Mise en cache et pagination pour pages de listes lentes : modèles pratiques
Apprenez la mise en cache et la pagination pour pages de listes lentes : patterns pratiques de pagination par curseur, conception de clés de cache et alternatives sûres aux API « renvoyer tout ».
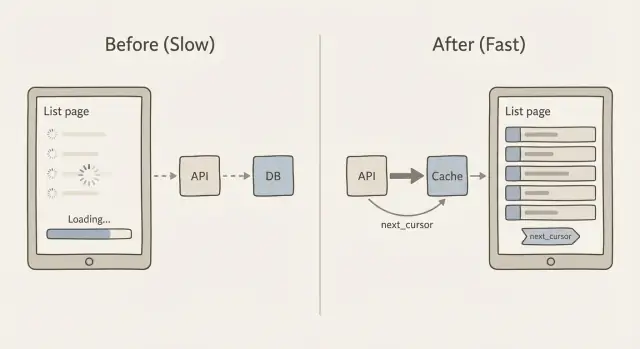
Pourquoi les pages de liste ralentissent quand les données augmentent
Une page de liste fonctionne souvent bien à 200 lignes, puis commence soudainement à dysfonctionner à 20 000. Les utilisateurs voient un défilement lent, des indicateurs de chargement qui ne s'arrêtent pas, et des filtres qui prennent des secondes à répondre. Parfois la page affiche un état vide parce que la requête expire ou que le client abandonne et n'affiche rien.
Le problème de fond est simple : chaque enregistrement supplémentaire demande plus de travail. La base de données doit trouver les lignes, les trier et appliquer les filtres. L'API doit les transformer en JSON. Le réseau doit transférer ces données. Ensuite le navigateur (ou l'app mobile) doit les analyser, allouer la mémoire et les afficher.
Où passe le temps
À mesure que votre jeu de données grossit, les ralentissements viennent généralement d'un mélange de :
- Travail en base de données : scans importants, jointures coûteuses et tri de grands ensembles de résultats.
- Taille de la charge utile : renvoyer des centaines ou milliers de lignes par requête.
- Coût du rendu : l'interface essaie d'afficher trop d'éléments d'un coup.
- Requêtes répétées : la même liste demandée encore et encore sans mise en cache.
Le tri et le filtrage ont un coût caché car ils forcent souvent la base à toucher bien plus de données que prévu. Par exemple, filtrer par “status = open” est peu coûteux avec le bon index, mais “recherche par nom contient” ou “tri par dernière activité” peut vite devenir cher. Pire encore, ajouter une pagination par OFFSET (page 2000) peut obliger la base à parcourir des milliers de lignes juste pour atteindre la page suivante.
L'objectif n'est pas « le rendre rapide une fois ». L'objectif est un temps de réponse prévisible à mesure que les données augmentent. Cela signifie généralement renvoyer moins d'enregistrements par requête, utiliser une pagination qui ne ralentit pas sur les pages profondes, et mettre en cache les réponses de liste pour que les visites répétées ne paient pas à chaque fois le coût complet.
Évitez les endpoints "tout renvoyer"
Une raison courante des ralentissements est une API qui renvoie toute la table parce que c'était pratique au stade du prototype. Cela ressemble souvent à :
GET /api/orders
200 OK
[
{ "id": 1, "customer": "...", "notes": "...", "internalFlags": "...", ... },
{ "id": 2, ... }
]
Cela échoue à l'échelle car cela multiplie le travail à trois niveaux : la base doit scanner et trier plus de lignes, le serveur doit construire et envoyer une énorme réponse JSON, et le navigateur doit la parser et afficher une longue liste. Même si vous ajoutez ensuite mise en cache et pagination, un endpoint « renvoie tout » reste coûteux à générer et à transmettre.
Les mobiles et les réseaux instables le ressentent en premier. Une réponse JSON de 5–10 Mo peut passer sur un Wi‑Fi de bureau, mais tomber en timeout sur de la 4G, vider la batterie et donner l'impression que l'app est cassée. Cela rend aussi la récupération d'erreur plus difficile : si une requête échoue, l'utilisateur perd toute la page au lieu du seul segment suivant.
