Déploiement blue‑green pour petites applis : bascules et rollbacks plus sûrs
Apprenez le déploiement blue‑green pour petites applis : deux environnements, bascule sûre, rollback rapide, et conseils pratiques pour base de données et sessions.
Pourquoi les petites applis souffrent encore de déploiements risqués
Les petites applis tombent en panne pour des raisons ennuyeuses. On déploie un petit changement, et soudain tout le monde ne peut plus se connecter. Ou un job en arrière-plan démarre deux fois et écrit des lignes en double. Ou une valeur de config pointe vers la mauvaise base et les utilisateurs ont des erreurs pendant une heure.
Ces pannes semblent injustes parce que l’appli n’est pas « grosse ». Mais le risque est souvent plus élevé dans les petites équipes : moins de relectures, moins de temps de test, et personne en astreinte pouvant tout laisser pour réparer la production.
Les pires déploiements cassent des choses difficiles à reproduire en local. L’authentification et les sessions peuvent échouer parce que des cookies sont invalidés, des callbacks mal configurés ou des tokens refusés. Les données deviennent dangereuses quand des migrations verrouillent des tables, ou quand le code écrit de nouveaux champs avant qu’ils n’existent. Les paramètres d’exécution mordent quand des secrets manquent, des variables d’environnement sont erronées, ou les règles réseau diffèrent du dev. Et même quand tout marche en test, le trafic réel peut faire tomber un endpoint qui semblait correct en développement.
Le déploiement blue‑green réduit ce risque sans transformer les releases en cérémonie lourde.
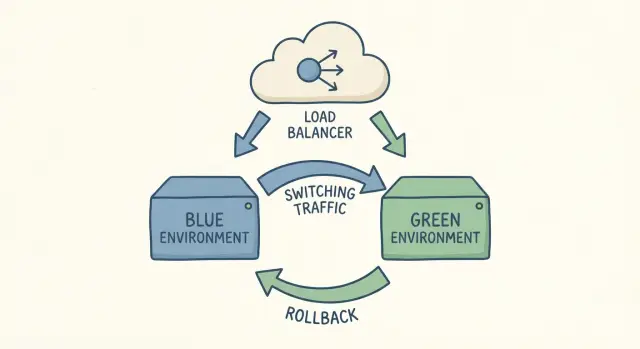
Quand on parle de « deux environnements », on entend deux copies complètes de votre configuration d’application qui tournent en parallèle : l’un est en production (bleu), l’autre est la nouvelle version que vous voulez mettre en ligne (vert). Les deux doivent utiliser le même type de serveur, les mêmes dépendances et des réglages proches de la production. L’essentiel est qu’un seul reçoive effectivement du trafic utilisateur.
Une bascule, c’est simplement changer le trafic du bleu vers le vert. Si quelque chose tourne mal, vous revenez en arrière. C’est tout l’objet.
Il ne s’agit pas d’un processus lourd. C’est se donner un endroit sûr pour répondre à des questions pratiques avant que les utilisateurs ne payent le prix : la connexion fonctionne‑t‑elle toujours ? Les pages clés se chargent‑elles ? Les jobs de fond se comportent‑ils bien ? Peut‑on revenir vite en arrière si on a raté quelque chose ?
Un scénario courant pour une petite appli est la modification « rapide » faite à la hâte. Elle marche pour vous, puis casse pour les utilisateurs parce que la production gère différemment les cookies, les domaines ou les secrets. Avec le vert prêt en coulisse, vous pouvez tester ces détails spécifiques à la production d’abord, puis basculer le trafic quand vous êtes confiant.
Si votre base de code est générée par IA et déjà bancale, le risque augmente. Les équipes héritent souvent d’une authentification cassée, de secrets exposés et d’une logique emmêlée qui réagit différemment sous vrai trafic. Blue‑green ne réparera pas un mauvais code tout seul, mais il peut empêcher qu’un mauvais déploiement ne tourne en longue panne.
Blue‑green en clair
Le déploiement blue‑green, c’est l’idée simple de maintenir deux copies prêtes de votre appli.
Le bleu est ce que les utilisateurs voient maintenant. C’est la version live qui gère le trafic. Le vert est la nouvelle version que vous voulez publier. Vous la construisez, la configurez et la testez pendant que le bleu continue de servir les utilisateurs.
