Migrer SQLite vers Postgres : playbook pour un cutover phasé
Playbook pratique pour migrer SQLite vers Postgres dans des apps générées par l'IA : traduction de schéma, types, indexation, cutovers phasés et contrôles.
Pourquoi cette migration est risquée dans les apps générées par l'IA
Les prototypes générés par l'IA « fonctionnent » souvent parce que SQLite est indulgent. Il accepte des valeurs bizarres, tolère des types lâches et permet d'avancer avec un minimum de configuration. Beaucoup d'outils IA choisissent aussi SQLite par défaut parce qu'il ne demande aucune configuration et est facile à déployer. Le problème, c'est que ces raccourcis initiaux deviennent des hypothèses cachées dans votre code.
Quand vous migrez SQLite vers Postgres, les premières cassures paraissent petites mais se propagent vite. Une requête qui passait sous SQLite peut échouer sur Postgres à cause d'un typage plus strict, d'un comportement différent des dates et des booléens, ou de comparaisons sensibles à la casse. Les migrations échouent aussi parce que SQLite vous permettait d'ajouter des colonnes ou de modifier des tables d'une manière qui ne se traduit pas proprement en Postgres.
Ce qui casse en général en premier :
- Authentification et sessions (gestion des timestamps, contraintes d'unicité, sensibilité à la casse)
- Requêtes qui « marchaient en local » (casts implicites, comportement lâche de GROUP BY)
- Jobs en arrière-plan et imports (données sales tolérées par SQLite)
- Performance (index manquants qui n'étaient pas évidents avec SQLite)
- Scripts de déploiement (hypothèses sur une DB fichier vs une DB serveur)
La migration vaut le coup quand vous avez besoin de concurrence, de sauvegardes robustes, d'un meilleur planificateur de requêtes, d'un contrôle d'accès plus sûr ou que vous dépassez une config mono-nœud. Elle ne vaut pas le coup si l'app est encore jetée chaque semaine, si vos exigences ne sont pas stables, ou si votre goulot d'étranglement principal est l'adéquation produit-marché et non la base de données.
« Pas de surprises downtime » ne signifie pas zéro risque. Cela signifie que vous planifiez les modes d'échec communs, que vous pouvez mesurer l'avancement et que vous avez un chemin propre de rollback. En pratique, l'objectif est soit aucune interruption visible par l'utilisateur, soit une courte fenêtre planifiée avec un plan de secours clair.
Ce playbook suit un arc simple : inventorier ce que vous avez réellement, traduire le schéma avec soin, convertir les données en sécurité, planifier les indexes et la performance, exécuter un cutover phasé avec synchronisation, corriger les changements d'app souvent oubliés, puis tester et répéter le rollback. Si votre app a été générée par des outils comme Lovable, Bolt, v0, Cursor ou Replit, des équipes comme FixMyMess commencent souvent par un diagnostic rapide du code pour révéler les hypothèses spécifiques à SQLite avant de toucher les données de production.
Que vérifier avant de toucher la base de données
Avant de migrer SQLite vers Postgres, clarifiez ce que vous avez réellement. Les apps construites par l'IA « fonctionnent » souvent en démonstration, mais cachent des surprises comme la coercition silencieuse de types, du SQL ad hoc et des jobs en arrière-plan qui continuent d'écrire pendant que vous tentez de déplacer les données.
Commencez par une cartographie table-par-table. Vous voulez les noms, le nombre de lignes et quelles tables croissent vite. Les plus grosses tables dictent souvent votre plan de cutover car elles prennent le plus de temps à copier et sont les plus douloureuses à réindexer.
Si possible, capturez un instantané rapide de taille et de croissance :
-- SQLite: approximate quick checks
SELECT name FROM sqlite_master WHERE type='table';
SELECT COUNT(*) FROM your_big_table;
Ensuite, comprenez le trafic. Une migration de base de données est rarement bloquée par les lectures. Elle est bloquée par des écritures que vous avez oubliées : webhooks, queues, tâches planifiées et « scripts d'aide » que quelqu'un lance manuellement.