Voici une règle simple pour rester raisonnable : envoyez seulement ce que l'utilisateur peut voir maintenant. Cela signifie généralement une petite page (par exemple 25–100 lignes) et seulement les champs nécessaires pour la vue de liste.
Quand des équipes nous montrent un panneau d'administration généré par IA, on trouve souvent des endpoints de liste renvoyant des enregistrements complets (y compris de longs champs texte) sans limite. La victoire rapide est de renvoyer une forme compacte « list item » et de charger les détails seulement quand quelqu'un ouvre une ligne. Ce changement suffit souvent à réduire le temps de requête, la taille de la réponse et le temps de rendu côté client sans toucher au design de l'UI.
Pagination par curseur en clair
Beaucoup d'endpoints de liste commencent par une pagination par offset : « donne-moi la page 3 » signifie « saute les 40 premières lignes et renvoie les 20 suivantes ». Cela paraît simple, mais ça devient plus lent à mesure que la table grossit parce que la base doit tout de même parcourir les lignes ignorées.
La pagination par offset devient aussi étrange quand les données changent pendant que quelqu'un navigue. Si de nouvelles lignes sont insérées ou supprimées, la page suivante peut montrer des doublons ou sauter des éléments. Vous avez demandé « page 3 », mais « page 3 » n'est pas stable.
La pagination par curseur corrige cela en utilisant un marque-page plutôt qu'un numéro de page. Le client dit « donne-moi les 20 éléments suivants après ce dernier élément que j'ai vu ». Cette valeur “après” est le curseur. C'est l'idée centrale pour garder chaque requête petite, prévisible et rapide.
Ce qu'est réellement le curseur
Un curseur est généralement un petit paquet de valeurs provenant de la dernière ligne dans la réponse courante. Pour le rendre stable, votre liste doit avoir un ordre de tri cohérent qui n'admet pas d'égalité non résolue. Un schéma courant est trier par created_at avec id en tie‑breaker (par exemple : le plus récent d'abord, et si deux lignes partagent le même timestamp, trier par id).
Cet ordre stable importe car il garantit que « après cet élément » pointe toujours vers un seul emplacement précis dans la liste.
Comment marche next_cursor
Conceptuellement, le serveur renvoie :
- Les éléments pour cette requête (par exemple 20)
- Un
next_cursorqui représente le dernier élément de cet ensemble
S'il n'y a plus d'éléments, next_cursor est vide ou absent. Le client le stocke et le renvoie pour obtenir la tranche suivante. Pas de comptage de pages, pas de grands sauts et beaucoup moins de surprises quand la liste change.
Pas à pas : implémenter un endpoint paginé par curseur
La pagination par curseur est le pattern de base pour garder les listes stables et rapides, même quand de nouvelles lignes arrivent.
1) Choisir un ordre de tri stable
Choisissez un ordre qui ne change pas pour une ligne donnée. Un choix courant est created_at desc, id desc. Le tie‑breaker id est important quand plusieurs lignes ont le même timestamp.
2) Définir les formes de requête et de réponse
Gardez la requête petite et prévisible : un limit, un cursor optionnel et les filtres que vous supportez déjà (status, owner, search).
Une forme de réponse simple ressemble à :
{
"items": [/* results */],
"next_cursor": "opaque-token",
"has_more": true
}
3) Encoder et décoder le curseur en toute sécurité
Ne mettez pas du SQL brut ou un offset de base de données dans le curseur. Faites-en un token opaque qui contient seulement ce dont vous avez besoin pour reprendre la pagination, comme le created_at et l'id du dernier élément.
Un format pratique est du JSON encodé en base64, éventuellement signé (pour empêcher la falsification par le client). Exemple de payload à l'intérieur du token : { "created_at": "2026-01-10T12:34:56Z", "id": 123 }.
4) Interroger en utilisant le curseur (et gérer les insertions)
Avec created_at desc, id desc, la requête pour la page suivante doit récupérer les lignes « avant » le curseur :
created_at < cursor_created_atOR (created_at = cursor_created_atANDid < cursor_id)
Cela maintient la pagination stable même si de nouveaux éléments sont insérés en haut pendant que l'utilisateur parcourt la liste.
