elle souvent le problème de LCP dans les UIs générées par l'IA ?
Si le LCP est une image, assurez‑vous qu'elle ait les bonnes dimensions pour la fenêtre et qu'elle commence à se télécharger tôt, et non après du travail client. Si le LCP est du texte, vérifiez les CSS bloquantes et le chargement des polices qui retardent le premier rendu réel du titre ou du bloc hero.
Comment identifier ce qui cause mes sauts de mise en page (CLS) ?
Capturez les événements de layout shift dans un enregistrement Performance et cliquez sur les plus gros pour voir ce qui a bougé et ce qui l'a déclenché. La solution consiste généralement à éviter les changements de taille tardifs en réservant de l'espace en amont pour les médias, les bannières ou les blocs asynchrones.
Quelles sont les corrections rapides pour CLS qui tiennent réellement ?
Traitez‑le comme un problème de stabilité, pas seulement de style. Ajoutez des dimensions explicites ou aspect-ratio pour les images et embeds, faites correspondre la hauteur des skeletons au contenu final et affichez les UI tardives (barres cookie, widgets) sans pousser la page vers le bas.
Comment identifier ce qui cause un mauvais INP sur les clics et tapotements ?
Enregistrez un trace Performance pendant que vous réalisez l'interaction lente, puis regardez juste après l'événement d'entrée les longues tâches qui bloquent le thread principal. La solution habituelle consiste à réduire le travail pour cette interaction : éviter les rerenders inutiles, scinder les chemins coûteux ou différer les tâches non urgentes jusqu'après la réponse UI.
Pourquoi les Web Vitals régressent après de petites modifications UI dans des composants générés par l'IA ?
Parce que de petites modifications peuvent changer la mise en page initiale, le moment des fetchs et les effets secondaires au sein d'un même composant, ce qui déplace LCP, CLS ou INP sans signe évident en revue de code. Séparer layout, chargement de données et logique d'interaction rend la performance plus prévisible et évite que des changements « mineurs » ne déplacent les objectifs.
Comment mesurer les améliorations sans se tromper ?
Changez une seule chose, puis mesurez avec la médiane de trois runs comparables sur la même configuration. Ne vous fiez pas à un unique meilleur run, et surveillez les compromis : une correction de CLS peut empirer le LCP, ou une amélioration de l'INP peut introduire un nouvel élément LCP au‑dessus du pli.
Quand dois‑je arrêter d'ajuster et refactorer ou demander de l'aide ?
Quand vous ne pouvez pas mapper de façon fiable un pic de métrique à un élément précis et au composant qui l'a créé, vous devinez probablement et risquez de créer d'autres problèmes. Dans ce cas, un court passage de nettoyage paie souvent avant d'autres réglages ; si vous héritez d'un code généré par des outils comme Lovable, Bolt, v0, Cursor ou Replit, FixMyMess peut auditer la base et aider à rendre le prototype suffisamment stable pour que les corrections de performance tiennent.