Épuisement du pool de connexions : réglages pour le serverless
Comprenez pourquoi l’épuisement du pool de connexions arrive même avec peu de trafic, et comment configurer le pooling pour serverless vs serveurs longuement actifs afin d’éviter des pannes.
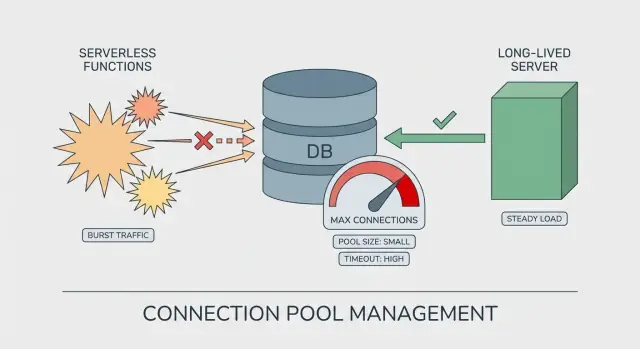
À quoi ressemble l’épuisement du pool en production
L’épuisement du pool de connexions signifie que votre application ne peut pas obtenir une connexion à la base de données quand elle en a besoin. Les requêtes s’accumulent, l’application attend, puis abandonne après un timeout. Pour les utilisateurs, c’est comme si le site cassait de manière aléatoire.
La plupart des équipes le remarquent d’abord comme « tout est lent » même si le CPU et le trafic semblent normaux. Des pages qui chargent normalement en une seconde se bloquent 10 à 30 secondes, puis échouent. Ça touche souvent en premier les flux sensibles : connexion, paiement, enregistrement d’un formulaire.
Les symptômes visibles côté utilisateur ressemblent souvent à :
- Pages lentes qui parfois reviennent après un rafraîchissement
- Erreurs 500 aléatoires qui disparaissent puis reviennent
- Échecs de connexion ou sessions qui tombent
- Jobs en arrière-plan qui ne progressent plus
- Applications mobiles qui time-out sur des actions simples
Côté ingénierie, le schéma est plus précis : les files de requêtes grandissent, on passe plus de temps à attendre la base, et les logs montrent des erreurs comme « timeout acquiring connection ». Sur la base, les connexions actives peuvent être proches de la limite ou monter en pics courts.
Ce qui est déroutant, c’est le décalage : le trafic peut sembler « léger » alors que le système est bloqué en attente.
Une cause fréquente est qu’un petit nombre de requêtes gardent des connexions plus longtemps que prévu. Une requête lente, une transaction laissée ouverte, ou du code qui oublie de libérer un client peut bloquer le pool. Après cela, même quelques utilisateurs peuvent déclencher un embouteillage.
Pourquoi cela arrive même avec un trafic léger
« Utilisateurs en ligne » n’est pas la même chose que « connexions actives à la base ». La plupart des bases autorisent moins de connexions concurrentes qu’on ne le pense, et chaque connexion coûte en mémoire et CPU.
Avec Postgres, max_connections est souvent configuré de façon conservatrice. Même une limite comme 100 peut être trop élevée en pratique si chaque connexion est lourde. Ajoutez les outils d’admin, les workers en arrière-plan, les migrations et les scripts ponctuels, et vous pouvez être à court plus vite qu’attendu.
De plus, une seule requête peut toucher la base plusieurs fois : la requête principale, un write analytics, une mise à jour de session, et peut-être l’envoi d’un job. Si ces accès ne sont pas gérés, un « trafic léger » génère beaucoup de travail concurrent.
L’épuisement du pool provient généralement d’un ou plusieurs de ces facteurs :
- Fuites de connexions après erreurs ou timeouts, qui ne retournent jamais au pool
- Requêtes lentes qui gardent les connexions plus longtemps, forçant les autres requêtes à attendre
- Retries qui multiplient le trafic (retries client, server, ORM)
- Bruit de fond comme bots, cron jobs, health checks, polling de queues
- Tâches de démarrage ou migrations ouvrant des connexions supplémentaires au mauvais moment
Un exemple concret : vous avez 10 utilisateurs, mais un endpoint exécute parfois une requête de 4 secondes. Avec un pool de 10, une petite rafale (rafraîchissements, retries, ou un bot) peut occuper toutes les connexions. Les nouvelles requêtes attendent, atteignent le timeout d’acquisition, échouent, retentent, et empirent le pic.
