File d'attente des messages morts pour les tâches en arrière-plan : limiter les réessais et rejouer en toute sécurité
Découvrez comment une file d'attente de messages morts (DLQ) pour les tâches en arrière-plan permet de capturer les messages empoisonnés, limiter les réessais et rejouer en toute sécurité sans dupliquer les effets secondaires.
Ce qui pose problème quand les tâches en arrière-plan échouent en boucle
Une tâche en arrière-plan s'exécute généralement hors de la vue : envoyer un e-mail, prélever une carte, redimensionner une image, synchroniser un enregistrement. Lorsqu'elle échoue une fois, un réessai résout souvent le problème. Le souci commence quand la même tâche échoue encore et encore, sans limite et sans endroit clair où la placer.
Ce type de tâche est souvent appelé message empoisonné. Sens littéral : une entrée incorrecte ou une situation cassée qui fait échouer le worker à chaque fois qu'il la touche. Cela peut être une payload malformée, une ligne de base de données manquante, une clé API expirée, ou un bug de code qui n'apparaît que pour un client.
Les réessais infinis font plus de mal qu'on ne le croit. Ils peuvent :
- Créer une panne en gardant les workers occupés sur le même travail défaillant au lieu de traiter les tâches saines.
- Faire grimper les coûts (plus de compute, plus d'opérations sur la file, plus de trafic DB).
- Inonder les logs et alertes jusqu'à ce que les vrais problèmes soient ignorés.
- Déclencher des effets secondaires répétés, comme prélever ou envoyer des e-mails en double, si la tâche plante après avoir effectué l'action.
Un schéma d'échec courant est le succès partiel. Exemple : votre tâche envoie un e-mail, puis plante en écrivant “envoyé” dans la base. Le réessai suivant ne voit pas le drapeau “envoyé” et renvoie l'e-mail. Vous vous retrouvez avec des doublons, des utilisateurs mécontents, et une piste d'audit confuse.
C'est pourquoi les équipes ajoutent une dead-letter queue (DLQ) pour les tâches en arrière-plan. Plutôt que de réessayer indéfiniment, on plafonne les réessais et on met la tâche défaillante de côté avec ses détails d'erreur. Ensuite on corrige la cause et on rejoue la tâche volontairement.
Une bonne configuration a trois éléments : une politique de réessai qui s'arrête avant que tout ne fonde, un enregistrement DLQ qui préserve ce qui s'est passé, et un flux de relecture attentif aux doublons. Si vous avez hérité d'un worker fragile (y compris un généré rapidement par un outil IA), ces garde-fous peuvent transformer un système bruyant en un système fiable.
Les dead-letter queues, expliquées simplement
Une dead-letter queue (DLQ) est une zone de mise en attente pour les tâches en arrière-plan qui ont échoué et ne doivent pas continuer à être réessayées automatiquement. Ce n'est pas un endroit où le travail disparaît discrètement. C'est là où les échecs deviennent visibles, vérifiables et réparables.
Pensez-y comme déplacer une tâche bloquée hors de la file principale pour que le reste du système puisse continuer. Vous choisissez la clarté plutôt que les réessais sans fin.
Quelques termes qui se confondent souvent :
- Retry queue : tâches qui ont échoué mais qu'on s'attend à réussir plus tard (par exemple, un problème réseau temporaire). Elles s'exécutent de nouveau après un délai.
- DLQ : tâches qui ont échoué et qui demandent une intervention humaine, une correction de code, une correction de données, ou une décision avant d'être relancées.
- Parking lot queue : un seau plus large que certaines équipes utilisent pour les éléments “non urgents”. En pratique, cela devient souvent une DLQ informelle sans règles claires.
Alors, quand réessayer et quand envoyer en DLQ ? Réessayez lorsque l'échec est probablement temporaire et sûr à répéter. Envoyez en DLQ lorsque les réessais sont peu susceptibles d'aider, ou risquent d'endommager. Par exemple, “taux limité par le fournisseur” est généralement réessayable. “ID client invalide” ou “champs requis manquants” nécessite souvent une correction de données ou de code, donc cela appartient à la DLQ.
