Empêcher les doublons d'utilisateurs grâce aux contraintes d'unicité et à un backfill sûr
Apprenez à empêcher les doublons d'utilisateurs avec des contraintes d'unicité, la normalisation des entrées et un plan de backfill sûr qui évite downtime et perte de données.
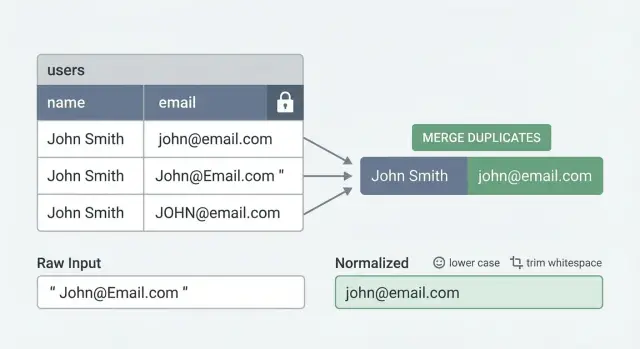
Le vrai problème : pourquoi les doublons d'utilisateurs persistent
Les doublons d'utilisateurs ne ressemblent que rarement à un même e-mail tapé deux fois. Ils apparaissent plutôt sous forme de petites différences que les humains considèrent comme la même personne, mais que la base de données considère comme des valeurs distinctes.
Exemples courants :
- Même e-mail, casse différente :
[email protected]vs[email protected] - Espaces invisibles :
[email protected]vs[email protected] - Méthodes de connexion multiples : un compte créé avec un mot de passe, un autre plus tard via Google ou GitHub utilisant le même e-mail
- Points de création différents : un enregistrement créé pendant le checkout, puis un autre pendant l'onboarding
- Particularités des fournisseurs :
[email protected]utilisé une fois,[email protected]utilisé une autre fois (certaines applis veulent qu'ils soient une seule personne, d'autres non)
Le résultat paraît aléatoire pour les clients. Quelqu'un se connecte avec « l'autre » méthode et arrive dans « l'autre » compte. La facturation peut se fragmenter, un utilisateur payant paraît non payé. Le support se transforme en travail de détective parce que « je ne vois pas mes projets » signifie en réalité « vous avez deux comptes et vos données sont dans l'autre ». L'analytics devient bruyant aussi, si bien que la rétention et la conversion deviennent peu fiables.
Les équipes essaient souvent d'empêcher les doublons dans l'UI : désactiver le bouton, afficher « l'e-mail existe déjà », ou faire une vérification avant de créer l'utilisateur. Ça aide, mais ce n'est pas suffisant. Votre base de données peut recevoir des écritures depuis des apps mobiles, API backend, panels admin, imports, jobs en arrière-plan, webhooks et tentatives de retry après timeout. Deux requêtes peuvent aussi se concurrencer : les deux vérifient « cet e-mail existe ? » en même temps, voient « non » et insèrent toutes les deux.
La protection au niveau base de données est différente. La base applique la règle à chaque écriture, peu importe d'où elle vient. Vous définissez ce qui doit être unique (souvent un e-mail normalisé, ou une combinaison comme provider + provider_user_id), et la base refuse les inserts ou updates qui créeraient un second enregistrement avec la même identité. Cette garde-fou transforme « on essaie de ne pas créer de doublons » en « les doublons ne peuvent plus se produire ».
Façons courantes dont les doublons se créent
Les doublons apparaissent quand l'application suppose que la base de données "s'en chargera". Si la base n'applique pas l'unicité, les cas limites deviennent beaucoup de lignes pour la même personne, et vous vous retrouvez à tenter d'empêcher les doublons uniquement avec du code applicatif.
Une cause fréquente est une condition de course lors de l'inscription. Deux requêtes peuvent atteindre votre serveur presque en même temps (double tap, connexion instable, deux onglets). Si les deux exécutent « vérifier si l'utilisateur existe » avant que l'une insère, les deux concluent que l'utilisateur est nouveau.