Quand le vert vous convient, vous effectuez une bascule contrôlée pour que les utilisateurs atteignent le vert au lieu du bleu. Cette bascule se fait généralement en un seul endroit : une règle de load balancer ou de reverse proxy, un swap d’environnement si votre hôte le propose, un réglage de routeur dans votre passerelle de conteneurs, ou (moins idéal) le DNS. Le DNS fonctionne, mais la mise en cache rend le timing moins prévisible.
Le gros avantage, c’est la rapidité et la confiance. Si quelque chose casse après la bascule, revenir en arrière consiste souvent à renvoyer le trafic vers le bleu. Vous ne reconstruisez pas l’ancienne version sous pression : elle est déjà là et fonctionne.
Imaginez un simple SaaS avec connexion, facturation et tableau de bord. Vous déployez le vert avec un nouveau layout, vous faites un smoke test sur l’infra réelle, puis vous basculez. Si les clients signalent des graphiques cassés, vous basculez en quelques minutes sur le bleu pendant que vous corrigez le vert.
Blue‑green ne résout pas tout. Deux domaines font trébucher la plupart des équipes :
Base de données : si le vert a besoin d’une nouvelle table ou de colonnes modifiées, il faut planifier pour que bleu et vert puissent fonctionner en sécurité pendant la transition.
Sessions et connexions : si les sessions sont stockées en mémoire sur chaque instance, les utilisateurs peuvent être déconnectés quand le trafic passe. Un stockage de sessions partagé (ou une auth sans état) évite cela.
Quand blue‑green convient (et quand non)
Blue‑green est idéal si vous voulez des releases plus sûres sans outillage de release compliqué. Vous conservez deux environnements proches de la production, testez le nouveau avec des réglages réels, puis basculez le trafic.
C’est adapté quand votre appli est majoritairement sans état et que vos changements sont faciles à tester bout en bout. Cela inclut souvent les applis web simples, les APIs avec des requêtes courtes et indépendantes, les outils internes avec un ensemble d’utilisateurs connu, et les SaaS en phase initiale qui publient souvent de petits changements. C’est aussi pertinent si vous pouvez vous permettre d’exécuter deux copies pendant une fenêtre de release.
Exemple simple : un petit SaaS avec Next.js et une API. Vous déployez la nouvelle version sur le vert, vous faites un rapide smoke test (connexion, création d’un élément, export), puis vous basculez. Si quelque chose cloche, vous revenez en quelques minutes.
Ce n’est pas une bonne option quand la partie la plus difficile de votre release est la base de données, ou quand le travail ne peut pas être dupliqué en toute sécurité entre environnements. Signaux d’alerte : réécritures fréquentes de schéma qui lockent les tables, jobs longs qui ne peuvent être mis en pause ou dupliqués, état mémoire lourd comme les WebSockets ou un stockage de sessions personnalisé, et effets secondaires tiers (paiements, emails) qu’on ne peut pas rejouer sans précaution. Ça tourne aussi mal quand l’équipe n’a pas de checklist écrite pour la bascule et le rollback.
Il y a un coût : vous payez deux copies pendant les releases. Pour les petites applis, cela peut rester abordable, mais prévoyez des coûts doublés pour le compute et tout service dupliqué (queues, caches) si nécessaire.
L’outil compte moins que les habitudes d’équipe. Une courte checklist (qui bascule, quoi vérifier, ce qui déclenche le rollback) évite la panique.
Ce qu’il faut avant d’essayer
Blue‑green marche le mieux quand vous traitez bleu et vert comme deux copies séparées et complètes de la production. Si les bases ne sont pas solides, vous pourrez peut‑être basculer le trafic, mais vous ne saurez pas quel côté est sain et le rollback peut devenir chaotique.
Commencez par la configuration. Bleu et vert doivent exécuter le même code, mais ne doivent pas partager les mauvais secrets par accident. Séparez clairement les variables d’environnement et facilitez la vérification de l’environnement utilisé par un service. Une erreur fréquente est de pointer le vert vers la mauvaise base, vers un callback OAuth incorrect ou vers une clé de paiement de test.
Checklist minimale
Avant votre première bascule, vous devez pouvoir répondre « oui » à :
- Configs séparées pour blue et green (env vars, secrets, clés tierces), avec un nommage clair et un moyen facile de vérifier ce qui est chargé.
- Un artefact de build reproductible promu d’un environnement à l’autre (build once, deploy many). Ne rebuild pas pour le vert.
- Une vérification de santé qui prouve plus que « le serveur est up » (inclure dépendances critiques comme DB et cache).
