Limites de concurrence pour les workers en arrière-plan qui protègent votre BDD
Les limites de concurrence pour les workers en arrière-plan stabilisent la charge BDD en plafonnant les jobs parallèles et la profondeur de file. Découvrez des règles simples, des contrôles rapides et un exemple pratique.
Pourquoi les workers en arrière-plan peuvent saturer votre BDD
Un « pic BDD » se manifeste souvent comme une réaction en chaîne. Des pages qui étaient rapides commencent à répondre lentement. Les connexions échouent. Vous voyez des timeouts dans votre API et une pile croissante de jobs échoués ou retentés. Même si une seule fonctionnalité utilise le background, elle peut donner l'impression que toute l'application est cassée parce que la base de données est le goulot commun.
Les workers en arrière-plan surchargent les bases de données plus vite que le trafic web parce qu'ils sont conçus pour être persistants et parallèles. Une requête web est limitée par le comportement des utilisateurs et par les timeouts de requête. Les workers, eux, tirent job après job et s'exécutent aussi vite que vos CPU le permettent. Si chaque job effectue quelques requêtes, cela devient des centaines ou milliers de requêtes par minute sans pause naturelle.
Le piège est que cela peut ressembler à des « requêtes lentes » alors que le vrai problème est le parallélisme. Quand trop de jobs frappent la BDD en même temps, la base manque de connexions, commence à mettre le travail en file intérieurement, et tout ralentit ensemble.
Signes qui pointent souvent vers la concurrence comme cause racine :
- Beaucoup de requêtes différentes ralentissent en même temps (et pas un seul endpoint)
- Erreurs de pool de connexions ou messages « too many connections »
- Pic de retries juste après un déploiement ou le démarrage d'une tâche planifiée
- Le CPU de la BDD monte alors que le débit n'augmente plus
L'objectif d'une limite de concurrence n'est pas de rendre les jobs plus lents. C'est de garder un débit régulier plutôt que saccadé : charge BDD stable, moins d'incidents, et latence cohérente pour les vrais utilisateurs.
Exemple : un job nocturne « reconstruire l'index de recherche » lance 20 workers. Chaque worker lit des lignes, met à jour un statut et écrit la progression. Le site est calme la nuit, mais la BDD se sature quand même et le trafic du matin arrive sur un système fatigué et encombré.
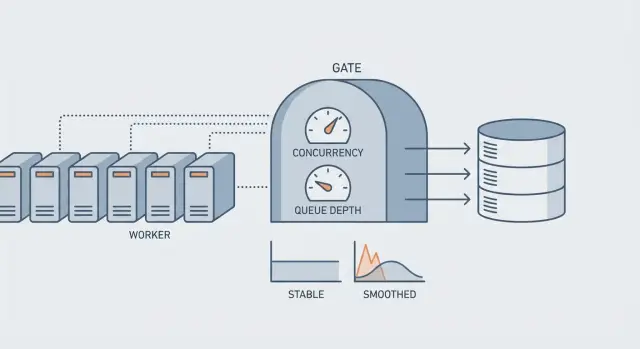
Concurrence, rythme et profondeur de file en termes simples
Quand on dit « il nous faut plus de workers », on parle généralement d'un des trois réglages suivants. Chacun résout un problème différent, et toucher au mauvais peut surcharger votre base.
La concurrence, c'est combien de jobs s'exécutent en même temps. Si la concurrence est à 20, vous pouvez avoir 20 jobs qui frappent la BDD en parallèle.
Le rate, c'est la vitesse de démarrage des jobs dans le temps, par exemple « 5 jobs par seconde », même si vous pourriez en exécuter plus.
La profondeur de file, c'est combien de jobs attendent en file. L'âge du backlog, c'est depuis combien de temps le plus ancien attend.
La profondeur indique le volume. L'âge du backlog indique la douleur. Une file peut être profonde mais correcte si elle s'écoule régulièrement. Une petite file peut devenir critique si les jobs sont bloqués et que le plus ancien attend depuis des heures.