Une autre source courante est la multiplicité des points d'entrée qui créent des utilisateurs : web, mobile, admin, import CSV, flux d'invitation, outil support. Chaque chemin accumule ses propres règles. L'un supprime les espaces, un autre non. L'un vérifie l'existence, l'autre l'ignore « juste pour cette fonctionnalité ».
OAuth peut aussi fragmenter les identités. Un utilisateur s'inscrit avec e-mail/mot de passe, puis clique « Continuer avec Google » en utilisant le même e-mail. Si le callback OAuth crée une nouvelle ligne utilisateur au lieu de lier à l'existante, vous avez deux comptes valides.
Les différences de format d'entrée créent des doublons sournois :
- Casse et espaces dans l'e-mail (
[email protected]vs[email protected]) - Formatage des téléphones (
+1 555 123 4567vs5551234567) - Champs optionnels arrivant plus tard (l'utilisateur commence par un téléphone, ajoute un e-mail ensuite)
- Variations internationales (indicatifs, zéros initiaux)
- Homologues Unicode (rare mais réel)
Les retries et timeouts peuvent aussi causer des doublons. Si un client ne reçoit pas de réponse (coupure réseau, gateway timeout), il peut réessayer automatiquement. Si votre serveur traite chaque retry comme une nouvelle inscription au lieu de la même intention, vous obtenez des doublons. C'est particulièrement courant dans des prototypes où la logique d'inscription est copiée entre routes sans idempotence ni contraintes en base.
Définir ce que « utilisateur unique » signifie pour votre produit
Avant d'ajouter des contraintes, décidez ce que « utilisateur unique » signifie dans votre système. La plupart des doublons apparaissent parce que le produit a plusieurs définitions de l'identité.
Commencez par les identifiants que vous considérez fiables : e-mail, numéro de téléphone et IDs fournisseurs externes (subject Google, id GitHub, subject SSO entreprise). Si vous supportez plusieurs méthodes de connexion, décidez si elles pointent toutes vers une seule ligne utilisateur, ou si chaque méthode peut créer sa propre ligne qui sera liée plus tard.
Ensuite, traitez explicitement les cas ambigus :
- Que faire si l'e-mail est vide, non vérifié ou masqué (Apple private relay) ?
- Autorisez-vous des utilisateurs invités qui ne s'inscrivent jamais ?
- Si l'e-mail peut être
NULL, autorisez-vous plusieursNULL(souvent oui) et comment un invité devient-il un compte réel ?
La portée tenant/workspace importe tout autant. L'unicité est-elle globale ou par tenant ? Dans beaucoup d'applis B2B, le même e-mail peut exister dans différents workspaces mais doit être unique à l'intérieur d'un workspace. Dans une appli grand public, on veut habituellement l'unicité globale.
Un scénario concret à décider d'emblée : quelqu'un s'inscrit avec Google le lundi, puis s'inscrit avec e-mail/mot de passe le mardi avec le même e-mail. Si votre définition est « une personne = une ligne », vous avez besoin d'une règle de fusion et il faut l'écrire.
Une politique de fusion simple :
- Choisir un enregistrement « primaire » (l'e-mail vérifié l'emporte ; sinon dernière connexion).
- Conserver les champs sensibles du primaire (hash de mot de passe, paramètres MFA).
- Fusionner les champs de profil (nom, avatar) seulement s'ils manquent sur le primaire.
- Repointer les données liées (commandes, participations, clés API) vers le primaire.
- Laisser une note d'audit pour pouvoir expliquer ce qui s'est passé plus tard.
Écrivez ces règles en langage simple avant de toucher la base. Cela aligne ingénierie, support et produit quand les vrais cas limites apparaissent.
Normaliser les entrées pour que la base puisse faire respecter l'unicité
Les contraintes d'unicité ne fonctionnent que si les valeurs que vous stockez sont cohérentes. Si une même personne peut s'inscrire comme [email protected], [email protected] et [email protected], la base voit trois chaînes différentes.
