Migrer d'une colonne JSON blob vers des tables normalisées avec backfills
Apprenez comment migrer d'une colonne JSON vers des tables normalisées avec un plan par phases : nouveau schéma, backfills, écritures doubles, bascule sûre et options de retour en arrière.
Pourquoi les colonnes JSON-blob cessent de fonctionner à mesure que vous grandissez
Une colonne JSON-blob est un champ unique de la base de données qui contient tout un objet en tant que texte, par exemple {"status": "paid", "coupon": "NEW10", "notes": "..."}. Les équipes commencent souvent par ça parce que c'est rapide : on peut ajouter des champs sans toucher au schéma, et beaucoup d'outils générateurs de code (surtout pour des prototypes rapides) favorisent cette approche.
Le problème arrive quand l'application a de vrais utilisateurs, un vrai volume de données et de vraies questions auxquelles la base doit répondre. Ce qui était une seule écriture simple se transforme en lectures lentes, en rapports compliqués et en beaucoup de cas particuliers dans le code.
Généralement, vous sentirez le JSON blob se dégrader de manière prévisible :
- Les requêtes ralentissent parce que filtrer et trier dans du JSON est plus difficile à optimiser.
- Les champs dérivent vers des formes incohérentes (parfois
phone, parfoisphoneNumber, parfois absent). - Le reporting devient de la devinette parce qu'on ne peut pas se fier aux types, aux champs obligatoires ou aux relations.
- Les corrections de données deviennent risquées parce qu'on édite de gros blobs au lieu d'une colonne claire.
- Les bugs restent cachés pendant des mois parce que des données incorrectes « tiennent » toujours dans le JSON.
Les blobs JSON masquent aussi les problèmes de qualité des données jusqu'à ce qu'il soit coûteux de les corriger. Une valeur qui devrait être un nombre peut devenir silencieusement une chaîne. Un champ requis peut disparaître. Plus tard, quand vous avez besoin de totaux exacts, de déduplication ou de journaux de conformité, vous découvrez que les règles n'ont jamais été appliquées.
« Tables normalisées » signifie découper ce blob en tables et colonnes séparées qui représentent chacune une chose, avec des types et des relations clairs. Au lieu d'un order.data blob, vous pourriez avoir orders, order_items, payments et addresses, avec des colonnes indexables et vérifiables.
Il y a des cas où il faut attendre. Ne migrez pas si le produit change chaque jour, si le volume de données est minime ou si vous n'avez pas une définition claire de ce que signifient les champs. Décidez d'abord ce qui doit rester stable.
Si vous avez hérité d'une appli générée par une IA où « tout est en JSON », ce motif est fréquent : ça marche en démo, puis ça casse en production. La bonne nouvelle : vous pouvez migrer en toute sécurité par phases avec des backfills, sans réécriture massive.
Cartographiez vos données actuelles avant de rien changer
Avant de passer d'un blob JSON à des tables normalisées, clarifiez comment le blob est réellement utilisé aujourd'hui. La plupart des migrations ratent parce qu'on devine ce qu'il y a dans le JSON et ce qui compte.
Notez les principaux flux de lecture et d'écriture qui touchent le blob, basés sur le comportement réel : les pages chargées par les utilisateurs, les formulaires soumis, les appels API, les jobs d'arrière-plan et les exports dont l'équipe dépend. Dans beaucoup d'applications, les premiers cas sont prévisibles : un chargement de page côté utilisateur, une action de sauvegarde, au moins un job en arrière-plan, une vue admin/reporting qui lit beaucoup de lignes, et une ou deux intégrations/webhooks qui ne touchent qu'une partie du blob.
Ensuite, ouvrez quelques lignes de production réelles et listez les champs qui pilotent des décisions. Écartez le bruit comme l'état UI temporaire, d'anciennes flags jamais lues ou des clés aléatoires apparues une fois.
Pour chaque champ, étiquetez-le comme requis, optionnel ou déprécié.
- Requis : l'app casse ou les règles métier échouent sans lui.
- Optionnel : utile mais pas toujours présent.
- Déprécié : sûr à supprimer plus tard, après avoir confirmé que personne ne le lit.
Surveillez les données dupliquées dans des formes différentes. Un signe courant : un champ existe à la fois comme colonne de haut niveau et dans le JSON, ou deux clés JSON représentent le même concept (ex. userId vs customer_id). Ces duplications compliquent les backfills et rendent les bugs difficiles à tracer.
