Journalisation structurée pour un débogage en production en 5 minutes
La journalisation structurée facilite la reproduction rapide des bugs en production. Ajoutez des identifiants de requête, des error boundaries et des motifs de logs prêts à copier pour un débogage en 5 minutes.
Pourquoi les bugs en production semblent impossibles à reproduire
Un rapport de bug en production ressemble souvent à ça : « Ça a planté quand j'ai cliqué sur le bouton. » Pas de capture d'écran, pas d'heure exacte, pas d'ID utilisateur, et aucune indication sur l'appareil ou le navigateur. Quand vous essayez vous-même, tout fonctionne.
La production est désordonnée parce que les conditions exactes sont difficiles à recréer. Les vrais utilisateurs ont des comptes différents, des données différentes, des réseaux instables, plusieurs onglets ouverts et des sessions périmées. Un problème de timing rare peut déclencher un crash que vous ne voyez jamais en staging.
Les prints console et les messages d'erreur vagues ne survivent pas dans cet environnement. La console d'un utilisateur n'est pas votre console, et même si vous collectez des logs, « quelque chose a échoué » ne vous dit pas quelle requête, quel feature flag ou quel service en amont a déclenché le problème. Pire : une seule erreur non gérée peut arrêter l'app avant qu'elle n'enregistre le détail dont vous aviez besoin.
L'objectif est simple : quand un rapport arrive, vous devez pouvoir répondre à trois questions en quelques minutes :
- Que s'est-il passé (l'événement et l'action utilisateur)
- Où cela s'est-il produit (la requête exacte, la page et le composant)
- Pourquoi cela s'est produit (l'erreur, plus le contexte important)
C'est pour cela que la journalisation structurée compte. Plutôt que de vider des phrases aléatoires, vous enregistrez des événements cohérents avec les mêmes champs à chaque fois, afin de filtrer et suivre l'histoire à travers les services et les écrans.
Vous n'avez pas besoin d'une grosse refonte pour y arriver. De petits changements suffisent : ajoutez un identifiant de requête à chaque requête, incluez-le dans chaque ligne de log, et attrapez les plantages avec des error boundaries pour capturer le contexte quand l'interface plante.
Voici un exemple réaliste. Un fondateur dit : « Le checkout tourne parfois indéfiniment. » Sans meilleurs logs, vous devinez : le fournisseur de paiement ? la base de données ? l'auth ? Avec des request IDs et des événements cohérents, vous pouvez chercher un ID et voir : checkout_started, payment_intent_created, puis un timeout sur inventory_reserve, suivi d'une erreur UI. Vous avez alors un chemin d'échec unique à reproduire.
Si vous héritez d'une application générée par l'IA où les logs sont aléatoires ou manquants, c'est généralement l'une des corrections à plus fort retour sur investissement. Des équipes comme FixMyMess commencent souvent par un audit rapide de ce que vous pouvez tracer aujourd'hui, puis ajoutent le minimum de journalisation pour que le prochain bug prenne 5 minutes à enquêter au lieu d'une semaine d'hypothèses.
Qu'est-ce que des logs structurés, en termes simples
Les logs en texte brut sont ceux que vous avez probablement déjà vus : une phrase imprimée dans la console comme « User login failed ». Ils sont faciles à écrire, mais difficiles à utiliser quand ça casse en production. Chacun formule les messages différemment, des détails sont oubliés, et la recherche devient de la conjecture.
La journalisation structurée signifie que chaque ligne de log suit la même forme et inclut des détails clés en champs nommés (souvent en JSON). Au lieu d'une phrase, vous enregistrez un événement plus le contexte autour. De cette façon, vous pouvez filtrer, grouper et comparer les logs comme des données.
Un bon log devrait répondre à quelques questions de base :
- Qui a été affecté (quel utilisateur ou compte)
- Que s'est-il passé (l'action ou l'événement)
- Où cela s'est-il produit (service, route, écran, fonction)
- Quand cela s'est produit (l'horodatage est généralement ajouté automatiquement)
- Résultat (succès ou échec, et pourquoi)
Voici la différence en pratique.