- Un monitoring basique de ce que ressent l’utilisateur (taux d’erreurs et latence) plus une ou deux actions clés (inscription, paiement, upload de fichier).
- Des logs lisibles sous stress (request IDs, erreurs exploitables, et un moyen de comparer bleu vs vert).
Les health checks méritent une attention particulière. Un endpoint « 200 OK » suffit pour un load balancer, mais vous voulez aussi un signal plus profond avant la bascule. Par exemple : l’appli atteint‑elle la base, lit‑elle une ligne et écrit‑elle un enregistrement léger ? Si vous ne pouvez pas tester les écritures en toute sécurité, vérifiez au moins qu’une simple requête fonctionne.
Rendez les releases ennuyeuses. Le plus grand avantage du blue‑green, c’est la certitude que vous basculez vers ce que vous avez déjà testé. Si votre build change entre environnements, vous testez une chose et vous livrez une autre.
Pas à pas : runbook simple de release blue‑green
Blue‑green marche mieux avec une checklist courte et répétable. Le but n’est pas d’être sophistiqué, mais d’être ennuyeux et sûr.
1) Choisissez comment vous basculez le trafic
Choisissez une méthode et tenez‑vous y :
- Switch au load balancer ou reverse proxy
- Swap de plateforme (si votre hébergeur le permet)
- Changement DNS (marche, mais la mise en cache rend le timing imprévisible)
Décidez à l’avance qui a l’accès, combien de temps ça prend et comment l’annuler.
2) Déployez le vert pour qu’il corresponde au bleu
Déployez la nouvelle version sur le vert avec la même « forme » que le bleu : mêmes services (queue, cache, stockage), même approche de gestion des secrets, même configuration des workers, et réglages d’exécution équivalents. Les valeurs peuvent différer, mais la structure doit être cohérente.
La plupart des échecs blue‑green viennent du fait que le vert n’est pas vraiment similaire à la production : il pointe vers une autre base, un secret manquant casse l’auth après la bascule, ou un runner de job n’est pas câblé pareil.
3) Vérifiez le vert avant qu’il ne voie des utilisateurs
Faites des tests rapides contre le vert avec un compte réel (ou un compte safe pour le staging). Restez simple et focalisez‑vous sur ce qui casse le revenu et la confiance :
- Connexion et déconnexion
- Chargement de quelques pages clés
- Création et mise à jour d’un enregistrement réel
- Déclenchement d’un job en arrière‑plan (email, webhook, rapport)
- Analyse des logs pour des pics d’erreurs nouveaux
Si vous utilisez des caches ou des workers, démarrez‑les tôt et laissez‑les chauffer. Un pattern courant : « ça marchait en test » mais ça plante quand les caches sont froids et que les workers traitent les vraies files.
4) Basculez, puis surveillez de près
Basculez le trafic de manière contrôlée. Si votre infra permet une bascule progressive (même 10 % d’abord), faites‑le. Si c’est tout ou rien, faites‑le pendant une période calme.
Pendant 10 à 30 minutes, surveillez quelques signaux : taux d’erreurs, latence, succès de connexion, checkout ou votre action clé, et charge DB. Décidez à l’avance quels chiffres signifient « arrêter et revenir en arrière ».
Modifications de base de données sans perdre d’écritures
La partie la plus difficile du blue‑green n’est généralement pas la bascule : c’est la base de données.
Le risque central est simple : pendant un moment, deux versions de l’appli peuvent être actives. Si les deux utilisent la même base mais attendent des tables ou colonnes différentes, une version peut commencer à renvoyer des erreurs. Pire : elle peut écrire des données que l’autre version ne sait pas lire, ou écraser des champs de façon inattendue.
Un pattern plus sûr est de rendre les changements de schéma rétrocompatibles d’abord. Ajoutez avant de supprimer. Gardez l’ancien code fonctionnel pendant que la nouvelle version se déploie.
Utilisez l’approche « expand then contract »
La plupart des petites applis évitent les interruptions en divisant le travail de schéma :
- Expand : ajoutez de nouvelles colonnes ou tables, conservez les anciennes.
- Écrire en chevauchement : mettez le nouveau code pour écrire au nouvel endroit tout en gardant la lecture compatible.
- Contract : après la bascule et une période de sécurité, supprimez les anciennes colonnes, tables ou chemins code.
