Éviter la perte accidentelle de données lors des mises à jour avec la sémantique PATCH
Évitez la perte accidentelle de données lors des mises à jour en utilisant la sémantique PATCH, des listes d'autorisation de champs et des valeurs par défaut claires afin que les champs manquants ne soient jamais effacés.
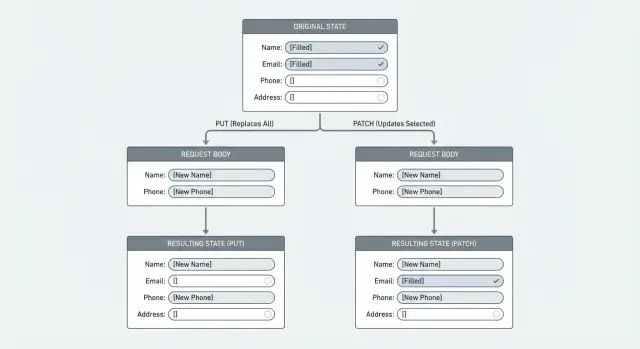
Pourquoi les mises à jour de type remplacement effacent-elles des données par accident
Une mise à jour de remplacement indique au serveur : « traite ce corps de requête comme l'enregistrement entier. » Tout ce que vous envoyez devient la nouvelle vérité, et tout ce que vous n'incluez pas est considéré comme n'existant plus. C'est ainsi que des champs se retrouvent effacés.
Cela arrive généralement quand un endpoint se comporte comme un PUT (remplacement complet) même si tout le monde l'appelle une « mise à jour ». Le client envoie une payload partielle, le backend la mappe sur le modèle, puis sauvegarde. Si un champ est manquant, certains chemins de code le définissent sur une valeur vide (""), null ou une valeur par défaut. Le résultat ressemble à une suppression silencieuse.
Exemple : un utilisateur modifie son profil et ne change que le nom affiché. Le formulaire envoie { "displayName": "Sam" }. Si votre serveur remplace tout le profil, des champs comme phone, address ou marketingOptIn peuvent soudainement devenir null ou false, alors que l'utilisateur ne les a jamais touchés.
Cela se voit souvent quand les clients n'envoient pas (ou ne peuvent pas envoyer) l'enregistrement complet, par exemple :
- Formulaires web qui n'envoient que les champs visibles
- Applications mobiles qui n'envoient que les « champs modifiés » pour économiser la bande passante
- Panneaux d'administration où certains champs sont cachés derrière des onglets ou des permissions
C'est facile à manquer lors des tests. Un test met à jour un champ et vérifie qu'il a changé, mais ne confirme pas que tous les autres champs sont restés identiques. Les utilisateurs découvrent le problème plus tard quand une adresse disparaît, qu'un réglage de notification est réinitialisé ou qu'une intégration cesse de fonctionner.
La première étape est d'identifier les endpoints où « mise à jour » signifie en réalité « remplacement ».
PUT vs PATCH : ce qui change et ce qui reste
PUT et PATCH répondent à des questions différentes.
PUT signifie : « Voici la ressource entière. Remplacez ce que vous avez par ceci. » Si le serveur traite le PUT comme un véritable remplacement, tout ce que le client n'inclut pas peut être supprimé ou réinitialisé.
PATCH signifie : « Voici des changements spécifiques. Appliquez-les par-dessus ce que vous avez déjà. » Il est conçu pour les modifications partielles, où le client n'envoie que les champs qu'il veut modifier.
C'est important parce que beaucoup de clients se comportent comme des formulaires d'édition. Une application mobile peut n'envoyer que { "displayName": "Mina" }. Si votre endpoint attend un objet complet (PUT) mais reçoit un objet partiel, vous pouvez effacer des champs comme bio, photoUrl ou timezone.
Une règle simple qui évite la plupart des surprises est de définir ce que signifie « manquant » :
- Champ manquant : laisser la valeur stockée telle quelle.
- Présent avec une valeur : la mettre à jour.
- Présent avec
null: l'effacer, mais seulement si l'effacement est explicitement autorisé.
Si vous utilisez PUT, ne considérez pas les champs manquants comme « à supprimer ». Considérez-les comme une erreur afin que les clients doivent envoyer une représentation complète.