Définissez le succès en termes mesurables avant de toucher le schéma. Des requêtes plus rapides sur des écrans précis. Un reporting qui n'exige plus de parser du JSON. Moins de bugs de données. Des validations plus simples. Moins de tickets de support pour « données manquantes ». Si vous ne pouvez pas mesurer l'amélioration, il est difficile de savoir quand la migration est réellement terminée.
Concevez le schéma normalisé en petites tranches sûres
Ne remplacez pas toute la colonne JSON en une fois. Choisissez une première tranche qui compte clairement : un écran sur lequel les utilisateurs se plaignent, un rapport lent, ou un endpoint API qui timeoute souvent. Une petite victoire force la clarté et borne le travail.
Commencez par nommer des entités réelles. Si le blob mélange « profil utilisateur », « plan d'abonnement », « paiements » et « événements d'audit », ce ne sont pas des champs d'une seule table mais des tables séparées avec des relations. Test simple : pouvez-vous décrire chaque table en une phrase sans mentionner « JSON » ?
Choisissez des identifiants stables. Si vous avez déjà une clé primaire pour la ligne parente (comme account_id), conservez-la et utilisez-la comme clé étrangère dans les nouvelles tables. Pour les enregistrements enfants, ajoutez des IDs stables (payment_id, event_id) au lieu de compter sur la position dans un tableau JSON. C'est important pour les backfills et les replays, car il faut un moyen fiable d'associer les lignes.
Appliquez des contraintes que vous pouvez assumer aujourd'hui, pas la liste parfaite de souhaits. Pour la première tranche, concentrez-vous sur :
NOT NULLpour les colonnes indispensables (commeuser_id,created_at).- Clés étrangères basiques quand la table parente est fiable.
- Unicité là où les doublons casseraient la fonctionnalité (ex. un plan actif par compte).
Si vous avez besoin de traçabilité pendant la transition, gardez-la explicite et temporaire. Une colonne raw_json sur la nouvelle table peut aider à déboguer les mappings, mais ce doit être un choix conscient, pas un nouveau fourre-tout.
Planifiez les index d'après vos requêtes réelles, pas la théorie. Si l'app récupère toujours « derniers événements pour un compte » ou « plan courant pour un utilisateur », indexez exactement ces filtres et ordres. Une petite tranche avec les bons index vaut mieux qu'un grand schéma inutilisable.
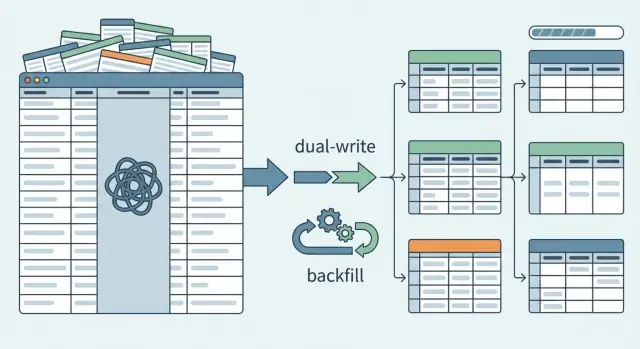
Mettez en place une migration par phases avec un risque minimal
Le chemin le plus sûr est d'ajouter, pas de remplacer. Créez d'abord les nouvelles tables et conservez la colonne JSON existante. La production reste stable pendant que vous prouvez que la nouvelle voie fonctionne.
Au départ, conservez le comportement ancien comme défaut. Les lectures continuent de provenir de la colonne JSON même après la création des nouvelles tables. En coulisses, vous pouvez activer la nouvelle voie de lecture pour un petit sous-ensemble de trafic ou quelques comptes internes.
Un feature flag aide ici. Il permet d'alterner entre l'ancienne source (JSON) et la nouvelle (tables) sans mettre tout en jeu. Il fournit aussi un rollback instantané si quelque chose cloche.
Ensuite, commencez les écritures doubles. Lorsqu'un enregistrement est créé ou mis à jour, écrivez-le à la fois dans la colonne JSON et dans les nouvelles tables normalisées. Ainsi, les nouvelles données s'accumulent dans la nouvelle structure pendant que l'app continue de dépendre de l'ancienne.
Les écritures doubles peuvent dériver si vous n'ajoutez pas de garde-fous simples. Un pattern utile est d'enregistrer un updated_at et un petit schema_version dans les deux endroits. Quand les versions diffèrent, vous savez que la ligne est obsolète et nécessite une attention avant de la considérer fiable.
