ID de corrélation pour tracer un clic entre API et tâches de fond
Les IDs de corrélation relient un clic utilisateur aux logs API et aux jobs en arrière-plan pour identifier rapidement les échecs, fournir des rapports de bug clairs et corriger les problèmes sans deviner.
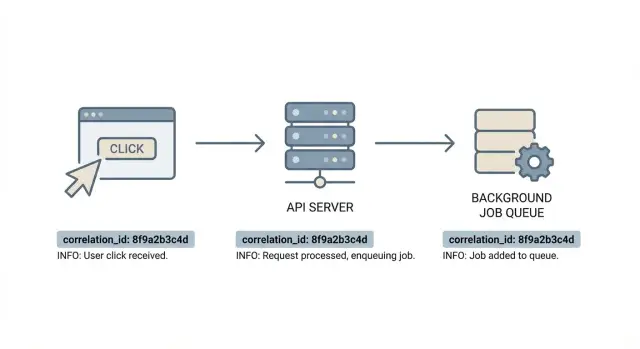
Pourquoi le débogage semble aléatoire sans un ID partagé
Un rapport de bug commence souvent simplement : « J’ai cliqué sur Enregistrer et ça a échoué. » Puis vous ouvrez les logs et tout devient de la devinette. La console du navigateur a un ensemble de messages, les logs de l’API sont ailleurs, et les logs des tâches en arrière-plan vivent dans un système différent. Même si chaque endroit loggue beaucoup, rien ne s’aligne.
C’est là que le débogage paraît aléatoire. Vous cherchez par intervalle de temps, ID utilisateur ou texte vague comme « paiement échoué », en espérant tomber sur les bonnes lignes. Si plusieurs utilisateurs sont actifs ou si des retries ont lieu, il est facile de suivre le mauvais fil.
C’est aussi pour ça qu’on entend souvent « ça marche sur ma machine ». Sur votre laptop, vous retentez le même clic et ça passe. En production, ce même clic peut toucher un autre serveur, rater un cache, appeler un tiers lent, ou mettre en file un job qui échoue ensuite. Sans un moyen unique de connecter ces événements, l’histoire se découpe en fragments.
Une seule action utilisateur peut se ramifier rapidement : un clic frontend déclenche une ou plusieurs requêtes API ; l’API touche la base de données et peut-être d’autres services ; elle peut mettre en file des jobs pour l’email, la facturation, le traitement d’images ou l’indexation ; et ces jobs peuvent s’exécuter plus tard sur d’autres machines, parfois avec des retries. Des webhooks et callbacks ajoutent encore des étapes.
L’objectif est simple : une seule piste que vous pouvez suivre du début à la fin. Avec des IDs de corrélation, vous prenez un ticket de support, récupérez un identifiant, et vous remontez jusqu’à l’événement frontend, la requête API exacte, et chaque ligne de log des jobs exécutés ensuite. Le débogage cesse d’être une chasse au trésor et devient une chronologie fiable.
Ce qu’est un ID de corrélation (et ce que ce n’est pas)
Un ID de corrélation est une étiquette unique qui suit une unité de travail à travers votre système. Pensez-y comme le contexte d’« une action utilisateur » : un clic, une requête API, les jobs qu’elle déclenche, et les appels en aval.
Chaque ligne de log appartenant à cette chaîne inclut le même ID. Cela vous permet de chercher une seule fois et de voir toute l’histoire.
Un ID de corrélation n’est pas un identifiant utilisateur. Il ne doit pas décrire qui est l’utilisateur, sur quoi il a cliqué, ni quelles données étaient impliquées. C’est une étiquette opaque qui aide à relier des événements entre systèmes sans deviner.
On le confond souvent avec d’autres IDs :
- Session ID relie plusieurs actions dans le temps à une même session navigateur. Utile pour l’authentification et l’analytics, mais trop large pour tracer une seule action cassée.
- ID de ligne en base identifie une rangée (comme un ID de commande). Utile pour la logique métier, mais cela ne connecte pas automatiquement le frontend, l’API et le traitement en file.
- Correlation ID (request ID) relie toutes les étapes d’un flux, même quand plusieurs services et jobs sont impliqués.
Quand le créer ? Idéalement à la périphérie : dans le navigateur quand l’action démarre (puis l’envoyer en header), ou au premier point d’entrée de l’API (gateway/load balancer/serveur app) si vous ne pouvez pas faire confiance au client. Beaucoup d’équipes acceptent un ID fourni par le client, vérifient son format, et en génèrent un nouveau s’il manque ou est invalide.