Quand une tâche est déplacée en DLQ, elle doit contenir assez de contexte pour déboguer et rejouer en toute sécurité plus tard :
- La payload de la tâche (les entrées exactes utilisées)
- Le message d'erreur et la pile (ou équivalent)
- Le nombre de réessais et les horodatages (première erreur, dernière tentative)
- Une clé d'idempotence stable ou une empreinte de job
- L'état connu des effets secondaires (si pertinent), comme “paiement créé” ou “e-mail envoyé”
Ce dernier point est important. Une DLQ ne sert pas seulement à capter les échecs. Elle sert à rendre la tentative suivante contrôlée et informée.
Décider ce qui est réessayable et ce qui ne l'est pas
Les réessais n'aident que lorsque le problème est temporaire. Quand le problème est permanent, les réessais gaspillent le temps des workers et dissimulent le vrai problème. C'est la première décision derrière toute dead-letter queue pour tâches en arrière-plan : qu'est-ce qui doit être retenté, et qu'est-ce qui doit s'arrêter rapidement.
Une règle simple fonctionne bien : réessayez lorsque la tâche pourrait réussir plus tard sans changer le code ni l'entrée. Si elle ne peut jamais réussir avec la même payload, ne réessayez pas.
Classifier les erreurs selon l'intention
Au lieu de traiter toutes les exceptions de la même façon, mappez-les en quelques catégories claires :
- Transient : timeouts réseau, pertes de connexion DB, 5xx temporaires d'un fournisseur.
- Throttling : limites de taux (429), quota dépassé, “réessayer dans 60 secondes”.
- Introuvable / état manquant : enregistrement lié supprimé, utilisateur inexistant.
- Entrée invalide : payload ne passant pas la validation, champ requis manquant, mauvais format.
- Auth / permissions : identifiants expirés, accès révoqué, action interdite.
Cette classification doit déterminer la suite : réessai immédiat, réessai différé, ou déplacement en DLQ avec une raison claire.
Exemple : une tâche qui prélève une carte échoue avec un timeout de l'API de paiement. C'est transient, donc un réessai a du sens. Mais si la tâche échoue parce que l'ID client manque dans la payload, réessayer ne résoudra jamais le problème. Mettez-la en DLQ et alertez quelqu'un pour corriger les données (ou le producteur de la tâche).
Pourquoi cela compte pour les alertes et la relecture
Une DLQ n'est pas juste un parking. La raison pour laquelle vous avez déplacé une tâche là-bas vous dit quoi faire ensuite :
- Les échecs transients signifient souvent qu'il faut un meilleur backoff, pas un humain.
- Les entrées invalides signifient généralement une correction du code ou des données avant toute relecture.
- Les échecs d'auth signifient souvent qu'il faut faire pivoter des clés avant toute autre action.
Cela rend aussi la relecture plus sûre. Si une tâche est en DLQ pour “payload invalide”, votre outil admin peut bloquer la relecture par défaut et demander une correction d'abord. Beaucoup de workers hérités échouent ici parce que tout est traité comme “réessayable” jusqu'à ce que quelqu'un définisse des catégories et des règles d'arrêt claires.
Définir une politique de réessai qui ne fait pas fondre le système
Les réessais sont utiles, mais des réessais non contrôlés peuvent transformer une tâche cassée en panne système. Une bonne politique limite les dégâts, répartit la charge dans le temps et s'arrête tôt quand une tâche ne fonctionnera clairement pas.
Le nombre maximum de tentatives doit correspondre au type d'échec. « Une taille unique pour tous » est la façon dont on finit par réessayer les mauvaises choses. Un appel réseau instable peut mériter 5–10 tentatives. Une payload invalide (champs requis manquants) ne devrait pas obtenir 10 tentatives — elle devrait aller rapidement en DLQ. Traitez la DLQ comme l'endroit où vont les tâches une fois le budget de réessai épuisé.
