Observabilité des gestionnaires de webhooks : logs, IDs d'événements, vue d'administration
Les webhooks échouent en silence sans la bonne visibilité. Découvrez l’observabilité des handlers webhook avec logs de vérification de signature, stockage des event IDs et une petite vue admin.
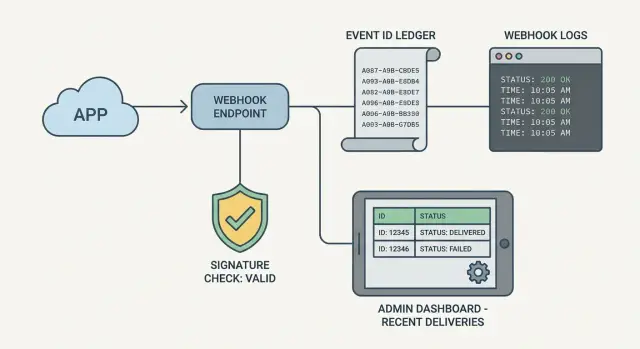
Pourquoi les handlers webhook donnent l’impression d’être invisibles quand ils tombent en panne
Les webhooks sont plus difficiles à déboguer que des appels API classiques parce que ce n’est pas vous qui cliquez sur le bouton qui envoie la requête. Un fournisseur envoie un événement quand il veut, depuis une infrastructure que vous ne contrôlez pas, et vous découvrez souvent qu’il y a un problème seulement après la plainte d’un client.
Avec un endpoint API typique, vous pouvez reproduire l’appel, regarder la réponse et itérer. Avec les webhooks, l’échec peut être silencieux : le fournisseur réessaie en arrière-plan, votre appli renvoie un 500 générique, et vous devez deviner si la requête était authentique, si votre code a tourné, et où ça s’est arrêté.
La partie la plus frustrante est le trou une fois que les retries commencent. Vous pouvez voir un pic de trafic, puis rien d’utile : pas d’identifiant d’événement clair, aucune trace de ce qui s’est passé à chaque tentative, et aucun enregistrement indiquant si vous l’avez déjà traité. C’est comme ça qu’on finit par facturer deux fois, rater une mise à jour d’abonnement ou créer des enregistrements en double.
L’observabilité d’un handler webhook, c’est simplement pouvoir répondre à quelques questions rapidement, sans lire des payloads bruts ni activer un mode debug bruyant :
- Qui a envoyé cette requête, et a-t-elle passé la vérification de signature ?
- Quel était l’événement (ID, type, horodatage), et l’avons-nous déjà vu ?
- Qu’a fait notre handler, et pourquoi il a échoué (si c’est le cas) ?
Une bonne observabilité reste petite, sûre et facile à maintenir. Vous n’avez pas besoin d’un système de monitoring complexe. Quelques logs structurés, un event ID stocké et une petite vue d’administration peuvent transformer un webhook invisible en quelque chose que vous comprenez en minutes.
Que signifie « observable » pour un endpoint webhook
« Observable » signifie que lorsqu’une livraison échoue (ou semble correcte mais produit un mauvais résultat), vous pouvez répondre à ce qui s’est passé sans deviner, renvoyer aveuglément, ou ajouter des print statements ponctuels.
Pour chaque livraison, vous devriez pouvoir répondre :
- Avons-nous reçu la requête, et quand ?
- La vérification de signature a-t-elle réussi ou échoué, et pourquoi ?
- Quel était l’événement (event ID), et l’avons-nous déjà traité ?
- Combien de temps a pris le traitement, et où le temps a-t-il été passé ?
- Qu’avons-nous renvoyé à l’expéditeur (code de statut et type d’erreur) ?
C’est le cœur : une trace claire de « arrivé » à « terminé », avec assez de contexte pour déboguer retries, doublons et échecs partiels.
Une bonne base consiste à capturer un petit ensemble d’en-têtes de requête (pas tous), le résultat du contrôle de signature (passé/échoué avec une courte raison), un identifiant d’événement stable, des timestamps (reçu/début/fin) et un résultat final (traité, ignoré comme doublon, rejeté comme invalide).
Faites attention à la vie privée. Ne loggez pas de secrets, de signatures brutes, de tokens d’auth ou de payloads complets par défaut. Si vous avez besoin de visibilité sur le payload, stockez un snapshot minimal et rédigé (par exemple : type d’événement, hash de l’ID client, montant) et conservez tout body brut seulement pour un débogage de courte durée dans un emplacement protégé.
Si les payloads peuvent contenir des données personnelles (noms, emails, adresses, données de santé ou financières), traitez les logs webhook comme des données utilisateur. Fixez des durées de conservation, restreignez l’accès et documentez qui peut les consulter. C’est souvent la différence entre « logs utiles » et un incident de conformité.