À quoi doit-il ressembler ? Rendez-le unique, opaque et sûr à logger. Une valeur de type UUID ou ULID fonctionne bien. N’y intégrez pas d’emails, d’IDs utilisateur, ni d’informations sensibles.
Où l’ID doit voyager dans une app typique
Un ID de corrélation n’aide que s’il survit au trajet complet. Considérez-le comme une étiquette qui suit une action utilisateur depuis le navigateur, via votre API, jusqu’au travail en arrière-plan, de sorte que chaque ligne de log puisse être rattachée au même instant.
Dans la plupart des apps, cela signifie porter le même ID à travers :
- l’événement frontend (clic ou envoi de formulaire)
- la requête API
- les appels en aval (services internes et tiers)
- les jobs en arrière-plan (publication et traitement par les workers)
- les effets secondaires finaux (écritures, emails, traitement de fichiers)
Utilisez les mêmes « conteneurs » partout. Sur le web, le transport le plus courant est un en-tête HTTP (beaucoup d’équipes utilisent un nom comme X-Request-Id ou X-Correlation-Id). Sur le serveur, stockez-le dans le contexte par requête pour que chaque ligne de log puisse l’inclure automatiquement. Pour les jobs, ajoutez-le aux métadonnées du job ou au payload pour que le worker puisse le restaurer avant de logguer.
La traçabilité casse généralement aux frontières :
- redirections et navigations cross-domain qui suppriment les en-têtes personnalisés
- retries et timeouts qui créent un nouvel ID de requête sans copier l’ancien
- publishers de queue qui oublient d’inclure l’ID dans le payload du job
- code worker qui logge avant d’avoir chargé l’ID dans le contexte de logging
- fan-out (un clic déclenche beaucoup de jobs) sans relation parent-enfant claire
Une règle simple qui évite beaucoup de confusion : le premier backend qui reçoit la requête est la source de vérité. Le frontend peut transmettre un ID existant quand il en a un, mais le backend décide de ce qui est accepté et de ce qui est généré.
Étape par étape : ajouter les IDs de corrélation de bout en bout
Choisissez un seul nom d’entête et utilisez-le partout. La cohérence compte plus que l’orthographe exacte, car chaque saut (navigateur, API, queue, worker) doit reconnaître le même champ.
Commencez côté frontend. Quand l’utilisateur clique sur un bouton, réutilisez un ID existant pour l’action en cours ou créez-en un nouveau. Conservez-le en mémoire (ou dans un objet de contexte de courte durée) et joignez-le à chaque appel API déclenché par ce clic.
Côté API, lisez l’en-tête dans un middleware. S’il manque, générez-en un. Sauvegardez-le dans le contexte de requête pour que les logs, erreurs et appels en aval puissent l’inclure. Répondez-le aussi dans l’en-tête de réponse, afin que le navigateur (et le support) puisse référencer l’ID exact utilisé.
Un flux pratique ressemble à ceci :
- Le frontend définit
X-Correlation-Idune fois par action utilisateur et le réutilise pour les requêtes liées. - L’API accepte l’en-tête (ou en crée un), le stocke dans le contexte de requête, et l’inclut dans les réponses.
- L’enqueue copie le même ID dans les métadonnées ou le payload du job.
- Le worker restaure l’ID dans le contexte du worker avant de logguer.
- Les erreurs incluent l’ID dans les réponses affichées aux utilisateurs ou au support.
Les retries sont un endroit où les équipes perdent souvent la piste. Si une requête est retentée à cause d’un timeout, gardez le même ID pour qu’on sache que c’est toujours la même action utilisateur. Si l’utilisateur reclique plus tard, générez un nouvel ID.
Si vous travaillez dans un codebase en désordre, implémentez cela en un seul endroit par couche : un helper frontend, un middleware API et un wrapper de job. C’est généralement suffisant pour rendre le débogage prévisible.
Des logs qui rendent l’ID utile
Un ID de corrélation n’aide que s’il apparaît dans les logs que vous lisez réellement. La façon la plus simple de le rendre filtrable est de logger dans un format structuré et cohérent. Des logs JSON sont faciles à filtrer par correlation_id et à comparer entre frontend, API et jobs en arrière-plan.
Au minimum, chaque ligne de log liée à une requête devrait inclure quelques champs de confiance :
correlation_idroute(ouaction)status(statut HTTP ou résultat du job)message(court, lisible par un humain)duration_ms(quand applicable)
Ne loggez pas tout. Une base propre est une ligne au démarrage de la requête, une au terme, et des lignes supplémentaires seulement pour les branches importantes comme les échecs de validation, les retries, les appels externes et les exceptions.