La normalisation consiste à choisir un format de stockage pour une même identité et à toujours écrire ce format en base. C'est l'étape discrète qui permet à une contrainte d'unicité d'être réellement efficace.
Ce qu'il faut normaliser (et les précautions)
Pour l'e-mail, commencez simplement : supprimez les espaces et mettez en minuscules avant de sauvegarder. Décidez comment traiter le plus-addressing ([email protected]). Certaines équipes suppriment la partie +... pour réduire les doublons, mais c'est spécifique au fournisseur et pas toujours sûr. Un défaut plus sûr est lowercase + trim, et n'ajoutez le traitement du + que si vous êtes sûr que cela correspond à vos règles produit.
Pour les numéros de téléphone, stockez un format cohérent, idéalement avec l'indicatif pays et uniquement les chiffres. Sinon +1 (415) 555-0123 et 4155550123 peuvent passer à travers l'unicité.
Pour les noms d'utilisateur, alignez-vous sur le comportement produit. Si votre UI traite Jane et jane comme identiques, votre backend doit normaliser de la même façon avant l'insertion.
Un pattern pratique est de stocker les deux :
- L'entrée brute (ce que l'utilisateur a tapé, utile pour l'affichage et le support)
- La valeur normalisée (celle sur laquelle vous appliquez l'unicité)
L'application côté backend prime sur les indices côté frontend
Normalisez dans le backend à chaque création ou mise à jour d'utilisateur. Les vérifications côté frontend améliorent l'UX, mais elles sont faciles à contourner (anciens clients, apps multiples, appels API directs).
Un mode d'échec courant : un fondateur importe des utilisateurs depuis un CSV pendant que des inscriptions ont lieu. L'import garde la casse d'origine, le formulaire d'inscription force en minuscules, et maintenant vous avez deux comptes pour le même e-mail. La normalisation côté backend plus une contrainte sur la valeur normalisée empêchent cette divergence.
Choisir la bonne contrainte d'unicité pour votre schéma
Une contrainte d'unicité est une règle appliquée par la base : deux lignes ne peuvent pas partager la même valeur « unique ». Un index unique est le mécanisme qui rend la vérification rapide. Beaucoup de bases créent un index unique automatiquement quand vous ajoutez une contrainte, donc la différence pratique est surtout d'intention et d'outillage.
La difficulté est de choisir les bonnes colonnes. « L'e-mail doit être unique » semble simple, mais ça casse vite quand vous ajoutez des équipes, plusieurs fournisseurs d'auth, des e-mails optionnels ou des soft deletes.
Quand utiliser l'unicité composite
Si les utilisateurs appartiennent à un workspace ou tenant, vous voulez souvent l'unicité à l'intérieur de ce tenant, pas globalement. Cela devient une règle composite, par exemple :
tenant_id + normalized_email(le même e-mail peut exister dans des tenants différents)provider + provider_user_id(l'identité vraie pour les logins OAuth)tenant_id + provider + provider_user_id(commun quand une même identité provider peut rejoindre plusieurs tenants)
L'unicité composite aide aussi quand vous supportez à la fois mot de passe et OAuth. Vous pouvez appliquer une règle forte pour chaque type d'identité sans forcer un champ (comme l'e-mail) à tout gérer.
Unicité partielle et soft deletes
Les données réelles sont désordonnées. Certains utilisateurs n'ont pas d'e-mail encore, ou vous autorisez des comptes uniquement téléphone. Dans ce cas, imposez l'unicité seulement quand la valeur existe (règle partielle). Un exemple courant : "l'e-mail doit être unique, mais seulement pour les lignes où l'e-mail est présent".
Les soft deletes impliquent une autre décision. Si vous marquez les utilisateurs comme supprimés plutôt que de les supprimer, choisissez et encodez une politique :
- Unique parmi les utilisateurs actifs uniquement (permet la réinscription avec le même e-mail)
- Unique pour tous les utilisateurs, y compris supprimés (empêche la réutilisation et simplifie l'audit)
Prévoyez la gestion des doublons existants avant d'appliquer l'unicité
Activer l'unicité quand des doublons existent déjà va échouer, ou bloquer les inscriptions au pire moment. Avant d'imposer quoi que ce soit, inventairez les doublons, décidez quel enregistrement « gagne », et assurez-vous que les références (sessions, commandes, participations) peuvent être déplacées en sécurité.