Texte brut (difficile à rechercher) :
Login failed for user
Structuré (facile à filtrer et grouper) :
{
"level": "warn",
"event": "auth.login",
"userId": "u_123",
"requestId": "req_8f31",
"route": "/api/login",
"status": 401,
"error": "INVALID_PASSWORD"
}
Les champs les plus utiles sont généralement les plus ennuyeux que vous regretteriez d'avoir manqués plus tard : event, userId (ou account/team ID), requestId et status. Si vous n'ajoutez que quatre champs, commencez par ceux-ci. Ils vous permettent de répondre : « Quelle requête exacte cet utilisateur a-t-il effectuée, et que l'application a-t-elle renvoyé ? »
La structure est ce qui rend le débogage en production rapide. Vous pouvez rapidement rechercher tous les échecs event = auth.login, grouper par status, ou tirer tous les logs avec requestId = req_8f31 pour voir l'histoire complète d'un problème utilisateur. C'est la différence entre faire défiler pendant 30 minutes et trouver le problème en 5.
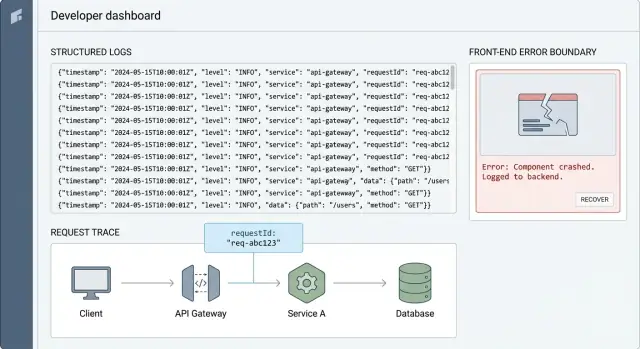
Les request IDs : le moyen le plus rapide pour tracer un problème utilisateur
Un request ID est une courte chaîne unique (comme req_7f3a...) que vous attachez à une action utilisateur unique. Le but est simple : il relie tout ce qui est arrivé pour cette action, du clic frontend, à l'API, à la requête base de données, et retour.
Sans cela, le débogage en production devient de la devinette. Vous cherchez dans les logs par heure, utilisateur ou endpoint et vous tombez sur une pile de messages non liés. Avec un request ID, vous filtrez pour n'obtenir qu'une histoire et la lire dans l'ordre.
C'est de la corrélation : le même ID apparaît dans chaque ligne de log qui appartient à la même requête. C'est la colle qui rend la journalisation structurée réellement exploitable quand vous êtes sous pression.
Où créer l'identifiant de requête
Créez l'ID le plus tôt possible, puis passez-le à travers toutes les couches.
- Au bord (CDN / load balancer) ou au gateway API, si vous en avez un
- Sinon au point d'entrée du backend (le premier middleware qui gère la requête)
- Si aucun n'existe (commun dans les prototypes générés par l'IA), générez-le dans le handler serveur avant tout autre travail
Une fois créé, renvoyez-le au client dans un header de réponse aussi. Quand un utilisateur dit « Ça a planté », vous pouvez demander cet ID ou l'afficher dans un écran de support.
Quand réutiliser vs générer un nouvel ID
Réutilisez le même request ID pour toute la durée d'une requête, y compris les appels internes déclenchés par celle-ci. Si votre API appelle un autre service, passez l'ID pour que la trace reste intacte.
Générez un nouvel ID quand vous ne traitez plus la même requête :
- Reprises (retries) : conservez l'ID original comme parent, mais donnez à chaque tentative son propre attempt ID (pour voir les échecs répétés)
- Jobs en arrière-plan : créez un nouvel job ID et stockez l'ID de requête original comme « trigger » (pour reconnecter le job à l'action utilisateur)
Un exemple simple : un utilisateur clique sur « Payer » et obtient une erreur. Le frontend log requestId=abc123, l'API journalise le même abc123 avec la route et l'ID utilisateur, et la couche base de données journalise abc123 à côté de la requête et du temps. Quand le paiement échoue, vous pouvez afficher abc123 et voir exactement où ça a cassé, généralement en quelques minutes.
Comment ajouter des request IDs de bout en bout (pas à pas)
Un request ID est une courte valeur unique qui suit une action utilisateur à travers votre système. Quand le support dit « le checkout a échoué à 14h14 », le request ID vous permet d'extraire chaque ligne de log liée en secondes.