5) Ajouter des garde‑fous
Fixez une valeur par défaut pour limit (par exemple 25) et un maximum strict (par exemple 100). Validez le curseur, le limit et les filtres. Si le curseur est invalide, renvoyez une 400 claire. Chez FixMyMess, ces garde‑fous manquent souvent dans les endpoints générés par IA, ce qui explique pourquoi les pages de liste tombent sous une vraie charge.
Concevoir des clés de cache pour les réponses de liste
Mettre en cache les pages de liste paraît simple jusqu'à ce que vous vous souveniez du nombre de « listes différentes » que votre appli peut produire. Un endpoint peut supporter recherche, filtres, options de tri, tailles de page différentes et pagination par curseur. Si votre clé de cache ignore l'un de ces inputs, vous risquez d'afficher de mauvais résultats au mauvais utilisateur.
Une bonne clé de cache est simplement l'empreinte unique de la réponse de liste exacte. Incluez tout ce qui change les lignes affichées ou leur ordre. Typiquement cela signifie :
- Périmètre : public vs par utilisateur vs par organisation (et l'id correspondant)
- Entrées de requête : filtres, texte de recherche et tri
- Pagination : curseur (ou marqueur « première page ») et limit
- Version : un tag optionnel (par ex. « list-v2 ») pour changer le format en sécurité
Gardez la clé lisible. Un pattern simple qui marche bien est :
resource:scope:filters:sort:cursor:limit
Par exemple : tickets:org_42:status=open|q=refund:created_desc:cursor=abc123:limit=25. Normalisez les entrées pour éviter des misses inutiles (trimer les espaces, trier les paramètres de filtre, utiliser un séparateur cohérent).
Décidez ce que vous mettez en cache. Beaucoup d'équipes ne mettent en cache que la première page parce qu'elle est la plus sollicitée et bénéficie le plus d'un TTL court. Mettre en cache chaque page aide aussi, mais multiplie le nombre de clés et complique l'invalidation quand les données changent.
Ne mettez pas en cache quand cela a plus de chances d'être faux que d'aider : listes fortement personnalisées (comme « recommandé pour vous »), listes changeant toutes les quelques secondes, ou listes incluant des contrôles d'accès difficiles à encoder dans la clé.
Si vous travaillez sur une appli générée par IA, surveillez les endpoints qui traitent le « cursor » comme optionnel et reviennent à « renvoyer tout ». C'est un problème courant que nous corrigeons en verrouillant les defaults de pagination et en faisant figurer le contexte complet de la requête dans la clé de cache.
Garder les listes mises en cache fraîches sans compliquer
La plupart des pages de liste n'ont pas besoin d'une fraîcheur parfaite et instantanée. Elles doivent donner l'impression d'être rapides et être « assez récentes » pour l'objectif de l'utilisateur. C'est la clé pour faire marcher la mise en cache sans transformer l'invalidation en un second produit.
TTL vs invalidation basée sur les événements (en clair)
Un TTL (time to live) est l'option la plus simple : mettez la liste en cache pendant, disons, 30–120 secondes, puis rafraîchissez. C'est facile et fiable, mais cela peut afficher des données légèrement anciennes.
L'invalidation basée sur les événements tente d'être exacte : quand un enregistrement change, vous supprimez immédiatement les listes mises en cache affectées. C'est très frais, mais complexe car un changement peut concerner beaucoup de filtres et d'ordres de tri.
Un compromis pratique est « stale while revalidate » : servez la liste mise en cache même si elle est un peu vieille, puis rafraîchissez-la en arrière‑plan. Les utilisateurs ont des pages rapides, et le cache se répare rapidement après des changements.
Invalidation ciblée et gérable
Plutôt que « supprimer tout », invalidez seulement ce que vous pouvez décrire clairement :
- Par utilisateur ou locataire (seulement leurs listes)
- Par type de ressource (orders vs customers)
- Par groupe de filtres (status=open, tag=vip)
- Par « version de collection » (un compteur que vous incrémentez lors des écritures)
La dernière option est souvent la plus simple : incluez collection_version dans la clé de cache. Quand quelque chose change, incrémentez la version, et les anciennes entrées de cache deviennent obsolètes.
