Changements de base de données sans interruption avec expand-contract
Apprenez à réaliser des changements de base de données sans interruption avec l'approche expand-contract : ajoutez des champs sûrs, migrez les données par étapes, gardez l'ancien code fonctionnel, puis supprimez l'ancien.
Pourquoi les modifications de base de données provoquent des interruptions
La plupart des pannes liées à la base de données surviennent quand le code et le schéma changent en même temps, mais ne se déploient pas dans le même ordre partout. Les serveurs d'app, les jobs en arrière‑plan et les tâches planifiées ne se mettent pas à jour instantanément. Pendant un moment, l'ancien code et le nouveau tournent côte à côte. Si l'une des versions attend quelque chose que la base de données ne fournit plus, les utilisateurs le ressentent.
L'erreur classique est de penser qu'« il suffit d'exécuter une migration » est une étape sûre. Une migration peut verrouiller des tables, réécrire beaucoup de lignes, ou supprimer une colonne qu'un processus encore en cours lit. Même des changements « mineurs » comme renommer une colonne peuvent casser la production si une requête s'attend encore à l'ancien nom.
Les signes d'une interruption sont généralement :
- des erreurs 500 quand le code lit une colonne ou une table qui n'existe plus
- des données manquantes ou incorrectes quand l'ancien et le nouveau code lisent/écrivent des formes différentes
- des timeouts quand une migration bloque les écritures ou déclenche des requêtes lentes
- des bugs « ça marche chez moi » quand seuls certains serveurs sont mis à jour
- des jobs en arrière‑plan qui échouent, retentent et surchargent le système
« Rétro‑compatible » signifie que l'ancien code peut continuer à fonctionner en sécurité pendant que la base de données change. Concrètement, vous évitez de supprimer ou de modifier quoi que ce soit dont l'ancien code dépend. Vous ajoutez de nouveaux champs ou tables de façon compréhensible pour les deux versions, puis vous déplacez les données progressivement.
Les changements sans interruption sont difficiles parce que les bases de données sont un état partagé. Une migration risquée peut impacter chaque requête, chaque écriture et chaque job d'un coup. L'approche expand-contract réduit ce risque en évitant le moment « tout ou rien » : on étend d'abord le schéma, on fait tourner les deux versions en sécurité, on migre les données en arrière‑plan, puis on nettoie seulement après que le nouveau chemin a prouvé sa stabilité.
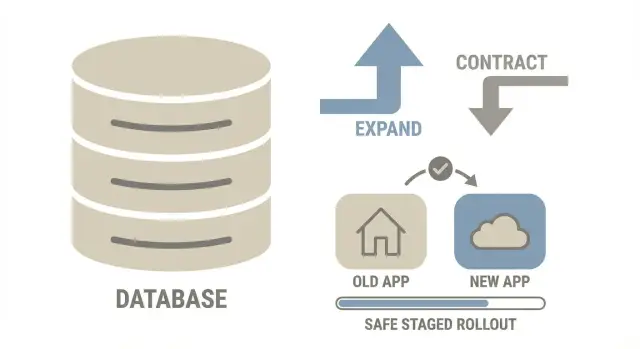
L'idée expand-contract en une image
Pensez à expand-contract comme rénover une cuisine tout en continuant à cuisiner chaque jour. Vous n'enlevez pas l'ancien évier d'abord. Vous ajoutez le nouvel évier, vous basculez l'usage, et vous ne retirez l'ancien que quand tout fonctionne.
Time ->
1) EXPAND 2) MIGRATE (gradual) 3) CONTRACT
Add new parts Copy/backfill data safely Remove old parts
Keep old path Run both paths for a while After new path is proven
- Expand : Ajoutez ce dont vous avez besoin (nouvelle colonne, nouvelle table, nouvel index) sans casser l'ancien code.
- Migrate : Déplacez les données par petits lots pendant que l'application reste en ligne. Pendant un temps, les deux formes coexistent.
- Contract : Supprimez les anciennes pièces seulement après que le nouveau chemin se soit montré stable en production.
Cela réduit le risque parce que chaque étape est plus petite, plus facile à mettre en pause et plus simple à raisonner qu'une grosse migration unique.