Voici ce que “visible en succès et en échec” peut donner :
{"level":"info","message":"request_start","correlation_id":"c-9f3a","route":"POST /checkout","user_id":"u_42"}
{"level":"info","message":"request_end","correlation_id":"c-9f3a","route":"POST /checkout","status":200,"duration_ms":184}
{"level":"error","message":"payment_failed","correlation_id":"c-9f3a","route":"POST /checkout","status":402,"error":"card_declined"}
Faites attention à ce que vous loggez. N’exportez pas les corps de requête complets, les en-têtes d’auth, les tokens, les cookies ou des secrets. Loggez plutôt de petits résumés comme items_count, plan=pro, provider=stripe, ou email_domain=gmail.com. Cela compte encore plus dans les prototypes développés rapidement, où les logs peuvent accidentellement afficher des variables d’environnement ou des URLs de base de données.
Jobs en arrière-plan : conserver la piste à travers les queues
Les logs de requêtes et les logs de jobs répondent à des questions différentes. Les logs de requêtes couvrent ce qui s’est passé pendant que l’utilisateur attendait : le clic, l’appel API, la réponse. Les logs de job couvrent ce qui s’est passé après : envois d’emails, traitement de fichiers, retries, et échecs qui apparaissent des minutes plus tard. Sans un identifiant partagé, ces deux mondes ne se rencontrent jamais.
Quand vous publiez un message dans une queue, joignez le même ID que celui utilisé pour la requête API. Certaines équipes le placent dans les métadonnées du message (headers/attributes) et aussi dans le payload en fallback. L’essentiel est la cohérence : choisissez un nom de champ et utilisez-le partout pour que la recherche dans les logs soit prévisible.
Un pattern lisible :
- Utilisez un ID racine par action utilisateur.
- Quand l’API met en file un job, incluez cet ID racine et éventuellement un ID de job séparé.
- Si un clic crée plusieurs jobs, conservez le même ID racine pour tous.
- Pour des jobs planifiés sans clic utilisateur, générez un nouvel ID racine au scheduler.
Côté worker, traitez l’ID comme la première chose à lire. Avant de logguer quoi que ce soit, extrayez l’ID du message, placez-le dans le contexte de log, puis commencez le traitement. Sinon, l’échec le plus pénible survient : le job fait un travail utile, plante, et ne logge qu’après sans l’ID.
Le fan-out mérite une règle supplémentaire : conservez l’ID racine partagé, mais ajoutez un identifiant enfant par job pour savoir quelle branche a échoué.
Rendre l’ID visible pour le support et les rapports de bug
Si seuls les ingénieurs peuvent voir l’ID, cela n’aidera pas quand un client signale « le bouton n’a rien fait ». Rendre l’ID de corrélation facile à trouver quand quelque chose va mal, afin que le support puisse le demander et que l’ingénierie puisse aller directement aux bons logs.
Une approche simple est d’afficher un petit libellé sur les états d’erreur, pas sur chaque écran. Mettez-le là où les utilisateurs regardent déjà les détails : un toast d’erreur, un message de formulaire échoué, ou une page « Quelque chose s’est mal passé ».
Comment l’afficher sans embrouiller les utilisateurs
Utilisez une ligne calme comme : « Référence : ABCD-1234. » Évitez des mots comme « trace » ou « distribué ». Si l’ID est long, montrez une version raccourcie (par exemple les 8–12 premiers caractères) et gardez la valeur complète disponible via un bouton « Copier ».
Le support a aussi besoin d’un script cohérent. Restez simple : demandez le code “Référence”, et s’ils ne le voient pas, demandez de reproduire et de faire une capture d’écran de l’erreur. Si possible, collectez l’heure approximative et ce qu’ils ont cliqué, puis collez le code dans le ticket pour que l’ingénierie puisse rechercher immédiatement.
Note sur la vie privée
Traitez les IDs de corrélation comme une étiquette de diagnostic, pas comme des données personnelles. N’y encodez pas d’emails, d’IDs utilisateur, ou d’empreintes de périphérique. Gardez-les aléatoires et inoffensifs pour qu’ils soient sûrs à partager dans une capture d’écran ou un ticket.
Erreurs courantes qui cassent la traçabilité
La plupart des échecs de traçage ne sont pas des bugs sophistiqués. Ce sont des petits choix qui coupent la chaîne entre un clic, une requête API, et un job en arrière-plan.