Procédure pas à pas : déployer l'unicité sans downtime
L'objectif est d'empêcher les doublons sans geler les inscriptions ni bloquer les connexions. L'approche la plus sûre est d'ajouter d'abord les éléments, de les remplir progressivement, de corriger les cas sales, puis seulement demander à la base d'appliquer l'unicité.
Séquence de déploiement sécurisée
Commencez par ajouter une clé normalisée que la base peut comparer de façon fiable. Pour l'e-mail, cela signifie généralement une version en minuscules et sans espaces (plus les règles produit).
Un déroulé pratique :
- Ajoutez une nouvelle colonne pour la valeur normalisée (ex :
email_normalized) et mettez à jour votre appli pour que chaque nouvelle inscription écrive à la foisemailetemail_normalized. - Backfillez
email_normalizedpour les utilisateurs existants en petits lots (plages d'ID ou fenêtres temporelles) afin que chaque lot finisse rapidement. - Exécutez une détection des doublons en utilisant la clé normalisée et regroupez les collisions (par exemple, toutes les lignes où
email_normalized = "[email protected]"). - Résolvez chaque groupe avant d'imposer l'unicité : choisissez un gagnant, fusionnez les données nécessaires, et marquez les autres comme fusionnés/désactivés.
- Ajoutez l'index/contrainte unique seulement après que les doublons ont disparu, en utilisant une option en ligne si votre base la supporte.
Exemple concret : un prototype peut stocker [email protected], [email protected] et [email protected] comme trois utilisateurs distincts. Une fois que vous backfillez email_normalized = "[email protected]", ces lignes entrent en collision et forment un groupe à fusionner.
Minimiser les locks et les surprises
La plupart des downtimes arrivent quand un changement force des locks longs de table. Gardez chaque opération rapide et prévisible.
Quelques règles utiles :
- Backfillez avec une taille de lot stricte et un timeout. Si un lot ne finit pas rapidement, rendez-le plus petit.
- Faites en sorte que l'appli écrive la valeur normalisée avant de commencer le backfill. Sinon de nouvelles lignes arrivent avec des nulls et vous ne rattrapez jamais le retard.
- Surveillez les « nouveaux doublons par heure » pendant le déploiement. Si ça monte en flèche, quelque chose écrit encore des clés incohérentes.
- Créez l'index unique d'une façon qui évite de bloquer les écritures (par exemple création "concurrente/en ligne", selon votre base).
Plan de backfill : trouver et fusionner les doublons en sécurité
Le backfill est moins une question de SQL sophistiqué que de prudence sur l'identité. L'objectif est simple : garder un enregistrement, déplacer tout vers lui, et laisser une trace claire.
Commencez par lister les doublons en utilisant la même clé normalisée que vous appliquerez ensuite (par exemple e-mail en minuscules et trim). Faites cela en lecture seule d'abord, puis exportez les groupes pour revue.
-- Example: find duplicate emails by normalized value
SELECT
LOWER(TRIM(email)) AS email_norm,
COUNT(*) AS user_count,
ARRAY_AGG(id ORDER BY created_at) AS user_ids
FROM users
WHERE email IS NOT NULL
GROUP BY LOWER(TRIM(email))
HAVING COUNT(*) > 1
ORDER BY user_count DESC;
Pour chaque groupe de doublons, choisissez un "utilisateur primaire". Une règle pratique est de conserver le compte le plus probable et actif. Critères utiles : e-mail vérifié, activité la plus récente, statut payant.
Puis fusionnez dans un ordre prévisible pour ne pas perdre de données :
- Verrouillez le groupe de doublons (ou exécutez la fusion dans une transaction) pour empêcher de nouvelles écritures pendant le déplacement.