Pourquoi « plus de workers » empire souvent la situation au début : les workers se concurrencent surtout sur quelques ressources. Le goulot caché est généralement la base de données : limites du pool de connexions, verrous de lignes ou de tables, transactions longues. En augmentant la concurrence, vous n'ajoutez pas seulement du travail : vous augmentez la contention. Les requêtes attendent des connexions, les transactions restent ouvertes plus longtemps, les verrous durent plus, et tout ralentit.
Un exemple rapide : 10 workers lancent chacun un job qui maintient une transaction pendant 300 ms. Ça parait court. Mais si ces jobs touchent les mêmes tables, doubler à 20 workers peut doubler les attentes de verrous et pousser le temps des transactions à plusieurs secondes. Vos requêtes web se battent alors avec les workers pour les connexions et toute l'application semble en panne, même si ce n'est qu'une surcharge.
Ce qui casse en premier dans la base de données
Quand les workers font un pic, la première défaillance n'est souvent pas « la base est lente ». C'est « la base ne peut pas accepter plus de travail pour l'instant ». Cela apparaît comme des timeouts, une pile de requêtes en attente et des taux d'erreur qui montent même si le CPU semble correct.
1) Épuisement du pool de connexions
La plupart des applis ont un pool de connexions fixe par processus. Chaque thread ou process worker a besoin d'une connexion pour chaque requête. Si vous démarrez plus de workers que le pool ne peut en servir, ils se mettent en attente pour une connexion. Ces workers en attente consomment toujours de la mémoire et continuent de réessayer, ce qui ajoute de la pression partout.
Un schéma courant : votre appli web a besoin de 20 connexions pour rester saine, mais les workers prennent le reste du pool et le site commence à échouer sur les logins ou le checkout.
2) Verrous dus aux transactions longues
Les verrous sont la prochaine panne fréquente. Même si les requêtes sont rapides, des transactions longues maintiennent des lignes verrouillées. Si beaucoup de jobs touchent les mêmes lignes chaudes ou tables (par ex. mise à jour du même utilisateur, d'un solde, ou d'un champ "last_processed_at"), le travail devient sériel : un job à la fois peut avancer et les autres attendent.
Les attentes de verrous peuvent ressembler à une lenteur aléatoire, mais la racine est trop de parallélisme sur les mêmes données.
3) Schémas de requêtes coûteux dans les jobs
Les jobs font souvent un petit travail en boucle serrée, ce qui crée beaucoup de requêtes. Les coupables habituels : patterns N+1, mises à jour par élément au lieu de mises à jour en lot, recomputation répétée des mêmes agrégats, index manquants sur les filtres des jobs, et récupération de bien plus de données que nécessaire.
4) Appels externes à l'intérieur d'une transaction
Si un job ouvre une transaction puis appelle une API externe (email, paiements, AI, stockage) avant de commit, la connexion BDD et les verrous sont gardés pendant que le worker attend le réseau. Multipliez ça par des workers parallèles et vous obtenez une saturation rapide des connexions.
Les limites de concurrence aident, mais elles fonctionnent mieux avec des transactions courtes et des coûts de requête prévisibles.
Comment choisir des limites sensées (sans deviner)
Une bonne limite n'est pas un chiffre intuitif : c'est un nombre que votre BDD peut supporter lors d'un mauvais jour, quand le trafic est élevé et les caches manquent. Le but est simple : garder la BDD dans des plages sûres de connexions et de temps de requête tout en faisant des progrès réguliers.
Commencez avec une base conservatrice liée à la base de données, pas au serveur d'app. Regardez votre pool de connexions BDD (ou le max de connexions) et gardez une marge pour le trafic web, les tâches d'admin et les migrations. Ensuite tenez compte de la durée pendant laquelle un job typique garde une connexion.
Une base pratique :
- Réservez 50–70 % des connexions BDD pour le trafic en ligne et le travail inconnu.
- Utilisez les 30–50 % restants comme budget total pour tous les workers combinés.
- Commencez avec une faible parallélisation (souvent 1–3 workers par file) et augmentez seulement si la latence BDD reste stable.
- Re-vérifiez après ajout de fonctionnalités. Des limites qui fonctionnaient le mois dernier peuvent échouer après un changement de requête ou un index manquant.
Ne mettez pas un seul chiffre global pour tous les jobs. Séparez les limites par file selon l'impact métier. Une file critique (réinitialisation de mot de passe, onboarding) doit rester réactive même si une file de masse (backfills, imports) est grande.