Logger les vérifications de signature sans fuir de secrets
La vérification de signature est le test « êtes-vous vraiment qui vous dites être ? » de votre webhook. Elle empêche des appels aléatoires de toucher votre endpoint en prétendant être votre fournisseur de paiement, service d’email, ou tout autre système.
Pour l’observabilité, vous voulez assez de détails pour répondre à deux choses rapidement : la vérification a-t-elle été exécutée, et pourquoi a-t-elle échoué ? L’astuce est de logger les résultats et le contexte, pas le matériel secret.
Un schéma sûr est une entrée de vérification par requête, avec des champs utiles pour le support et le débogage mais innocents si on les copie dans un ticket.
Logger des éléments tels que :
- Résultat :
verified=true/falseet unereasonclaire commemissing_signature,bad_format,timestamp_out_of_windowoumismatch - Ce que vous attendiez : le nom de l’algorithme (par exemple
hmac-sha256) et quel header vous avez vérifié (nom de header seulement) - Contexte temporel : timestamp serveur, âge de la requête (secondes) et si une protection contre la relecture a été appliquée
- Identifiants : votre
request_idgénéré et, si présent, l’event ID du fournisseur
Ne loggez pas la clé secrète, la valeur brute de la signature, le payload complet ou des en-têtes non rédigés.
Quand la vérification échoue, évitez le logging « dump the request ». Au lieu de cela, loggez un petit résumé rédigé : taille du payload, content-type, et quels headers requis étaient présents.
Ajoutez des compteurs simples pour que les échecs apparaissent même quand personne ne surveille les logs. Au minimum, suivez les totaux pour verified, failed et missing signature (optionnellement ventilés par provider). Si un déploiement change accidentellement le nom d’en-tête attendu, vos logs devraient montrer un pic reason=missing_signature plutôt qu’un 401 vague sans explication.
Stocker les event IDs pour dédupliquer et tracer les retries
La plupart des fournisseurs de webhook réessaient le même événement si votre endpoint timeout, renvoie un 500 ou subit un problème réseau. Si vous ne stockez pas un identifiant d’événement stable, vous pouvez facturer deux fois, provisionner deux fois ou envoyer des emails en double. Sauvegarder l’event ID est le chemin le plus simple vers l’idempotence : le même événement peut vous arriver 1 fois ou 10 fois, mais vous n’appliquez ses effets qu’une seule fois.
Commencez par stocker un petit enregistrement pour chaque webhook entrant, même si vous ne faites rien d’autre pour l’instant. Vous pouvez le garder dans une table de base de données, un key-value store, ou une queue plus une petite table d’audit.
Un enregistrement minimal inclut généralement provider, event ID, timestamp de réception, statut (received/processed/failed/ignored) et un court message d’erreur optionnel.
Ensuite, pour chaque requête, faites ceci dans l’ordre : extrayez l’event ID, insérez-le avec une contrainte d’unicité sur (provider, event ID), et si l’insert échoue parce qu’il existe déjà, renvoyez rapidement 200 et sautez l’action métier. Cette simple vérification transforme les retries de conjectures en une timeline fiable.
Certains providers n’envoient pas d’event ID clair, ou votre handler ne peut pas le lire avant la vérification de signature. Dans ce cas, dérivez-en un vous-même à partir de parties stables de la requête, comme un hash de provider + request path + un header stable + les octets du body. Évitez les timestamps ou tout ce qui change entre les retries.
La rétention importe parce que les payloads webhook contiennent souvent des données personnelles. Une règle pratique : conservez les résumés plus longtemps et les données brutes moins longtemps (ou pas du tout). Gardez la ligne d’événement (provider, event ID, timestamps, statut) 30 à 90 jours, conservez tout body brut pour une fenêtre courte (24 à 72 heures) si vous le stockez, et limitez la longueur des messages d’erreur pour réduire le risque de fuite de secrets.
Exemple : un fournisseur de paiement réessaie trois fois le même événement invoice.paid. Avec les event IDs stockés, vous voyez une ligne marquée processed et les livraisons suivantes marquées duplicate, donc vous savez que le client n’a pas été facturé deux fois et pourquoi le provider continuait d’essayer.
Enregistrer le cycle de vie : de reçu à traité à répondu
Un webhook peut sembler « OK » parce que l’émetteur a reçu un 200, alors que votre appli a échoué après coup. Pour rendre l’observabilité réelle, séparez la réception (ce que vous renvoyez à l’expéditeur) du traitement métier (ce que votre appli a réellement fait).