- Repointiez les enregistrements liés (commandes, projets, participations, clés API, tickets) de duplicate_user_id vers primary_user_id.
- Résolvez les conflits champ par champ (conserver l'e-mail vérifié, garder les détails de profil les plus récents, conserver le rôle le plus élevé).
- Écrivez une ligne d'audit : duplicate_user_id -> primary_user_id, date/heure, qui/quoi exécuté.
- Désactivez l'utilisateur non-primaire (soft-delete), et ne faites une suppression physique qu'une fois sûr qu'aucune dépendance n'existe.
Les identifiants et e-mails demandent un traitement spécial. Si l'utilisateur primaire garde l'e-mail, supprimez ou mettez à null l'e-mail sur les enregistrements non-primaires pour qu'ils ne puissent plus servir à se connecter. Pour les mots de passe, sessions et identités OAuth, migrez seulement si vous êtes sûr qu'ils appartiennent à la même personne ; sinon révoquez les sessions des comptes non-primaires et demandez une nouvelle connexion.
Ne cassez pas la connexion : gérer l'auth et les sessions pendant les fusions
Une fusion n'est pas juste déplacer des données de profil. La connexion dépend souvent d'IDs utilisateur qui sont inscrits dans des sessions, refresh tokens, liens de reset, et webhooks tiers. Fusionner deux comptes et ignorer ces références, et les gens rencontrent des boucles de connexion ou des erreurs « compte introuvable ».
Un pattern sûr est de garder un compte primaire et de traiter chaque doublon comme un alias pointant vers lui. Quand quelqu'un se connecte via un compte fusionné, vous le résolvez vers le primaire et poursuivez sans changer ce que l'utilisateur a tapé.
Rediriger les doublons vers l'utilisateur primaire
Conservez une petite table de correspondance (même une simple table) comme merged_user_id -> primary_user_id. À chaque lecture d'auth, vérifiez ce mapping et réécrivez l'ID utilisateur vers le primaire avant de créer une nouvelle session. Cela évite les boucles car le système ne crée jamais de sessions pour des comptes qui n'existent plus.
Cette approche d'alias vous donne aussi du temps pour migrer les anciens appelants sans outage.
Tokens, resets et intégrations : ce qu'il faut mettre à jour
Avant de basculer, décidez ce que vous allez invalider vs migrer :
- Sessions et refresh tokens : soit les repointer vers l'ID primaire, soit les révoquer et forcer une nouvelle connexion.
- Tokens "Se souvenir de moi" : les renouveler au prochain login pour éviter des échecs silencieux.
- Réinitialisations de mot de passe et vérifications : générer de nouveaux liens liés au compte primaire ; ne laissez pas d'anciens liens pointer vers un ID fusionné.
- Intégrations externes : si un partenaire stocke votre ancien user ID, conservez la résolution d'alias pour que les événements entrants s'attachent au primaire.
- Logs d'audit : conservez les anciens user IDs pour l'historique, mais affichez l'identité primaire dans l'admin pour réduire la confusion.
Exemple : si Anna a accidentellement créé deux comptes avec le même e-mail (un via Google et un via mot de passe), la fusion doit maintenir sa session actuelle et toute future réinitialisation de mot de passe doit cibler uniquement le compte primaire.
Erreurs courantes qui causent outages ou perte de données
La plupart des outages surviennent quand la base est forcée d'appliquer une règle que vos données ne respectent pas encore. Une contrainte unique est inflexible : si même un seul doublon existe, les écritures échouent, les files d'attente s'accumulent et les inscriptions peuvent se mettre en panne.
Un exemple courant : une équipe ajoute un index unique sur users.email un vendredi, en supposant "nous n'avons pas de doublons". Pendant la nuit, un ancien job d'import se relance et insert le même e-mail avec une casse différente. Lundi matin, les inscriptions renvoient des 500 et le support est submergé.
Erreurs qui posent problème :
- Activer une contrainte unique avant d'avoir nettoyé les doublons existants.