Concevoir une mise à jour de schéma rétro‑compatible
Un changement de schéma rétro‑compatible signifie que l'ancienne et la nouvelle version de l'application peuvent tourner contre la même base.
Commencez par des changements additifs. Ajoutez une nouvelle colonne, une nouvelle table ou une table de jointure, mais conservez l'ancien schéma tant que vous n'êtes pas sûr que rien n'en dépend. Si vous devez renommer quelque chose, ajoutez d'abord le nouveau nom et conservez l'ancien (par exemple via une vue ou une colonne dupliquée), puis supprimez l'ancien nom plus tard.
Pendant la phase d'expansion, choisissez des valeurs par défaut qui ne surprendront pas l'ancien code. Les champs NULLABLE sont généralement plus sûrs le premier jour qu'un champ requis. Si un champ doit être non‑NULL, introduisez‑le avec une valeur par défaut sûre qui reflète le comportement existant, puis appliquez des règles plus strictes après la mise à jour de l'app.
Quelques règles évitent la plupart des cassures :
- Ne supprimez pas de colonnes ni ne changez leur sens avant la phase de contract.
- Évitez les renommages comme première étape. Ajoutez d'abord, migrez, puis nettoyez.
- Ajoutez les contraintes progressivement (NOT NULL, UNIQUE, clés étrangères) après que les données sont en place.
- Planifiez les changements d'index pour éviter de longs verrous d'écriture (utilisez les options en ligne quand elles existent).
- Assurez‑vous que chaque nouveau champ a une histoire pour les lignes anciennes.
Décidez tôt comment lectures et écritures fonctionneront tant que les deux versions coexistent. Les approches courantes sont :
- Le nouveau code écrit à la fois l'ancien et le nouveau format pendant la transition (dual‑write).
- Le nouveau code écrit seulement le nouveau format, et une couche de compatibilité maintient l'ancien format à jour.
- Les lectures changent en premier, avec un fallback sur l'ancien source tant que le backfill n'est pas terminé.
Exemple : si vous scindez users.full_name en first_name et last_name, ne supprimez pas encore full_name. Ajoutez les nouvelles colonnes, laissez la nouvelle app écrire les trois, et gardez les lectures anciennes pointées sur full_name jusqu'à ce que vous soyez sûr.
Étape par étape : le workflow expand-contract
Les changements sans interruption fonctionnent mieux quand vous planifiez un état temporaire « intermédiaire ». Ce pont permet à l'ancien et au nouveau code de coexister pendant que vous déplacez les données.
Expand : ajoutez de nouveaux chemins sans casser les anciens
Choisissez le modèle cible, puis concevez un modèle‑pont qui peut représenter les deux versions (souvent anciennes colonnes + nouvelles colonnes).
Étendez le schéma en sécurité : ajoutez d'abord colonnes ou tables, conservez les champs anciens, et rendez les nouveaux champs nullable ou donnez‑leur des valeurs par défaut sûres. Si vous avez besoin d'index, ajoutez‑les de manière à ne pas bloquer les écritures.
Déployez du code dual‑compatible : publiez un code capable de lire à la fois les anciens et nouveaux emplacements et d'écrire de manière à garder les données cohérentes.
Migrer et basculer : déplacez les données, puis changez le trafic
Backfilllez les données par petits lots. Faites le job redémarrable et sûr à exécuter plusieurs fois.
Basculez les lectures avant les écritures. Les lectures sont plus faciles à observer et à revenir en arrière car elles ne modifient pas les données. Quand les lectures sont stables, déplacez les écritures par phases (souvent via dual‑write), puis retirez le fallback.
Contractez seulement après vérification. Définissez la « vérification » à l'avance (nombre de lignes identique, contrôles ponctuels validés, taux d'erreur et latence normaux).
Comment migrer les données progressivement sans casser les écritures
L'approche la plus sûre est de backfiller les lignes existantes pendant que votre appli sert du trafic. L'important est de faire de petits lots et de garantir que les nouvelles écritures ne manquent pas la nouvelle forme.
Exécutez le backfill en lots assez petits pour finir rapidement, avec de courtes pauses entre les lots afin que le trafic normal reste fluide.
Suivez la progression pour pouvoir reprendre : un timestamp migrated_at, un flag boolean, ou un marqueur « last processed id ». Ajoutez une requête « combien restent‑il » pour savoir si vous avancez réellement.