Configuration pas à pas
Utilisez le même schéma de base dans n'importe quelle stack :
- Créer (ou accepter) un request ID au bord du serveur. Si le client en envoie déjà un (souvent
X-Request-Id), conservez-le. Sinon, générez-en un dès que la requête entre dans votre API. - Stockez-le dans le contexte de requête afin que chaque log l'inclue. Mettez-le quelque part dans le code accessible sans le passer à chaque fonction. Beaucoup de frameworks ont un stockage local à la requête. Sinon, attachez-le à l'objet request.
- Renvoyez-le au client dans la réponse. Ajoutez un en-tête de réponse comme
X-Request-Id. Cela donne au support et aux utilisateurs quelque chose de concret à copier. - Transmettez-le aux systèmes en aval. Ajoutez le même header sur les appels HTTP sortants, incluez-le dans les payloads de queue/job, et passez-le aux wrappers de base de données pour que les requêtes lentes puissent être rattachées à la même requête.
- Incluez-le dans les rapports d'erreurs (optionnel). Quand vous capturez des exceptions, joignez
requestIdpour que les rapports de crash et les logs correspondent. Pour les erreurs visibles par l'utilisateur, vous pouvez afficher un court « code de support » dérivé du request ID.
Voici un exemple simple de style Node/Express. L'idée est la même dans les autres langages :
import crypto from "crypto";
app.use((req, res, next) => {
const incoming = req.header("X-Request-Id");
req.requestId = incoming || crypto.randomUUID();
res.setHeader("X-Request-Id", req.requestId);
next();
});
function log(req, level, message, extra = {}) {
console.log(JSON.stringify({
level,
message,
requestId: req.requestId,
...extra
}));
}
Une fois ceci en place, votre journalisation structurée devient instantanément plus utile : chaque événement peut être recherché par requestId, même si le problème saute entre les services.
Si vous avez hérité d'une app générée par l'IA où les logs sont des chaînes aléatoires (ou complètement absents), ajouter des request IDs est l'une des réparations les plus rapides car cela améliore le débogage sans changer la logique métier.
Concevoir des événements de log que vous pouvez réellement rechercher
De bons logs se lisent comme une timeline. Quand quelque chose casse, vous devez pouvoir répondre : que s'est-il passé, pour quelle requête, et quelle décision le code a prise.
Avec la journalisation structurée, cela signifie que chaque ligne de log est un petit enregistrement avec les mêmes champs à chaque fois, pas une phrase libre. La cohérence est ce qui fait fonctionner la recherche.
Commencez par un petit ensemble de noms d'événements
Choisissez quelques types d'événements centraux et réutilisez-les dans l'app. Évitez d'inventer un nouveau nom pour la même chose chaque semaine.
Voici des types d'événements courants qui restent utiles dans le temps :
- request_started
- request_finished
- db_query
- auth_failed
- error
Nommez les événements en minuscules avec des underscores, et gardez la signification stable. Par exemple, si vous avez déjà auth_failed, n'ajoutez pas login_denied et sign_in_rejected plus tard sauf s'ils signifient quelque chose de différent.
Loggez une décision, pas une ligne de code
Une règle simple : loggez quand le programme prend une décision qui change le résultat. C'est le point que vous voudrez retrouver plus tard.
Mauvais : logger chaque ligne autour d'un appel base de données.
Mieux : un seul événement db_query qui vous dit ce qui compte : quel modèle/table (pas le SQL brut), s'il a réussi, et combien de temps ça a pris.
Incluez toujours des champs de résultat
Facilitez le filtrage des échecs et des chemins lents. Ajoutez quelques champs qui apparaissent sur la plupart des événements :
- ok : true ou false
- errorType : une courte catégorie comme ValidationError, AuthError, Timeout
- durationMs : pour tout ce qui est mesuré (requêtes, db, API externe)
- statusCode : pour les réponses HTTP
Un exemple réaliste : si un utilisateur signale « le checkout échoue », vous devriez pouvoir rechercher event=auth_failed ou ok=false, puis filtrer par statusCode=401 ou errorType=AuthError, et enfin repérer la partie lente en triant par durationMs.
Si vous héritez d'un code généré par l'IA, cela manque souvent ou est incohérent. Chez FixMyMess, une des premières réparations est de normaliser les noms d'événements et les champs pour que le débogage en production cesse d'être de la devinette.
