Disjoncteurs pour fournisseurs instables : prévenir les pannes en chaîne
Apprenez comment des disjoncteurs pour fournisseurs instables empêchent les pannes en chaîne grâce aux timeouts, retries, repli et reprise sûre quand les dépendances se stabilisent.
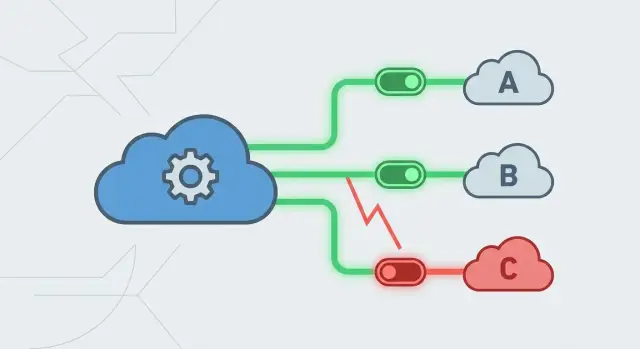
Pourquoi des fournisseurs instables peuvent faire tomber une appli par ailleurs saine
Une application peut être solide et quand même s'effondrer parce que quelque chose sur lequel elle s'appuie commence à merder. Une passerelle de paiement ralentit, un service d'email renvoie des erreurs, ou un proxy de base de données fait des siennes. Si votre appli continue d'appeler cette dépendance comme si de rien n'était, un petit problème se propage vite.
Cette réaction en chaîne est une panne en cascade : une dépendance lente ou défaillante fait attendre les requêtes, les requêtes en attente s'accumulent, et bientôt les parties saines de votre appli ne respirent plus. Les threads restent bloqués, les pools de connexions se remplissent, les files d'attente s'entassent, et tout semble « down » alors que la plupart de votre code va bien.
Cela commence souvent par des déclencheurs ordinaires :
- Des timeouts trop longs, si bien que chaque requête attend bien plus longtemps que ce que l'utilisateur supportera.
- Des limites de débit, suivies de retries qui poussent encore plus de trafic dans le goulet.
- Des pannes partielles où certains appels fonctionnent et d'autres restent bloqués, ce qui est plus dur à repérer.
- Des « succès lents » où les réponses finissent par réussir mais prennent 10x plus de temps et saturent les ressources.
Les retries sans garde-fous aggravent la situation. Si chaque action utilisateur déclenche trois retries et que des centaines d'utilisateurs frappent le même fournisseur, vous pouvez créer votre propre pic de trafic. C'est pourquoi les disjoncteurs comptent : ils empêchent votre appli de toucher la plaque chauffante encore et encore.
Du point de vue utilisateur, c'est simple et pénible. Les boutons tournent indéfiniment, les pages se rechargent en erreur, et les gens recommencent à cliquer parce que rien ne se passe. Cela mène à des actions dupliquées (commandes en double, prélèvements en double, multiples tickets). Pire, les utilisateurs ne savent pas si leurs données ont été sauvegardées ou si un paiement est passé.
Ce mode de défaillance apparaît souvent dans les apps héritées générées par l'IA : timeouts manquants, retries agressifs, et gestion des erreurs qui ne couvre que le « happy path » peuvent transformer un accroc fournisseur en panne générale. La correction commence par traiter les défaillances de dépendances comme normales, pas comme exceptionnelles.
Disjoncteurs en une minute : ce qu'ils font et pourquoi
Un disjoncteur est une garde autour d'un appel externe. Quand une dépendance commence à échouer, vous arrêtez de l'appeler pendant un court laps de temps. Cela empêche d'envoyer plus de trafic, plus d'erreurs et de bloquer davantage de threads. Au lieu que chaque requête se bloque, vous échouez vite et basculez sur un repli.
Les disjoncteurs passent généralement par trois états :
- Fermé : les appels circulent normalement, et vous suivez les résultats.
- Ouvert : le fournisseur semble malsain, donc les appels sont bloqués immédiatement et vous renvoyez une réponse contrôlée.
- Semi-ouvert : après une période de refroidissement, vous autorisez un petit nombre d'appels de test pour voir si le fournisseur s'est rétabli.