- Générer un nouvel ID à chaque saut. Les nouveaux IDs sont acceptables pour des sous-opérations, mais conservez l’original comme parent.
- Écraser un ID existant venu d’en amont. Gateways, CDNs ou services partenaires peuvent déjà envoyer un request ID. Si vous le remplacez, vous perdez la capacité d’apparier leurs logs aux vôtres.
- Oublier l’ID lors de l’enqueue. Si le log API montre l’ID mais que le log du job n’a rien, vous serez obligé de deviner.
- Le loguer dans un seul étage seulement. Les IDs uniquement frontend n’aident pas si le serveur échoue avant de répondre. Les IDs uniquement serveur n’aident pas le support à relier ce que l’utilisateur a vu.
- Considérer l’ID comme un mécanisme de sécurité. Un ID de corrélation n’est pas un token de session. Ne l’utilisez pas pour l’auth et n’y mettez pas de secrets.
Un exemple rapide : un utilisateur clique sur « Exporter ». Le navigateur crée un ID, mais l’API en génère un autre et ne logge que celui-ci. Le job d’export plus tard logge son propre ID aléatoire. Vous vous retrouvez alors avec trois IDs sans lien pour un seul clic.
Une règle simple corrige la plupart de ces cas : acceptez un ID entrant, validez son format, puis transmettez-le inchangé. Si vous avez besoin de détails supplémentaires, ajoutez un second champ comme parent_id ou job_id.
Checklist rapide pour confirmer que ça fonctionne
Vous savez que les IDs de corrélation font leur travail quand un seul ID peut répondre : « que s’est-il passé après ce clic ? »
Testez une action (staging suffit) : cliquez sur « Enregistrer », récupérez l’ID de corrélation depuis l’UI ou l’en-tête de réponse, puis recherchez-le dans les logs serveur. Vous devriez voir un démarrage et une fin de requête clairs, plus tous les appels en aval.
Checklist :
- Un ID trouve le démarrage de la requête API, les étapes clés, et la fin de la requête.
- Le même ID apparaît dans chaque job en arrière-plan créé par cette requête (enqueue, démarrage du job, fin du job).
- Les erreurs incluent l’ID et un message simple sur ce qui a échoué (pas uniquement une stack trace).
- Les retries conservent le même ID de corrélation pour la même action utilisateur et ajoutent un numéro de tentative.
- Le support peut demander l’ID et trouver la piste complète sans deviner.
Vérifications pratiques : si la recherche par ID de corrélation ne renvoie qu’une seule ligne, vous ne l’attachez pas à toutes les lignes de log. Si un clic produit plusieurs IDs non liés, vous générez de nouveaux IDs dans l’API ou le runner du job au lieu de transmettre l’original.
Exemple : tracer un clic échoué à travers une API et un job
Un client clique sur « Payer » sur votre page de checkout. Le bouton tourne une seconde, puis l’UI affiche une erreur générique : « Quelque chose s’est mal passé. » Sans ID partagé, vous devinez. Avec des IDs de corrélation, vous suivez un seul fil du navigateur au backend puis à la file de jobs.
Dans le navigateur, l’app crée un ID dès le clic et l’envoie avec l’appel API dans un header (par exemple X-Correlation-Id). L’utilisateur ne le voit que si vous choisissez d’afficher un code de référence en cas d’erreur.
Ce que vous recherchez, dans l’ordre :
- Console du navigateur :
pay_click correlationId=7f3a... - Log d’accès API :
POST /api/pay correlationId=7f3a... status=500 - Log d’erreur API :
correlationId=7f3a... error="Stripe token missing" userId=... - Enregistrement de la queue :
job=enrich_receipt correlationId=7f3a... queued - Log du worker :
correlationId=7f3a... failed error="DB timeout" retry=1
La recherche devient alors rapide. Plutôt que de scanner toutes les erreurs de paiement de la dernière heure, vous filtrez par correlationId=7f3a... et obtenez une timeline resserrée : clic à 10:14:03, erreur API à 10:14:04, retry du job à 10:14:20.
Souvent vous découvrez deux problèmes à la fois : le bug produit (« Stripe token missing ») et le manque d’observabilité qui rendait tout aléatoire (le worker n’a pas loggé le même ID, ou le message en file l’a perdu).
Étapes suivantes si votre app est difficile à déboguer aujourd’hui
Si votre app est impossible à suivre, ne tentez pas de tout réparer en une fois. Déployez cela sur une petite portion, prouvez que ça marche, puis étendez.