Quand le remplacement complet (PUT) est encore utile
Le remplacement complet peut fonctionner quand le client possède vraiment le document entier et peut envoyer de manière fiable tous les champs à chaque fois. Par exemple, un outil d'administration interne qui édite un petit enregistrement de paramètres, ou un processus de synchronisation qui dispose toujours d'un snapshot complet.
Si vous ne pouvez pas garantir cela (la plupart des API publiques ne le peuvent pas), utilisez PATCH pour les modifications et documentez les règles afin que les clients ne devinent pas.
Choisissez et documentez vos règles de mise à jour
La plupart des bugs d'effacement de champs viennent d'un décalage d'équipe : le serveur pense « remplacement », tandis que le client envoie « seulement les champs modifiés ». Avant de modifier le code, décidez ce que signifie chaque endpoint.
Pour chaque endpoint de mise à jour, définissez :
- Mode de mise à jour : replace ou patch
- Champs manquants : ignorés ou rejetés
nullexplicite : autorisé pour effacer ou rejeté- Propriété : quels champs le client peut éditer vs champs détenus par le serveur
- Validation : ce qui est vérifié à chaque mise à jour
La distinction « manquant vs null » est là où les équipes se brûlent. Si le client omet phone, vous voulez généralement le laisser inchangé. Si le client envoie { "phone": null }, cela peut signifier « l'effacer », mais seulement si vous voulez autoriser cela.
La cohérence entre web, mobile et outils d'administration compte. Différents clients envoient souvent des formes de payload différentes, et un client de type remplacement peut effacer des données créées par un autre.
Un test rapide : choisissez un champ (comme timezone) et décrivez ce qu'il advient pour (1) manquant, (2) null et (3) chaîne vide. Si l'équipe ne peut pas répondre rapidement, les règles ne sont pas assez claires.
Utilisez des allowlists de champs pour contrôler ce qui peut être modifié
Une allowlist de champs signifie que le serveur n'accepte les changements que pour des champs spécifiques et nommés. Tout le reste est bloqué ou rejeté.
Cela aide de deux façons :
- Empêche les écritures accidentelles sur des champs que l'interface n'avait pas l'intention de modifier.
- Empêche les clients de mettre à jour des champs sensibles détenus par le serveur.
Les champs détenus par le serveur ne devraient presque jamais être modifiables depuis un endpoint standard « update profile/settings », par exemple :
- role ou permissions
- indicateurs d'état du compte
- totaux de facturation
createdAt/updatedAt- flags internes comme
isAdminouriskScore
Rejetez les champs inconnus plutôt que de les stocker silencieusement. L'acceptation silencieuse masque les fautes de frappe, les clients obsolètes et les formes de payload inattendues.
Allowlists imbriquées pour objets complexes
Si vous acceptez des objets imbriqués comme address ou settings, appliquez la même règle à l'intérieur. Allowlistez la clé de premier niveau, puis allowlistez les clés imbriquées. Cela permet que settings.theme soit modifiable tout en bloquant quelque chose d'insecure comme settings.isAdmin.
Étape par étape : implémenter des mises à jour partielles sûres
Une mise à jour partielle sûre consiste à « appliquer ces changements », pas à « remplacer l'enregistrement ». Le modèle le plus fiable est : charger ce qui existe, appliquer seulement ce que le client a envoyé (et est autorisé à changer), valider, puis sauvegarder.
Un flux d'implémentation pratique
Une séquence répétable ressemble à ceci :
- Récupérer l'enregistrement actuel depuis la base (et vérifier la propriété user/tenant).
- Construire un objet
changesà partir du corps de la requête en utilisant une allowlist. - Valider les changements (types, formats, limites de longueur, enums).
- Appliquer uniquement les champs présents dans la requête. Ne pas écrire de valeurs par défaut pour les champs manquants.
- Sauvegarder, puis retourner l'enregistrement mis à jour pour que le client puisse se resynchroniser.
Cela évite le mode d'échec courant où le client soumet deux champs et le serveur écrase dix autres avec des valeurs vides.
Journalisation sans fuite de données
Quand quelque chose tourne mal, vous voulez de la visibilité sans stocker de valeurs sensibles. Journalisez des métadonnées comme :
- id de l'enregistrement (et id user/tenant)
- quels noms de champs ont changé
- échecs de validation
Journalisez « updated: displayName, avatarUrl », pas le vrai displayName.