Niveaux de logs et volume sans se noyer dans le bruit
Si chaque événement est loggé comme une erreur, vous cessez de faire confiance à vos logs. Si vous loggez tout en debug, vous enterrez l'indice dont vous aviez besoin. Un bon débogage en production commence par une promesse simple : les logs par défaut doivent expliquer ce qui s'est passé sans inonder votre système.
À quoi sert chaque niveau
Pensez aux niveaux de log comme un système de tri pour l'urgence et l'attente. Dans la journalisation structurée, le niveau est juste un champ sur lequel vous pouvez filtrer.
- DEBUG : Détails que vous ne voulez voir que pendant une enquête. Exemple : le temps de réponse d'une API en aval ou la branche exacte prise par votre code.
- INFO : Jalons normaux. Exemple : « user signed in », « payment intent created », « job completed ».
- WARN : Quelque chose a mal tourné, mais l'app peut récupérer. Exemple : retry d'une requête, utilisation d'une valeur de secours, un service tiers renvoyant un 429.
- ERROR : L'opération a échoué et nécessite de l'attention. Exemple : exception non gérée, écriture DB échouée, ou une requête qui renvoie un 5xx.
Une règle pratique : si cela va réveiller quelqu'un la nuit s'il y a un pic, c'est probablement ERROR. Si cela aide à expliquer une plainte utilisateur plus tard, c'est probablement INFO. Si c'est utile uniquement quand vous avez un ticket spécifique, c'est DEBUG.
Garder le volume sous contrôle
Les endpoints à fort trafic peuvent générer rapidement du bruit, surtout dans des apps générées par l'IA où la journalisation est souvent ajoutée partout sans plan. Plutôt que supprimer des logs, contrôlez le flux.
Utilisez des tactiques simples :
- Échantillonnage : Logger 1% des requêtes réussies, mais 100% des WARN et ERROR. L'échantillonnage est surtout utile sur les health checks, les endpoints de polling et les jobs bruyants.
- Limites de débit : Si le même avertissement se répète, loggez-le une fois par minute avec un compteur.
- Un événement par résultat : Préférez un seul log « request finished » avec duration et status plutôt que 10 petits logs.
Enfin, surveillez la performance. Évitez la construction de chaînes lourdes ou la sérialisation JSON dans les chemins chauds. Logger des champs stables (comme route, status, duration_ms) et ne calculer les détails coûteux que lorsque le niveau est activé.
Error boundaries : attraper les plantages et conserver le contexte utile
Une error boundary est un filet de sécurité dans l'UI. Quand un composant plante pendant le rendu, une méthode de cycle de vie ou un constructeur, la boundary l'attrape, affiche un écran de secours et (surtout) enregistre ce qui s'est passé. C'est ainsi que vous transformez une page blanche et une plainte vague en quelque chose que vous pouvez reproduire.
Ce qu'elle attrape : les erreurs UI synchrones qui surviennent pendant la construction de la page. Ce qu'elle n'attrape pas : les erreurs dans les gestionnaires d'événements, les timeouts ou la plupart du code asynchrone. Pour ceux-là, vous avez toujours besoin de try/catch et de gestion des promesses rejetées.
Que logguer quand l'UI plante
Quand la boundary se déclenche, loggez un seul événement avec assez de contexte pour rechercher et grouper les échecs similaires. Si vous faites de la journalisation structurée, gardez les clés cohérentes.
Capturez :
route(le chemin actuel) et tout état UI important (onglet, modal ouvert, étape d'un wizard)component(où ça a planté) eterrorName+messageuserAction(ce que l'utilisateur vient de faire, comme "clicked Save")requestId(si vous en avez un depuis le serveur ou votre client API)- info de
build(version de l'app, environnement) pour matcher avec une release
Voici une forme simple :
log.error("ui_crash", {
route,
component,
userAction,
requestId,
errorName: error.name,
message: error.message,
stack: error.stack,
appVersion,
});
Ce que l'utilisateur doit voir vs ce dont les devs ont besoin
Le message utilisateur doit être calme et sûr : « Quelque chose s'est mal passé. Veuillez rafraîchir. Si cela persiste, contactez le support. » Évitez d'afficher le texte d'erreur brut, les stack traces ou des IDs qui pourraient révéler des détails internes.