Exemple : vous voulez renommer users.fullname en users.display_name. Ne supprimez pas fullname pendant la bascule. Ajoutez display_name, publiez du code qui écrit les deux champs (ou qui écrit l’un et backfill l’autre), puis nettoyez plus tard.
Séparez le déploiement des migrations destructrices
N’essayez pas de regrouper « drop column », « rewrite table » ou « backfill 50 millions de lignes » au même moment que la bascule. Faites le travail lent ou risqué en avance, pendant que la version actuelle sert les utilisateurs. Si une migration prend des minutes ou locke des lignes, traitez‑la comme une pré‑migration et rendez‑la sûre tant que l’ancienne appli tourne.
Pendant la fenêtre de bascule, vérifiez la compatibilité dans les deux sens : l’ancienne app lit‑elle les lignes écrites par la nouvelle, et la nouvelle lit‑elle celles écrites par l’ancienne ? C’est là que les hypothèses cachées apparaissent (listes de colonnes codées en dur, gestion manquante des nulls, ou valeurs par défaut non sûres).
Sessions et auth : garder les utilisateurs connectés pendant la bascule
La façon la plus rapide de transformer une bascule sûre en cauchemar support est de déconnecter tout le monde par accident. Les sessions cassent généralement parce que quelque chose change entre blue et green : nom du cookie, clé de signature, format du token, ou même domaine/sous‑domaine.
Gardez les règles d’identité identiques des deux côtés
Pendant la fenêtre de bascule, considérez ces éléments comme des contrats partagés qui ne doivent pas changer :
- Clés de signature et chiffrement des sessions (secrets de cookie, clés JWT, secrets CSRF)
- Paramètres des cookies (nom, domaine, path, Secure, HttpOnly, SameSite)
- Format des tokens et des sessions (claims, règles d’expiration, sérialisation)
- Callbacks d’auth et URLs de redirection (pour OAuth)
Si vous devez faire une rotation de clés, faites‑la avec chevauchement. Le vert doit accepter l’ancienne et la nouvelle clé pour vérification, tout en émettant seulement de nouvelles sessions avec la nouvelle clé. Les utilisateurs existants restent connectés et les nouvelles connexions utilisent la clé plus sûre.
Préférez l’auth sans état (stateless) mais restez compatible
Si votre appli peut utiliser des tokens d’accès à courte durée avec un flux de refresh, les bascules sont plus simples car le serveur n’a pas à retenir les sessions. L’important est la compatibilité : le vert doit accepter les tokens émis par le bleu jusqu’à leur expiration naturelle. Évitez de changer les noms de claims ou les règles d’audience dans la même release.
Si vous utilisez des sessions côté serveur, partagez le magasin de sessions. Bleu et vert doivent lire/écrire le même backend (souvent Redis ou une table en DB). Si chaque environnement a son propre magasin, les utilisateurs passeront sur le vert et seront considérés « inconnus » même si leur cookie est valide.
Les checkouts et longs formulaires sont des points sensibles : quelqu’un est en plein paiement, la bascule arrive et sa requête suivante arrive sur le vert. Protégez‑ça en stockant l’état du panier et de la commande en base (pas seulement en mémoire), utilisez l’idempotence pour les actions de paiement, et rendez les soumissions tolérantes aux répétitions. Quand c’est possible, basculez progressivement et laissez le bleu finir les requêtes en cours avant de couper complètement.
Revenir en arrière rapidement sans empirer la situation
Avec blue‑green, rollback ne veut généralement pas dire annuler les changements de code. Ça veut dire renvoyer le trafic vers l’environnement précédent (du vert vers le bleu). Si le routage est propre, c’est rapide.
Le but est la vitesse et la certitude. Choisissez un propriétaire de la décision, et conservez une action évidente qui bascule le trafic (un bouton, une commande, une étape de runbook). Quand chacun a sa « solution rapide », les rollbacks s’accumulent et se compliquent.
Définissez les déclencheurs de rollback avant la bascule. Exemples courants : un pic soudain de 5xx/timeouts, échecs de connexion ou d’inscription, échecs de paiement, problèmes d’intégrité des données (commandes manquantes, doublons), ou une hausse de latence qui rend l’appli inutilisable.
La base de données reste le point dur. Une fois que le vert a commencé à recevoir des écritures, revenir au bleu n’est sûr que si le bleu peut lire la nouvelle forme des données. Si votre release a supprimé une colonne, renommé des champs ou changé des contraintes, le bleu peut planter ou mal fonctionner silencieusement. C’est comme ça qu’un rollback devient une panne plus grave.