Voici une checklist d'inventaire simple qui évite la plupart des surprises de downtime :
- Tables : nombre de lignes, plus grandes tables et toute table « chaude » avec des mises à jour fréquentes
- Flux de données : quels endpoints écrivent, lesquels lisent seulement, et quels jobs s'exécutent selon un planning
- Style de requête : où vous utilisez un ORM vs du SQL brut dans le code
- Bizarreries SQLite : endroits qui comptent sur un typage lâche, des booléens implicites ou un traitement étrange des dates
- Config : où sont stockées et injectées les chaînes de connexion, clés API et secrets de BD
Le SQL brut est le piège classique. Un ORM peut adapter des requêtes pour Postgres, mais un extrait SQL copié depuis un outil de chat peut utiliser une syntaxe propre à SQLite ou supposer un tri NULL particulier.
Exemple concret : un prototype généré dans Replit peut stocker des booléens comme « true »/« false » en texte dans une table, 0/1 entiers dans une autre, et compter sur SQLite pour accepter les deux. Postgres vous obligera à choisir, et ce choix affecte les requêtes, les indexes et la logique applicative.
Si vous avez hérité d'une app générée par l'IA et en désordre, un diagnostic rapide du code (le type que FixMyMess réalise avant les changements) peut découvrir ces writers cachés et ces hypothèses spécifiques à SQLite avant qu'ils ne provoquent un échec de cutover.
Traduction du schéma sans surprises ultérieures
Quand vous migrez SQLite vers Postgres, le plus grand risque n'est pas la copie des données. C'est de découvrir que votre app dépendait de comportements SQLite que vous n'avez jamais décrits.
SQLite accepte souvent un schéma vague : clés étrangères manquantes, types de colonnes lâches et règles implicites dans le code applicatif. Les apps générées par l'IA aggravent cela car le schéma a pu être généré rapidement puis bricolé.
Rendre le schéma explicite (tables, clés, relations)
Commencez par écrire une carte claire de chaque table et comment les lignes se lient entre elles. Ne vous fiez pas à ce que vous pensez que l'app fait — confirmez-le avec le schéma réel et des données réelles.
Une manière pratique de traduire est de travailler dans cet ordre :
- Définir la clé primaire de chaque table et si elle doit jamais changer.
- Décider comment chaque relation fonctionne (1:1, 1:many) et ajouter des foreign keys volontairement.
- Ajouter les contraintes sur lesquelles vous comptiez implicitement (NOT NULL, UNIQUE, CHECK).
- Gérer les relations circulaires en créant d'abord les tables, puis en ajoutant les foreign keys après.
- Garder des noms cohérents (colonnes comme userId vs user_id causent des bugs silencieux plus tard).
IDs autoincrement : choisissez la version Postgres maintenant
Dans SQLite, INTEGER PRIMARY KEY est un cas spécial qui auto-incrémente. Dans Postgres, vous devriez choisir GENERATED BY DEFAULT AS IDENTITY (ou ALWAYS) plutôt que l'ancien SERIAL, et le documenter.
Exemple : un prototype IA peut insérer des utilisateurs sans id explicite et supposer qu'il n'y a pas de collision d'ids. Si vous réinsérez des données et oubliez de remettre la séquence à jour, la prochaine insertion peut échouer ou, pire, réutiliser des ids.
Enfin, faites en sorte que votre script de migration soit ré-exécutable. Postgres est plus strict, donc visez des scripts idempotents : créer les objets seulement s'ils manquent, et ajouter les contraintes de façon contrôlée pour qu'une exécution partielle puisse reprendre sans deviner l'état.