Commencez par une action utilisateur qui casse souvent (par ex. « Enregistrer les paramètres ») et tracez-la via un endpoint API et un type de job. Choisissez quelque chose que vous pouvez déclencher plusieurs fois. Quand vous pouvez prendre un seul ID depuis le navigateur et retrouver chaque ligne de log associée, vous avez construit le pattern à réutiliser.
Rédigez une courte note de convention pour éviter la dérive :
- quel nom d’en-tête vous acceptez et transmettez
- quel nom de champ de log vous écrivez
- où l’ID est généré et quand il est réutilisé
- comment il est passé dans les jobs en arrière-plan
- où le support peut le voir dans l’UI
Si vous avez hérité d’un prototype généré par IA qui casse en production, il est souvent utile de commencer par un audit ciblé pour repérer où les IDs et le contexte de logging se perdent entre API, queues et workers. Les équipes utilisent FixMyMess (fixmymess.ai) pour ce type de diagnostic et de réparation de codebase, surtout quand elles doivent rendre une app existante prête pour la production rapidement.
Une fois le premier endpoint et job traçables, étendez tranche par tranche. Le débogage s’améliore chaque semaine, sans attendre une réécriture complète.
Questions Fréquentes
What is a correlation ID in plain English?
Un ID de corrélation est une seule valeur opaque qui étiquette un flux de bout en bout, par exemple un clic et tout ce qu’il déclenche. Il vous permet de rechercher une fois dans les logs et de voir l’événement frontend, la requête API, les appels en aval et les jobs en arrière-plan associés.
Where should the correlation ID be generated?
Générez-le au point d’entrée le plus tôt et digne de confiance, généralement le premier backend (gateway ou middleware API). Si le client en envoie un, acceptez-le seulement s’il correspond au format attendu ; sinon générez-en un nouveau et utilisez-le comme source de vérité.
Should a correlation ID contain user or business data?
Considérez-le comme une étiquette de diagnostic, pas un identifiant utilisateur. Il ne doit pas contenir d’emails, d’identifiants utilisateur, d’IDs de commande ou toute donnée sensible, car il finira dans les logs, captures d’écran et tickets de support.
How do I pass the correlation ID from the browser to the API?
Choisissez un nom d’entête unique et envoyez-le sur chaque requête API liée à la même action utilisateur. Répondez-le aussi dans l’en-tête de réponse afin que le navigateur et le support puissent référencer l’ID exact utilisé par le serveur.
Should retries reuse the same correlation ID or generate a new one?
Oui, tant que les retries concernent la même action utilisateur. Conserver le même ID permet d’indiquer clairement que plusieurs tentatives appartiennent à un seul clic ; vous pouvez ajouter un compteur de tentatives dans les logs pour plus de précision.
How do I keep the correlation ID when work moves to a queue/background job?
Copiez le même ID de corrélation dans les métadonnées du message ou dans le payload du job lorsque vous mettez en file. Faites en sorte que le worker restaure cet ID dans le contexte de logging avant de produire la moindre entrée de log. Si le worker logge sans restaurer l’ID, la piste se brise exactement là où vous en avez besoin.
What if one click triggers multiple background jobs?
Utilisez un ID racine pour tout le clic, et ajoutez un identifiant de job séparé pour chaque branche si vous avez besoin de les distinguer. Ainsi, en recherchant l’ID racine vous verrez l’histoire complète, tout en pouvant isoler quel job a échoué.
What should I log alongside the correlation ID to make it actually useful?
Enregistrez-le toujours comme un champ cohérent sur chaque ligne de log liée à une requête ou un job, idéalement dans des logs structurés pour faciliter le filtrage. Une base simple : une ligne au début, une ligne à la fin, et des lignes supplémentaires uniquement pour les branches importantes (appels externes, retries, exceptions).
How can I expose the correlation ID to users and support without confusing them?
Affichez-le uniquement lors d’états d’erreur sous la forme d’un code “Référence” pour que des utilisateurs non techniques puissent le partager sans confusion. Si l’ID complet est long, montrez une version courte et fournissez une option pour copier la valeur complète pour le support.
What’s the quickest way to implement this in a messy or AI-generated codebase?
Le plus rapide est souvent d’ajouter un helper frontend, un middleware API et un wrapper pour les jobs afin de standardiser les IDs et la journalisation, puis d’étendre endpoint par endpoint. Si vous avez hérité d’une app générée par IA où IDs, auth ou logs sont emmêlés, FixMyMess peut effectuer un audit de code gratuit et généralement corriger les problèmes critiques en 48–72 heures, en rendant la traçabilité bout en bout fonctionnelle.