Journaux d'audit pour les actions admin qui règlent les litiges rapidement
Les journaux d'audit pour les actions admin vous aident à voir qui a changé quoi, quand et pourquoi. Apprenez quoi capturer, comment ajouter des diffs et comment rechercher les logs pour résoudre les litiges.
Pourquoi les journaux d'audit admin et support comptent
Quand quelque chose change dans une appli et que personne ne peut l'expliquer, le support devient de la conjecture. Le client se sent accusé, les collègues se sentent mis en cause, et de petits problèmes deviennent de longues discussions et ralentissent la résolution d'incidents.
Les actions admin et support sont les gestes en coulisse qui peuvent modifier l'expérience d'un utilisateur sans qu'il n'ait rien fait. Un agent support réinitialise un mot de passe. Un admin change un plan. Quelqu'un supprime du contenu. Ces actions sont souvent nécessaires, mais elles provoquent le plus de disputes parce qu'elles se déroulent hors vue.
Les litiges ressemblent souvent à ça :
- « Je n'ai jamais demandé ce remboursement, pourquoi a-t-il été émis ? »
- « Mon compte a été désactivé, qui l'a fait et quelle règle a été déclenchée ? »
- « Notre abonnement a été rétrogradé et des fonctionnalités ont disparu du jour au lendemain. »
- « Un post a été supprimé, mais nous devons prouver la raison et le moment. »
- « Le support a changé mon email, et maintenant je ne peux plus me connecter. »
À ces moments, l'intérêt d'un journal d'audit n'est pas « plus de données ». C'est une réponse claire. Une bonne entrée montre qui a fait quoi, sur quel enregistrement, et quand. Une excellente entrée montre aussi ce qui a changé (un diff) et assez de contexte pour expliquer pourquoi cela s'est produit (ID de ticket, code de raison, note interne).
Ceci est d'autant plus important pour les équipes qui livrent vite ou qui héritent de code généré par IA. Quand la logique est désordonnée, l'appli peut se comporter différemment de ce que vous attendez, et vous avez quand même besoin d'une piste fiable. Chez FixMyMess, nous voyons souvent des prototypes construits avec des outils comme Cursor ou Replit où les panneaux admin sont à moitié fonctionnels et les actions critiques ne sont pas du tout journalisées — c'est exactement à ce moment que les litiges deviennent douloureux.
De bons logs règlent rapidement les disputes, raccourcissent les investigations et protègent à la fois les clients et votre équipe avec des faits plutôt qu'avec des opinions.
Ce qu'une entrée de journal d'audit devrait contenir
Un journal d'audit n'est utile dans un litige que si chaque entrée répond clairement à cinq questions : qui l'a fait, ce qui s'est passé, ce qui a été affecté, quand cela s'est produit, et d'où cela provient. Si l'une de ces réponses manque, on repart à deviner.
Commencez par l'acteur. Stockez un identifiant stable (ID utilisateur, ID admin ou ID de compte de service) et les permissions qu'il avait à ce moment (rôle). Si le support peut se faire passer pour des utilisateurs, enregistrez-le explicitement : effectué par l'admin X en se faisant passer pour l'utilisateur Y. Sans ça, vous ne pouvez pas savoir si un changement a été fait par le client ou par le personnel en son nom.
Capturez l'action et la cible ensemble. « Mise à jour de l'email client » est mieux que « update », mais ne vous fiez pas uniquement au texte libre. Gardez un nom d'action structuré (create, update, delete, export, password reset, login override) et l'enregistrement exact qui a été touché. Incluez le tenant/workspace pour séparer les comptes.
Pour le temps, stockez un horodatage précis en UTC et ne le formatez en heure locale que pour l'affichage. Les litiges se jouent souvent sur des minutes, et l'UTC évite les confusions avec l'heure d'été.