Incompatibilités de types et conversions sûres
Quand vous migrez SQLite vers Postgres, la plupart des bugs inquiétants proviennent des différences silencieuses de types. SQLite stockera volontiers "true" dans une colonne que vous pensiez entière. Postgres ne le fera pas, et c'est une bonne chose, mais cela signifie que vous devez effectuer des conversions explicites.
Les incompatibilités qui causent de vraies pannes
Quelques motifs reviennent fréquemment dans les apps générées par l'IA :
- Booléens : les apps SQLite utilisent souvent 0/1, "true"/"false" ou même la chaîne vide. Dans Postgres, utilisez
booleanet convertissez avec des règles claires (par exemple : seuls 1 et "true" deviennent true). - Entiers stockés en texte : IDs et compteurs peuvent être sauvés comme chaînes. Convertissez seulement si chaque valeur est propre, sinon gardez le texte et ajoutez une nouvelle colonne entière que vous backfillez en sécurité.
- Nulls et valeurs par défaut : SQLite peut être lâche avec les valeurs manquantes. Postgres appliquera
NOT NULLet les defaults. Si d'anciennes lignes contiennent des nulls, ajoutez la contrainte seulement après backfill.
Les dates/horodatages sont un autre piège. Les projets SQLite stockent souvent des dates comme des chaînes en heure locale, des formats mixtes ou des secondes epoch. Choisissez d'abord un standard : timestamptz en UTC est généralement le plus sûr. Convertissez ensuite d'un format connu à la fois et loggez les lignes qui ne parsistent pas. Si votre app affiche « hier » pour des utilisateurs dans différents fuseaux, c'est souvent un signe de mélange entre heure locale et UTC.
Les champs JSON nécessitent un choix délibéré. Si vous interrogez l'intérieur du JSON (filtrer par une clé, indexer), stockez en jsonb. Si vous ne stockez que des blobs et les récupérez, text peut suffire, mais vous perdez la validation et la puissance de requête.
Argent et décimales ne doivent pas utiliser des floats. Si un checkout généré par l'IA totalise $19.989999, corrigez en utilisant numeric(12,2) (ou l'échelle nécessaire) et arrondissez pendant la conversion.
Une approche pratique est d'exécuter une conversion à blanc sur une copie des données de production, compter les échecs par colonne, et n'adopter les types et contraintes finaux qu'après cette étape.
Indexation et changements de performance à prévoir
Quand vous migrez SQLite vers Postgres, l'app a souvent l'air de « fonctionner » mais ralentit. Une grosse raison est que SQLite et Postgres font des choix différents sur l'utilisation des indexes.
SQLite peut s'en sortir avec moins d'indexes parce qu'il s'exécute en processus, avec un planificateur simple et des charges plus petites. Postgres est conçu pour la concurrence et de plus grandes données, mais il est strict sur les statistiques, la sélectivité des indexes et la forme des requêtes. Si une app générée par l'IA est partie avec des scans table-entiers accidentels, Postgres les exécutera fidèlement, simplement à un coût plus visible.
Commencez par choisir les indexes à partir de requêtes réelles, pas d'hypothèses. Récupérez les requêtes les plus utilisées en lecture et écriture (login, listes, recherche, comptes tableau de bord) et concevez autour d'elles. Exemple rapide : si votre app exécute souvent WHERE org_id = ? AND created_at >= ? ORDER BY created_at DESC LIMIT 50, un index composite sur (org_id, created_at DESC) est généralement plus utile que deux indexes mono-colonnes.
Indexes composites et unicité
L'ordre compte dans les indexes composites Postgres. Mettez d'abord le filtre le plus sélectif (souvent org_id ou user_id), puis la colonne utilisée pour le tri ou les scans de plage. Ajoutez la direction de tri quand elle correspond à la requête.
Séparez aussi l'idée de « doit être unique » de « aide la performance ». Une contrainte UNIQUE impose une règle métier et crée un index unique de backing. Un index unique autonome peut être utile pour des cas partiels, mais si c'est vraiment une règle métier, modélisez-la comme contrainte pour que ce soit clair.