Règle pratique : gardez les changements de DB rétrocompatibles pendant une courte fenêtre. Ajoutez des colonnes d’abord, conservez les anciennes, déployez du code qui gère les deux, et ne supprimez les anciens champs qu’après un délai de sécurité.
Fixez une fenêtre de décision. Par exemple : « si on voit des échecs critiques dans les 10–20 premières minutes, on revient en arrière. Après ça, on corrige en avant sauf en cas de perte de données. » Cela évite les débats interminables pendant que les utilisateurs sont bloqués.
Séquence simple de rollback :
- Déclarez un propriétaire d’incident et geler les autres changements
- Basculez le trafic vers l’environnement précédent
- Vérifiez les connexions, paiements et les flux utilisateur critiques
Erreurs communes qui causent des pannes
Blue‑green paraît simple, mais la plupart des pannes surviennent dans les interstices entre « deux environnements » et « trafic basculé ».
Une grosse erreur est de traiter bleu et vert comme deux applis différentes. Ça commence petit : variable d’environnement manquante, secret tourné d’un seul côté, ou feature flag différent. Puis la bascule arrive et les paiements échouent ou les emails ne partent plus. Bleu et vert doivent être le même build et avoir la même forme de config, avec seulement les différences minimales (couleur de déploiement et hostnames).
Un autre oubli fréquent concerne le travail en arrière‑plan. Le trafic web peut basculer proprement, mais le job runner est toujours dirigé vers l’ancien environnement, ou les deux environnements lancent la même tâche planifiée. Ça cause des factures en double, des notifications répétées ou des nettoyages concurrents.
Les changements de base de données sont le principal danger. Les équipes lancent une migration cassante au moment précis de la bascule. Si le vert utilise le nouveau schéma et que le bleu écrit encore dans l’ancien format (ou inversement), vous pouvez perdre des écritures ou corrompre des données rapidement. Le pattern plus sûr : rendre les changements compatibles, déployer, basculer, puis supprimer l’ancien schéma plus tard.
Les tests locaux ne suffisent pas. Blue‑green échoue sur des détails propres à la production : fournisseurs d’auth réels, cookies réels, caches réels, timeouts réels et charge réelle. Si vous ne testez le vert que sur votre laptop, vous ne testez pas ce que vous vous apprêtez à servir aux utilisateurs.
Enfin, les équipes hésitent pendant un incident parce qu’elles n’ont pas défini une règle d’arrêt. Décidez à l’avance ce qui déclenche un rollback immédiat : un pic d’erreurs, des échecs de connexion au‑delà d’un seuil, une rupture de flux clé (inscription, paiement, reset), une hausse d’erreurs DB (deadlocks, timeouts), du travail en double, ou le simple fait de ne pas pouvoir expliquer le problème en quelques minutes.
Checklist rapide et prochaines étapes
Blue‑green marche le mieux quand chaque release est une routine courte qui attrape les quelques choses qui blessent le plus les utilisateurs : connexion cassée, écritures ratées et ralentissements après la bascule.
Avant de toucher au trafic, faites une passe pré‑deploy : confirmez les health checks du nouvel environnement (y compris dépendances critiques), vérifiez que les variables d’environnement et secrets sont chargés au bon endroit, révisez les migrations pour sécurité (additives d’abord, pas de suppressions surprises), et assurez‑vous que logs et monitoring fonctionnent.
Juste après la bascule, testez comme un vrai utilisateur. Pour beaucoup de petites applis, cela signifie : s’inscrire ou se connecter, créer ou mettre à jour un enregistrement, et compléter une action clé d’argent ou de messagerie (checkout, paiement, envoi d’une invite, sauvegarde d’un brouillon).
Après les premières minutes, arrêtez de cliquer partout et regardez les signaux. Cherchez des changements, pas des chiffres parfaits : un pic soudain d’erreurs, une montée de latence, ou un backlog dans les queues.
Décidez des règles de rollback avant d’en avoir besoin. Un rollback n’est pas seulement une bascule : c’est aussi une décision sur les données — qui a l’autorité pour revenir en arrière, l’action exacte et son délai, ce qu’il advient des écritures faites après la bascule, comment gérer les sessions, et quand arrêter de revenir en arrière et commencer à corriger en avant.