Les développeurs, en revanche, ont besoin du contexte complet dans les logs. Un bon schéma consiste à afficher un court « code d'erreur » dans l'UI (comme un timestamp ou un token aléatoire) et à logger l'événement détaillé avec ce même token.
Côté serveur, utilisez l'équivalent : un handler global d'erreurs pour les requêtes, plus des handlers pour les promesses rejetées non gérées et les exceptions non capturées. C'est là que beaucoup d'apps générées par l'IA échouent, et pourquoi des équipes comme FixMyMess trouvent souvent des plantages « silencieux » sans requestId et sans logs utiles.
Si vous mettez cela en place une fois, un crash en production cesse d'être un mystère et devient un événement recherchable que vous pouvez corriger rapidement.
Journaliser en toute sécurité : éviter de divulguer des secrets et des données personnelles
De bons logs vous aident à corriger les bugs rapidement. De mauvais logs créent de nouveaux problèmes : mots de passe fuités, clés d'API exposées et données personnelles que vous n'aviez pas l'intention de stocker. Une règle simple fonctionne bien : loggez ce dont vous avez besoin pour déboguer le comportement, pas ce que l'utilisateur a tapé.
Ne loggez jamais ceci (même « juste pour l'instant") : mots de passe, cookies de session, tokens d'auth (JWT), clés d'API, codes OAuth, clés privées, numéros complets de carte, CVV, informations bancaires, et copies complètes de documents. Traitez aussi les données personnelles comme sensibles : adresses email, numéros de téléphone, adresses postales, IPs (dans de nombreux cas), et champs de texte libre qui peuvent contenir n'importe quoi.
Alternatives plus sûres qui permettent quand même de déboguer
Au lieu de vider des payloads entiers, loggez de petits éléments stables de contexte qui vous aident à reproduire le problème.
- Redaction : remplacez les secrets par "[REDACTED]" (faites-le automatiquement).
- Valeurs partielles : loggez seulement les 4 derniers caractères d'un token ou d'une carte.
- Hash : loggez un hash unidirectionnel d'un email pour corréler les événements sans stocker l'email.
- Utilisez des IDs : userId, orderId, invoiceId et requestId suffisent généralement.
- Résumez : loggez des comptes et des types ("3 items", "payment_method=card") au lieu de l'objet complet.
Exemple : au lieu de logger un checkout entier, loggez orderId, userId, cartItemCount et paymentProviderErrorCode.
Pourquoi le code généré par l'IA fuit des secrets (et comment l'empêcher)
Les prototypes générés par l'IA loggent souvent des corps de requête entiers, des headers ou des variables d'environnement en mode « debug ». C'est risqué en production, et facile à manquer parce que « ça marche ». Cherchez les pièges courants : console.log(req.headers), print(request.json()), loguer process.env, ou logger l'objet d'erreur complet qui inclut les headers.
Protégez-vous avec deux habitudes : nettoyer avant de logger, et bloquer les clés dangereuses par défaut. Créez un petit wrapper de "safe logger" qui redige automatiquement des champs comme password, token, authorization, cookie, apiKey et secret où qu'ils apparaissent.
Enfin, adoptez une politique de rétention. Conservez les logs détaillés seulement aussi longtemps que nécessaire pour le débogage et les revues de sécurité. Gardez les résumés plus longtemps, supprimez les détails bruts plus tôt, et facilitez la purge des logs d'un utilisateur quand c'est requis.
Un exemple réaliste de débogage en 5 minutes
Un utilisateur rapporte : « Je n'arrive pas à me connecter. Ça marche sur mon laptop, mais pas en production. » Vous ne pouvez pas le reproduire localement, et le seul indice est un horodatage et leur email.
Avec la journalisation structurée et les request IDs en place, vous partez du rapport utilisateur et remontez à partir d'une seule requête.
Minute 1 : trouver la requête
Votre support ou l'UI de l'app affiche un court « code de support » (qui n'est que le requestId). Si vous n'avez pas encore cette UI, vous pouvez toujours rechercher les logs par identifiant utilisateur (email hashé) autour du moment indiqué, puis extraire le requestId du premier événement correspondant.
Minutes 2–4 : tracer le flux et repérer l'étape qui échoue
Filtrez les logs par requestId=9f3c... et vous avez maintenant une histoire propre : une tentative de login, de bout en bout, à travers plusieurs services.