Les pannes sous « trafic léger » concernent généralement la durée de vie et la concurrence des connexions, pas le nombre brut de requêtes.
Serverless vs serveurs longuement actifs : la différence de pooling
Sur un serveur longuement actif (VM, container, serveur d’application classique), le processus reste en ligne pendant des heures ou des jours. Le pool DB est réutilisé sur beaucoup de requêtes. Il se « réchauffe », s’établit dans un pattern stable, et on peut raisonner sur le nombre de connexions existantes.
Serverless est différent. Votre code peut tourner dans de nombreuses instances éphémères. Chaque instance peut créer son propre pool, même si elle ne gère que quelques requêtes. C’est ainsi que l’épuisement du pool apparaît malgré un trafic qui semble faible : le trafic est réparti sur plus d’instances que prévu.
Pourquoi le serverless multiplie les connexions
La hausse provient généralement des cold starts et des événements d’auto-scaling. Quand la plateforme veut plus de parallélisme, elle démarre plus d’instances, et chacune peut ouvrir son propre ensemble de connexions.
Une taille de pool qui semble sûre sur un serveur peut être risquée en serverless :
- Serveur longuement actif : 1 instance x pool de 20 = ~20 connexions
- Rafale serverless : 30 instances x pool de 20 = ~600 connexions
Même brève, cette rafale peut suffire à atteindre les limites de Postgres, ralentir les requêtes et provoquer des timeouts.
Une façon simple d’y penser
Sur des serveurs longuement actifs, on règle le pool pour la réutilisation et le débit. En serverless, on le règle pour le rayon d’impact : supposez qu’il peut y avoir de nombreuses copies de votre app actives en même temps.
Chiffres à collecter avant de modifier les paramètres
Deviner les réglages du pool transforme de petits problèmes en incidents de production. Avant de toucher quoi que ce soit, collectez quelques chiffres pour savoir si vous manquez de connexions, si vous les gardez trop longtemps, ou les deux.
Commencez par la limite de la base. Trouvez max_connections de Postgres, puis listez qui les utilise : votre app, outils d’admin, workers en arrière-plan, migrations, outils BI, replicas en lecture. Beaucoup d’équipes pensent avoir « 100 connexions » alors que 30 sont déjà prises.
Ensuite, concentrez-vous sur la concurrence, pas le trafic journalier. Un site à 200 utilisateurs par jour peut quand même monter à 20 requêtes concurrentes si une page déclenche plusieurs appels API ou si quelques personnes rafraîchissent en même temps. Regardez le pic de requêtes concurrentes pendant vos 5 à 15 minutes les plus chargées, et segmentez par instance (ou par fonction en serverless).
La vitesse des requêtes compte autant que le nombre de connexions. Repérez les requêtes lentes par temps total et par latence p95/p99. Quelques requêtes de 2 à 5 secondes peuvent bloquer des connexions assez longtemps pour tout arrêter.
Les signaux qui expliquent habituellement les pannes « soudaines » :
- Connexions ouvertes vs limite Postgres, et la vitesse de leur croissance
- Temps d’attente de connexion (temps passé à attendre une connexion libre)
- Timeouts du pool et pics d’erreurs (fréquence et horodatage)
- Concurrence des requêtes au moment où les erreurs commencent
- Si les workers en arrière-plan partagent la même base et le même pool
Un check rapide : si votre timeout d’acquisition est de 10 secondes et que vous observez une latence API de bout en bout de 12 secondes, les utilisateurs blâment « le serveur » alors que le retard réel vient de l’attente d’une connexion.
Pas à pas : tuning du pooling pour serveurs longuement actifs
Sur des serveurs longuement actifs (VM, containers, pods always-on), le piège principal est d’oublier que chaque processus peut avoir son propre pool. Dix workers web avec un pool de 20 ne font pas 20 connexions, c’est jusqu’à 200.