Certains types de jobs sont connus pour embêter la BDD : exports, runs de facturation, gros imports, tout ce qui scanne de larges tables. Mettez des plafonds par job sur ces opérations même si le pool global de workers est plus grand. Par exemple, vous pouvez autoriser 10 workers au total mais seulement 1 export à la fois.
Décidez aussi quoi faire quand la file grandit. Si vous l'ignorez, vous aurez souvent des pics surprises plus tard quand les workers rattrapent le retard.
- Backpressure : ralentir les producteurs (réduire la fréquence, ajouter des délais, limiter les enqueues par minute).
- Shedding : abandonner ou coaliser le travail à faible valeur (fusionner les doublons, ne garder que le plus récent).
- Différer : déplacer les tâches lourdes vers les heures creuses avec des plafonds stricts.
- Diviser : fragmenter un job géant en morceaux plus petits avec une limite par morceau.
Étape par étape : définir concurrence et profondeur de file
Commencez par nommer vos types de jobs. Notez ce qui déclenche chaque job, à quelle fréquence il tourne, et s'il lit ou écrit beaucoup de lignes. Marquez les jobs lourds côté BDD (imports, backfills analytiques, "synchroniser tout", envois d'email qui mettent à jour l'état utilisateur). Ce sont les premiers à contrôler.
Ensuite, fixez un plafond du nombre de jobs pouvant s'exécuter en même temps, puis répartissez ce plafond entre les files. Une configuration commune est une file par défaut pour le travail normal et une file lourde pour les jobs intensifs BDD. Cela empêche un type de job bruyant de voler toutes les connexions.
Un setup pratique de départ :
- Plafond global : garder les jobs concurrents totaux en dessous de votre budget sûr de connexions BDD.
- Plafond par file : donner aux jobs lourds une plus petite part que les jobs rapides.
- Plafond par job (si supporté) : seulement 1–2 instances du même job coûteux à la fois.
- Priorité : garder le travail orienté utilisateur avant les maintenances.
- Fenêtres temporelles : exécuter les files lourdes pendant les heures creuses.
Puis limitez la profondeur de file. Décidez du comportement quand la file est pleine : mettre en pause les nouveaux enqueues, les retarder (avec une exécution programmée), ou rejeter avec une erreur claire. Si votre file lourde atteint 1 000 jobs, vous pouvez arrêter d'accepter de nouveaux imports de masse et demander aux utilisateurs de réessayer plus tard.
Les retries peuvent aussi créer des pics. Ajoutez du jitter (petits délais aléatoires) pour éviter que les échecs ne retentent en même temps, et utilisez un backoff qui grandit rapidement pour les erreurs BDD comme les timeouts.
Déployez les changements progressivement. Baissez d'abord la concurrence, observez la BDD, puis augmentez les limites par petits paliers. Si le temps de requête monte ou si les connexions restent bloquées au max, reculez avant que les utilisateurs ne le remarquent.
Monitoring qui vous dit si les limites fonctionnent
Les limites fonctionnent quand votre base de données reste stable même si le volume de jobs varie. Vous devriez voir des pointes contrôlées, pas des chutes soudaines où tout ralentit d'un coup.
Signaux BDD importants
Surveillez un petit ensemble de métriques ensemble :
- Connexions actives (et temps d'attente du pool)
- Nombre de requêtes lentes et p95 des temps de requête
- Attentes de verrous et deadlocks
- Utilisation CPU et pression mémoire
- IOPS disque et latence lecture/écriture
Si les connexions sont saturées alors que le CPU est bas, vous avez probablement trop de requêtes concurrentes qui attendent des verrous ou de l'I/O. Si le CPU est saturé et que les requêtes lentes augmentent, la BDD fait trop de travail par requête.
Signaux côté workers qui montrent si le throttling aide
Suivez le nombre de jobs en cours, en file, la durée des jobs (p50 et p95), le taux de retries, et les dead letters. Un système sain voit sa file monter et descendre mais l'âge du backlog reste à peu près stable.