Backoff et jitter, en termes simples
Backoff signifie attendre plus longtemps entre les tentatives. Cela donne du temps aux services en aval pour se rétablir et empêche les workers de marteler le même endpoint.
- Backoff fixe : attendre le même temps à chaque réessai.
- Backoff exponentiel : attendre de plus en plus longtemps à chaque fois.
- Jitter : ajouter un petit délai aléatoire pour que de nombreuses tâches ne réessayent pas exactement en même temps.
Exemple : votre fournisseur de paiement a une brève panne. Sans jitter, chaque tâche échouée réessaye exactement au bout de 30 secondes et provoque une deuxième vague d'échecs.
Limites temporelles qui évitent la « douleur infinie »
Fixez deux horloges :
- Timeout par tentative (combien de temps on laisse une tentative avant de l'annuler).
- Fenêtre temporelle globale (combien de temps vous êtes prêt à continuer les réessais avant d'abandonner).
Un défaut pratique pour beaucoup d'équipes : 3–5 tentatives, backoff exponentiel commençant à 10–30 secondes, petit jitter (par exemple 0–10 secondes), un timeout par tentative qui correspond au temps normal d'appel, et une fenêtre globale comme 15–60 minutes. L'objectif n'est pas la perfection. C'est d'arrêter les réessais incontrôlés avant qu'ils ne s'accumulent et n'empêchent le travail sain d'avancer.
Que consigner quand on déplace une tâche en DLQ
Quand une tâche atterrit dans une dead-letter queue (DLQ), vous ne sauvegardez pas juste un “message échoué”. Vous créez un dossier de cas que quelqu'un pourra avoir besoin de comprendre, corriger et rejouer des jours plus tard.
Commencez par le minimum de données nécessaires pour reproduire l'échec et décider de la suite. Un bon enregistrement DLQ inclut généralement :
- Type de job (quel handler doit le traiter) et version (si la forme de la payload évolue dans le temps)
- Payload originale (telle que reçue) plus un résumé administrateur sans données sensibles
- Compte des tentatives et historique des réessais (combien, et pourquoi cela a continué d'échouer)
- Horodatages : première apparition, dernière tentative, déplacement en DLQ
- Détails d'erreur : dernier message d'erreur/stack, plus la chaîne de cause racine si disponible
Un ID de job stable est critique. Générez-en un lors de la création initiale et conservez-le identique pour les réessais et relectures. Ajoutez ensuite une clé de dédoublonnage ou d'idempotence qui représente l'effet réel attendu (par exemple, send_invoice_email:invoice_123:recipient_456). C'est ce qui vous permet de rejouer sans refaire l'action.
Faites attention à ce que les admins voient. Les payloads contiennent souvent des secrets, des tokens ou des données personnelles. Stockez la payload brute seulement si nécessaire pour le debug, mais conservez aussi un champ résumé sûr et rédigé (par exemple, montrez l'ID utilisateur, pas l'e-mail ; affichez les 4 derniers chiffres d'une carte, pas le token complet).
Enfin, conservez à la fois la dernière erreur et la cause initiale quand vous le pouvez. Exemple : une tâche peut finir par “timeout appel fournisseur”, mais l'erreur racine était “clé API manquante”. Si votre DLQ garde la chaîne, la correction est évidente et la relecture est plus sûre.
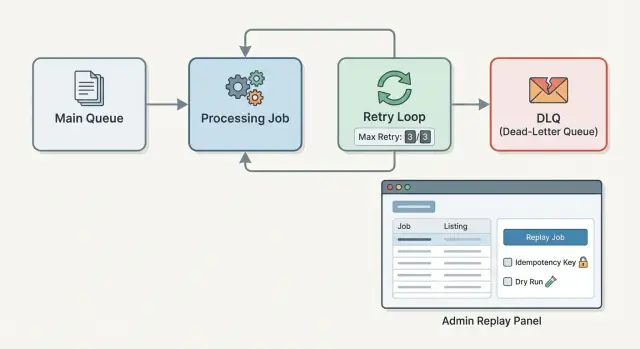
Étape par étape : ajouter DLQ et réessais plafonnés à votre worker
Traitez chaque exécution de tâche comme une petite transaction : soit elle se termine, soit elle échoue d'une manière que vous pouvez raisonner plus tard. Une dead-letter queue pour les tâches en arrière-plan est simplement l'endroit où vont les tâches « on a assez essayé, maintenant un humain doit regarder ».