Commencez par un objectif qui laisse de la marge sous la limite de la DB. Si Postgres permet 100 connexions, vous ne voulez rarement que votre app puisse prendre les 100. Laissez de la place pour les migrations, sessions admin, outils et déploiements.
1) Définir une taille de pool qui correspond à la vraie concurrence
Pensez en « combien de requêtes font des queries en même temps », pas « combien d’utilisateurs ». Les requêtes lentes prolongent la durée d’utilisation d’une connexion, ce qui augmente la taille de pool nécessaire.
Approche pratique : fixez un budget total de connexions pour toute l’application (souvent 60% à 80% de la limite DB), puis divisez-le entre les processus qui se connectent. Commencez petit et augmentez seulement si vous voyez de la mise en file et que la base a encore de la marge. Budgétez séparément les workers de jobs.
2) Ajouter des timeouts qui échouent vite (et permettent la récupération)
Deux paramètres évitent les accumulations silencieuses : le timeout d’acquisition (combien de temps une requête attend pour une connexion) et le timeout d’inactivité (combien de temps une connexion inutilisée reste ouverte). Des timeouts d’acquisition courts transforment un effondrement lent en une erreur visible et contenue que vous pouvez alerter.
Si vous devez choisir, un petit pool avec des timeouts clairs est plus sûr qu’un gros pool qui pousse la base dans la surcharge.
3) Limiter la concurrence au-dessus du pool
Si votre serveur peut accepter 500 requêtes concurrentes mais que votre budget DB total est de 60 connexions, il vous faut un plafond : nombre de workers, concurrence des requêtes, ou parallélisme des job runners.
Vérifiez ensuite que les connexions sont toujours retournées, y compris sur les chemins d’erreur. Cherchez les finally manquants, transactions abandonnées, ou sessions ORM longues.
Pas à pas : tuning du pooling pour serverless
Serverless change les calculs. Le code peut être identique, mais la plateforme peut créer beaucoup d’instances courtes en même temps.
1) Fixer des caps stricts par instance
Rendez chaque instance « petite » du point de vue de la base. Dans beaucoup de setups serverless, vous ne voulez pas d’un grand pool à l’intérieur de chaque fonction.
Règles simples :
- Limitez la taille du pool à un faible nombre (souvent 1 à 4 par instance)
- Utilisez un timeout d’acquisition court pour que les requêtes échouent vite au lieu de s’accumuler
- Utilisez un timeout d’inactivité pour que les connexions inutilisées se ferment rapidement
- Réutilisez le pool entre invocations (créez-le une fois, en dehors du handler)
- Assurez-vous que chaque requête libère la connexion, même en cas d’erreur
Check de sanity : si Postgres autorise 100 connexions et que la plateforme peut lancer 50 instances, un pool de 5 par instance peut tenter 250 connexions. C’est suffisant pour casser la prod.
2) Contrôler la concurrence avant d’atteindre la DB
Votre meilleur « pool » est souvent une limite de concurrence. Limitez combien de requêtes une version du service peut exécuter en parallèle. Cela empêche un nouveau déploiement, une tempête de retries ou une rafale de jobs de submerger la base.
Surveillez aussi le parallélisme caché : batchs avec Promise.all, handlers de webhooks qui se dispersent, consommateurs de queue qui traitent plusieurs messages à la fois. Ces patterns multiplient les connexions même avec peu de trafic utilisateur.
3) Utiliser un pooler externe ou un proxy géré quand c’est possible
Si votre plateforme propose un proxy DB (ou si vous pouvez exécuter un pooler externe), il peut absorber l’échelle serverless et stabiliser les connexions à la base. Sachez toutefois que le proxy a ses propres limites : il peut manquer de capacité ou mettre les requêtes en file plus longtemps que le timeout de votre fonction.
Un mode d’échec réaliste est « nouveau pool par requête » plus retries. Dix invocations concurrentes peuvent devenir 30 tentatives de connexion en quelques secondes.