Ce n'est pas la même chose qu'« ajouter des retries et des timeouts ». Un timeout limite combien de temps vous attendez, mais vous pouvez toujours accumuler beaucoup de travail en attente quand un fournisseur est lent. Les retries peuvent multiplier le trafic au pire moment. Un disjoncteur ajoute une règle de plus haut niveau : vous avez vu suffisamment d'échecs, donc arrêtez d'essayer pour l'instant.
Bien configuré, le résultat est volontairement ennuyeux :
- Les utilisateurs obtiennent une réponse rapide, même si elle est dégradée (données en cache, travail en file d'attente, ou un message clair « réessayez bientôt »).
- Vos serveurs restent réactifs parce qu'ils ne restent pas bloqués à attendre un fournisseur en panne.
- Les incidents restent contenus parce qu'une dépendance fragile ne provoque pas une réaction en chaîne.
Exemple : si votre flux d'inscription envoie un email de confirmation et que l'API d'email commence à temporiser, un disjoncteur peut arrêter les tentatives d'envoi pendant quelques minutes et mettre les emails en file d'attente. Les utilisateurs peuvent toujours créer un compte au lieu de regarder la page tourner indéfiniment.
Les bases de code générées par l'IA oublient souvent ce modèle ou le câblent mal. FixMyMess voit couramment des timeouts longs associés à des retries agressifs, ce qui transforme un accroc fournisseur en panne. Un disjoncteur est l'un des moyens les plus rapides pour rendre les défaillances de dépendances prévisibles.
Où ajouter des disjoncteurs en premier (emplacements à fort impact)
Commencez là où une dépendance peut bloquer toute l'application. Les meilleurs premiers cibles ne sont pas des « fonctionnalités rares ». Ce sont les appels sur les écrans à fort trafic et les flux critiques.
Une façon simple de prioriser est de penser en deux dimensions :
- Risque : le fournisseur échoue, ralentit ou impose des limites fréquemment.
- Rayon d'impact : un appel lent bloque beaucoup de requêtes, monopolise des workers, ou casse un parcours utilisateur central.
Choisissez les dépendances qui échouent fort (et souvent)
Les services tiers sur le chemin critique méritent une protection en priorité : paiements, email/SMS, fournisseurs d'authentification et API de LLM. Ils sont hors de votre contrôle et peuvent se dégrader sans prévenir.
Si vous ne protégez qu'une chose, choisissez la dépendance qui peut couper l'accès ou l'argent. Un checkout qui bloque est pire qu'un reçu retardé. Un timeout de login est pire que des analytics manquants.
Concentrez-vous sur les endpoints liés aux actions critiques
Les disjoncteurs importent surtout sur les endpoints où les utilisateurs essaient activement de terminer quelque chose : login, signup, onboarding, checkout, reset de mot de passe, et toute action « submit » qui doit répondre vite.
Pour choisir les premiers points d'appel :
- Identifiez vos endpoints principaux par trafic et impact business.
- Cartographiez les appels externes que chaque endpoint effectue.
- Signalez les appels synchrones sur le chemin requête/réponse.
- Décidez ce que « défaillance » signifie (timeouts et 5xx, mais aussi payloads cassés ou incomplets).
- Confirmez ce qui se passe aujourd'hui quand la dépendance est lente (spinners, accumulation dans les files, épuisement de threads).
Les équipes sont souvent surprises par ce qui compte comme défaillance. Un fournisseur peut renvoyer HTTP 200 avec un payload cassé, des champs manquants, ou un token inutilisable. Traitez cela comme une défaillance aussi, sinon le disjoncteur ne s'ouvrira pas quand il le devrait.
Exemple : si l'onboarding appelle un LLM pour générer un message de bienvenue et que cet appel prend 20 secondes, les utilisateurs pensent que l'inscription est cassée. Mettez le disjoncteur autour de cet appel, définissez un timeout clair, et renvoyez un message par défaut simple.
Le code hérité généré par l'IA peut compliquer cela car les appels aux dépendances sont entremêlés dans les handlers et routes. Un premier mouvement pratique est d'isoler chaque fournisseur derrière une frontière propre pour pouvoir ajouter timeouts, disjoncteurs et repli sans tout réécrire.