Un flux simple qui fonctionne dans la plupart des stacks :
- Exécutez le handler dans un try/catch (ou équivalent) qui capture une erreur typée, pas juste une chaîne.
- En cas d'échec, incrémentez un compteur de tentatives et calculez le prochain horaire d'exécution en utilisant le backoff (par exemple : 1m, 5m, 20m), avec un peu de jitter pour éviter les regroupements.
- Si l'erreur n'est clairement pas réessayable (payload invalide, enregistrement manquant, permission refusée), ou si le nombre de tentatives atteint le cap, déplacez la tâche en DLQ au lieu de la réessayer.
- Déclenchez une alerte avec assez de contexte pour déboguer (type de job, id, tentative, classe d'erreur, première apparition). Évitez d'inclure la payload complète dans les alertes car elle peut contenir des secrets ou des données personnelles.
- Suivez quelques compteurs pour que les problèmes apparaissent tôt.
try {
handle(job)
markDone(job)
} catch (err) {
attempts = job.attempts + 1
if (!isRetryable(err) || attempts \u003e= MAX_ATTEMPTS) {
moveToDLQ(job, err)
alert(job, err)
} else {
reschedule(job, backoff(attempts))
}
}
Pour les tableaux de bord, rien de compliqué : suivez les jobs en cours d'exécution, les jobs programmés pour réessai, la profondeur de la DLQ, et “DLQ ajoutées par heure”.
Empêcher les effets secondaires en double lors de la relecture
La relecture d'une tâche échouée est là où le vrai risque se cache. La tâche originale a peut-être déjà effectué la partie dangereuse (prélever une carte, envoyer un e-mail, écrire une ligne), puis a planté en enregistrant son état. Si vous la rejouez depuis la DLQ sans protection, vous pouvez prélever deux fois, envoyer deux fois ou créer des enregistrements en double.
La façon la plus simple de rester sûr est l'idempotence. En termes simples : la même requête doit produire le même résultat, même si vous l'exécutez deux fois. Votre tâche doit pouvoir dire « j'ai déjà fait ça » et sortir sans répéter l'effet secondaire.
Moyens pratiques :
- Clés d'idempotence : générez une clé stable par action réelle (comme
invoice_123_charge) et stockez-la avec le résultat. À la relecture, vérifiez la clé en premier. - Contraintes d'unicité : faites en sorte que la base de données impose “une seule” action (un paiement par commande, un e-mail de bienvenue unique) et traitez les doublons comme un succès.
- Pattern outbox : écrivez l'intention une fois dans la base, puis laissez un expéditeur séparé la délivrer. Les relectures revérifient et n'envoient que ce qui est encore en attente.
Un bon modèle mental est « écrire une fois, envoyer plus tard ». D'abord, enregistrez un fait durable comme « paiement pour la commande 8821 autorisé » dans une transaction. Ce n'est qu'après que vous appelez le service externe (fournisseur d'e-mails, passerelle de paiement). Si la tâche meurt à mi-chemin, la relecture verra le fait stocké et ne fera que le travail restant minimal.
Exemple : une tâche envoie un e-mail de reçu après un achat. Si elle envoie l'e-mail puis plante avant de marquer receipt_sent=true, la relecture enverra un second reçu. Corrigez cela en stockant receipt_sent_at avec une clé unique comme receipt:{order_id} avant l'envoi, ou en plaçant l'e-mail dans une table outbox et en laissant un expéditeur dédié s'occuper de la livraison.
Construire un flux admin de relecture sûr par défaut
Si les gens peuvent rejouer des jobs en DLQ en un clic, ils le feront. Le flux admin doit supposer des erreurs, de la pression et un contexte partiel. Sûr par défaut signifie que l'action la plus simple est aussi la plus sûre.