Garde-fous pour empêcher qu’un petit souci ne devienne une panne
La plupart des incidents d’épuisement du pool commencent par un léger ralentissement. Quelques requêtes attendent un peu plus, puis tout s’accumule. Les garde-fous consistent à échouer vite, à reculer et à garder l’application utilisable pendant que la base se rétablit.
Décidez d’un comportement d’échec clair. Si une requête ne peut pas obtenir rapidement une connexion, elle doit s’arrêter et retourner une erreur claire, pas rester bloquée jusqu’au timeout en amont. Des timeouts courts protègent aussi vos workers car ils libèrent des threads et votre service peut continuer à répondre.
Les retries doivent avoir des limites strictes. Retenter chaque requête échouée peut transformer un hic en une ruée. Limitez les retries aux opérations sûres (lectures idempotentes), ajoutez du jitter (délai aléatoire) et cappez le temps total de retry.
Les circuit breakers sont l’étape suivante. Quand vous observez des échecs DB répétés, ouvrez le breaker pour une courte fenêtre et échouez immédiatement les nouvelles requêtes dépendantes de la DB. Mieux vaut échouer vite que tirer tout le système dans un effondrement lent.
La dégradation gracile garde les utilisateurs en mouvement. Selon votre produit, cela peut signifier un mode lecture seule quand les écritures échouent, servir des résultats mis en cache pour les lectures communes, désactiver temporairement des fonctionnalités lourdes comme les rapports, ou retourner un message convivial « réessayez dans 30 secondes » pour les endpoints dépendants de la DB.
Alertez sur des signaux précoces, pas seulement sur les erreurs dures. L’augmentation du temps d’attente de connexion, la profondeur de file qui grandit et la hausse de la latence p95 apparaissent souvent quelques minutes avant « trop de connexions ».
Erreurs courantes qui déclenchent un épuisement soudain du pool
La plupart des incidents ne proviennent pas d’une énorme montée du trafic. Ils surviennent quand quelques décisions empilent et mangent votre marge de sécurité.
Un piège fréquent est de dimensionner le pool de l’app à la limite DB. Si Postgres permet 100 connexions et que vous mettez votre pool à 100, vous n’avez laissé aucune marge pour les migrations, outils admin, workers ou une seconde copie de l’app pendant un déploiement.
L’auto-scaling serverless est une autre cause fréquente. Si chaque instance fonction crée son propre pool, vous n’avez pas « un pool de 20 », vous avez « 20 fois N instances », ce qui peut transformer un trafic léger en tempête de connexions en secondes.
Les erreurs qui déclenchent le plus souvent une panne soudaine :
- Utiliser le max DB comme taille du pool de l’app au lieu de réserver une marge
- Créer un pool séparé par instance serverless (ou par requête)
- Fuite de connexions sur les chemins d’erreur (retours précoces, exceptions, requêtes annulées)
- Garder les connexions trop longtemps (requêtes lentes, index manquants, transactions longues)
- Laisser le bruit de fond concurrencer les vrais utilisateurs (health checks, cron jobs, polling de queue)
Un pattern réaliste : une app « idle » où un health check frappe toutes les quelques secondes, un cron tourne chaque minute, et une requête lente prend 10 secondes. Avec un petit pool, quelques recouvrements suffisent à le remplir.
Checklist rapide avant mise en production
Beaucoup d’incidents qualifiés d’épuisement du pool sont en fait des vérifications finales manquantes : limites inconnues, timeouts incohérents, concurrence laissée au hasard.
D’abord, écrivez le plafond dur. Postgres a une limite de connexions, et les fournisseurs gérés réservent souvent des connexions pour l’administration. Si vous ne connaissez pas votre maximum utilisable, vous ne pouvez pas dimensionner les pools en sécurité.