Les réglages qui comptent : timeouts, seuils et fenêtres de réinitialisation
Un disjoncteur n'est efficace que si ses paramètres le sont. Trop permissif, les utilisateurs sentent encore la panne. Trop strict, vous bloquez du trafic sain.
Timeouts : décidez combien de temps vous êtes prêts à attendre
Choisissez un timeout par requête basé sur ce que fait l'utilisateur. Pour un bouton « Enregistrer », attendre 10 secondes paraît cassé. Pour une synchronisation en arrière-plan, vous pouvez tolérer plus.
Une règle utile : le timeout doit être plus court que le temps que votre appli peut se permettre d'être bloquée. S'il est trop élevé, les requêtes s'accumulent, les workers se bouchent, et un petit ralentissement fournisseur devient une panne d'appli.
Les retries n'aident que lorsque les échecs sont brefs et que le fournisseur n'est pas surchargé. Retenter après des timeouts aggrave souvent les choses car cela double le trafic au moment même où la dépendance souffre.
Seuils et récupération : quand ouvrir, quand tester
Vous avez besoin de trois nombres : quand ouvrir, combien de temps attendre, et comment tester la récupération.
Un point de départ pratique :
- Ouvrir après un pic clair, par exemple 5 échecs sur les 20 derniers appels.
- Attendre 30 à 60 secondes avant de retester.
- En semi-ouvert, autoriser 1 à 3 appels de sonde, pas une inondation.
- Limiter les retries à 0 ou 1, et seulement pour des requêtes sûres et idempotentes.
- Définir des timeouts par endpoint, souvent 1 à 3 secondes pour les actions visibles par l'utilisateur.
Les probes en semi-ouvert sont le « doigt dans l'eau ». Après la fenêtre de réinitialisation, vous laissez passer un petit nombre de requêtes contrôlées. Si elles réussissent de façon consistante, vous refermez le circuit. Si elles échouent, vous rouvrez.
Exemple : si un fournisseur d'email envoie des codes de connexion et commence à temporiser, utilisez un timeout court pour que l'UI ne se bloque pas, ouvrez le disjoncteur après quelques échecs, et sondez chaque minute. Les utilisateurs obtiennent une étape claire plutôt que des spinners sans fin.
Si vous avez hérité d'un code généré par l'IA avec des boucles « retry forever » accidentelles, corriger ces paramètres est souvent un des changements à plus fort effet.
Pas à pas : implémenter un disjoncteur sans sur-ingénierie
La façon la plus rapide d'obtenir de la valeur est de centraliser. Ne dispersez pas les vérifications partout. Mettez le comportement en un seul endroit pour pouvoir l'affiner plus tard sans chercher dans des dizaines de fichiers.
Un flux simple qui marche dans la plupart des applis
Créez un wrapper « client fournisseur » unique pour chaque dépendance externe (paiements, email, modèle IA, auth, expédition). Chaque appel passe par lui. Ce wrapper gère les timeouts, les retries, l'état du disjoncteur et la journalisation.
Une implémentation simple ressemble souvent à ceci :
- Centralisez les appels dans un module avec une interface unique.
- Normalisez les erreurs en un petit ensemble que votre appli comprend (timeout, indisponible, mauvaise requête).
- Suivez les résultats récents dans une fenêtre roulante et ouvrez le circuit quand les échecs dépassent votre seuil.
- Quand le circuit est ouvert, échouez vite et renvoyez un repli sûr.
- Après un refroidissement, sondez prudemment et ne refermez qu'après un vrai succès.
Ce que signifie un « repli sûr » en pratique
Un repli ne devrait pas prétendre que tout a marché. Il doit permettre à l'utilisateur d'avancer sans aggraver la situation.
Si l'email échoue, acceptez la soumission du formulaire, affichez une confirmation et mettez l'email en file d'attente. Si une API de tarification est en panne, affichez des prix en cache avec un horodatage « valeur connue au ». Si un appel touche à de l'argent ou à la sécurité, soyez explicite sur l'incertitude.
Gardez les décisions de repli proches du wrapper. Le reste de l'appli doit appeler sendEmail() ou chargeCard() et recevoir un résultat clair.