Alertes actionnables :
- L'âge du backlog augmente pendant 10–15 minutes
- Le taux de retries augmente en parallèle des timeouts BDD
- Les connexions BDD restent proches du max pendant plusieurs minutes
- La durée des jobs dérive à la hausse (surtout le p95)
Comment décider quoi changer : si réduire la concurrence calme les métriques BDD et améliore la durée des jobs, il fallait resserrer les limites. Si baisser la concurrence n'aide pas beaucoup mais que les requêtes lentes et les attentes restent élevées, il faut optimiser les requêtes ou les index, pas seulement throttler.
Exemple : si un job d'email nocturne provoque des retries et des attentes de verrous, la limite peut être correcte mais la requête qui sélectionne les destinataires peut nécessiter une taille de lot plus petite ou un index.
Erreurs courantes qui provoquent malgré tout des pics
Beaucoup d'équipes ajoutent des limites et subissent encore des pics. Généralement la limite a été fixée en fonction de la capacité des workers, pas de ce que la BDD peut supporter. Régler la concurrence sur le nombre de coeurs CPU peut sembler sensé, mais cela ignore la taille du pool de connexions, la contention des verrous et les requêtes lentes. Une base peut tomber bien avant que l'hôte worker soit « occupé ».
Le comportement de retry est un autre générateur silencieux de pics. Des retries illimités, ou des retries qui s'exécutent tous au même moment (par ex. « retry dans 30s » pour chaque échec), peuvent créer une tempête de retries. Une brève panne devient une seconde panne quand des milliers de jobs se réveillent en même temps et martèlent les mêmes tables.
La conception des files peut amplifier le problème. Si vous utilisez une seule file pour tout, le travail en masse peut étouffer le travail critique. Un backfill énorme retarde des jobs visibles par l'utilisateur, puis quelqu'un augmente la concurrence pour rattraper le retard, ce qui frappe encore plus la BDD.
Pendant les incidents, une erreur fréquente est d'augmenter les limites pour « vider le backlog ». Cela transforme souvent une file gérable en saturation de connexions BDD. Vous pouvez vider la file plus vite, mais vous augmentez aussi les timeouts, les attentes de verrous et les deadlocks, si bien que le backlog revient.
Garde-fous pour éviter les pannes habituelles :
- Basez la concurrence sur les connexions BDD et le coût des requêtes, pas sur les coeurs CPU.
- Ajoutez du jitter et un backoff exponentiel aux retries, avec un maximum strict.
- Séparez les files pour le travail critique et pour le travail en masse.
- Considérez l'augmentation des limites comme un dernier recours, et faites-le par petites étapes.
- Définissez une politique claire de délai, d'abandon ou de rejet quand la file est pleine.
Checklist rapide avant de passer en production
Avant de lancer des workers en production, supposez le pire : un déploiement, un redémarrage ou une récupération d'incident où tous les workers se réveillent en même temps. Votre base ne se soucie pas que les jobs soient « en arrière-plan » — elle voit juste une vague soudaine de connexions et de requêtes.
Checklist :
- Peak connections math est documenté. Additionnez web servers + process workers x threads + scripts d'admin. Comparez au plafond de connexions BDD (et gardez une marge).
- Les jobs lourds sont séparés et plafonnés. Mettez les jobs les plus coûteux (imports, backfills, gros envois d'email, syncs) dans leur propre file avec une concurrence plus basse.
- La profondeur de file a un plafond strict et l'âge du backlog est surveillé. Une longueur max de file empêche l'accumulation infinie et une alerte sur l'âge du job le plus vieux détecte tôt les ralentissements.
- Les retries ne créent pas de tempête. Étalez les retries, arrêtez après une fenêtre raisonnable, et évitez les retries immédiats sur des erreurs BDD liées à la charge.
- Vous avez un bouton d'urgence. Sachez comment couper la concurrence rapidement (et comment mettre en pause seulement la file lourde) sans redeployer.
Un exemple pratique : si un job de rapport nocturne touche beaucoup de lignes, donnez-lui sa propre file avec une concurrence 1–2, limitez la profondeur de cette file, et alertez si le job le plus ancien a plus de 15 minutes.