Pendant que le backfill tourne, de nouvelles lignes arrivent. Gérez‑ça en faisant que l'application écrive les nouveaux champs pour toutes les lignes nouvelles ou mises à jour. Si vous ne pouvez pas le faire partout immédiatement, utilisez le dual‑write pour une courte période, puis lisez depuis les nouveaux champs avec fallback sur l'ancien.
Rendez le job idempotent. Il doit être sûr de s'exécuter deux fois sur la même ligne :
- Mettre à jour seulement les lignes qui ne sont pas encore migrées
- Utiliser des transformations déterministes (même entrée = même sortie)
- Éviter les mises à jour de type append qui dupliquent les données
- Logger les échecs par ligne et continuer au lieu d'arrêter tout le job
Inventoriez aussi chaque writer, pas seulement l'API principale : workers, webhooks, outils d'admin, imports et scripts. Un writer manqué peut annuler silencieusement votre plan.
Stratégie de déploiement : garder l'ancien code opérationnel pendant le changement
Supposez que les anciennes et nouvelles formes de données existeront en même temps. Déployez du code qui peut lire les deux et qui ne plante pas quand un champ est manquant, dupliqué ou pas entièrement backfillé.
Un switch contrôlé (feature flag ou config) vous aide à changer le comportement par petites étapes. Une séquence de déploiement simple :
- Déployez du code qui peut lire anciennes et nouvelles colonnes (ou tables).
- Activez les nouvelles lectures pour une petite tranche (un environnement, un locataire, ou un petit pourcentage de trafic).
- Surveillez le taux d'erreur et les requêtes lentes, puis élargissez.
- Quand les lectures sont stables, commencez le dual‑write ou basculez les écritures en phases.
- Gardez l'ancien chemin disponible tant que la migration n'est pas sûre.
Le rollback doit être banal. Idéalement, vous pouvez revenir les lectures à l'ancienne source et arrêter les nouvelles écritures sans perte de données. Avec le dual‑write, rollback signifie souvent continuer à écrire l'ancienne forme pendant que vous enquêtez.
Avant de contracter (supprimer colonnes ou tables), recherchez des signaux de stabilité : pas de NULL inattendus dans les nouveaux champs, comptages de lignes cohérents, backlog de migration qui n'augmente pas, et volume de support normal.
Erreurs courantes qui créent des interruptions
La plupart des pannes pendant expand-contract proviennent de deux problèmes : la base se retrouve bloquée, ou différentes parties de l'app ne sont pas d'accord sur la signification des données.
Les erreurs les plus dangereuses :
- Verrous longs. Changer le type d'une colonne sur une grosse table ou ajouter un index de la manière « simple » peut bloquer reads ou writes pendant des minutes.
- Dérive silencieuse pendant le dual‑write. Manquer un chemin d'écriture et les anciennes et nouvelles formes divergent. Les utilisateurs voient des échecs "aléatoires".
- Renommages qui cassent tout le reste. L'app peut fonctionner alors que les exports, dashboards et scripts ad‑hoc commencent à échouer.
- Oublier les chemins hors requêtes. Cron jobs, workers, panneaux admin et scripts ont besoin du même plan de compatibilité.
- Contracter trop tôt. Supprimer l'ancienne colonne trop tôt et vous perdez votre option de rollback.
Un exemple simple : vous basculez les lectures sur profile_json, mais un worker d'email utilise encore last_name et commence à envoyer des « Bonjour , » aux utilisateurs. Pas d'interruption, mais un incident en production.
Checklist rapide avant, pendant et après le changement
Les changements sans interruption échouent pour des raisons banales : la table est plus grosse que prévu, un pic de trafic arrive, ou un chemin de code attend encore l'ancien schéma.
Avant de commencer, confirmez le périmètre et le timing (taille de la table, churn, fenêtre de faible charge) et confirmez la compatibilité (anciennes et nouvelles versions peuvent tourner en sécurité).
Pendant le déploiement, surveillez l'app (taux d'erreur, latence) et la base (CPU, verrous, retard de réplication, requêtes lentes). Ralentissez ou mettez en pause le backfill si les timeouts augmentent.