Commencez par un petit ensemble de vues qui répondent rapidement aux questions de base :
- Liste DLQ : filtrer par type de job, classe d'erreur, date et environnement.
- Vue détail : payload, clé d'idempotence, en-têtes/métadonnées, et l'erreur exacte.
- Relecture : options pour rejouer maintenant vs programmer, unique vs lot.
- Ignorer/résoudre : endroit pour marquer “ne sera pas corrigé” avec une raison.
Dans la vue détail, montrez l'historique des tentatives : horodatages, version du worker, nombre de réessais, et tous les effets secondaires enregistrés (par exemple, “facture #1234 créée”). C'est sur cette base que se prennent de bonnes décisions.
Les contrôles de relecture doivent forcer l'opérateur à exprimer une intention. La relecture en lot doit demander un aperçu du filtre (“32 jobs correspondent”) et une seconde confirmation qui nomme le type de job et le risque d'effet secondaire (“peut envoyer des e-mails”). Un mode dry run vaut le coup : validez les inputs et dépendances actuelles sans effectuer d'écritures ni d'appels externes, puis montrez ce qui se passerait.
Les garde-fous empêchent la relecture de transformer une mauvaise tâche en deux mauvais résultats :
- Bloquer la relecture si la même clé d'idempotence a déjà réussi.
- Par défaut, programmer (quelques minutes plus tard) pour les actions en lot, pas immédiat.
- Exiger un choix explicite quand la tâche est connue non idempotente.
- Limiter le débit des relectures par type de job pour éviter les rafales.
- Écrire systématiquement une entrée d'audit.
Les permissions comptent. Limitez la relecture à un petit rôle, et consignez qui a rejoué quoi et quand, incluant la raison.
Erreurs courantes et pièges à éviter
La plupart des configurations DLQ échouent pour des raisons banales : règles floues, réessais trop agressifs, ou relecture considérée comme un bouton sans risque.
Pièges courants (et comment les éviter) :
- Réessayer tout pour toujours. Si chaque échec est « réessayer », vous n'apprenez jamais ce qui est cassé. Définissez des règles DLQ claires (payload invalide, enregistrements manquants, échecs d'auth, erreurs 4xx fournisseurs) et sortez ces tâches du chemin chaud rapidement.
- Pas de cap + pas de backoff = tempêtes de réessais. Une panne peut devenir un flot qui ralentit tout le système. Fixez un nombre max de tentatives, utilisez un backoff exponentiel avec jitter, et arrêtez quand l'erreur n'est clairement pas temporaire.
- Un bouton de relecture qui peut doubler les effets. Rejouer une tâche ayant déjà prélevé une carte ou envoyé un e-mail peut causer de vrais dégâts. Rendez les handlers idempotents (clé d'idempotence, contraintes uniques, ou marqueur “déjà traité”) et concevez la relecture pour être sûre même si on clique deux fois.
- Logger des secrets dans les payloads ou erreurs. Les DLQ stockent souvent le corps original du job. Si cela inclut tokens, mots de passe, clés API ou données clients complètes, vous créez une fuite silencieuse. Rédigez les champs sensibles avant d'enquêter, et nettoyez les messages d'erreur avant de les stocker.
- Utiliser la DLQ comme stockage longue durée. Une DLQ sans propriétaire devient un cimetière. Assignez un propriétaire, définissez une politique de rétention et planifiez un nettoyage. Suivez un petit ensemble de métriques (taille de la DLQ, âge du plus ancien item, taux de succès des relectures) pour que cela reste maîtrisé.
Une règle simple aide : votre DLQ devrait être une boite de réception courte pour investigation, pas une décharge. Si elle grossit, c'est un bug produit ou un problème ops, et quelqu'un doit s'en occuper.
Exemple : une tâche d'envoi d'e-mail échouée qui ne doit pas renvoyer
Un utilisateur s'inscrit, et votre app met en file une tâche “envoyer l'e-mail de bienvenue”. La tâche inclut user_id, to_email, template_id, et un send_id (un identifiant d'idempotence unique pour cet e-mail).