Ajoutez suffisamment de contexte pour retracer l'événement de bout en bout. Une base solide : point d'entrée (nom de l'écran UI ou endpoint API), ID de requête (et ID de session si vous l'avez), IP source et user agent (quand c'est approprié), résultat (succès/échec avec code d'erreur), et une raison support ou référence de ticket.
Exemple : un client dit « Le support a changé mon plan sans demander ». Une entrée robuste montre l'ID admin, si l'impersonation a été utilisée, une action comme plan_update, le workspace cible, un horodatage UTC, et un ID de requête que vous pouvez suivre jusqu'à l'écran ou l'appel API exact. C'est la différence entre une histoire vague et un log qui règle le problème en quelques minutes.
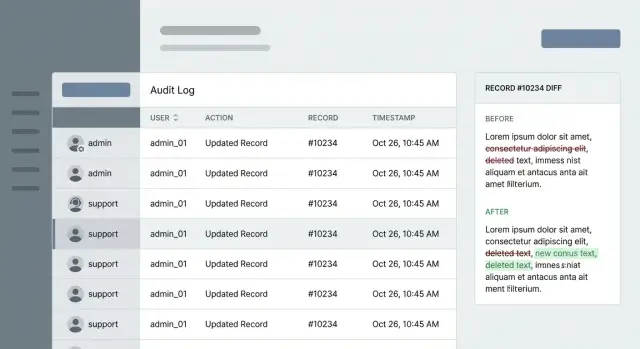
Suivre les diffs sans divulguer de données sensibles
Un diff est le moyen le plus simple de clore les disputes parce qu'il montre les valeurs avant et après pour chaque champ modifié. L'objectif est la clarté sans transformer vos logs en une seconde base de données remplie de données privées.
Ne journalisez que ce qui a changé. Si un admin modifie un profil client, enregistrez une petite charge utile comme role: user -\u003e admin et status: trial -\u003e active, pas le profil complet. Cela rend les entrées lisibles, accélère les recherches et réduit les expositions accidentelles.
Les champs sensibles nécessitent un traitement spécial. Vous ne voulez généralement pas de valeurs brutes dans les logs pour les mots de passe, tokens d'accès, numéros de carte complets ou notes privées. Une règle utile : si vous ne le colleriez pas dans un chat de support, ne le mettez pas dans un journal d'audit.
Approches courantes : masquage (par exemple ****@gmail.com), hachage (empreinte unidirectionnelle), un simple indicateur « changed » (comme password: changed), redaction complète, ou séparation des détails sensibles dans un magasin séparé avec un accès plus strict et une rétention plus courte.
Les diffs sont encore plus utiles avec l'intention. Ajoutez un code de raison (comme customer_request, fraud_review, bug_fix, policy_exception) et une courte note. Lors d'un litige ultérieur, le « pourquoi » compte autant que le « quoi ».
Capturez aussi les IDs liés pour reconstruire l'histoire : ID de ticket, ID de conversation, ID de commande, ID de remboursement, et la clé primaire de l'enregistrement.
Exemple : un client affirme que le support a mis à niveau son plan sans permission. Votre entrée doit montrer plan: basic -\u003e pro, l'identité de l'agent, l'horodatage, le code de raison customer_request et un ID de ticket qui correspond à la conversation où il a demandé le changement. Si vous avez hérité d'un code généré par IA qui journalise trop (ou rien du tout), FixMyMess commence souvent par ajouter des diffs sûrs et des règles strictes de redaction pour que les logs résolvent les litiges au lieu d'en créer de nouveaux.
Comment concevoir des logs fiables à long terme
Des logs fiables tiennent moins aux tableaux de bord sophistiqués qu'à des règles ennuyeuses mais constantes. Si vous voulez que les journaux admin et support règlent des litiges, vous avez besoin d'entrées difficiles à falsifier, faciles à lire et cohérentes à travers tous les chemins de code.
