Boundaries d'erreur Next.js avec action « Réessayer » pour permettre la récupération des utilisateurs
Apprenez à créer des boundaries d'erreur Next.js avec une action « Réessayer » qui affiche un message clair, capture le contexte pour le support, et aide les utilisateurs à se rétablir au lieu d'afficher un écran blanc.
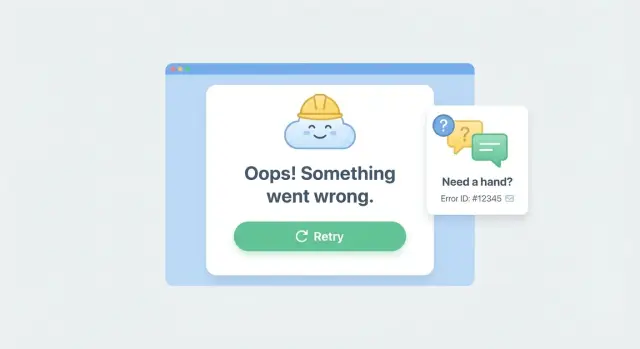
Pourquoi les écrans blancs font fuir les utilisateurs (et la confiance)
Quand une application plante et affiche un écran blanc, la plupart des gens pensent qu'ils ont fait une erreur. Ils cliquent sur Retour, rafraîchissent ou ferment l'onglet, et ils ne reviennent généralement pas.
Le vrai dommage n'est pas l'erreur elle‑même. C'est l'incertitude : « Mon travail a‑t‑il été enregistré ? », « Mon compte est‑il cassé ? », « Est‑ce sûr d'utiliser ceci ? » Une panne silencieuse apprend aux utilisateurs à ne plus faire confiance à chaque bouton.
Les écrans blancs cachent aussi ce qui compte le plus dans l'instant : la prochaine étape. Si le paiement plante, l'utilisateur a besoin d'un moyen de réessayer. Si l'envoi d'un formulaire échoue, il doit savoir si l'action a été prise et comment éviter de tout retaper.
La récupération compte plus qu'une formulation parfaite parce que les gens essaient d'accomplir une tâche, pas de lire une explication. Une bonne expérience d'erreur garde l'app utilisable quand c'est possible. Quand ce n'est pas possible, elle guide l'utilisateur vers la meilleure action suivante.
Un objectif pratique pour une UI de secours :
- Expliquer en langage clair ce qui s'est passé
- Proposer une action claire (Réessayer, Recharger, Retour)
- Protéger leur travail (conserver l'état du formulaire si possible)
- Fournir un moyen d'obtenir de l'aide (avec un code de référence)
C'est pourquoi les boundaries d'erreur avec une action Réessayer sont si efficaces : elles transforment une impasse en détour. Même un simple bouton « Réessayer » peut sauver une session quand le plantage est dû à un réseau temporaire ou à une API instable.
Parfois afficher un écran d'erreur utile vaut mieux que de masquer les échecs. Si votre app casse en production, faire comme si de rien n'était ne fait que gaspiller le temps des utilisateurs. Un écran de récupération clair rend un signal vague comme « ça a cessé de fonctionner » exploitable.
Ce que font réellement les boundaries d'erreur React et Next.js
Une boundary d'erreur est un filet de sécurité pour votre UI. Quand un composant plante pendant le rendu (ou dans une méthode de cycle de vie), la boundary peut attraper ce plantage et afficher un écran de secours au lieu de faire tomber toute la page.
En termes simples, elle attrape les problèmes qui surviennent pendant que React essaie d'afficher l'écran. Elle ne capture pas les erreurs dans les handlers d'événements (comme un clic), les erreurs asynchrones qui s'exécutent plus tard (comme une promesse fetch), ni les problèmes hors de React (comme une extension de navigateur qui casse des choses). Ceux‑ci nécessitent leur propre gestion.
Dans Next.js, cela aide aussi à séparer les pannes client et serveur.