Que contrôler quand les requêtes ralentissent
Après la migration, focalisez-vous sur :
- Index composites manquants pour des patterns filtre+tri courants
- Mauvais types causant des casts (ce qui peut empêcher l'utilisation d'un index)
- Statistiques obsolètes (exécutez ANALYZE après les chargements massifs)
- Scans séquentiels sur de grandes tables là où vous attendiez des index scans
- Surcharge d'écriture due à trop d'indexes sur des tables chaudes
Si vous avez hérité d'un schéma IA avec « indexer tout » ou « n'indexer rien », un audit court (comme le fait FixMyMess) rapporte vite.
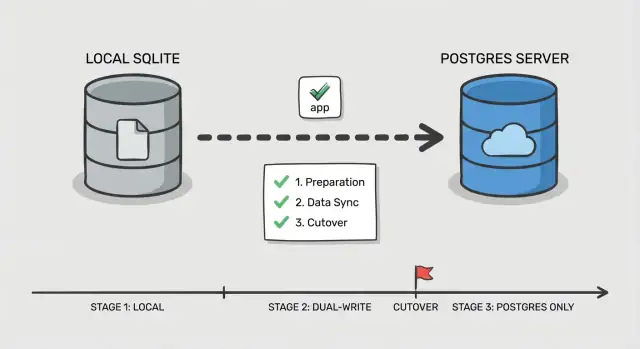
Plan de cutover par étapes
Un cutover sûr, ce n'est pas un grand basculement, c'est vérifier chaque pièce pendant que les utilisateurs continuent d'utiliser l'app. Cela compte encore plus quand vous migrez SQLite vers Postgres dans une app générée par l'IA, où des requêtes cachées et des cas limites sont fréquents.
Phase 0 : Décidez comment vous allez basculer
Choisissez un ordre simple : switcher les lectures d'abord, puis les écritures. Les lectures sont plus faciles à valider et à revenir en arrière. Les écritures changent la source de vérité, traitez-les comme l'étape finale.
Ajoutez un point de contrôle dans l'app : un feature flag ou un toggle de configuration qui sélectionne quelle base gère les lectures et quelle base gère les écritures. Gardez-le simple et explicite pour pouvoir le retourner rapidement en cas d'incident.
Phase 1-5 : Exécuter le cutover en petites étapes
Avant de toucher le trafic, mettez en place Postgres (base, users, rôles et accès au moindre privilège). Assurez-vous que votre app peut s'y connecter dans le même environnement qu'aujourd'hui.
Suivez ensuite ce flux en phases :
- Copie bulk : snapshot de SQLite et chargement dans Postgres.
- Sync incrémentale : garder Postgres à jour avec les changements pendant que l'app écrit toujours sur SQLite.
- Cutover lecture : diriger les lectures vers Postgres, garder les écritures sur SQLite, et surveiller les erreurs et les requêtes lentes.
- Cutover écriture : diriger les écritures vers Postgres, garder une courte fenêtre où vous pouvez revenir en arrière.
- Finaliser : arrêter la sync, verrouiller les anciens identifiants et conserver SQLite en lecture seule pour une période définie.
Définissez le rollback avant de switcher quoi que ce soit : quel toggle être renvoyé, quelles données vous pourrez perdre et comment vous gérerez cela. Par exemple, si votre app IA écrit des sessions utilisateur et des resets de mot de passe, décidez si ces tables nécessitent un traitement spécial pour qu'un rollback ne casse pas les connexions.
Si vous avez besoin d'un second avis, FixMyMess aide souvent les équipes à répéter ce plan sur des codebases IA en désordre avant le vrai cutover.
Garder les données synchronisées pendant la transition
Quand vous migrez SQLite vers Postgres avec un cutover phasé, la vraie difficulté n'est pas la copie initiale. C'est de maintenir la cohérence pendant que des utilisateurs réels interagissent.