Traitez chaque entrée comme append-only. N'éditez pas d'anciens événements quand quelque chose change ou quand un agent fait une erreur. Écrivez un nouvel événement qui corrige le précédent, pour que l'historique reste complet.
Utilisez une forme d'événement unique partout, même entre équipes et services différents. Quand le support, les admins, les jobs en arrière-plan et les appels API produisent tous des champs différents, le journal cesse de répondre aux questions basiques sous pression.
Un schéma de base pratique :
- who : ID utilisateur, rôle et toute info d'acting-as
- what : nom d'action (par exemple,
user.password_reset) - where : type d'enregistrement et ID de l'enregistrement
- when : horodatage serveur (UTC)
- context : ID de corrélation de requête, source (UI/panel admin/clé API/job en arrière-plan), et IP/appareil quand approprié
Les IDs de corrélation transforment un "on pense que c'est arrivé vers 15h" en preuve. Générez-en un par requête, transmettez-le dans les appels internes et attachez-le à l'événement d'audit. Si une action touche trois tables, le même ID de corrélation permet de relier ces événements à un même ticket de support ou clic.
Enregistrez la source à chaque fois. « L'admin a changé le plan » n'est pas suffisant quand la vraie question est de savoir si cela venait de l'UI admin, d'une clé API utilisée par une agence ou d'un job nocturne.
Planifiez la rétention tôt. Décidez combien de temps vous avez besoin des événements pour les litiges, quelle taille les logs peuvent atteindre et où ils résident. Les équipes qui viennent à FixMyMess découvrent souvent que leur appli générée par IA n'a jamais journalisé d'actions critiques ou a supprimé l'historique trop tôt, ce qui rend la vérification impossible lorsqu'un client conteste une facturation.
Rendre les logs réellement consultables pour le support
La recherche fait la différence entre « on pense que c'est arrivé » et « voici le moment exact où c'est arrivé ». Concevez la recherche comme le support travaille : trouvez un client, réduisez au bon enregistrement, puis confirmez le changement exact.
Gardez les noms d'action courts et cohérents. Une taxonomie serrée (penser dizaines, pas centaines) rend les filtres utilisables et évite le chaos « tout est personnalisé » dans lequel les applis construites rapidement tombent souvent. Si vous avez besoin de plus de détails, mettez-les dans des champs structurés, pas dans un nouveau nom d'action.
Normalisez le minimum pour que chaque événement puisse être filtré de la même manière partout dans l'appli.
Les champs qui rendent la recherche utile
Au minimum, assurez-vous que chaque événement inclut :
- action (par exemple,
user.password_reset,billing.refund_issued) - actor_id et actor_role (admin, support, system)
- record_type et record_id (toujours présents, toujours formatés de la même façon)
- created_at (heure serveur)
- request_id (pour regrouper les événements liés)
Ajoutez ensuite un petit ensemble de champs « contexte support » sûrs qui aident à la recherche : email client (ou une version hachée/normalisée), numéro de commande, nom du workspace/org, et ID de ticket ou de conversation. Gardez-les séparés, pas enfouis dans une phrase.
Évitez les événements bruyants. Les vues de page, ouvertures d'écran et « liste chargée » enterrent le signal. Les journaux d'audit doivent se concentrer sur les actions qui modifient l'état, accordent l'accès ou exposent des données sensibles.
Rendez chaque entrée lisible sans perdre la structure : une phrase claire pour les humains plus des champs structurés pour les filtres. « L'agent support a mis à jour l'email de facturation » est utile, mais doit quand même inclure record_type=workspace, record_id=... et un résumé du diff qui prouve ce qui a changé.
Étape par étape : ajouter la journalisation des actions admin à une appli
Un workflow pratique
Dressez la liste de ce que les admins et le support peuvent réellement faire aujourd'hui, pas de ce que vous espérez qu'ils feront. Transformez chaque capacité en un nom d'événement clair pour que le journal lise comme une chronologie plutôt que comme un tiroir à bazar.