Les erreurs client sont des plantages dans le code qui s'exécute dans le navigateur de l'utilisateur (un composant cassé, un état incorrect, une forme de données inattendue). Les erreurs serveur surviennent pendant que Next.js construit la page côté serveur (une requête DB qui échoue, une API qui timeoute, des vérifications d'auth qui lèvent une exception).
Une bonne UI de secours doit aider une vraie personne à accomplir la suite :
- Dire ce qui s'est passé en mots simples (pas de stack traces)
- Proposer une action comme Réessayer ou Recharger
- Garder le reste de la page utilisable quand c'est possible
- Fournir un petit code d'assistance que quelqu'un peut partager
Le plus grand bénéfice est de réduire le rayon d'impact. Au lieu qu'un seul widget casse tout le checkout, seul ce widget échoue pendant que le panier, la navigation et les champs de formulaire restent actifs.
Le pattern « recovery‑first » : message + action + contexte
Une bonne boundary d'erreur n'est pas seulement un attrape‑crash. C'est un écran de récupération qui aide quelqu'un à finir sa tâche. L'objectif est de réduire la panique, proposer une étape sûre, et capturer assez de détails pour corriger la cause racine.
Un fallback orienté récupération comporte trois ingrédients : un message clair, une action sûre que l'utilisateur peut entreprendre immédiatement, et une petite pièce de contexte qu'il peut partager avec le support (comme un ID de référence).
Commencez par l'action, pas par des excuses. Si une section de la page échoue, laissez l'utilisateur réessayer uniquement cette section. Si toute la route a échoué, proposez Recharger la page ou Retour. Maintenez des actions à faible risque : elles ne doivent pas supprimer de données ni répéter accidentellement un achat.
Pour le message, dites ce que l'utilisateur doit savoir, pas ce que le code sait. Évitez les stack traces, les noms de composants ou « TypeError: undefined is not a function ». Un message plus utile est : « Nous n'avons pas pu charger vos projets. Vos modifications sont enregistrées. Essayez à nouveau. »
Ajoutez ensuite du contexte qui transforme un rapport vague en quelque chose de débogable. Affichez un court ID de référence comme ERR-7F3A2C et un horodatage. Si vous consignez cet ID, le support peut retrouver rapidement l'erreur correspondante.
Planifiez vos boundaries avant d'écrire du code
Les boundaries fonctionnent mieux quand vous les traitez comme une partie du design produit, pas comme un patch de dernière minute. Avant d'ajouter des composants, décidez ce que « récupérer » signifie pour chaque partie de l'app.
Commencez par cartographier où les pannes doivent être contenues. Une boundary au niveau page est utile quand toute la route dépend d'une seule requête ou d'un layout critique. Des boundaries plus petites, au niveau composant, fonctionnent mieux quand vous pouvez maintenir le reste de la page utilisable (par exemple, la barre latérale charge mais le fil d'actualité échoue).
Une règle rapide de placement :
- Mettez une boundary au niveau page/route pour les flux critiques comme le checkout, la connexion ou l'enregistrement des paramètres.
- Mettez une boundary autour de widgets optionnels comme recommandations, graphiques ou commentaires.
- Ajoutez une boundary autour d'intégrations risquées comme des SDK tiers, éditeurs embarqués et uploads de fichiers.
- Évitez d'envelopper chaque petit composant. Cela rend les erreurs plus difficiles à comprendre.
Ensuite, définissez ce que Réessayer fait réellement. Réessayer doit être prévisible : rerendre le segment, refetcher des données, ou réinitialiser une tranche d'état spécifique. Si Réessayer ne fait que rejouer le même état cassé, les utilisateurs vont spammer le bouton et rester bloqués.
Rendez le comportement explicite avec une règle simple : « Réessayer réinitialise X et refetch Y. » Par exemple, si « Enregistrer le profil » échoue, réessayer doit relancer la requête d'enregistrement et réactiver le formulaire, pas effacer ce que l'utilisateur a tapé.