Deux patterns simples de sync (et quand les utiliser)
Si l'app a peu de trafic et que les changements sont faciles à rejouer, des jobs de backfill périodiques peuvent suffire : prenez une copie initiale, puis lancez un job planifié qui copie les lignes modifiées depuis la dernière exécution (en vous basant sur updated_at ou une table append-only d'événements). C'est simple, mais augmente le risque de divergences juste avant le cutover.
Si l'app est active, le dual-write est plus sûr : chaque écriture va dans les deux bases pendant une période. C'est plus de travail, mais réduit l'écart et rend le cutover moins stressant.
Garder les IDs cohérents
Décidez tôt quel système possède les clés primaires. La règle la plus simple : conservez les mêmes IDs dans Postgres et ne les renumérotez jamais. Si SQLite utilisait des IDs entiers, réglez les séquences Postgres pour démarrer au-dessus du max actuel afin d'éviter les collisions. Si vous passez aux UUID, ajoutez d'abord une colonne UUID, backfillez-la et conservez l'ancien ID en référence externe stable jusqu'à la migration complète.
Pour éviter la confusion, définissez des règles de conflit dès le départ :
- Choisir une source de vérité pour les écritures (souvent Postgres une fois le dual-write activé)
- En cas de divergence, préférer « latest updated_at wins » seulement si les horloges sont fiables
- Pour les montants d'argent, permissions et auth, préférer des règles explicites plutôt que des timestamps
- Enregistrer chaque conflit pour revue
Faites tourner les deux systèmes en parallèle assez longtemps pour couvrir l'usage normal (quelques jours, parfois un cycle business complet). Loggez suffisamment pour repérer la dérive vite : comptes par table, échantillons de checksum pour les tables chaudes, échecs d'écriture par endpoint et une petite piste d'audit des IDs modifiés. C'est souvent là que les équipes demandent à FixMyMess de vérifier le dual-write et détecter la dérive avant les clients.
Changements côté app souvent oubliés
Le swap de base de données n'est que la moitié du travail. Beaucoup d'équipes migrent les données, pointent l'app vers Postgres, puis passent la journée suivante à courir après des erreurs étranges qui n'apparaissaient pas sous SQLite.
Paramètres de connexion et pool
SQLite signifie généralement « un fichier, faible concurrence ». Postgres est un serveur, et il acceptera volontiers trop de connexions jusqu'au jour où il ne le pourra plus.
Si votre app utilise un pool, définissez une limite et des timeouts réalistes. Un échec courant après migration est que les jobs d'arrière-plan et l'app web ouvrent chacun leur propre pool, multipliant les connexions et provoquant des ralentissements qui ressemblent à « Postgres est lent » alors que le vrai problème est « trop de connexions ».
Requêtes qui dépendaient de l'indulgence de SQLite
SQLite renvoie souvent un résultat même quand le SQL est un peu mal fichu. Postgres est plus strict, et cette rigueur est habituellement une bonne chose.
Surveillez les comparaisons entre types (texte vs nombres), les casts implicites et l'utilisation lâche de GROUP BY. Vérifiez aussi le comportement des correspondances de chaînes et la casse, car une recherche qui « marchait » sous SQLite peut changer si vous comptiez sur une insensibilité à la casse accidentelle.
Les transactions et les hypothèses de verrouillage peuvent aussi changer. Du code qui allait bien avec « write whenever » peut maintenant rencontrer des deadlocks ou de la contention si de grosses lectures et écritures sont enveloppées dans une longue transaction.
L'authentification et le stockage des sessions sont un autre piège discret. Si vos sessions de connexion, tokens de reset ou refresh tokens vivent en base, de petites différences (timestamps, contraintes uniques, jobs de nettoyage) peuvent provoquer des déconnexions massives ou des flux de login cassés.