Gérer manquants, null et valeurs par défaut sans surprises
La plupart des bugs « mes données ont été effacées » viennent d'une confusion : le serveur ne distingue pas « l'utilisateur n'a pas touché à ceci » et « l'utilisateur veut effacer ceci ».
Traitez la payload comme des instructions :
- Manquant signifie « laisser tel quel ».
nullsignifie « l'effacer », mais seulement pour les champs où l'effacement a du sens.
Décidez aussi comment gérer les valeurs vides. Une chaîne vide n'est pas la même chose que manquant, et un tableau vide n'est pas la même chose que null. Si un utilisateur supprime toutes les étiquettes, { "tags": [] } doit définir les tags à aucun. Si le client envoie { "tags": null }, décidez si cela signifie « supprimer les tags » ou « entrée invalide », puis respectez cette décision.
Évitez d'appliquer des valeurs par défaut prévues pour la création lors des mises à jour. Les valeurs par défaut appartiennent aux flux de création. Dans les flux de mise à jour, les valeurs par défaut deviennent souvent destructrices.
Protéger contre les mises à jour perdues et les conditions de course
Même avec la sémantique PATCH, deux modifications peuvent encore s'écraser mutuellement. Le risque est lié au timing.
Exemple : un utilisateur ouvre « Modifier le profil » sur un laptop et un téléphone. Le téléphone met à jour displayName et sauvegarde. Le laptop, qui affiche encore les anciennes données, met à jour bio plus tard. Sans vérification de fraîcheur, la deuxième sauvegarde peut annuler des parties de la première.
Utilisez un contrôle de concurrence optimiste pour que le serveur puisse rejeter les modifications périmées :
- Champ de version : stocker un entier comme
profileVersion; n'updatez que si la version correspond. - Vérification
updatedAt: le client envoie le dernier timestamp vu; le serveur n'update que si inchangé. - ETag + If-Match : le client prouve qu'il édite la dernière version.
En cas de conflit, retournez une erreur claire (souvent HTTP 409 ou 412) et demandez au client de recharger.
Erreurs courantes qui effacent des champs
La plupart des pertes de données lors des mises à jour ne sont pas un problème de base de données. C'est un problème de contrat d'API : le serveur traite les champs manquants comme « veuillez supprimer ».
Causes fréquentes :
- Utiliser la sémantique PUT avec un client qui n'envoie que les champs modifiés
- Sauvegarder un objet complet construit à partir d'un état client périmé
- Mettre à jour des objets imbriqués en tant que tout au lieu de patcher les enfants (remplacer
addresseffaceaddress.line2si le client n'a envoyé queaddress.city) - Remplir les champs manquants avec des valeurs par défaut pendant la validation ou la normalisation
Une mentalité plus sûre est simple :
- Manquant : ne pas y toucher
- Null : effacer (seulement quand autorisé)
- Inconnu : rejeter
Vérifications rapides avant mise en production
Avant de déployer un endpoint de mise à jour, faites une passe centrée sur un risque : la mise à jour d'un champ change-t-elle accidentellement d'autres champs ?
Une petite checklist :
- Confirmer que chaque chemin de mise à jour suit les mêmes règles manquant/null.
- Appliquer des allowlists côté serveur (pas seulement dans l'UI).
- Tester que les champs manquants ne modifient pas les données stockées (mettre à jour seulement
displayName, vérifier queemail,phone,addressrestent identiques). - Tester que
nullefface seulement les champs que vous autorisez explicitement. - Ajouter une vérification de concurrence pour que deux modifications ne s'écrasent pas.
Un scénario rapide qui détecte beaucoup de problèmes : prenez un enregistrement réel de staging avec de nombreux champs remplis, envoyez une mise à jour qui ne change qu'un seul champ, puis récupérez à nouveau et faites un diff. Tout changement inattendu est un signal d'alerte.
Exemple : une édition de profil qui efface des champs non soumis
Un bug courant semble inoffensif : un utilisateur met à jour la photo de profil, clique sur Enregistrer, puis constate plus tard que son numéro de téléphone a disparu. Rien n'a été supprimé intentionnellement. Ça a été écrasé.
Voici comment cela arrive. L'écran de profil ne permet à l'utilisateur que de changer une photo, donc le client n'envoie que ce champ. Le serveur traite la requête comme un remplacement complet et écrit un nouvel enregistrement en n'utilisant que ce qui a été soumis.