- Normaliser dans un chemin de code mais pas dans d'autres (web force lowercase, import admin ne le fait pas).
- Partir du principe que l'e-mail est toujours présent ou vérifié (comptes uniquement téléphone et logins sociaux existent ; les utilisateurs changent d'e-mail).
- Fusionner des utilisateurs sans mettre à jour toutes les clés étrangères (commandes, participations, logs d'audit, clés API, sessions, champs "created_by").
- Supprimer des données silencieusement pendant des fusions sans plan de rollback.
Traitez la déduplication comme une migration de données réversible, pas comme un simple script de nettoyage. Conservez les deux enregistrements, enregistrez ce qui a changé et ne supprimez qu'une fois que vous pouvez prouver qu'aucune dépendance n'existe sur l'ancienne ligne.
Une approche de sécurité simple qui fonctionne bien :
- Logger chaque décision de fusion (id gagnant, id perdu, champs choisis, timestamp).
- Déplacer les références par lots et vérifier les comptes avant/après.
- Ajouter une table de mapping canonique pour que les anciens ids se résolvent encore pendant la transition.
- Tester tous les chemins d'écriture (app, admin, imports, workers) en utilisant la même fonction de normalisation.
Checklist rapide et prochaines étapes
Commencez par la cohérence. Votre base ne peut vous protéger que si chaque chemin d'écriture produit la même "clé unique".
Checklist :
- Confirmer que les règles de normalisation sont appliquées sur tous les chemins d'écriture (inscription, invitation, création admin, OAuth, imports, jobs).
- Lancer un scan des doublons en utilisant la clé normalisée et revoir les résultats avec l'équipe.
- Tester la logique de fusion sur un petit échantillon réel d'abord et confirmer l'impact sur profils, participations, abonnements et logs d'audit.
- Nettoyer complètement les doublons, puis activer la contrainte en base (index/contrainte unique) seulement après que les données sont sûres.
- Ajouter une surveillance pour les nouveaux conflits (violations de contrainte) afin d'apprendre des problèmes via les logs, pas via les utilisateurs.
Désignez un propriétaire et un calendrier. "Dedupe" reste bloqué quand c'est flou. Rendre cela concret : définir l'enregistrement canonique, définir comment repointer les clés étrangères, et définir quoi faire quand deux enregistrements divergent (nom, téléphone, facturation, dernière connexion).
Un simple dry run aide : prenez 50 clusters de doublons de production, exécutez votre fusion sur une copie de staging et vérifiez que les utilisateurs peuvent encore se connecter, voir le bon workspace et effectuer des réinitialisations de mot de passe.
Si vous avez hérité d'une app générée par IA et que les doublons continuent parce que les contraintes et la normalisation n'ont jamais été appliquées de bout en bout, FixMyMess (fixmymess.ai) peut aider en diagnostiquant chaque chemin de création d'utilisateur, en réparant l'auth et la logique de fusion, et en vous menant à une unicité appliquée par la base sans casser la connexion.
Questions Fréquentes
Pourquoi des comptes utilisateurs en double continuent-ils d'apparaître même si on vérifie dans l'interface ?
Parce que les doublons sont généralement créés par plusieurs chemins d'écriture et des problèmes de timing, pas simplement parce que "le même e-mail a été saisi deux fois". Deux requêtes peuvent se concurrencer, des imports peuvent contourner les vérifications, des callbacks OAuth peuvent créer de nouvelles lignes, ou un retry après un timeout peut relancer la logique d'inscription. Seule une règle en base bloque les doublons quelle que soit la source de l'écriture.
Quelle est la façon la plus simple d'empêcher les doublons d'e-mails causés par la casse ou les espaces ?
Normalisez la valeur sur laquelle vous appliquez l'unicité. Pour l'email, un bon choix par défaut est trim + lowercase côté backend à chaque création ou mise à jour d'utilisateur, puis appliquez l'unicité sur la colonne normalisée. Conservez l'email original si vous voulez afficher exactement ce que l'utilisateur a tapé.