Les stampedes de cache arrivent quand de nombreuses requêtes ratent le cache et le reconstruisent en même temps. Deux protections simples aident :
- Ajouter du jitter au TTL (aléatoire +/- 10–20%)
- Coalescence des requêtes (un seul ré-constructeur, les autres attendent)
- Servir de l'obsolète pendant une courte fenêtre
Enfin, décidez quelle cohérence vous avez réellement besoin. Pour la plupart des pages d'admin et des fils d'actualité, « les mises à jour apparaissent en 1–2 minutes » suffit. Pour les mouvements d'argent ou les permissions, ne mettez pas la liste en cache du tout, ou gardez un TTL très court et validez côté détail.
Patterns de pagination côté client qui restent rapides
La plupart des écrans de liste ont un modèle de trafic clair : les gens arrivent sur la page 1 bien plus que sur n'importe quelle autre page. Mettez en cache la première page côté client (mémoire ou local storage) avec un TTL court, et affichez‑la immédiatement tout en la rafraîchissant en arrière‑plan. Cela règle souvent la sensation d'« écran blanc » qui fait paraître une liste lente.
Avec la pagination par curseur, traitez le curseur comme faisant partie de l'identité de la page. Gardez une petite map cursor -> rows pour que revenir en arrière n'entraîne pas de nouvelles requêtes, et pour que votre UI reste réactive même sur des réseaux instables.
Le préchargement (prefetch) de la page suivante aide, mais seulement s'il est doux. Une approche sûre : précharger lorsque l'utilisateur est proche du bas (ou après une pause dans le défilement), et annuler la requête si l'utilisateur change les filtres ou le tri.
- Précharger une seule page à l'avance
- Débouncer le déclencheur (par exemple 200–400 ms)
- Bloquer le préchargement si une requête est déjà en cours
- Ne pas précharger pour les filtres coûteux (comme la recherche plein texte)
- Arrêter le préchargement quand l'onglet est caché
Les états de chargement comptent plus qu'on ne le croit. Utilisez un indicateur de chargement « doux » (laissez les lignes existantes visibles) et un bouton de retry évident pour les échecs. Au retry, n'ajoutez les résultats qu'après avoir confirmé qu'ils appartiennent à la même requête (mêmes filtres, tri et curseur), sinon vous aurez des doublons ou un mélange de lignes.
La déduplication côté client est votre filet de sécurité. Fusionnez toujours les lignes par un ID stable (par exemple id), pas par index de tableau ou timestamp. Si vous recevez la même ligne deux fois, remplacez‑la sur place pour que la liste ne saute pas.
Le scroll infini n'est pas toujours mieux. Il peut être pire pour des écrans d'admin où les gens ont besoin de sauter, trier et comparer. Si les utilisateurs disent souvent « j'étais sur la page 7 », préférez une navigation paginée avec taille de page claire, et réservez le scroll infini aux feeds où la position exacte n'a pas d'importance.
Notions basiques sur la base de données et la charge utile qui améliorent la mise en cache
La mise en cache aide, mais n'efface pas les requêtes lentes. Une réponse de liste mise en cache doit quand même être générée au moins une fois, et les misses arrivent plus que prévu (nouveaux filtres, nouveaux utilisateurs, clés expirées, déploiements). Si la requête DB est fragile, tout le système paraît instable.
Les index sont le premier endroit à vérifier. Pour les pages de liste, le pattern gagnant est simple : votre index doit correspondre à la façon dont vous filtrez et triez. Si votre endpoint fait WHERE status = 'open' et ORDER BY created_at DESC, la base doit avoir un chemin qui supporte les deux.
Règles pratiques pour les requêtes de liste :
- Indexez les colonnes utilisées le plus souvent dans le
WHERE. - Incluez la colonne de tri (
ORDER BY) dans le même index si possible. - Si vous filtrez toujours par locataire ou utilisateur, cette colonne devrait généralement venir en premier.
- Préférez des clés de tri stables (created time, id) pour que pagination et cache restent prévisibles.
- Re‑vérifiez les index après avoir ajouté de nouveaux filtres, pas des mois plus tard.