Une erreur courante dans les prototypes hérités est l'appel d'une API tierce depuis plusieurs routes avec des comportements de retry différents. Ça marche en test, puis ça temporise en prod et déclenche des retries partout. Un wrapper avec un vrai timeout, un échec rapide et une fenêtre de refroidissement arrête l'entassement et protège votre base et vos files.
Concevoir des replis que les utilisateurs acceptent
Les disjoncteurs arrêtent l'hémorragie. Les replis maintiennent l'utilisateur en mouvement. Un bon repli est honnête, sûr et facile à expliquer.
Commencez par nommer l'objectif utilisateur pour chaque appel dépendant. Si l'objectif est « voir mon solde », un repli peut être « afficher le dernier solde connu avec un horodatage ». Si l'objectif est « terminer le checkout », un repli peut être « enregistrer la commande et confirmer plus tard », pas « faire semblant que c'est passé ».
Types de repli utiles : données en cache, travail en file d'attente, UI dégradée, revue manuelle, et fournisseurs alternatifs (seulement s'ils sont réellement équivalents). La règle la plus importante : ne mentez pas. Les gens pardonnent « Nous confirmerons bientôt » bien plus que des doubles prélèvements.
Décidez quand afficher un message versus dégrader silencieusement selon l'impact. Si l'utilisateur peut prendre une mauvaise décision (argent, sécurité, délais), affichez un message clair et une prochaine étape. Si c'est cosmétique, une dégradation silencieuse peut suffire.
Rendez-le observable (pour corriger vite)
Des replis sans logs transforment les incidents en suppositions. Capturez suffisamment de contexte pour comprendre ce qui s'est passé :
- Ce que l'utilisateur a essayé de faire (et les entrées clés que vous pouvez stocker en toute sécurité)
- Le statut du fournisseur (timeout, 500, rate limit, circuit ouvert)
- Un ID de corrélation traversant la requête, l'appel fournisseur et le chemin de repli
- Le résultat (mis en file, mis en cache, revue manuelle créée)
- Le message affiché à l'utilisateur
Les apps générées par l'IA ont parfois des replis, mais personne ne sait quel chemin a été emprunté. La correction est simple : rendez chaque repli explicite, traçable et honnête.
Un exemple réaliste : le fournisseur de paiements commence à céder en pleine journée
Il est 12h10 un mardi. Votre checkout est sain, mais dépend d'une API de paiements tierce. Le fournisseur commence à temporiser. Pas d'échec net, juste des blocages de 10 à 20 secondes.
Sans protection, le problème s'étend. Chaque requête checkout attend, puis retry. Les requêtes coincées s'accumulent, monopolisant workers et connexions BD. Les clients rafraîchissent et recliquent sur « Payer ». Certaines requêtes passent, d'autres non, et vous vous retrouvez avec des pages lentes, des tentatives en double et une boîte support remplie de « Ai-je été facturé ? ».
Avec un disjoncteur, l'histoire change vite. Après une courte série de timeouts, le disjoncteur s'ouvre pour le client paiements. Le checkout ne met plus 20 secondes à apprendre l'évidence. Il échoue vite et affiche un message clair comme : « Les paiements sont temporairement indisponibles. Votre commande est enregistrée. Réessayez dans quelques minutes. »
Au lieu de lancer d'autres appels de paiement, l'appli enregistre l'intention (panier, total, utilisateur, ID commande en attente). Si possible, mettez un essai de paiement en file d'attente ou proposez une méthode alternative. L'essentiel est que les utilisateurs obtiennent un résultat rapide et honnête, et que le système reste réactif.
Quand le disjoncteur s'ouvre, vous obtenez aussi des signaux plus propres : « dépendance paiements en panne » plutôt qu'une lenteur vague partout. La récupération n'est pas un travail de héros. Après la fenêtre de réinitialisation, le circuit passe en semi-ouvert, envoie quelques probes contrôlés, puis se referme si le fournisseur est à nouveau sain.
Erreurs courantes qui aggravent les pannes
Les pannes empirent généralement parce que l'application continue d'appuyer, d'attendre et de se bloquer jusqu'à ce que tout déborde. Les disjoncteurs aident, mais seulement si vous évitez quelques pièges.