Si vous héritez d’une appli générée par IA et que les déploiements tombent sans arrêt, considérez ça comme un problème de santé du code, pas seulement un problème de processus. Les équipes de FixMyMess (fixmymess.ai) font des diagnostics de code, des réparations logiques, un renforcement de la sécurité et une préparation des déploiements pour les prototypes générés par IA, ce qui peut rendre les bascules blue‑green et les rollbacks prévisibles au lieu de stressants.
Questions Fréquentes
What is blue-green deployment in simple terms?
Le déploiement blue-green consiste à garder deux environnements complets et prêts à tourner. L’un (bleu) sert les utilisateurs en production, pendant que vous déployez et testez la nouvelle version dans l’autre (vert). Quand vous êtes satisfait, vous basculez le trafic vers le vert ; si quelque chose casse, vous revenez au bleu.
Why do small apps get so much downtime from “small” deploys?
Les petites applis ont souvent moins de vérifications avant une release : moins de temps de test, moins de relecteurs, et une réponse aux incidents plus lente. Une petite erreur de configuration ou un changement d’authentification peut mettre toute l’appli hors service. Blue‑green vous offre une étape « essayer sur l’infra réelle » sans ajouter beaucoup de processus.
What’s the best way to switch traffic between blue and green?
La bascule la plus courante se fait au niveau d’un load balancer ou d’un reverse proxy car c’est rapide et réversible. Si votre plateforme propose un swap d’environnement, c’est souvent encore plus simple. Le DNS peut fonctionner, mais la mise en cache le rend imprévisible.
What should I test on green before I cut over?
Faites un smoke test rapide qui reflète ce qui importe aux utilisateurs : connexion, quelques pages clés, une création/mise à jour, et un job en arrière-plan ou un effet secondaire important. Vérifiez que les mêmes secrets et variables d’environnement que la production sont bien chargés. Surveillez ensuite les erreurs et la latence immédiatement après la bascule pour pouvoir revenir en arrière rapidement si besoin.
How do I avoid green pointing at the wrong database or secrets?
Considérez la configuration comme le risque principal. Rendez évident dans quel environnement vous êtes, séparez clairement les configs blue et green, et revérifiez les points sensibles : endpoints de base de données, URLs de callback OAuth, domaines des cookies et clés de paiement. Les coupes douloureuses ne viennent généralement pas d’un bug mais d’un mauvais réglage.
How do I prevent users from getting logged out during the switch?
Gardez les règles d’identité identiques sur les deux côtés pendant la bascule, notamment les clés de signature et chiffrement de session, les paramètres des cookies et le format des tokens. Si vous utilisez des sessions serveur, partagez le même magasin de sessions (Redis ou base de données) pour que blue et green reconnaissent les mêmes sessions. Si vous faites une rotation de clés, procédez avec recouvrement pour que green accepte encore les sessions émises par blue jusqu’à expiration.
How do I handle database migrations without losing writes?
Supposez que blue et green puissent accéder à la même base pendant un moment : vos changements de schéma doivent donc être rétrocompatibles. Ajoutez d’abord de nouvelles colonnes ou tables, déployez du code capable de lire/écrire les deux formes, puis supprimez l’ancien schéma plus tard. Évitez les migrations destructrices au moment précis de la bascule.
When should I roll back vs fix forward?
Le rollback se fait généralement en renvoyant le trafic vers blue, pas en reconstruisant l’ancienne version sous pression. Décidez à l’avance des déclencheurs de rollback (échecs de connexion, paiements, pics d’erreurs ou problèmes d’intégrité des données). Soyez prudent si green a déjà écrit des données dans un format que blue ne peut pas lire.
How do I stop background jobs from running twice in blue and green?
Si la même tâche planifiée tourne dans les deux environnements, vous risquez des doublons (factures en double, notifications répétées). Avant la bascule, vérifiez qu’un seul jeu de workers/schedulers exécute les tâches « one‑time » ou périodiques durant la transition. Après la bascule, contrôlez les files, les tâches cron et les processeurs de webhooks pour vous assurer qu’ils pointent au bon endroit.
Does blue-green help if my app is AI-generated and already unstable?
Le code généré par IA est souvent fragile (authentification fragile, logique emmêlée, configuration incohérente) et son comportement en production peut être imprévisible. Blue‑green limite la zone d’impact, mais ne corrige pas les fondamentaux cassés comme des migrations dangereuses ou des secrets codés en dur. Si vos déploiements échouent régulièrement, il vaut souvent mieux diagnostiquer et assainir le code pour rendre les releases prévisibles.