Après coup, prouvez qu'il est sûr de contracter : plus aucune lecture/écriture n'utilise l'ancien schéma, les dashboards restent propres pendant un cycle métier complet, et les flags temporaires sont retirés.
Une manière pratique de dénicher des dépendances cachées : en staging, faites temporairement renvoyer NULL pour les anciennes colonnes et exécutez les flux normaux (inscription, checkout, modification de profil). Si quelque chose casse, vous n'êtes pas prêt à supprimer les pièces legacy.
Exemple : changer le schéma du profil utilisateur sans interruption
Supposons que votre table users ait une seule colonne name ("Ada Lovelace"), mais que vous ayez maintenant besoin de first_name et last_name pour la recherche, le tri et les emails personnalisés.
Expand
Ajoutez first_name et last_name comme colonnes nullable. Conservez name. N'ajoutez pas encore NOT NULL.
Mettez à jour l'app pour que chaque écriture remplisse les deux : elle continue de remplir name, et elle remplit aussi first_name et last_name. Les lectures peuvent continuer d'utiliser name pour l'instant.
Migrer et déployer
Backfilllez les lignes existantes avec un job en arrière‑plan. Restez simple : coupez au premier espace, et pour les cas compliqués ("Prince", "Mary Jane Watson-Parker"), faites au mieux pour first_name et laissez last_name vide.
Une séquence pratique :
- Déploy 1 : ajoutez
first_name,last_name - Déploy 2 : dual‑write (mettre à jour anciens et nouveaux champs)
- Backfill : migrer les users existants par lots
- Déploy 3 : lire
first_name/last_nameen priorité, fallback surname - Vérifier : confirmer que les nouveaux champs sont remplis pour les utilisateurs actifs et les nouvelles inscriptions
Quand le nouveau code est stable, basculez l'UI et les exports pour utiliser les nouveaux champs (avec un fallback sûr pour le nom affiché).
Contract
Après avoir confirmé que rien ne dépend plus de name (y compris scripts et workers), arrêtez d'écrire dedans et supprimez la colonne dans une release ultérieure.
Phase de contract : nettoyer en sécurité et éviter la complexité persistante
La phase de contract supprime l'échafaudage temporaire qui rendait le changement sûr. L'ignorer vous laisse une complexité permanente et les migrations futures deviennent plus risquées.
« Fini » signifie que l'ancien schéma est réellement inutilisé. Une définition d'équipe simple :
- Aucun code d'app ne lit ni n'écrit les anciennes colonnes ou tables
- Aucun worker, cron ou script ne les référence
- Aucune logique de dual‑write ne reste
- Aucun feature flag n'existe uniquement pour supporter l'ancien chemin
- La surveillance montre que seul le nouveau chemin est utilisé
Avant de supprimer quoi que ce soit, faites un balayage ciblé : recherchez les anciens noms dans la base de code, révisez les jobs planifiés, vérifiez les logs de requêtes pour des lectures sur les objets anciens, et confirmez que dashboards et runbooks ne réfèrent plus aux champs legacy.
Après la suppression, supprimez aussi les aides : scripts de backfill, métriques temporaires et validations spéciales qui existaient uniquement pendant la transition.
Consignez ce qui a changé et pourquoi : ancien vs nouveau schéma, comment les données ont été déplacées, et quand vous avez déclaré l'ancien chemin mort. La prochaine fois, vous irez plus vite.
Prochaines étapes : planifiez votre changement et demandez un second avis
Expand-contract vaut le coup quand un changement de schéma touche une table chaude, l'authentification, les paiements ou tout ce que votre appli écrit toute la journée. Si vous ne pouvez pas vous permettre même une courte fenêtre de maintenance, traitez‑le comme une release, pas comme une « petite migration ». Pour des outils internes à faible trafic ou des tables de reporting ponctuelles, une fenêtre planifiée peut suffire.
Pour estimer le risque, regardez le blast radius et la réversibilité. Le blast radius, c'est combien de chemins de code lisent ou écrivent les données (incluant jobs et outils d'admin). La réversibilité, c'est si vous pouvez rollbackper l'app et continuer à travailler avec la base.