Avant : mise à jour de type remplacement (efface des champs)
Existing record in the database:
{
"id": "u_123",
"displayName": "Sam",
"phone": "+1-555-0100",
"photoUrl": "https://cdn.example/old.png"
}
Client sends:
{ "photoUrl": "https://cdn.example/new.png" }
Server does (conceptually):
profile = request.body
save(profile)
Result: phone disappears because it wasn’t included.
Après : sémantique PATCH + allowlist de champs (gardent les champs)
Au lieu de remplacer tout l'enregistrement, traitez la payload comme des changements et n'acceptez que les champs que l'endpoint est censé éditer.
allowed = ["photoUrl"]
changes = pick(request.body, allowed)
profile = loadProfile(userId)
profile = merge(profile, changes)
save(profile)
Maintenant seul photoUrl change. Tout le reste reste tel quel.
Étapes suivantes : auditer vos mises à jour et corriger les endpoints à risque
Trouvez chaque endpoint qui peut modifier des données sauvegardées (profils, paramètres, facturation, « update status »). Pour chacun, comparez ce qui existe en stockage, ce que le client envoie et ce que le serveur écrit. Si le serveur peut écrire plus de champs que la requête n'en contient, vous avez un risque.
Une checklist d'audit pratique :
- Recherchez des handlers qui écrasent des enregistrements entiers à partir du corps de la requête.
- Faites que chaque endpoint soit soit vrai replace (et rejette les payloads partiels) soit vrai patch (applique seulement les champs autorisés et présents).
- Ajoutez une allowlist par endpoint et rejetez les champs inattendus.
- Standardisez les règles manquant vs null pour que les clients se comportent de façon cohérente.
- Auditez aussi les jobs en arrière-plan et les outils d'administration, pas seulement les API publiques.
Si vous avez hérité d'une base de code générée par IA, les endpoints de mise à jour sont un point de défaillance courant parce que les handlers générés par défaut ont souvent un comportement « replace ». FixMyMess (fixmymess.ai) se concentre sur le diagnostic et la réparation de ce type de problèmes en production, y compris le renforcement de la sémantique des mises à jour, l'ajout d'allowlists et le durcissement de la validation pour que les vraies données utilisateur ne soient pas effacées.
Questions Fréquentes
Should I use PUT or PATCH for updates?
Use PATCH for partial edits so missing fields stay unchanged. Keep PUT only for true full replacements where the client can reliably send the entire resource every time.
Why do fields get wiped when I “update” only one field?
Because a replace-style update treats the request body as the whole new record. Any field you don’t send can get overwritten with null, an empty value, or a default, which looks like a silent deletion.
What’s the safest way to treat missing fields vs null?
Pick one clear rule and enforce it server-side: missing means “leave as-is,” while null means “clear it” only for fields where clearing is allowed. If you can’t safely support clearing, reject null for that field.
Can web forms cause accidental data loss even if the user didn’t touch those fields?
Yes, and it’s common. Many forms only submit visible inputs, so hidden or tabbed fields won’t be included in the payload. If your backend replaces the record, those unsubmitted fields can get reset.
How do I prevent clients from updating fields they shouldn’t touch?
Use a field allowlist per endpoint and only apply changes for keys that are both allowed and present in the request. Unknown fields should be rejected so typos and unexpected payloads don’t quietly change data.
What’s a safe server-side pattern for partial updates?
Load the existing record, build a changes object by picking only allowed keys from the request, validate the changes, then merge and save. Avoid constructing a full model purely from the request body.
How do I handle nested objects like address without wiping subfields?
Don’t treat nested objects as all-or-nothing replacements unless that’s the contract. Patch nested keys individually (for example address.city) so sending one nested field doesn’t wipe siblings like address.line2.
Why are defaults dangerous in update endpoints?
Defaults belong in create flows, not update flows. If you apply defaults during updates, missing fields can get “helpfully” filled with default values and overwrite real stored data.
How do I stop two edits from overwriting each other (race conditions)?
Use optimistic concurrency control so stale clients can’t overwrite newer changes. A version number, an updatedAt check, or ETag/If-Match can let the server reject outdated edits with a clear conflict response.
What’s the quickest test to catch “wiped field” bugs before shipping?
Test with a real record that has many fields set, send an update that changes only one field, then re-fetch and diff the full record. If anything else changed, your update path is doing replacement or applying defaults incorrectly.