Un workflow simple :
- Inventaire des actions admin/support (remboursement, réinitialisation de mot de passe, changement de plan, édition de profil, attribution de rôle) et associez chacune à un événement.
- Marquez les enregistrements à haut risque qui doivent toujours être journalisés (auth, facturation, permissions, propriété de compte).
- Définissez le contexte requis : acteur, enregistrement cible, horodatage, raison, et un diff sûr.
- Implémentez la journalisation dans la couche service (là où s'exécutent les règles métier), pas éparpillée dans les boutons UI.
- Faites un « test de litige » qui reconstruit qui a changé quoi et pourquoi en utilisant uniquement les logs.
Après avoir cartographié les événements, décidez ce que « cible » signifie dans votre appli. Un bon modèle est target_type (Subscription), target_id (sub_123), et des IDs liés optionnels (comme user_id). Cela facilite grandement les recherches ultérieures.
Où les équipes bloquent généralement
Haut risque ne veut pas dire rare. Cela signifie qu'un changement ici peut coûter de l'argent, verrouiller quelqu'un hors de son compte ou créer un argument de support. Si vous doutez, commencez par un ensemble court : paramètres d'auth, facturation/factures, rôles/permissions, changements d'email/téléphone, et tout ce qui affecte l'accès.
Exigez une raison humaine pour les actions sensibles, même courte. « Le client a confirmé le nouvel email par téléphone » est bien plus utile que « updated ».
Faites un faux litige avant de livrer. Faites comme si un client disait « Le support a rétrogradé mon plan sans demander ». Pouvez-vous extraire un événement qui montre : quel admin, quel enregistrement, le diff avant/après (Plan : Pro -\u003e Basic), la note de raison, et l'horodatage ? Si ce n'est pas le cas, corrigez les champs maintenant.
Si vous réparez une appli générée par IA, journaliser dans la couche service réduit aussi les « événements manquants » quand le code UI change. C'est souvent une des premières corrections que des équipes comme FixMyMess effectuent quand des prototypes deviennent des produits réels.
Actions à haut risque à journaliser à chaque fois
Si vous ne journalisez que quelques choses, concentrez-vous sur les actions qui peuvent modifier l'argent, l'accès ou la confiance. Ce sont les moments qui tournent en litiges : « Je n'ai jamais changé ça », « Le support a accédé à mes données », ou « Quelqu'un s'est octroyé des permissions ».
Les actions qui méritent une journalisation toujours active
Concentrez-vous sur les événements puissants, difficiles à inverser ou touchant des données sensibles. Un test simple : si un utilisateur serait contrarié de le voir sur un relevé, une capture d'écran ou un rapport de conformité, cela appartient au log.
Priorisez :
- Lectures de données sensibles (exports, téléchargements, « voir la carte complète », ouverture de profils contenant des détails privés).
- Changements de rôles et permissions (mises à jour de rôle, appartenance à des groupes, clés API, paramètres SSO, flags admin).
- Impersonation (début, fin, et chaque action prise pendant l'impersonation, en enregistrant à la fois le membre du staff et le compte client).
- Actions en masse (remboursements massifs, suppressions en lot, migrations, éditions par lot), y compris les comptes et références aux IDs affectés.
- Tentatives restreintes échouées (vérifications de permission refusées, tokens admin invalides, exports bloqués), avec des limites de débit pour éviter le bruit.
Un exemple rapide de résolution de litige
Un client dit : « Le support a téléchargé ma liste de factures et a changé mon plan. » Si vos logs capturent à la fois « Export invoices » (lecture) et « Plan changed » (écriture), vous pouvez rapidement montrer qui l'a fait, quand, depuis quelle session, et si cela s'est produit pendant une impersonation.
C'est là que beaucoup de prototypes générés par IA cassent en production : ils journalisent seulement les écritures réussies et omettent les lectures sensibles. Des plateformes comme FixMyMess commencent souvent par ajouter ces événements à haut risque parce qu'ils apportent le plus grand gain de confiance et de support avec un petit changement de code.