Exemple : empêcher un job nocturne de planter votre appli
Imaginez une appli SaaS où les utilisateurs restent actifs tard, puis un import nocturne démarre à 1 h. L'import lit un gros CSV, enrichit chaque ligne et écrit des mises à jour dans les mêmes tables que l'app utilise pour les connexions, les tableaux de bord et la facturation.
Sans limites, le système de workers essaiera de finir plus vite en lançant autant de jobs qu'il peut. En quelques minutes, les connexions BDD atteignent le plafond. Des requêtes à 50 ms deviennent des secondes. Les requêtes web time out. Puis les retries commencent, et vous avez une seconde vague de travail re-queue qui se bat pour la même base.
Un plan simple change l'histoire :
- Placez les jobs d'import sur leur propre file, séparée des jobs critiques (emails, webhooks, paiements).
- Limitez la concurrence d'import à un petit nombre selon la capacité BDD (par ex. 3–5 workers).
- Ajoutez une limite de profondeur de file pour arrêter les nouvelles enqueues quand le backlog est déjà trop grand.
- Ajoutez une limitation de débit autour des opérations BDD les plus lourdes (comme les upserts) pour lisser les pics.
L'import prend maintenant plus de temps, mais reste prévisible. Les requêtes utilisateur gardent une part stable des connexions. Si l'import génère plus de travail que le système ne peut gérer, il attend dans la file au lieu de provoquer un embouteillage.
Le compromis est simple : un job batch un peu plus lent en échange d'une appli stable. La plupart des équipes préfèrent un import qui finit plus tard plutôt que des tickets support et des rollbacks d'urgence.
Quand les limites ne suffisent pas (et quoi changer ensuite)
Les limites sont un rail de sécurité, pas une cure miracle. Si vous atteignez les limites chaque jour et que la file ne rattrape jamais, le problème est généralement le job lui-même, pas le nombre de workers.
Scalez les workers quand le job est déjà efficace et que vous avez juste plus de volume. Corrigez la logique du job quand chaque job est plus lourd qu'il ne devrait l'être (trop de requêtes, travail répété, ou verrouillage de lignes trop long).
Réduire la charge BDD avant d'ajouter des workers
La plupart des incidents viennent de jobs qui font beaucoup de petits allers-retours vers la base en parallèle. Les changements qui paient souvent :
- Travail par lots : update/insert en chunks plutôt que ligne par ligne.
- Rendre les jobs idempotents : sûrs à retry sans effets secondaires en double.
- Réduire les allers-retours : récupérer ce dont vous avez besoin une fois, puis opérer en mémoire.
- Ajouter les index adaptés : les scans lents se multiplient rapidement sous parallélisme.
- Raccourcir les transactions : faire moins de travail en maintenant les verrous.
Exemple : un job nocturne « recalculer les stats » qui charge 10 000 utilisateurs et exécute 10 requêtes par utilisateur fera fondre votre BDD même avec une faible concurrence. Le retravailler pour fonctionner par lots (ou avec une requête agrégée) peut transformer une tempête de requêtes en quelques requêtes prévisibles.
Séparation lecture/écriture : utile, mais pas magique
Envoyer le travail en lecture vers des replicas peut aider si le job est vraiment en lecture et si les replicas tiennent la charge. Cela n'aide pas quand la douleur vient des écritures, des verrous de lignes, ou d'une table chaude que tous les jobs touchent. Surveillez aussi le lag des replicas : lire sur une réplica et écrire sur le primaire peut conduire à des décisions faites sur des données obsolètes.
Si vous comptez sur le throttling indéfiniment, fixez un objectif concret (par ex. diviser par deux le nombre de requêtes par job ou garder le runtime des jobs sous 30 s) et réévaluez vos limites après avoir optimisé la charge.
Étapes suivantes pour des codebases générées par l'IA
Les apps générées par l'IA sortent souvent avec des valeurs par défaut dangereuses car l'objectif est souvent « faire fonctionner » plutôt que « survivre en production ». C'est ainsi qu'on retrouve des files non bornées, des workers qui créent autant de tâches que la machine permet, et aucun backpressure quand la BDD commence à ralentir.
Un pattern courant : un job background lit 50 000 lignes puis fait un write par enregistrement sans batching. Même si chaque write est rapide, la charge combinée peut saturer les connexions, créer des piles de verrous, et transformer des requêtes normales en timeouts. Dans ce cas, fixer des limites sensées aide, mais ce n'est qu'une partie de la solution.