Enfin, décidez quel contexte vous capturez pour le support, et ce que vous ne montrerez jamais. Un contexte utile peut être aussi simple que le nom de route/écran, ce que l'utilisateur a cliqué, l'horodatage et l'environnement (prod vs staging), et un court code d'erreur. Gardez des lignes rouges strictes : n'incluez jamais de secrets, tokens, corps de requête complets ou données personnelles dans l'UI.
Étape par étape : ajouter des boundaries d'erreur avec Réessayer dans Next.js
Une bonne boundary d'erreur fait deux choses : elle dit à l'utilisateur ce qui s'est passé en termes simples, et elle lui donne une étape claire suivante (Réessayer ou revenir en arrière). Voici deux manières pratiques de l'ajouter.
App Router : error.tsx + reset()
Dans l'App Router, ajoutez un fichier error.tsx dans le segment de route que vous voulez protéger. Next.js l'affichera quand quelque chose dans ce segment lèvera.
'use client'
export default function Error({
error,
reset,
}: {
error: Error & { digest?: string }
reset: () => void
}) {
return (
<div style={{ padding: 16 }}>
<h2>Something went wrong</h2>
<p>Try again. If it keeps happening, you can go back to a stable page.</p>
<div style={{ display: 'flex', gap: 8, marginTop: 12 }}>
<button onClick={() => reset()}>Retry</button>
<button onClick={() => (window.location.href = '/')}>Go to Home</button>
</div>
<p style={{ marginTop: 12, fontSize: 12, opacity: 0.8 }}>
Error code: {error.digest ?? 'unknown'}
</p>
</div>
)
}
Utilisez des libellés conviviaux. « Réessayer » est plus clair que « Reset boundary », et « Aller à l'accueil » est plus sûr que laisser quelqu'un bloqué.
Pages Router : composant ErrorBoundary réutilisable
Si vous êtes sur le Pages Router (ou si vous voulez un wrapper que vous pouvez placer autour d'un widget spécifique), utilisez un composant de classe React.
import React from 'react'
type Props = { children: React.ReactNode; fallback?: React.ReactNode }
type State = { hasError: boolean }
export class ErrorBoundary extends React.Component<Props, State> {
state: State = { hasError: false }
static getDerivedStateFromError() {
return { hasError: true }
}
retry = () => this.setState({ hasError: false })
render() {
if (this.state.hasError) {
return (
this.props.fallback ?? (
<div style={{ padding: 16 }}>
<h2>We hit a problem</h2>
<p>You can retry, or go back to a stable page.</p>
<button onClick={this.retry}>Retry</button>{' '}
<button onClick={() => (window.location.href = '/')}>Go to Home</button>
</div>
)
)
}
return this.props.children
}
}
Placez cette boundary autour de la plus petite zone risquée (un formulaire complexe, un widget de paiement, ou un panneau chargé de données) pour que le reste de la page reste utilisable.
Ajouter du contexte pour le support sans exposer de données sensibles
Quand quelque chose échoue, les utilisateurs ne veulent pas un mystère. Donnez‑leur une simple référence à partager, et capturez assez de contexte pour reproduire le problème.
Commencez par générer un ID d'erreur (une courte chaîne aléatoire ou un UUID). Affichez‑le dans l'UI de secours comme « ID d'erreur : ABC123 » et facilitez sa copie. Si l'utilisateur clique Réessayer, conservez le même ID afin de connecter la première panne à la tentative suivante dans vos logs.
Capturez un contexte léger qui répond à : où étaient‑ils, que tentaient‑ils de faire, et quand cela s'est produit ? En général, quelques champs suffisent :
- Route ou page (par exemple, /settings/billing)
- Zone fonctionnelle (Facturation, Paiement, Éditeur)
- Dernière action utilisateur (Cliqué sur « Enregistrer », Formulaire soumis)
- Horodatage et fuseau horaire
- Build/version de l'app
Envoyez ou stockez les détails de l'erreur en toute sécurité. Une bonne règle : si vous ne le colleriez pas dans une conversation publique, ne le collectez pas automatiquement. Évitez les secrets (clés API, tokens), corps de requête complets, mots de passe, détails de paiement et cookies bruts. Si vous loggez côté serveur, préférez la rédaction et les listes blanches (logger seulement les champs attendus).