Gardez chaque événement facile à comprendre : un nom d'action clair, l(es) enregistrement(s) touché(s), et assez de contexte pour expliquer pourquoi cela s'est produit sans exposer de secrets.
Erreurs courantes qui rendent les journaux d'audit peu fiables
La plupart des litiges n'arrivent pas parce que vous n'avez aucun log. Ils arrivent parce que les logs sont vagues, incomplets ou impossibles à faire confiance plus tard. Une bonne piste d'audit doit se lire comme une preuve : claire, spécifique et difficile à falsifier.
Un échec fréquent est de journaliser un événement générique comme « updated user » sans détail au niveau champ. Quand un client dit « Le support a changé mon plan », vous devez voir exactement ce qui a changé (valeur avant, valeur après), pas seulement que « quelque chose » s'est passé. Sans diffs, vous manquez aussi des motifs comme des basculements répétés ou des écrasements accidentels.
Autre erreur : déverser des secrets et des données personnelles dans la piste. Tokens complets, mots de passe, cookies de session, clés API ou données de paiement brutes ne devraient jamais atterrir dans les logs. Stockez des valeurs rédigées ou des références à la place, et enregistrez que le champ sensible a changé sans enregistrer la valeur.
L'attribution de l'acteur casse plus souvent qu'on ne pense. Les jobs en arrière-plan, webhooks et scripts tournent souvent en tant que « system », même quand ils ont été déclenchés par un humain. Cela rend la piste beaucoup moins utile pour le support réel.
Éléments tueurs de fiabilité à surveiller :
- Les événements peuvent être édités ou supprimés après coup.
- L'acteur manque (ou est toujours « system ») pour les flux automatisés.
- Les identifiants d'enregistrement ne sont pas stables, donc les recherches renvoient du bruit.
- Les noms d'action ne sont pas cohérents, donc les filtres manquent la moitié de l'histoire.
- Les diffs sont partiels ou ambigus (avant/après manquants).
Exemple : un fondateur conteste un changement de remboursement. Votre log devrait montrer le diff du statut du remboursement, le compte admin qui l'a cliqué, le ticket/raison et l'ID de l'enregistrement. Quand FixMyMess audite des applis générées par IA défaillantes, c'est souvent l'une des premières lacunes que nous voyons : « ça a été mis à jour » sans la preuve dont vous avez besoin.
Checklist rapide pour résoudre un litige avec les logs
Quand un client dit « Je n'ai jamais changé ça » ou « Votre équipe a cassé mon compte », l'objectif est simple : construire une chronologie claire que les deux parties peuvent comprendre. De bons logs vous permettent de répondre vite à trois questions : qui l'a fait, qu'est-ce qui a changé et quand.
Commencez large, puis restreignez jusqu'à ce que vous regardiez un événement précis et son diff exact.
Une méthode rapide pour arriver à la vérité
- Trouvez le client avec un identifiant stable (customer ID, account ID, ticket ID) et confirmez que vous regardez le bon enregistrement.
- Filtrez par type d'action (password reset, refund, plan change) et par acteur (admin précis, agent support, job automatisé).
- Ouvrez les détails du changement et lisez le diff, pas seulement le résumé.
- Utilisez l'ID de corrélation/requête pour voir ce qui s'est passé dans le même flux. Les litiges viennent souvent d'effets secondaires, pas du clic initial.
- Écrivez le résultat en termes simples et, si nécessaire, ajoutez un événement de suivi qui enregistre la résolution.
Petit exemple
Un client signale avoir été rétrogradé sans consentement. Le log montre qu'un agent a changé le plan, mais le même ID de corrélation inclut aussi une tentative de paiement échouée quelques secondes plus tôt. Le diff montre qu'une règle de rétrogradation a été déclenchée automatiquement après l'échec. Cela règle généralement le litige et indique quoi corriger : clarifier l'UI, durcir les permissions ou améliorer la règle.