Faut-il faire respecter l'unicité par e-mail ou par identifiant OAuth du fournisseur ?
Oui en général : pour OAuth, appliquez l'unicité sur l'identité du provider, pas seulement sur l'e-mail. Stockez et faites respecter quelque chose comme provider + provider_user_id afin qu'une même identité Google ne puisse pas créer plusieurs lignes, puis liez cette identité au compte utilisateur existant si les règles de fusion le permettent.
Doit-on considérer le plus-addressing Gmail comme le même utilisateur ?
Par défaut, ne pas supprimer la partie + sauf si vous êtes sûr que cela correspond à vos règles produit. Certaines équipes veulent que [email protected] et [email protected] soient la même personne, mais c'est spécifique aux fournisseurs (Gmail) et peut surprendre sur d'autres domaines. Commencez par lowercase+trim, puis ajoutez des règles par fournisseur si nécessaire.
Comment gérer l'unicité dans une application multi-tenant ?
Si votre produit a des workspaces/tenants, l'unicité est souvent limitée au tenant. Cela signifie appliquer tenant_id + email_normalized pour que le même e-mail puisse exister dans deux workspaces différents, mais jamais deux fois dans le même workspace. Les applications grand public appliquent généralement l'unicité globale.
Qu'en est-il des utilisateurs en soft-delete — quelqu'un peut-il réutiliser le même e-mail plus tard ?
Décidez de la politique puis encodez-la dans la contrainte. Un choix courant est "unique parmi les utilisateurs actifs", ce qui permet à quelqu'un de se réinscrire après suppression, mais cela nécessite une contrainte partielle basée sur un drapeau active ou deleted_at. Si vous avez besoin d'un historique d'audit strict et voulez empêcher la réutilisation, appliquez l'unicité sur tous les utilisateurs, actifs et supprimés.
Comment déployer une contrainte unique sans downtime ?
Ajoutez d'abord la colonne normalisée et commencez à l'écrire pour toutes les nouvelles inscriptions, puis backfillez les utilisateurs existants par petits lots. Ensuite, détectez les collisions avec la clé normalisée, fusionnez ou désactivez les doublons, et seulement après ajoutez l'index/contrainte unique en mode non bloquant si votre base le supporte. Cette séquence évite l'interruption où "on active la contrainte et les inscriptions se mettent à échouer".
Comment fusionner des utilisateurs en double sans casser la connexion ou les abonnements ?
Choisissez un utilisateur principal, repointez chaque enregistrement lié vers ce principal, et gardez une table explicite merged_to pour que les anciens IDs continuent de se résoudre pendant la transition. Les sessions, tokens de refresh, réinitialisations de mot de passe et liens de vérification demandent une attention particulière ; par défaut, redirigez ou régénérez ces éléments pour le compte principal afin d'éviter les boucles de connexion.
Comment arrêter les doublons causés par des retries, timeouts ou doubles clics sur l'inscription ?
Créez une clé d'idempotence pour l'intention d'inscription et traitez les retries comme la même opération plutôt qu'une nouvelle création de compte. Même avec l'idempotence, conservez la contrainte unique en base, car les conditions de course et les requêtes parallèles peuvent toujours se produire. La combinaison évite à la fois les répétitions accidentelles et les problèmes de concurrence réels.
Nous avons hérité d'une app générée par IA et les doublons sont partout — quelle est la façon la plus rapide de corriger ça ?
On peut réparer rapidement si vous traitez cela à la fois comme un problème de données et comme un problème d'auth/data-model. FixMyMess peut auditer chaque chemin de création d'utilisateur, implémenter la normalisation côté backend, ajouter les bonnes contraintes uniques et exécuter un backfill/fusion sécurisé pour que les doublons cessent d'apparaître sans casser les connexions. Si vous avez hérité d'un code généré par IA qui crée des utilisateurs inconsistants, il est souvent plus rapide de nous laisser réparer les flux de bout en bout que de corriger les routes une par une.