Si vous ajoutez une option « Signaler » ou « Contacter le support » dans l'UI d'erreur, pré‑remplissez l'ID d'erreur et le contexte de base pour que l'utilisateur n'ait pas à tout expliquer.
Concevoir un UI de secours réellement utile
Un bon écran d'erreur doit ressembler à un atterrissage sûr, pas à une impasse. Évitez le jargon technique et évitez de blâmer l'utilisateur. « Quelque chose s'est mal passé » suffit. « Unexpected token in JSON » est du bruit.
Gardez la structure de la page familière pour qu'elle ressemble toujours à votre app. Conservez l'en‑tête, la navigation et l'espace où le contenu apparaît normalement. Quand le layout reste stable, les gens sont plus susceptibles de réessayer plutôt que de partir.
Rendez la prochaine étape évidente. Le bouton principal doit être le centre visuel de l'écran, pas un petit lien texte. Placez l'action primaire en premier, et nommez‑la en langage simple.
Un ensemble simple d'actions qui couvre la plupart des cas :
- Réessayer
- Revenir
- Recharger la page
- Contacter le support
Ajoutez une phrase courte expliquant ce qui se passe si l'on réessaye (par exemple, « Nous allons retenter le chargement de vos données »). S'il y a un risque de perte de modifications, dites‑le clairement et proposez une option plus sûre comme « Copier les détails » ou « Enregistrer le brouillon » si vous le pouvez.
L'accessibilité compte ici. Quand le fallback apparaît, déplacez le focus clavier sur le titre ou le bouton principal pour que les utilisateurs de lecteurs d'écran et clavier sachent qu'il y a du nouveau. Assurez‑vous d'un bon contraste, de cibles de toucher larges, et que Entrée/Espace activent le bouton principal.
Enfin, incluez un petit contexte non sensible qui aide le support sans effrayer l'utilisateur : un horodatage, un court code de référence, et ce qu'il essayait de faire (« Enregistrement des paramètres »).
Erreurs courantes (et comment les éviter)
Les boundaries sont là pour protéger les utilisateurs, pas pour cacher des problèmes. Un écran amical ne sert à rien si le même bug se répète. Il déplace juste la douleur vers le support.
Les plus grosses erreurs sont souvent simples.
Erreurs qui empirent discrètement
- Attraper trop large : une boundary globale peut transformer un petit widget cassé en panne de page entière. Placez les boundaries autour des fonctionnalités pour que le reste de la page fonctionne.
- Réessayer sans issue : si Réessayer échoue sans fin, les utilisateurs se sentent piégés. Après 1–2 tentatives, proposez un autre chemin (retour, rechargement ou contact support).
- Afficher le texte d'erreur brut : les stack traces et messages DB effraient les utilisateurs et peuvent divulguer des détails. Affichez un message simple et conservez l'info technique dans les logs.
- Pas d'ID d'erreur : si le support ne peut pas relier ce que l'utilisateur a vu aux logs, le diagnostic devient du tâtonnement.
- Un seul fallback pour tout : « Quelque chose s'est mal passé » partout apprend aux utilisateurs à quitter l'app. Adaptez le fallback à la fonctionnalité : sauvegarde, chargement, auth, paiements.
Comment les éviter (règles simples)
Traitez Réessayer comme un outil de récupération, pas comme un bouton de réinitialisation. Désactivez le bouton Réessayer pendant l'opération, et changez le message si ça échoue à nouveau.
Incluez du contexte pour le debug sans exposer de secrets : ID d'erreur, heure, nom de page/feature, et dernière action. Gardez hors de l'UI les tokens, emails, et payloads complets.
Testez le chemin d'échec volontairement. Coupez le réseau, forcez un 500, et confirmez que l'UI propose une étape claire et donne au support quelque chose de traçable.