Les retries immédiats et sans fin sont un amplificateur classique. Si un fournisseur fait un accroc et que des milliers de clients retentent en même temps, vous créez votre propre pic de trafic et prolongez la panne du fournisseur.
Les timeouts manquants sont un autre problème. Sans timeout clair, les requêtes restent bloquées, les files grandissent, les serveurs ralentissent, et bientôt même les parties saines de l'appli paraissent cassées.
Faites aussi attention à la portée du disjoncteur. Un disjoncteur global partagé entre des fonctionnalités non liées est dangereux. Une panne paiement ne devrait pas empêcher la connexion ou la lecture de données personnelles. Scoppez les disjoncteurs à une dépendance unique et à un type d'appel unique.
Cinq signaux d'alerte rapides :
- Retries qui partent instantanément et sans fin (pas de backoff, pas de plafond)
- Timeouts manquants ou si longs que les requêtes s'accumulent
- Un disjoncteur partagé entre de nombreuses dépendances ou endpoints
- Un repli qui signale « succès » alors que l'action n'a pas eu lieu
- Un circuit qui s'ouvre mais ne sonde jamais pour récupérer
Des replis qui ne mentent pas
Le repli le plus dommageable cache la défaillance. Si un utilisateur clique sur « Payer maintenant », que le fournisseur échoue, et que l'appli affiche « Paiement accepté », vous aurez des litiges et des clients en colère.
Un repli plus sûr est honnête et précis : « Nous n'avons pas pu traiter le paiement. Votre commande est enregistrée. Réessayez dans quelques minutes. » Quand c'est possible, gardez l'utilisateur en mouvement : sauvegardez la progression, offrez un accès en lecture seule, ou fournissez un flux alternatif.
Vérifications rapides à faire aujourd'hui
Quelques contrôles rapides peuvent éviter la journée « un fournisseur est instable, tout fond ». Commencez par vos trois principales dépendances externes (paiements, auth, email/stockage) et inspectez les chemins de code qui les appellent :
- Chaque appel sortant a un vrai timeout choisi intentionnellement.
- Les retries sont plafonnés et volontaires. Ne retentez rien qui peut provoquer des doubles charges ou écritures sans idempotence.
- Chaque dépendance critique a un plan B que l'utilisateur peut comprendre.
- Les changements d'état du disjoncteur sont visibles dans les logs (et idéalement sur un tableau de bord).
- La récupération est automatique via des probes semi-ouvertes sûres.
Pour tester rapidement, simulez une panne de fournisseur pendant cinq minutes dans un environnement sûr. Faites échouer l'appel (réseau bloqué, 500 forcé), confirmez que les utilisateurs obtiennent un résultat prévisible (message, cache ou travail en file), confirmez que le disjoncteur s'ouvre, puis restaurez le fournisseur et vérifiez qu'il récupère sans surveillance manuelle.
Prochaines étapes : rendre les pannes de dépendances ennuyeuses, pas catastrophiques
Notez vos dépendances principales et les parcours utilisateur exacts qu'elles touchent : « Checkout », « Connexion », «Réinitialisation de mot de passe », «Envoyer une invitation ». Ensuite, décidez ce qui est « assez bien » si chacune est indisponible. Parfois la bonne réponse est simplement d'échouer vite avec un message clair et un réessai sûr plus tard.
Ensuite, ajoutez une couche de wrapper par fournisseur pour que timeouts, retries, le pattern de disjoncteur et la journalisation vivent au même endroit. Si vous ne faites qu'une chose cette semaine, choisissez la dépendance liée aux revenus ou à l'accès.
Si vous héritez d'une app générée par l'IA qui s'effondre sous la charge réelle, FixMyMess (fixmymess.ai) peut réaliser un audit de code gratuit et pointer les timeouts manquants, les boucles de retry risquées et la gestion faible des pannes de dépendances. Il est souvent possible de stabiliser rapidement les pires intégrations en ajoutant des wrappers propres, des défauts sensés et des replis honnêtes.
Questions Fréquentes
Qu'est-ce qu'une défaillance en cascade, en termes simples?