Si votre projet a commencé comme un prototype généré par l'IA, les migrations cassent souvent pour des raisons prévisibles : SQL brut caché, writers en arrière‑plan manqués, logique de dual‑write à moitié finie et hypothèses de schéma éparpillées dans la base de code. Si vous avez besoin d'aide pour démêler cela avant un changement en production, FixMyMess (fixmymess.ai) peut revoir le code et le plan de migration et pointer les points risqués qui causent habituellement des pannes.
Questions Fréquentes
Pourquoi les migrations de base de données cassent-elles la production même quand le changement semble petit ?
Parce que votre flotte se met rarement à jour en une seule fois. Pendant un certain temps, l'ancien code et le nouveau s'exécutent côte à côte ; si l'une des versions attend une colonne, une table ou une contrainte qui n'existe plus (ou qui a déjà été supprimée), les requêtes commencent à échouer ou à écrire des données au mauvais format.
Que signifie « compatible vers l'arrière » pour un changement de base de données ?
Cela signifie que vous pouvez modifier le schéma pendant que l'ancien code tourne encore sans provoquer de crashs ni de données corrompues. Concrètement, on évite de supprimer ou de changer la signification de quoi que ce soit dont l'ancien code dépend tant que le nouveau chemin n'est pas entièrement actif et stable.
Qu'est-ce que l'approche expand-contract en termes simples ?
Expand-contract est un mode de déploiement plus sûr : vous ajoutez d'abord les nouveaux éléments du schéma, puis vous migrez les données progressivement pendant que les anciens et les nouveaux chemins coexistent, et seulement ensuite vous supprimez les éléments anciens. Cela réduit le risque d'un "big bang" qui ferait tout tomber.
Que dois‑je faire en premier dans la phase d'expansion ?
Commencez par ajouter de nouvelles colonnes ou tables sans toucher aux éléments anciens. Rendez les nouveaux champs nullable ou donnez-leur des valeurs par défaut sûres pour que les écritures existantes ne cassent pas, et déployez du code qui ne plante pas si les nouveaux champs sont absents ou vides.
Quand est‑il sûr de supprimer une colonne ou une table ancienne ?
Supprimer ou renommer des colonnes que l'ancien code lit est la manière la plus rapide de provoquer des 500. Même si l'API principale est mise à jour, les jobs en arrière-plan, les cron, les outils d'administration et les scripts peuvent encore référencer les anciens noms pendant des heures ou des jours.
Comment migrer les données existantes sans bloquer le trafic en production ?
Lancez un backfill redémarrable qui déplace les lignes par petits lots et peut être relancé sans risque. En parallèle, assurez-vous que les nouvelles écritures remplissent la nouvelle forme (souvent via un dual-write ou une couche de compatibilité) pour ne pas vous retrouver avec une cible mouvante qui n'aboutit jamais.
Qu'est‑ce que le dual‑write, et quand faut‑il l'utiliser ?
C'est quand le nouveau code écrit à la fois les représentations ancienne et nouvelle pendant la transition. Utile pour la sécurité et le rollback, mais cela peut créer une dérive si vous manquez une voie d'écriture ; il faut donc inventorier tous les writers et garder la transformation déterministe.
Dois‑je changer d'abord les lectures ou les écritures pendant le déploiement ?
Switcher d'abord les lectures, parce que vous pouvez observer les erreurs et revenir en arrière sans modifier les données. Une fois les lectures stables et le backfill majoritairement terminé, changez les écritures par étapes contrôlées, et ne supprimez le fallback qu'après vérification que le nouveau chemin est correct de façon constante.
Que devrais‑je surveiller pour détecter rapidement les problèmes ?
Surveillez les verrous de base de données, les requêtes lentes et le retard de réplication lors des changements de schéma et d'index, et regardez le taux d'erreur et la latence de l'application pendant le déploiement. Si les timeouts augmentent, ralentissez ou mettez en pause le backfill et ajustez la taille des lots ou le plan de requête avant de reprendre.
Comment FixMyMess peut‑il aider si mon appli générée par l'IA casse pendant les migrations ?
Si votre codebase a été générée par des outils comme Lovable, Bolt, v0, Cursor ou Replit, les hypothèses de schéma peuvent être dispersées dans du SQL brut, des jobs et des migrations à moitié terminées. FixMyMess peut réaliser un audit de code gratuit pour trouver les writers à risque, l'auth cassée, les secrets exposés et les dangers de migration, puis aider à déployer un expand-contract sûr rapidement.