Un enregistrement a une adresse invalide comme alex@@example.com. Le worker appelle votre fournisseur d'e-mails, reçoit un 400 “destinataire invalide”, et échoue.
Votre politique de réessai retente quelques fois (par exemple, 3 tentatives sur 10 minutes) au cas où l'erreur serait temporaire. Chaque tentative échoue de la même façon, donc la tâche est déplacée en DLQ avec une raison claire et non réessayable : “Format d'e-mail invalide : alex@@example.com”. Cette unique phrase importe car elle dit à un admin ce qu'il faut corriger sans creuser les stack traces.
Pendant l'incident, vos logs et métriques doivent rendre l'histoire évidente :
- Tentatives du job : 3 (toutes échouées avec le même 400)
- Compte DLQ : +1 (taggé
reason=invalid_recipient) - Envois d'e-mails : 0 (aucun message id fournisseur stocké)
- Temps jusqu'à la DLQ : 10m (montre que les réessais sont plafonnés)
Un admin ouvre l'item DLQ, édite l'entrée (ou corrige le record utilisateur), et clique sur replay. Le flux de relecture doit être sûr par défaut : il re-queue la tâche avec le même send_id, et le worker vérifie d'abord une table sent_emails. Si une ligne existe déjà pour send_id, il s'arrête. Sinon, il envoie l'e-mail, stocke l'ID fournisseur, puis marque la tâche comme terminée.
Pour éviter la même erreur la prochaine fois, validez tôt (rejetez les e-mails invalides avant l'enqueue) et conservez l'idempotence pour chaque effet secondaire (e-mails, paiements, webhooks).
Checklist rapide et prochaines étapes
Une DLQ pour les tâches en arrière-plan n'aide en production que si les détails ennuyeux sont bons. Ces détails empêchent les échecs de se transformer en doublons, pannes ou désordres silencieux dans les données.
Checklist construction pour réessais et capture DLQ :
- Plafonnez les tentatives et définissez le backoff (par exemple, 5 essais avec backoff exponentiel et jitter), plus un timeout dur par tentative.
- Notez ce qui est réessayable vs non réessayable (coups de réseau, 429/503, verrou DB temporaire) et traitez tout le reste comme non réessayable par défaut.
- Ajoutez une condition d'arrêt pour les poison messages (même signature d'erreur répétée, payload invalide, champs requis manquants) pour qu'ils aillent tôt en DLQ.
- Enregistrez l'essentiel en DLQ : type de job, args (rédigés), nombre de tentatives, dernière classe d'erreur et message, stack trace, horodatages, et version du worker.
- Rédigez les secrets et données personnelles avant de stocker quoi que ce soit (tokens, mots de passe, e-mails complets, corps de requête bruts) et conservez une piste d'audit de qui a modifié quoi.
Checklist de sécurité pour la relecture :
- Choisissez une stratégie d'idempotence par type de job (clé d'idempotence, contrainte unique, ou marqueur “déjà traité”) et testez-la en relançant la même tâche deux fois.
- Séparez relecture et réessai : la relecture doit nécessiter une décision humaine et idéalement une note de raison.
- Restreignez les permissions (admins seulement), ajoutez une confirmation claire et affichez un aperçu de ce qui arrivera (effets secondaires comme paiements ou e-mails).
- Décidez quelles modifications sont autorisées avant la relecture (éditer la payload, changer la destination, outrepasser une config) et consignez chaque édition.
- Après relecture, écrivez le résultat (succès, nouvel échec avec une nouvelle erreur, ou annulé) pour que la DLQ ne devienne pas un trou noir.
Si vous traitez un codebase généré par IA où réessais, idempotence et relecture sûre n'ont jamais été conçus, FixMyMess (fixmymess.ai) peut aider à diagnostiquer le worker et le comportement de la file, réparer la logique et la durcir pour la production.