Voici une liste rapide de vérifications côté app qui attrapent la plupart des surprises :
- Confirmer que chaque processus de l'app (web, workers, cron) lit la même config DB et les mêmes limites de pool.
- Remplacer le SQL spécifique à SQLite (upserts, fonctions date, gestion des booléens).
- Auditer tout SQL brut pour le style des quotes et des paramètres.
- Revoir les bornes de transaction et s'assurer que les jobs longs ne gardent pas de verrous plus que nécessaire.
- Vérifier les tables de sessions et tokens, la logique d'expiration et le comportement des contraintes uniques.
Exemple : un prototype IA peut stocker les sessions dans une table avec une colonne createdAt en texte et la comparer à « now » sous forme de chaîne. Ça peut sembler fonctionner sous SQLite, mais casser les vérifications d'expiration sous Postgres à moins de convertir en vrai timestamp.
Si vous avez hérité d'une base de code générée par Replit ou Cursor, c'est souvent là que des services comme FixMyMess trouvent les points de rupture cachés : les données sont bonnes, mais la logique applicative supposait le comportement de SQLite.
Tests, monitoring et répétition du rollback
La plupart des surprises de downtime viennent du fait que le cutover est traité comme un événement ponctuel, pas comme une procédure répétée. Les apps générées par l'IA sont encore plus risquées ici car elles ont souvent une validation faible, des requêtes inconsistantes et des cas limites qui n'apparaissent qu'avec des données réelles.
Commencez par un smoke test répétable que vous pouvez exécuter en quelques minutes sur les deux bases. Gardez-le petit et centré sur des parcours utilisateurs réels, pas toutes les fonctionnalités.
- Inscription/login/logout (incluant reset de mot de passe si présent)
- Créer un enregistrement clé (par ex. projet, commande ou note)
- Modifier cet enregistrement et vérifier que le changement est visible partout
- Supprimer (ou soft-delete) et confirmer que les permissions fonctionnent toujours
- Exécuter un écran admin/rapport qui joint plusieurs tables
Ensuite, faites un test de lecture en shadow. Pour une portion du trafic ou un job cron, lisez en parallèle depuis Postgres et SQLite, puis comparez les résultats. Loggez les divergences avec assez de contexte pour déboguer (id utilisateur, entrées de requête et clés primaires retournées). Cela attrape des différences subtiles comme l'ordre de tri, la gestion des NULL, la sensibilité à la casse et les conversions de fuseau.
Chargez en test les endpoints qui touchent vos tables les plus sollicitées, pas toute l'app. Un cas courant lors d'une migration SQLite → Postgres est qu'une requête qui « passait » a maintenant besoin d'un index manquant ou d'un meilleur join. Surveillez le p95 de latence et la saturation du pool de connexions.
Enfin, répétez le rollback au moins une fois, chronométré. Écrivez les étapes exactes, qui les exécute et à quoi ressemble un « stop the world » (flip du feature flag, mode lecture seule ou drain du trafic). Définissez les métriques de succès avant de commencer : taux d'erreur acceptable, plafond p95 de latence et un comptage de divergences qui doit atteindre zéro (ou une liste d'exceptions clairement justifiée).
Erreurs fréquentes et comment les éviter
SQLite est indulgent. Postgres est strict. Beaucoup d'équipes se font avoir parce que leur app « marchait d'une façon ou d'une autre » sur SQLite, puis échoue lors de la migration.
Un piège classique est de supposer que les types de données « fonctionneront ». SQLite stocke volontiers du texte dans une colonne semblant entière, ou des dates comme des chaînes aléatoires. Postgres ne le fera pas. Avant de bouger les données, scannez les colonnes aux valeurs mixtes ("", "N/A", "0000-00-00") et décidez du type réel.