Un setup minimal en production ressemble généralement à ceci :
- Ajouter nouvelles tables et index, sans supprimer la colonne JSON.
- Ajouter un feature flag de lecture, par défaut sur la source JSON.
- Implémenter les écritures doubles pour créations et mises à jour.
- Stocker
updated_atet unschema_versionpour comparaison. - Logger les divergences et garder un interrupteur de rollback rapide.
Backfills : migrer les données JSON existantes vers les nouvelles tables
Un backfill, c'est transformer du JSON désordonné en lignes propres. Traitez-le comme un vrai pipeline de données, pas comme un script jetable. Vous devez pouvoir l'arrêter, le redémarrer et le relancer sans dupliquer ou corrompre les données de destination.
Rendez le job idempotent et relançable. Un pattern courant : parser le JSON, mapper vers les nouvelles colonnes, puis upsert dans les tables de destination en utilisant une clé naturelle stable (comme user_id + nom du champ) ou un ID déterministe généré. Stockez un checkpoint pour savoir ce qui a été traité.
Pour limiter les risques, backfillez par petits lots et suivez la progression. Les plages d'ID fonctionnent bien quand les IDs sont denses. Les fenêtres temporelles conviennent quand les données sont événementielles. Une file de clés primaires est plus sûre quand les IDs sont épars. Beaucoup d'équipes font aussi une passe « changé depuis la dernière exécution » à la fin pour rattraper ce qui a bougé pendant le backfill.
La validation importe plus que la vitesse. Le JSON masque souvent des types incorrects et des champs manquants, donc soyez explicite sur les règles de parsing : valeurs par défaut, conversions de type et ce que signifie « vide ». Si vous voyez "age": "", stockez-vous NULL, 0 ou rejetez-vous ? Décidez et soyez cohérent.
Supposez que du JSON est cassé et concevez pour ça. Ne faites pas planter tout le job. Quarantainez et loggez les erreurs pour les corriger délibérément :
- Enregistrez l'ID de la ligne source et le chemin JSON qui a planté.
- Sauvegardez le fragment JSON brut qui a causé l'erreur.
- Taggez la raison (JSON invalide, champ requis manquant, mismatch de type).
- Continuez le traitement des enregistrements suivants.
C'est souvent là que les migrations échouent dans des applis générées par IA : cas limites partiellement parsés, troncatures silencieuses et conversions « best effort » qui paraissent correctes jusqu'à ce que le reporting ou la facturation en dépende. Un log strict de ce qui n'a pas pu être migré et pourquoi transforme les surprises en une liste d'actions claire.
Vérifiez l'exactitude avec des comparaisons et des garde-fous
Le plus effrayant n'est pas de déplacer les données, c'est de faire confiance au résultat. Vous avez besoin de contrôles simples qui vous disent, en termes clairs, si les nouvelles tables correspondent à ce que l'app lisait avant dans le JSON.
Commencez par des comparaisons qui calculent la même valeur de deux façons : (1) parser la colonne JSON comme l'ancien code le faisait, et (2) lire depuis les nouvelles tables. Faites cela d'abord pour le comportement visible par l'utilisateur : permissions, prix, limites de plan, flags de statut. Puis étendez aux champs plus profonds.
Déployez d'abord par échantillonnage avant d'essayer de tout valider. Échantillonnez un petit jeu (par ex. enregistrements récents par locataire ou par jour), examinez les divergences, corrigez votre mapping, puis élargissez la couverture jusqu'à être à l'aise pour valider l'ensemble des données.
Quand vous suivez les divergences, gardez des catégories exploitables :
- Manquant : la valeur existe dans le JSON mais aucune ligne dans les nouvelles tables.
- Différent : les deux existent mais ne correspondent pas après normalisation (types, arrondis, casse).
- Invalide : le JSON ne peut pas être parsé ou ne passe pas la validation.
- Inattendu : les nouvelles tables contiennent des valeurs qui n'ont jamais existé dans le JSON.
Décidez de la source de vérité pendant la transition et consignez-la. Choix courants : « JSON est la vérité (les nouvelles tables sont dérivées) » ou « nouvelles tables sont la vérité (JSON est un miroir de compatibilité) ». Choisissez une approche par phase. Sinon, les ingénieurs vont « corriger » les divergences en mettant à jour les deux côtés différemment.