Ensuite : arrêtez d'envoyer des données en trop. Beaucoup de pages lentes le sont parce qu'elles transfèrent trop de JSON, pas parce que la base est morte. Évitez SELECT *. Choisissez les champs réellement affichés dans le tableau. Si l'UI n'a besoin que de id, name, status et updated_at, ne renvoyez que ceux‑ci. Vous obtenez des requêtes plus rapides, des payloads plus petits et des taux de hit de cache supérieurs parce que les réponses sont moins coûteuses à stocker et servir.
Faites attention au tri sur des champs calculés, comme « full_name » (first + last), « last_activity » issu d'une sous‑requête, ou « relevance » d'une formule personnalisée. Ceux‑ci forcent souvent des scans, des plans join‑lourds ou le tri en mémoire de grands ensembles. Quand c'est possible, pré‑calculez la valeur dans une vraie colonne, ou triez par un champ plus simple et calculez la valeur fancy dans l'UI.
Avant d'optimiser plus loin, mesurez deux nombres :
- Temps de requête (p50 et p95, pas seulement une exécution).
- Taille de la charge utile pour une page.
- Lignes examinées vs lignes renvoyées.
- Taux de hit du cache pour l'endpoint de liste.
- Le filtre+tri le plus lent que les utilisateurs utilisent réellement.
C'est courant dans les applis générées par IA que nous voyons : les endpoints « fonctionnent » en démo, mais une fois que de vraies données arrivent, des index manquants et des payloads surdimensionnés font passer la mise en cache pour « inefficace ». Réparez les bases d'abord, puis la mise en cache devient un multiplicateur plutôt qu'un pansement.
Exemple : réparer une page d'admin lente dans une appli en croissance
Histoire courante : un dashboard admin a commencé comme prototype généré par IA. Il fonctionnait avec 200 lignes. Six mois plus tard il en a 200 000 et la liste « Users » expire ou met 10–20 secondes à charger. Les gens rafraîchissent, les filtres semblent aléatoires et la CPU DB monte en flèche.
La mauvaise version ressemble souvent à ceci : le client appelle un endpoint qui renvoie tout (ou utilise la pagination par offset avec des offsets énormes), la réponse inclut des champs lourds (profils, settings, historique d'audit), et chaque scroll déclenche une autre requête coûteuse. Il n'y a pas de cache, donc la même première page est recalculée pour chaque admin.
Voici une correction pratique qui garde le comportement prévisible.
Ce que nous avons changé
Nous avons conservé l'UI mais changé le contrat API :
- Utiliser la pagination par curseur : renvoyer
items,nextCursor, et exiger toujours unlimit. - Trier par une clé stable (par ex.
created_atplusid) pour que les curseurs n'entraînent pas de sauts ni de doublons. - Mettre en cache seulement la première page pour les vues communes (comme « All users, newest first »), car c'est la plus demandée.
- Restreindre les filtres aux champs sûrs et indexés (status, role, created date). Rejeter les recherches « contains » sur de gros champs texte à moins d'avoir un moteur de recherche dédié.
- Réduire la charge utile : la liste renvoie seulement ce qui est nécessaire. Les détails se chargent sur la page de l'utilisateur.
Une forme de réponse simple :
{ "items": [{"id": "u_1", "email": "[email protected]", "createdAt": "..."}], "nextCursor": "createdAt:id" }
Ce que les admins ont remarqué
L'écran initial apparaît vite, et le défilement reste fluide car chaque requête est bornée. Le rafraîchissement de la liste cesse d'écraser la base parce que la première page provient du cache. Les filtres sont cohérents car l'ordre de tri et les règles de curseur sont clairs.
Pour un déploiement sûr, mettez le nouvel endpoint derrière un feature flag pour les admins internes, comparez côte à côte et loggez les erreurs de curseur (doublons, lignes manquantes). Si vous héritez d'un prototype cassé d'outils comme Bolt ou Replit, des équipes comme FixMyMess commencent souvent par un audit rapide pour trouver les endpoints « renvoie tout » et les requêtes à corriger en priorité.
Erreurs courantes et pièges à surveiller
La plupart des correctifs échouent pour des raisons simples : la pagination est incohérente, le cache est dangereux, ou l'endpoint est abusable. Si vous travaillez sur la mise en cache et la pagination, voici les pièges qui font le plus mal plus tard.