Liste de contrôle rapide avant publication
Avant de déployer des boundaries avec Réessayer, passez une revue axée sur la récupération réelle de l'utilisateur. Vous voulez prouver deux choses : le fallback apparaît quand il doit apparaître, et l'utilisateur a une manière claire de reprendre ce qu'il faisait.
Provoquez une erreur contrôlée (par exemple throw dans un composant qui charge des données). Puis vérifiez :
- Le fallback s'affiche avec un message clair (sans stack trace).
- Réessayer récupère complètement ou retombe proprement avec une UI calme et cohérente.
- Un ID d'erreur s'affiche à l'utilisateur et apparaît dans les logs.
- L'UI et les logs n'incluent pas de secrets ni de données personnelles (tokens, emails, requêtes complètes, en‑têtes).
- Le flux fonctionne sur mobile et en connexion lente. Les boutons sont faciles à toucher, et Réessayer n'envoie pas de rafales de requêtes.
Assurez‑vous que Réessayer réinitialise tout état bloqué, se désactive pendant l'exécution, et affiche un court statut comme « Réessai en cours... ». Si Réessayer ne peut pas fonctionner (hors‑ligne, permissions manquantes), dites‑le et proposez une action sûre.
Un exemple réaliste : « Échec de l'enregistrement » sans perdre l'utilisateur
Un utilisateur modifie son adresse de facturation et clique Enregistrer. La requête touche un backend instable, renvoie un 500, et une partie de l'UI lance une exception. Sans boundary, la page peut planter et devenir blanche. L'utilisateur est coincé, incertain que ses modifications aient été enregistrées, et risque d'abandonner.
Avec une configuration orientée récupération, la boundary attrape le plantage et affiche un fallback qui maintient l'orientation de l'utilisateur. Le formulaire reste visible si possible (ou il se rerend avec les dernières valeurs saisies), et le message est clair : « Nous n'avons pas pu enregistrer vos modifications. » Il propose une étape évidente : Réessayer. Si Réessayer échoue encore, l'utilisateur conserve une sortie sûre comme « Retour au tableau de bord » ou « Annuler les modifications ».
Ce qui rend cela utilisable, c'est le contexte supplémentaire qui voyage avec l'erreur, sans exposition de données sensibles :
- L'utilisateur voit un message court, un bouton Réessayer, et un moyen clair de quitter la page.
- L'utilisateur voit un ID d'erreur qu'il peut copier (exemple : FM-8K2Q) pour contacter le support.
- Le support voit l'ID d'erreur plus un contexte basique : route, horodatage, version de l'app, navigateur, et la dernière action.
- Le support peut reproduire plus vite parce qu'il sait quelle requête a échoué et quel état avait l'UI, sans demander que l'utilisateur tout explique.
Prochaines étapes : déployer prudemment et demander de l'aide si c'est le bazar
Traitez les boundaries comme toute feature user‑facing : déployez en petites étapes, observez, puis étendez.
Commencez par un flux fragile où un plantage fait le plus de dégâts, comme le checkout, la connexion ou l'enregistrement. Ajoutez une boundary, vérifiez que le fallback explique la situation en termes simples, et confirmez que Réessayer fait réellement quelque chose d'utile (et ne relance pas simplement le même crash).
Avant de multiplier les boundaries, définissez une responsabilité. Quelqu'un doit revoir le texte d'erreur, les actions (Réessayer, Retour, Contacter le support) et le contexte de support pour que tout reste utile et sûr.
Si vous implémentez cela dans une base de code générée par des outils IA, attendez‑vous à des surprises : états emmêlés, flux de sauvegarde fragiles, auth cassée, secrets exposés, ou requêtes non sécurisées qui rendent « Réessayer » impossible. Si vous avez besoin d'un diagnostic rapide et d'un plan de correction pratique, FixMyMess (fixmymess.ai) se concentre sur la transformation de prototypes générés par IA en logiciels prêts pour la production, incluant diagnostic du code, réparation de la logique, durcissement de la sécurité et préparation au déploiement.