Questions Fréquentes
Qu'est-ce qu'un « poison message » dans une file de tâches en arrière-plan ?
Un message empoisonné est une tâche qui échoue à chaque fois avec la même entrée, donc les réessais n'aident pas. La solution consiste à arrêter les réessais automatiques tôt, à la déplacer dans une DLQ avec l'erreur et la charge utile, puis à corriger le code ou les données avant de la rejouer volontairement.
Quelle est la différence entre une retry queue et une dead-letter queue (DLQ) ?
Une retry queue contient des tâches dont l'échec est probablement temporaire et sûr à répéter (par exemple, des timeouts). Une DLQ est pour les tâches qui nécessitent d'abord une décision ou une correction (payload invalide, enregistrements manquants, problèmes de permission) afin qu'elles n'encombrent pas les workers.
Combien de tentatives une tâche en arrière-plan devrait-elle avoir avant d'aller dans la DLQ ?
Un bon point de départ pratique est un petit nombre de tentatives avec des délais croissants, et une limite dure après une fenêtre temporelle définie. Commencez par 3–5 tentatives avec backoff exponentiel, puis déplacez la tâche en DLQ une fois le budget de réessai épuisé.
Comment décider quelles erreurs sont réessayables vs non réessayables ?
Réessayez seulement quand la même charge utile pourrait réussir plus tard sans modifier le code ou les données. Les timeouts, erreurs 5xx temporaires et pertes de connexion DB sont généralement réessayables ; les entrées invalides, champs manquants et conditions « introuvable » doivent rapidement aller en DLQ.
Que dois-je stocker lorsqu'une tâche est déplacée dans la DLQ ?
Enregistrez assez d'informations pour reproduire et rejouer en toute sécurité : le type de job, la payload (champs sensibles rédigés), le nombre de tentatives et leur historique, et les détails complets de l'erreur. Stockez aussi un ID stable de job et une clé d'idempotence pour que la relecture détecte un travail déjà effectué.
Comment éviter les doubles prélèvements ou les e-mails en double lors de la relecture des tâches de la DLQ ?
L'idempotence est la protection principale : la même requête doit produire le même résultat même si elle est exécutée plusieurs fois. Utilisez une clé d'idempotence stable, une contrainte d'unicité pour l'action réelle, ou enregistrez un statut “déjà traité” avant d'envoyer e-mails, prélever des cartes ou créer des ressources externes.
À quoi ressemble un flux administratif de relecture sûr ?
Faites en sorte que la relecture demande une intention explicite et ajoute des garde-fous : affichez la payload et l'erreur, bloquez la relecture si la clé d'idempotence indique déjà un succès, et consignez qui a relancé et pourquoi. En cas de doute, relancez une tâche unique et vérifiez l'état des effets secondaires avant un lot.
Pourquoi les réessais infinis sont-ils si dangereux en production ?
Les réessais sans fin peuvent saturer les workers et transformer une seule tâche défectueuse en incident global. Ils augmentent aussi les coûts (compute, opérations de file, trafic DB), noient les vraies alertes et augmentent le risque d'effets secondaires répétés quand une tâche a réussi partiellement puis a planté.
Comment éviter de divulguer des secrets ou des données personnelles via les payloads et erreurs stockées en DLQ ?
Nettoyez la payload et les détails d'erreur avant de les stocker ou d'y donner accès : les jobs contiennent souvent des tokens, identifiants ou données personnelles. Gardez un résumé rédigé pour les admins, conservez seulement ce qui est vraiment nécessaire pour le debug, et évitez d'inclure des secrets dans les logs ou alertes.
FixMyMess peut-il aider si mon système de tâches a été généré par un outil IA et échoue sans cesse ?
Oui, particulièrement quand le worker et la logique de réessai ont été générés rapidement et n'ont jamais été conçus pour l'idempotence ou une relecture sûre. FixMyMess (fixmymess.ai) peut auditer le comportement de la file et du worker, identifier les causes des échecs et des duplications, puis réparer et durcir le code pour la production, souvent en 48–72 heures après un audit de code gratuit.