Si vous avez hérité d'une appli générée par IA, c'est souvent l'une des premières choses à ajouter pendant le nettoyage. Des équipes comme FixMyMess voient souvent des actions admin puissantes se produire sans aucune trace, ce qui transforme chaque plainte en devinettes.
Exemple : tracer un changement support de la plainte à la preuve
Un client écrit : « Mon abonnement a été annulé et je ne l'ai pas fait. » C'est là que les journaux admin et support arrêtent la spéculation. Vous voulez une piste propre qui montre qui a touché le compte, ce qui a changé et pourquoi.
Commencez par l'enregistrement client et filtrez les événements autour du moment où il a remarqué le problème. Dans une bonne piste, vous trouvez rapidement une impersonation (ou « login as user ») suivie d'une mise à jour d'abonnement.
Voici à quoi cette piste peut ressembler quand elle fonctionne bien :
2026-01-16 09:41:03Z actor=support:maya action=impersonate_user target=user:1842
context: ticket=SUP-10488 reason="Asked to check billing page error"
2026-01-16 09:43:19Z actor=support:maya action=subscription_update target=sub:7711
source=ui request_id=8f3c... ip=203.0.113.24
diff:
status: active -\u003e canceled
cancel_at_period_end: false -\u003e true
context: ticket=SUP-10488 note="Customer requested cancel at renewal"
Deux éléments règlent vite les litiges : le diff (ce qui a changé) et le contexte (ID de ticket, raison et une courte note). L'horodatage et l'acteur précisent s'il s'agissait d'une action du support ou du client.
Confirmez la source pour ne pas accuser le mauvais système :
- Action UI : il y a un acteur interne plus un ID de session/requête.
- Clé API : l'acteur est une clé ou une intégration, souvent avec un ID de clé.
- Job automatisé : l'acteur est un nom de job, avec un ID d'exécution/planification.
Si le changement est erroné, rétablissez-le immédiatement (par exemple, remettez l'abonnement en actif), puis journalisez l'action corrective comme son propre événement avec une note de raison comme « Reverted cancel, customer did not consent. ». Cette entrée finale empêche que le même argument ne revienne plus tard.
Prochaines étapes : commencer petit, puis durcir la piste
Commencez par un périmètre minimum que vous pouvez livrer le sprint suivant. Choisissez les actions admin et support qui causent le plus souvent des disputes et journalisez-les en priorité. Si vous ne faites qu'une chose, assurez-vous de pouvoir répondre : qui l'a fait, ce qui a changé, quel enregistrement et quand.
Une manière pratique de trouver les lacunes est un court exercice de litige. Prenez un ticket réel passé (ou fabriquez-en un) et essayez de prouver ce qui s'est passé en utilisant uniquement vos logs. Par exemple : « Un client dit que son plan a été rétrogradé sans permission. » Pouvez-vous voir l'utilisateur affecté, l'acteur (admin ou système), les valeurs avant/après et le contexte du ticket ? Si non, notez ce qui manque et ajoutez-le.
Quand les bases fonctionnent, ajoutez des garde‑fous pour que la piste reste sûre et utile : masquez ou omettez les champs sensibles (mots de passe, tokens, données de carte complètes) tout en journalisant le fait du changement, fixez une rétention conforme aux besoins du support et aux obligations légales, restreignez l'accès aux logs (et journalisez l'accès aux logs eux-mêmes), et ajoutez des alertes pour les actions à haut risque comme les changements de rôle, les remboursements et les réinitialisations d'auth.
Si votre base de code a été générée par des outils IA, une journalisation incohérente est courante : les actions arrivent à plusieurs endroits, les vérifications d'auth diffèrent selon la route, et les changements « system » sont difficiles à distinguer des actions humaines. Un audit ciblé peut être la correction la plus rapide.