{"level":"info","event":"auth.login.start","requestId":"9f3c...","userHash":"u_7b1...","ip":"203.0.113.10"}
{"level":"info","event":"auth.oauth.callback","requestId":"9f3c...","provider":"google","elapsedMs":412}
{"level":"error","event":"db.query.failed","requestId":"9f3c...","queryName":"getUserByProviderId","errorCode":"28P01","message":"password authentication failed"}
{"level":"warn","event":"auth.login.denied","requestId":"9f3c...","reason":"dependency_error","status":503}
Cette troisième ligne est la réponse complète : la base de données a rejeté la connexion en production. Parce que le log a un nom d'event stable et des champs comme queryName et errorCode, vous ne perdez pas de temps à lire des murs de texte ou à deviner quelle stack trace appartient à cet utilisateur.
Si vous avez aussi une error boundary côté client, vous pouvez voir un événement correspondant comme ui.error_boundary.caught avec le même requestId (passé en header) et l'écran où ça s'est produit. Cela confirme l'impact visible côté utilisateur sans dépendre de captures d'écran.
Minute 5 : transformer les logs en test reproductible
Vous pouvez maintenant écrire une reproduction précise qui correspond à la réalité :
- Utiliser le même chemin de login (callback Google)
- Exécuter contre une configuration proche de la production (source correcte des user/secret DB)
- Lancer l'opération défaillante unique (
getUserByProviderId) - Affirmer le comportement attendu (retourner un 503 clair avec un message sûr)
Dans beaucoup de bases de code générées par l'IA que nous voyons chez FixMyMess, ce problème exact survient parce que des secrets sont codés en dur localement mais récupérés différemment en production. L'objectif des logs n'est pas d'avoir plus de données, mais les bons champs pour passer d'une plainte utilisateur à une étape défaillante, rapidement.
Checklist rapide, erreurs courantes et prochaines étapes
Quand un problème en production survient, vous voulez des logs qui répondent vite à trois questions : que s'est-il passé, à qui, et où ça a cassé. Cette checklist garde votre journalisation structurée utile sous pression.
Checklist rapide
- Chaque requête reçoit un
requestId, et il apparaît dans chaque ligne de log pour cette requête. - Chaque log d'erreur inclut
errorTypeet une stack trace (ou l'équivalent le plus proche dans votre langage). - L'auth et les paiements (ou tout chemin impliquant de l'argent) ont des événements clairs « start » et « finish » pour repérer où le flux s'arrête.
- Les secrets et tokens sont redigés par défaut, et vous ne dumppez jamais des payloads entiers de requête ou de réponse.
- Les mêmes champs de base sont toujours présents :
service,route,userId(ouanonId),requestId, etdurationMs.
Si vous ne faites rien d'autre, assurez-vous de pouvoir coller un requestId dans votre recherche de logs et voir l'histoire complète depuis le premier handler jusqu'au dernier appel base de données.
Erreurs courantes qui font perdre du temps
Même de bonnes équipes tombent dans quelques pièges qui rendent les logs difficiles à utiliser quand ça compte.
- Noms de champs incohérents (par exemple
req_id,requestIdetrequest_idutilisés à différents endroits). - Contexte manquant (une erreur est loguée, mais vous ne pouvez pas dire quelle route, quel utilisateur ou quelle étape l'a causée).
- Logger seulement en cas d'erreurs (vous avez besoin de quelques événements jalons pour voir où un flux s'arrête).
- Trop de bruit au mauvais niveau (tout est
info, donc les vrais warnings sont enterrés). - Fuites de données accidentelles (tokens, clés API, cookies de session ou payloads de paiement complets dans les logs).
Prochaines étapes : choisissez les 3 flux critiques pour les utilisateurs (souvent signup/login, checkout et reset de mot de passe). Ajoutez des request IDs de bout en bout, puis 3 à 6 événements recherchables par flux (start, étape majeure, finish et un événement d'échec clair). Une fois ces flux solides, étendez au reste de l'app.
Si votre app générée par l'IA est difficile à déboguer parce que les logs sont désordonnés ou manquants, FixMyMess peut réaliser un audit gratuit du code et aider à ajouter des request IDs, des champs d'événements cohérents et une gestion d'erreur plus sûre pour faciliter la reproduction des incidents en production.