La pagination par offset est le piège classique. Elle va bien sur peu de données, mais si vous triez par un champ non unique (comme created_at), de nouvelles lignes peuvent s'insérer au milieu pendant que l'utilisateur parcourt. Cela crée des doublons, des éléments manquants ou une page qui « saute ». La pagination par curseur évite cela, mais seulement si votre ordre de tri est stable (par exemple : created_at plus un id unique).
Les curseurs peuvent eux‑mêmes poser des problèmes de sécurité et de cohérence. Si vous mettez des IDs bruts, des fragments SQL, ou des expressions de filtre dans le curseur, vous risquez que des utilisateurs devinent des valeurs, cassent le décodage ou forcent des requêtes coûteuses. Un pattern plus sûr : encoder seulement les dernières valeurs de tri, puis les valider côté serveur avant la requête.
La mise en cache introduit une autre classe d'erreurs. La plus grosse est d'oublier le scope. Si votre clé de cache n'inclut pas l'utilisateur, le tenant, le rôle et les filtres, vous pouvez fuiter des données entre comptes. Surveillez aussi l'histoire de la fraîcheur : les changements de statut et les suppressions sont les premières choses que les utilisateurs remarquent quand les listes mises en cache sont en retard.
Un exemple rapide : une page admin « Orders » affiche paid et pending. Si la clé de cache ignore le filtre status=pending, un admin peut voir une liste mélangée qui semble fausse, et le cache peut même être partagé avec des vues non‑admin.
Voici cinq garde‑fous qui évitent la plupart des incidents :
- Toujours ajouter un
limitmax et l'appliquer côté serveur. - Utiliser un tri stable avec un tie‑breaker unique.
- Rendre les curseurs opaques et valider les valeurs décodées.
- Construire les clés de cache à partir du scope utilisateur + filtres + tri + taille de page.
- Décider combien de temps les données obsolètes sont acceptables, puis invalider ou raccourcir le TTL pour les listes à haute fréquence de changement.
Si vous avez hérité d'une appli générée par IA avec une pagination fragile, des clés de cache non sûres ou des endpoints non bornés, FixMyMess peut auditer le code et pointer précisément les modes d'échec avant que vous ne les mettiez en production.
Checklist rapide et prochaines étapes
Utilisez ceci comme une passe finale quand vous améliorez la mise en cache et la pagination. Ce sont les détails qui décident si votre liste reste rapide à 1 000 lignes comme à 10 millions.
Construire en sécurité (API et cache)
- Fixez un cap strict sur
limit(et une valeur par défaut sensée) pour empêcher des requêtes de 50 000 lignes par accident. - Utilisez un tri stable (par exemple created_at + id) pour éviter le réarrangement des items entre requêtes.
- Gardez le curseur opaque. Traitez‑le comme un token, pas comme quelque chose que le client édite.
- Assurez‑vous que la requête utilise des index correspondant à vos filtres et à l'ordre de tri.
- Scopez les clés de cache à ce qui change la réponse : utilisateur ou tenant, filtres, tri, taille de page et curseur.
La mise en cache marche mieux quand la première page est facile à réutiliser, donc commencez par là. Choisissez un TTL correspondant à la fréquence de changement réelle de la liste, et ajoutez une protection basique contre les stampedes (lock, coalescence de requêtes, ou servir de l'obsolète pendant la revalidation) pour que les pics de trafic ne fassent pas fondre votre base.
Prouver que ça marche (tests et exploitation)
- Créez de nouveaux items pendant le paging et confirmez que vous ne voyez pas de doublons ni d'éléments manquants.
- Changez les filtres en plein défilement et confirmez que le client réinitialise l'état au lieu de mêler anciennes et nouvelles pages.
- Simulez un réseau lent et vérifiez que le client déduit les doublons et ignore les réponses hors ordre.
- Surveillez le temps de requête, le taux de hit du cache, le taux d'erreur et la taille des payloads après le lancement.
- Loggez les endpoints de liste les plus lents avec leurs filtres pour cibler les vrais coupables.
Prochaine étape : si votre prototype généré par IA a des endpoints de liste lents ou cassés, FixMyMess peut réaliser un audit gratuit du code pour localiser pagination, mise en cache et problèmes de sécurité avant la mise en production.