FixMyMess (fixmymess.ai) propose un audit de code gratuit pour repérer les journaux d'audit manquants, les pistes d'auth brisées et les failles de sécurité, en particulier pour les prototypes générés par IA qui ont besoin d'un comportement prêt pour la production.
Questions Fréquentes
Quel problème les journaux d'audit admin et support résolvent-ils réellement ?
Un journal d'audit transforme un litige en une chronologie vérifiable. Plutôt que de débattre de ce qui “aurait dû” se passer, vous pouvez pointer vers une entrée unique qui montre qui a agi, ce qu'il a fait, quel enregistrement a été touché et quand cela s'est produit.
Quelles actions admin/support dois-je journaliser en priorité ?
Consignez toute action qui modifie de l'argent, l'accès ou la confiance. Commencez par les réinitialisations de mot de passe, les changements d'email, les modifications de rôle/permission, les montées/baisses de plan, les remboursements, les annulations, l'usurpation de compte (impersonation) et les exports de données sensibles.
Quels champs chaque entrée de journal d'audit devrait-elle inclure ?
Une entrée utile répond à cinq questions : acteur, action, enregistrement cible, horodatage et contexte source. Concrètement cela signifie un ID d'acteur stable et son rôle, un nom d'action structuré, le type d'enregistrement et son ID, l'heure en UTC, plus les détails de requête/session et une référence de ticket ou raison support.
Comment nommer les actions pour que les logs restent consultables ?
Utilisez une taxonomie d'actions petite et cohérente comme billing.refund_issued ou user.password_reset. Placez les détails dans des champs structurés (diff, code de raison, ID de ticket) pour que les filtres restent fiables et éviter des dizaines de noms d'action presque identiques.
Dois‑je stocker des diffs (valeurs avant/après) dans les journaux d'audit ?
Enregistrez au niveau champ un avant/après uniquement pour les champs qui ont changé. Les diffs doivent être petits et précis (par exemple plan: basic -\u003e pro) pour prouver ce qui a changé sans vider des enregistrements complets dans les logs.
Comment journaliser des changements sans divulguer des données sensibles ?
Ne stockez pas les valeurs brutes pour les secrets ou les données très sensibles (mots de passe, tokens, détails de paiement complets, notes privées). Préférez la redaction, le masquage, le hachage ou un simple marqueur comme « changed », et conservez l'entrée centrée sur le fait du changement plus qui/quand/où.
Pourquoi les horodatages des journaux d'audit doivent-ils être en UTC ?
UTC évite les confusions liées aux horaires d'été et aux fuseaux, ce qui est fréquent quand les minutes comptent dans un litige. Stockez l'horodatage en UTC et ne le convertissez en heure locale que pour l'affichage.
Comment journaliser l'impersonation (« se connecter comme utilisateur ») ?
L'usurpation doit être explicite et traçable. Journalisez le début et la fin de l'impersonation, et pour chaque action effectuée pendant l'impersonation, enregistrez les deux identités : le membre du staff qui a agi et l'utilisateur/compte concerné.
Comment rendre les journaux d'audit dignes de confiance et difficiles à falsifier ?
Rendez les journaux append-only et traitez-les comme des pièces à conviction. Si quelque chose est incorrect, écrivez un nouvel événement correctif qui référence l'original, restreignez qui peut accéder ou supprimer les logs et journalisez aussi les accès aux logs.
Mon appli a été construite avec des outils IA et la journalisation est un désordre—peut-on réparer cela rapidement ?
Oui, c'est fréquent que des prototypes générés par IA ratent des logs critiques ou journalisent de manière incohérente. Une solution pratique : implémenter la journalisation dans la couche service (là où s'exécutent les règles métier), standardiser la forme des événements et des noms d'actions, et ajouter des diffs sûrs avec redaction ; FixMyMess peut faire un audit rapide pour identifier ce qui manque et corriger vite.