Les garde-fous rendent les erreurs moins coûteuses : feature flags pour les lectures, limites sur le nombre de lignes modifiées par backfill, et alertes quand le taux de divergences augmente. Gardez chaque phase réversible : bascule vers les lectures JSON, possibilité de mettre les écritures en pause et plan de nettoyage pour les données partiellement migrées.
Basculer progressivement les lectures sans casser les utilisateurs
Quand les nouvelles tables sont remplies et maintenues à jour, changez la façon dont vous lisez les données par petites étapes. Traitez chaque parcours de lecture comme une release séparée, pas comme une bascule globale.
Placez la nouvelle lecture derrière un feature flag. Déployez-la d'abord sur une petite tranche de trafic (ou seulement des comptes internes), puis élargissez. Cela contient les échecs et facilite le rollback.
Séquence pratique qui marche pour la plupart des apps :
- Changez un écran ou un endpoint API à la fois.
- Gardez la lecture JSON comme fallback pour cet endpoint.
- Comparez les résultats en tâche de fond et loggez les divergences.
- Augmentez l'exposition progressivement (1%, 10%, 50%, 100%).
- Supprimez le fallback seulement quand les résultats correspondent depuis un moment.
Après chaque bascule, surveillez d'abord ce que ressentent les utilisateurs : taux d'erreur, timeouts et requêtes lentes. Les lectures normalisées peuvent involontairement devenir beaucoup de petites requêtes, et un index manquant peut rendre une page auparavant rapide très lente. Ajoutez des alertes avant le rollout, pas après.
Maintenez les écritures doubles jusqu'à ce que vous fassiez confiance aux nouvelles lectures en charge réelle. Si vous arrêtez d'écrire dans le blob trop tôt, un rollback devient un incident de perte de données. L'écriture double est une assurance. Supprimez-la seulement quand vous êtes sûr de ne pas revenir en arrière.
Pendant la migration, rendez explicites les dépendances blob-only. Si une fonctionnalité dépend encore d'une clé uniquement présente dans le JSON, décidez si elle devient une colonne/table réelle ou si elle est supprimée. Laisser cela vague, c'est comment les équipes finissent par lire des deux modèles pour toujours.
Erreurs courantes qui causent perte de données ou downtime
La plupart des pannes lors d'une migration JSON→tables viennent du fait de considérer le travail comme un simple interrupteur. En réalité, vous faites coexister deux modèles de données pendant un moment, et l'intersection est là où ça casse.
Un échec fréquent : activer l'écriture double sans décider ce qui se passe quand les deux écritures divergent. Même si les deux updates se passent dans la même requête, vous avez besoin d'une politique de conflit (quel côté l'emporte) et d'un moyen de détecter et rejouer les écritures manquantes.
Les backfills posent aussi problème quand ils ne peuvent pas reprendre. Les jobs longs sont interrompus : déploiements, timeouts, verrous sur les lignes ou un enregistrement corrompu. Si le job recommence depuis le début, vous risquez des doublons, des mises à jour partielles ou une charge énorme qui ressemble à un DDoS pour votre propre base.
La dérive silencieuse des données est un autre point. Les équipes « nettoient » la sémantique des champs pendant la migration (changer les valeurs de statut ou les formats de date) et oublient de documenter le mapping. Tout semble correct jusqu'à ce que les rapports, les e-mails ou la facturation se comportent différemment.
Les erreurs les plus fréquentes :
- Pas de politique de conflit claire pour les écritures doubles, et pas de journal d'audit pour repérer les divergences.
- Backfills non idempotents et sans checkpoints.
- Changer la signification d'un champ en cours de migration sans mapping versionné et tests.
- Oublier les lecteurs en aval : analytics, exports, webhooks et jobs d'arrière-plan.
- Supprimer la colonne JSON trop tôt, avant que toutes les lectures soient déplacées et vérifiées.
Un exemple concret : une app stocke « profil utilisateur », « abonnement » et « permissions » dans une colonne JSON. Un backfill copie les données dans de nouvelles tables, mais un job nocturne lit encore le JSON et réécrit les tables normalisées, écrasant des changements récents. La solution n'est généralement pas du code plus intelligent : ce sont des règles claires : backfills re-exécutables, mappings stricts et garder la colonne ancienne jusqu'à ce que le nouveau modèle soit prouvé correct.