Questions Fréquentes
Pourquoi les écrans blancs font-ils partir les utilisateurs si vite ?
Un écran blanc crée de l'incertitude. Les utilisateurs ne savent pas si leur travail a été enregistré, si leur compte est cassé, ou quoi faire ensuite, donc ils partent.
Un simple écran de secours qui explique ce qui s'est passé et propose une action sûre permet aux gens de continuer au lieu d'abandonner la tâche.
Quels problèmes les boundaries d'erreur React attrapent-elles (et ne capturent-elles pas) ?
Une boundary d'erreur attrape les plantages au moment du rendu dans les composants React et affiche une interface de secours au lieu de planter toute la page.
Elle ne capture pas les erreurs dans les handlers d'événements (comme un clic), ni les rejets de promesse asynchrones survenus plus tard, ni les problèmes en dehors de React ; pour ces cas, vous avez toujours besoin de try/catch et d'un handling des requêtes.
Quand devrais-je utiliser `error.tsx` vs un composant ErrorBoundary réutilisable ?
Utilisez error.tsx dans l'App Router quand vous voulez que Next.js affiche automatiquement une UI de récupération pour un segment de route lorsqu'une exception est levée.
Utilisez un composant ErrorBoundary réutilisable quand vous voulez protéger un widget spécifique ou une partie d'une page afin que le reste de l'interface reste utilisable.
Que doit dire et faire une bonne UI de secours ?
Un bon comportement par défaut : un message simple, une action principale (généralement Réessayer), et une issue de secours (Retour ou Accueil).
Si possible, rassurez sur l'état comme « Vos modifications sont enregistrées » ou « Vous devrez peut‑être réessayer », mais ne l'affirmez que si vous en êtes sûr.
Que doit réellement faire le bouton Réessayer ?
Réessayer doit réinitialiser la partie cassée de l'UI et relancer exactement l'opération qui a échoué, comme refetcher des données ou retenter une sauvegarde.
Si Réessayer se contente de rerendre le même état cassé, les utilisateurs resteront bloqués : faites en sorte que Réessayer change quelque chose d'utile (réinitialiser une portion d'état, vider un cache, ou relancer une requête).
Comment éviter d'enfermer les utilisateurs dans une boucle sans fin de Réessayer ?
Après une ou deux tentatives infructueuses, changez l'UI de « Réessayer » à une option de sortie comme Retour, Recharger la page, ou Contacter le support.
Cela empêche les utilisateurs de spammer le bouton et leur donne un moyen clair de continuer leur travail ailleurs.
Quel contexte de support dois-je montrer aux utilisateurs quand quelque chose plante ?
Affichez une courte référence comme un ID d'erreur et un horodatage, et consignez le même ID côté serveur.
Gardez cela léger et non sensible pour que l'utilisateur puisse le copier en toute sécurité dans un message au support.
Quelles données ne doivent jamais apparaître dans l'écran d'erreur ?
Ne montrez pas de stack traces, tokens, cookies, corps de requête complets, informations de paiement, ni rien que vous ne voudriez pas voir dans une conversation publique.
Règle simple : affichez seulement un court code d'erreur et un contexte basique comme « Enregistrement des paramètres », tandis que les détails techniques restent dans des logs protégés et rédigés.
Où dois-je placer des boundaries dans une app Next.js ?
Placez les boundaries autour des zones risquées les plus petites pour qu'un widget défaillant ne fasse pas tomber tout le checkout.
Utilisez des boundaries au niveau page/route pour des flux critiques (connexion, paiement) et au niveau composant pour des panneaux optionnels (graphiques, commentaires, embeds tiers).
Comment tester les boundaries d'erreur avant de les déployer ?
Forcer des échecs volontairement : throw dans un composant, simuler une réponse 500, et tester le mode hors‑ligne pour voir l'expérience utilisateur.
Vérifiez que le fallback s'affiche, que Réessayer n'envoie pas une rafale de requêtes, et que l'ID d'erreur concorde avec ce que vous loggez, sans fuite de secrets.