Avant la release, confirmez :
- Votre budget de connexions :
max_connections, connexions réservées, et le cap cible pour l’app - Taille du pool et timeouts avec marge, y compris un timeout d’acquisition clair
- Paramètres de concurrence (surtout en serverless) pour qu’un déploiement ne puisse pas créer une vague de nouvelles connexions
- Les requêtes les plus lentes et les corrections principales (index et N+1 accidentel sont courants)
- Visibilité : tableaux de bord et alertes pour le nombre de connexions, le temps d’attente de connexion et les timeouts du pool (pas seulement les 500 génériques)
Un test pratique : lancez un petit test de charge qui correspond au « trafic léger » (quelques utilisateurs qui naviguent), puis surveillez le temps d’attente du pool et les connexions actives. Si l’un ou l’autre monte régulièrement, vous êtes déjà proche d’un incident.
Exemple réaliste : une panne avec seulement quelques utilisateurs en ligne
Une petite SaaS avait un mardi après-midi calme : six personnes connectées, quelques vues de tableau de bord par minute. Puis les utilisateurs ont signalé que la connexion tournait indéfiniment et que le tableau de bord renvoyait des 500 aléatoires.
Dans les logs, l’app n’était pas « down » au sens habituel. CPU ok. Mémoire ok. L’indice réel était des messages répétés comme « timeout acquiring a client » et « remaining connection slots are reserved ». Classique : épuisement du pool, alors que le trafic semblait léger.
Deux petits changements ont été déployés ensemble.
D’abord, un nouveau job en arrière-plan tournait chaque minute pour rafraîchir une table de stats. Ensuite, une requête du tableau de bord est devenue plus lente à cause d’un index manquant. Cette requête a commencé à prendre 8 à 12 secondes, et le job gardait une connexion le temps complet.
Puis le déploiement est passé d’un serveur longuement actif à du serverless. Rien dans le code ne semblait plus risqué, mais le parallélisme a bondi du jour au lendemain. Quelques chargements de pages concurrents plus quelques jobs concurrents ont signifié beaucoup plus de tentatives de connexion simultanées. Chaque instance avait son propre pool, donc le nombre total de connexions ouvertes a rapidement grimpé.
La réparation n’a pas été un réglage magique unique. C’était un ensemble de petits garde-fous :
- Réduire la taille du pool par instance pour que chaque instance ne puisse pas capter trop de connexions
- Caper la concurrence pour que la plateforme ne puisse pas créer un travail parallèle illimité
- Raccourcir les timeouts du pool pour que les requêtes échouent vite et se rétablissent au lieu de s’accumuler
- Optimiser la requête lente (ajouter l’index et réduire les jointures inutiles)
Après cela, l’app est restée stable. Les alertes sur « pool wait time » et « active connections » ont donné à l’équipe un avertissement minutes avant que les utilisateurs ne le ressentent.
Étapes suivantes : stabiliser le pooling et demander un deuxième avis
Si vous venez de lutter contre l’épuisement du pool, ne commencez pas par bricoler des nombres au hasard. Commencez par nommer votre modèle d’exploitation : serverless (beaucoup d’instances courtes), serveurs longuement actifs (peu de processus stables), ou hybride. Le pooling est un problème différent dans chaque cas.
Écrivez un budget de pooling simple qui empêche votre couche applicative d’exiger plus de connexions que Postgres ne peut en fournir en sécurité. Capturez trois choses : votre plafond utilisable de connexions Postgres, votre pic d’instances (ou nombre de rafales) et le cap par instance, et vos timeouts « stop sign » pour que les requêtes échouent vite au lieu de s’accumuler.
Ensuite, lancez un test de charge focalisé qui ressemble à la réalité. Beaucoup d’équipes testent le haut débit mais manquent le pattern qui déclenche l’épuisement : rafales brèves, requêtes lentes et retries. Incluez les flux de connexion/inscription, votre page la plus lente, et des tâches en arrière-plan qui tournent en même temps.
Si vous avez hérité d’une base de code générée par IA, vérifiez les pièges courants : « connect par requête », nettoyage manquant dans les chemins d’erreur, et retries cachés qui multiplient la concurrence. Si vous voulez un contrôle rapide, FixMyMess (fixmymess.ai) propose un audit de code gratuit qui repère où les connexions sont créées, fuient ou sont gardées trop longtemps, pour que vous puissiez corriger la cause au lieu de deviner les nombres du pool.