Les indexes sont une autre tâche souvent repoussée qui devient un feu en production. SQLite paraît rapide sur des jeux de données petits même sans indexes. Postgres peut ralentir dès que le trafic réel arrive si vous avez oublié les indexes pour les foreign keys, filtres fréquents et colonnes de tri.
Les cutovers échouent quand les écritures basculent trop tôt. Si vous commencez à écrire dans Postgres avant d'avoir des contrôles de dérive, vous ne saurez pas quelle DB est « juste » quand quelque chose casse. Ajoutez des contrôles de dérive (comptes de lignes, plages updated_at, checksums sur tables clés) avant de faire confiance au nouveau système.
Surveillez aussi un chemin de fichier SQLite caché. Les apps IA ont souvent par défaut ./db.sqlite dans une variable d'environnement ou une image Docker. Tout semble correct en staging, puis la prod écrit toujours dans l'ancien fichier.
Les migrations longues sont le tueur silencieux sur les grosses tables. Un seul ALTER TABLE ou un backfill massif peut verrouiller les écritures assez longtemps pour provoquer des timeouts.
Évitez ces pièges avec une petite checklist pré-vol :
- Auditer les colonnes « sales » et normaliser les valeurs avant de caster les types.
- Créer les indexes Postgres avant que le chargement complet ne se termine.
- Garder le dual-write ou la capture de changement désactivés jusqu'à ce que les contrôles de dérive fonctionnent.
- Chercher dans les configs et containers un chemin SQLite errant.
- Fractionner les gros backfills en lots avec des limites temporelles.
Si vous avez hérité d'une codebase IA fragile, des équipes comme FixMyMess commencent souvent par un audit rapide pour révéler ces risques avant la fenêtre de cutover.
Checklist rapide et prochaines étapes
Si vous ne retenez qu'une chose lors de la migration SQLite vers Postgres : la plupart des surprises de downtime viennent de petits écarts entre votre plan et ce que l'app fait réellement en production.
Avant le cutover (préparez-vous)
Faites ces éléments avant de toucher le trafic de production. Si un point est incertain, marquez et confirmez par un test rapide.
- Confirmer que les backups se restaurent proprement (pas seulement qu'ils existent) et capturer l'état exact de la fenêtre de cutover.
- Valider que le schéma traduit correspond à l'usage réel : contraintes, valeurs par défaut et comportement des timestamps.
- S'assurer que le chemin de sync tourne déjà et est stable (dual writes ou capture de changement), avec responsabilité claire des erreurs.
- Lancer un court test de charge similaire à la production sur Postgres et vérifier les pages/endpoints principaux.
Pendant le cutover (switch en sécurité)
L'objectif est un switch rapide et sans histoires avec des signaux clairs et une sortie définie.
- Utiliser un toggle unique et explicite (env var, flag de config ou switch de routeur) et définir qui le bascule.
- Mettre le monitoring visible avant le switch : taux d'erreur, latence, connexions DB et lag de réplication/sync.
- Avoir le rollback prêt et pratiqué : comment repointer l'app et comment gérer les écritures pendant le cutover.
Après le switch, vérifiez d'abord la correction, puis la performance. Comparez les comptes de lignes et les checksums pour les tables clés, exécutez quelques requêtes critiques bout en bout (login, checkout, creations/éditions) et scannez les logs pour de nouvelles erreurs comme des violations de contraintes ou des surprises de fuseau horaire.
Ensuite, attaquez la performance avec un focus. Sortez les requêtes les plus lentes en production, confirmez que les indexes sont utilisés comme attendu et corrigez les quelques-unes qui causent le plus de gêne utilisateur.
Si votre app a été générée par des outils comme Lovable, Bolt, v0, Cursor ou Replit, la couche base de données cache souvent des hypothèses sales (dates en chaînes, contraintes manquantes, requêtes non sûres). FixMyMess propose un audit de code gratuit pour révéler ces risques de migration tôt, avant de vous engager dans un plan de cutover.