Si vous avez hérité d'un prototype généré par des outils comme Lovable, Bolt, v0, Cursor ou Replit et qu'il montre déjà des comportements de pic, FixMyMess (fixmymess.ai) peut commencer par un audit de code gratuit pour repérer précisément la source de la pression BDD et recommander des réglages sûrs pour workers et files avant la mise en production.
Questions Fréquentes
Why do background workers overload the database faster than normal web traffic?
Les workers en arrière-plan peuvent s'exécuter en continu et en parallèle, donc ils exercent une pression constante sur la base de données sans pause naturelle. Si chaque job effectue même quelques requêtes, une haute concurrence entraîne rapidement des attentes sur le pool de connexions, de la contention sur les verrous et des timeouts qui impactent toute l'application.
How can I tell if the problem is concurrency rather than one slow query?
Si plusieurs requêtes non liées ralentissent en même temps, c'est généralement un signe de contention et non d'une seule requête lente. Les erreurs de pool de connexions, l'augmentation des retries juste après une tâche programmée et une hausse du CPU sans amélioration du débit sont aussi de bons indicateurs d'un parallélisme excessif.
What’s the difference between concurrency, rate limiting, and queue depth?
La concurrence, c'est le nombre de jobs qui s'exécutent simultanément. Le rate limiting, c'est la vitesse à laquelle vous lancez des jobs dans le temps. La profondeur de file (queue depth) est le nombre de jobs en attente, tandis que l'âge du backlog indique depuis combien de temps le plus ancien attend. Monter la concurrence quand la BDD est le goulot d'étranglement empire souvent la situation.
What usually breaks first in the database during a worker spike?
L'épuisement du pool de connexions est souvent la première panne : les workers et les requêtes web se disputent un nombre limité de connexions. Ensuite, des transactions longues et des verrous peuvent rendre le travail essentiellement séquentiel, donc ajouter des workers ne fait qu'augmenter les attentes.
Why is it dangerous to call external APIs inside a DB transaction?
Gardez les transactions courtes et évitez les appels réseau pendant qu'une transaction est ouverte. Sinon, la connexion et les verrous restent bloqués pendant que le worker attend la réponse externe ; multipliés par des workers parallèles, quelques millisecondes de latence peuvent saturer rapidement les connexions.
How do I choose a safe worker concurrency limit without guessing?
Commencez par budgéter les connexions BDD : réservez la majorité pour le trafic web et les tâches inconnues, puis allouez le reste à l'ensemble des workers. Démarrez avec une faible concurrence par file (souvent 1–3) et n'augmentez que si la latence et les attentes de verrous restent stables.
Should I use one queue for everything or separate queues?
Séparez les jobs par file selon leur impact et leur coût BDD afin que le travail en masse ne prive pas les tâches critiques pour l'utilisateur. Donnez aux files lourdes une concurrence plus faible et, si possible, imposez des limites par job pour les opérations connues comme "mangeuses" de BDD (exports, backfills, grosses importations).
How should I cap queue depth, and what should happen when it’s full?
Fixez un plafond strict et définissez le comportement quand il est atteint : différer, mettre en pause les producteurs, ou rejeter les nouvelles tâches lourdes avec un message clair. Une limite de profondeur empêche l'accumulation infinie et vous force à traiter la surcharge volontairement au lieu de laisser la BDD craquer.
How do I prevent retries from creating a second spike?
Utilisez du jitter et un backoff exponentiel avec une fenêtre de retry maximale, surtout pour les timeouts BDD. Sans jitter, de nombreux jobs retenteront au même instant et créeront une "tempête de retries" qui transforme une courte défaillance en une seconde panne.
What metrics tell me if my limits are working, and what do I change next?
Surveillez les connexions BDD et le temps d'attente du pool, le p95 des temps de requête, les attentes de verrous/déverrous, et l'âge du backlog avec les taux de retry. Si réduire la concurrence stabilise rapidement ces métriques et améliore la durée des jobs, vos limites étaient trop hautes ; sinon, c'est probablement la logique ou les index des jobs à corriger.