Questions Fréquentes
Que signifie réellement « épuisement du pool de connexions » ?
Cela signifie que votre application attend une connexion libre à la base de données mais qu’il n’y en a pas. Les requêtes font la queue, atteignent un timeout d’acquisition, et les utilisateurs voient des pages lentes suivies d’échecs intermittents.
Pourquoi l’épuisement du pool se produit-il même quand le trafic semble faible ?
Le CPU et le trafic peuvent sembler normaux parce que l’application ne fait pas plus de travail actif : elle attend. Quelques requêtes qui gardent des connexions plus longtemps que prévu peuvent bloquer tout le pool, donc même un trafic « léger » peut provoquer un arrêt.
Quels sont les symptômes côté utilisateur les plus fréquents en production ?
Cherchez des blocages longs (souvent 10–30 secondes) suivis d’erreurs 500, d’échecs de connexion ou de jobs en arrière-plan qui n’avancent plus. Parfois un rafraîchissement rétablit temporairement la page parce qu’une connexion est libérée, puis le problème revient quand le pool se remplit à nouveau.
Comment les fuites de connexions se produisent-elles généralement dans le code réel ?
Les fuites arrivent quand le code obtient une connexion sans la rendre sur tous les chemins d’exécution, surtout en cas d’erreur. Exceptions non gérées, retours précoces, requêtes annulées et nettoyage manquant sont des façons courantes de coincer des connexions.
Le vrai problème est-il « trop d’utilisateurs » ou autre chose ?
Pensez en termes de concurrence et de durée de maintien des connexions plutôt qu’en nombre d’utilisateurs. Un pool peut gérer un petit nombre de requêtes concurrentes ; si les requêtes sont lentes ou si les transactions restent ouvertes, chaque requête garde une connexion plus longtemps et le pool s’épuise plus vite.
En quoi le pooling est-il différent en serverless comparé aux serveurs longuement actifs ?
Sur des serveurs longuement actifs, le pool est réutilisé dans un processus stable et le nombre total de connexions est plus prévisible. En serverless, beaucoup d’instances courtes peuvent démarrer en même temps et chacune peut créer son propre pool, multipliant rapidement les connexions totales.
Quelles mesures dois-je collecter avant de changer les paramètres du pool ?
Commencez par la limite de la base (comme max_connections de Postgres) et soustrayez les connexions réservées aux outils admin, migrations et workers. Mesurez ensuite les requêtes concurrentes de pointe, le temps d’attente de connexion et quelles requêtes sont lentes au p95/p99, car ces chiffres expliquent la plupart des incidents « soudains ».
Quels timeouts et garde-fous évitent un effondrement progressif ?
Définissez un timeout d’acquisition pour que les requêtes échouent vite au lieu de s’accumuler, et un timeout d’inactivité pour que les connexions inutilisées se ferment. Ensuite, limitez la concurrence des requêtes et des jobs pour que votre application ne puisse pas accepter beaucoup plus de travail parallèle que votre budget de connexions ne le permet.
Quelles sont les plus grandes erreurs qui causent l’épuisement du pool ?
Évitez de fixer la taille du pool de l’application égale au max DB : durant un déploiement, des migrations ou des sessions admin ont aussi besoin de connexions. Évitez aussi de créer un pool par requête, de laisser les retries s’emballer, ou d’exécuter des requêtes lentes dans de longues transactions qui gardent les connexions trop longtemps.
Comment stabiliser rapidement une application générée par IA qui épuise constamment le pool ?
Commencez par vérifier les patterns « connect par requête », le nettoyage manquant lors des erreurs, les retries cachés et les requêtes lentes qui maintiennent des transactions ouvertes : les prototypes générés par IA ont souvent ces défauts. Si vous voulez un avis rapide, FixMyMess (fixmymess.ai) propose un audit de code gratuit qui pointe où les connexions sont créées, fuitent ou sont maintenues trop longtemps pour corriger la cause plutôt que de deviner les paramètres du pool.