Une défaillance en cascade survient lorsqu'une dépendance lente ou défaillante fait attendre votre application, et que ces requêtes en attente s'accumulent jusqu'à ce que les parties saines manquent de threads, connexions ou capacité de file d'attente. La solution consiste à arrêter d'attendre indéfiniment et à cesser d'appeler sans cesse le service défaillant pour que le reste de l'application reste réactif.
En quoi un disjoncteur diffère-t-il de l'ajout de timeouts et retries ?
Un disjoncteur est une règle autour d'un appel externe qui empêche les requêtes d'atteindre une dépendance lorsqu'elle est manifestement malsaine. Plutôt que de rester bloquée, votre appli échoue rapidement et renvoie un résultat contrôlé (comme des données en cache ou « réessayez plus tard »), ce qui évite d'engorger vos serveurs.
Comment choisir un timeout raisonnable pour une requête visible par l'utilisateur ?
Commencez par la tolérance utilisateur : pour un clic de bouton ou un chargement de page, visez un timeout court qui garde l'interface réactive (souvent quelques secondes, pas 20). Si l'appel est optionnel, rendez le timeout encore plus court et dégradez gracieusement l'interface ; si c'est critique, échouez vite avec un message clair plutôt que de laisser les requêtes s'accumuler.
Quand devrais-je éviter les retries, et quand sont-ils sûrs ?
Évitez les retries par défaut sur tout ce qui peut provoquer des effets secondaires dupliqués (prélèvements, envois, écritures). Les retries sont sûrs pour des lectures idempotentes, et encore là, ajoutez du backoff et limitez le nombre pour ne pas amplifier une panne.
Où devrais-je ajouter des disjoncteurs en priorité pour un impact maximal ?
Placez des disjoncteurs autour des appels synchrones sur le chemin critique : vérifications d'authentification, checkout/paiements, email/SMS pour codes, et toute API nécessaire pour rendre vos écrans principaux. Vous aurez le plus d'impact là où une dépendance peut bloquer beaucoup de requêtes et monopoliser des ressources partagées comme les pools de connexions.
Que signifient réellement les états fermé, ouvert et semi-ouvert ?
« Fermé » signifie que les appels circulent normalement et que vous suivez les échecs. « Ouvert » signifie que vous bloquez temporairement les appels et renvoyez une réponse contrôlée. « Semi-ouvert » signifie qu'après un délai de refroidissement vous laissez passer un petit nombre d'appels de test pour vérifier si la dépendance est à nouveau saine avant de refermer complètement le circuit.
Quel est un bon repli lorsque un fournisseur est indisponible ?
Un bon repli permet à l'utilisateur de continuer sans prétendre que tout a fonctionné. Par exemple, si l'envoi d'email échoue, acceptez l'inscription et mettez l'email en file d'attente ; si une API de tarification tombe, affichez les dernières valeurs connues avec un horodatage et un avertissement. Pour l'argent ou la sécurité, indiquez clairement ce qui s'est réellement passé.
Dois-je utiliser un disjoncteur global pour tout ?
Non : adaptez la portée du disjoncteur à la dépendance et au type d'appel, pas à toute l'application. Une panne de paiement ne doit pas empêcher la lecture des profils, et une panne d'email ne doit pas casser la connexion. Si vous écartez trop, une dépendance instable peut désactiver inutilement des fonctionnalités non liées.
Comment tester les disjoncteurs sans provoquer une vraie panne ?
Simulez la défaillance de la dépendance pendant quelques minutes dans un environnement sûr et vérifiez trois points : les requêtes échouent vite, les utilisateurs voient un résultat prévisible, et le système reste réactif sous charge. Restaurez ensuite la dépendance et confirmez que le circuit passe par des probes en semi-ouvert et récupère automatiquement sans intervention manuelle.
Pourquoi les apps générées par l'IA échouent-elles si gravement avec des fournisseurs instables, et que peut faire FixMyMess ?
Le code généré par l'IA propose souvent uniquement le « happy path » : timeouts longs ou absents, boucles de retry agressives, et appels fournisseurs dispersés. Si vous avez hérité d’un prototype qui fond sous la charge réelle, FixMyMess peut réaliser un audit de code gratuit et stabiliser rapidement les pires intégrations en ajoutant des wrappers propres, des timeouts sensés et des repli honnêtes, souvent en 48–72 heures.