Checklist rapide avant la bascule finale
Le jour de la bascule doit être ennuyeux. Si ça ressemble encore à un saut de foi, faites un dry run de plus.
- Tables et releases prêtes à être déployées : nouvelles tables en prod, migrations ré-exécutables et index/contraintes vérifiés.
- Backfill visible et répétable : progression, totaux d'erreurs et checkpoints visibles, relance possible sans duplication.
- Écriture double activée et règles de conflit consignées : vous savez quelle source gagne (par ex. plus récent) et vous loggez les conflits.
- Basculement des lectures sous garde : lectures basculables par endpoint ou tenant via feature flags, et réversibles rapidement.
- Taux de divergence acceptable et rollback testé : comparaison des totaux clés, vérifications ponctuelles d'enregistrements et pratique de rollback sur données de test.
Scénario d'exemple : nettoyer une appli construite par une IA qui stockait tout en JSON
Un fondateur lance un prototype CRM généré par IA en un week-end. Ça marche en démo, mais chaque profil client est stocké en un seul blob JSON dans une colonne. Un profil peut contenir nom, e-mail, statut, last_contacted, notes et champs personnalisés.
Trois mois après, la douleur arrive. Le reporting est lent car la base doit scanner et parser du JSON pour chaque graphique. Pire : le champ status est un désordre : "Active", "active", "ACTIV", "In progress", "In-Progress" et "inprogress" signifient approximativement la même chose. Les filtres ratent des enregistrements, les tableaux de bord divergent et les notes de vente se retrouvent attachées au mauvais stade.
Une première tranche sûre est de normaliser ce qui alimente le tableau de bord : clients et statuts.
Cette tranche peut ressembler à :
- Une table
customersavec des colonnes stables (id,name,email,created_at). - Une table de lookup
statuses(id,canonical_name) avec un ensemble autorisé. - Une façon de les relier (soit
customers.status_id, soit une tablecustomer_statusséparée selon l'historique).
Ensuite, backfill depuis le JSON existant :
- Parser chaque blob de profil et insérer ou mettre à jour la ligne customer.
- Mapper les chaînes de statut désordonnées vers des statuts canoniques, avec un seau « unknown » clair.
- Logger tout ce qui échoue au parse pour corriger les données au lieu de deviner.
La bascule reste progressive. D'abord, switcher seulement les lectures du tableau de bord vers les nouvelles tables. Garder les lectures JSON pour le reste de l'app pendant que vous comparez les comptes et totaux. Quand le tableau de bord est correct et rapide, migrer les autres écrans un par un.
Étapes suivantes : finir la migration et garder la propreté
Quand vos lectures sont entièrement sur les nouvelles tables et qu'une période stable sans surprises est passée, décidez du sort de la colonne JSON. La plupart des équipes la gèlent (plus d'écritures, conservée pendant une fenêtre de sécurité) ou la suppriment après sauvegardes et approbation.
Si vous avez reporté des sécurités pour avancer vite, ajoutez-les maintenant. Les tables normalisées rapportent sur le long terme quand elles empêchent les mauvaises données, pas seulement quand elles les stockent.
Verrouillez le nouveau contrat
Consignez les règles dont l'app dépend désormais : quels champs sont requis, ce que « valide » signifie et où chaque donnée vit. Cela devient le contrat de données pour les futures fonctionnalités et évite que de nouveaux arrivants réintroduisent un blob « juste pour l'instant ».
Une page suffit : noms de tables, colonnes clés, ownership (qui écrit quoi) et un court exemple d'enregistrement valide.
Empêchez le retour aux blobs
Après la migration, le plus grand risque est la dérive : de nouvelles fonctionnalités recommencent à fourrer des champs dans un JSON fourre-tout.
Gelez ou supprimez la colonne JSON après une période de stabilité définie. Ajoutez les contraintes et index que vous avez différés (clés étrangères, unicité, NOT NULL, et les index pour vos requêtes principales). Si vous gardez un champ JSON pour des métadonnées « misc », ajoutez un contrôle léger pour que de nouvelles clés n'apparaissent pas sans plan.
Si vous avez hérité d'une codebase générée par IA et que vous voulez la rendre robuste en production, FixMyMess (fixmymess.ai) se concentre sur le diagnostic et la réparation de ces architectures générées par IA, y compris les migrations par phases, les corrections logiques et le renforcement de la sécurité, avec une vérification humaine avant chaque livraison.