Quand c’est possible, acquittez rapidement, puis faites le travail lourd en arrière-plan. Même si vous traitez en ligne, enregistrez les deux parties comme des étapes distinctes afin de pouvoir dire si le problème vient de la vérification, du parsing, du travail DB ou d’un timeout.
Un modèle de cycle de vie simple que vous pouvez interroger
Choisissez un petit ensemble d’états et tenez-vous-y. Le but n’est pas le détail parfait, mais des réponses rapides.
Enregistrez une ligne (ou document) par événement entrant avec :
- Timestamps : received, verified, processing started, processing finished, responded
- Durées : temps de vérification, temps de traitement, temps total
- État : received, verified, processed, failed, ignored
- Réponse : code de statut, version du handler (optionnelle), classe d’erreur (sans secrets)
- Corrélation : event ID du provider plus votre propre correlation ID
Avec cela, les schémas apparaissent vite. Si la plupart des échecs arrivent après vérification et prennent 25 secondes, vous regardez probablement un appel DB lent, un worker de queue bloqué ou un index manquant.
Les correlation IDs relient le webhook au reste du système
Un webhook s’arrête rarement à l’endpoint. Il crée un utilisateur, marque une facture payée, envoie un reçu, ou met à jour des droits.
Conservez l’event ID du provider et générez une correlation ID que vous injectez dans les logs et les jobs en aval. Une seule recherche peut alors montrer la chaîne : requête reçue, signature vérifiée, job enqueued, paiement marqué payé, email envoyé.
Cela compte beaucoup dans des bases de code où le handler mélange « répondre au webhook » et « faire tout le travail » dans une seule fonction. Rendre le cycle de vie explicite transforme un mystère en une timeline.
Étape par étape : ajouter de l’observabilité à un handler existant
Chaque requête webhook devrait laisser une piste que vous pouvez suivre plus tard, même si elle échoue en cours de route.
Un ordre pratique qui fonctionne bien sur un endpoint existant :
- Ajoutez des logs structurés avec un ensemble de champs cohérent sur chaque requête (provider, event ID, request ID, signature checked, outcome, duration).
- Vérifiez la signature tôt, puis loggez seulement le résultat (pass/fail) et pourquoi ça a échoué. Ne loggez jamais la clé secrète ou la signature brute.
- Persistez l’event ID du provider dès que vous l’avez et faites de la déduplication dessus. Si c’est un retry, renvoyez une réponse sûre et enregistrez qu’il a été deduped.
- Enrobez la logique métier pour toujours capturer le statut, la classe d’erreur et les temps, même quand une exception est levée.
- Ajoutez une petite vue admin qui montre les événements webhook récents et les détails nécessaires pour répondre à « que s’est-il passé ? »
Après la première étape, gardez le schéma des logs stable. Quand les champs changent chaque semaine, la recherche devient du guessing. Si possible, générez un request ID à la périphérie et transportez-le dans les logs et l’enregistrement d’événement.
Pour les messages d’échec de signature, rendez-les humains et exploitables. « Signature failed: missing header X » est actionnable. « Invalid signature » ne l’est pas. C’est aussi un endroit où les équipes fuguent des données sensibles par erreur, donc soyez stricts sur ce que vous enregistrez.
Pour la vue admin, vous n’avez pas besoin d’un tableau complet. Une table des 50 derniers événements et une page de détail suffisent. La page détail doit montrer l’heure reçue, l’event ID, le statut de traitement, le code de réponse, la durée et la dernière classe d’erreur (par exemple : ValidationError vs DatabaseError).
Une petite vue admin qui répond à « que s’est-il passé ? »
Vous n’avez pas besoin d’un dashboard complet pour déboguer les webhooks. La plus petite vue utile est un écran avec une table d’événements récents et un panneau de détail. Lorsqu’on vous demande pourquoi un paiement, un enregistrement ou une expédition n’a pas été mis à jour, vous devriez pouvoir répondre en deux minutes.
Une bonne table d’événements récents montre assez pour repérer des motifs comme des retries répétés, une panne du fournisseur, ou des 500 renvoyés par votre handler. Gardez-la cohérente pour qu’elle soit facile à scanner.
Incluez :
- Event ID (ID du provider, plus votre ID interne si vous en avez un)
- Provider et type d’événement, heure de réception
- Statut (received, verified, processed, failed, ignored)
- Tentatives et heure de la dernière tentative
- Dernier message d’erreur (court, tronqué)
Dans le panneau détail, concentrez-vous sur ce dont une personne a besoin ensuite : la vérification de signature a-t-elle passé, quelle version du handler a tourné, quelle réponse a été envoyée, timestamps clés (reçu/verified/processed) et la correlation ID qui relie aux logs.
Les actions peuvent aider, mais seulement si elles sont sûres : reprocess (uniquement si votre handler est idempotent), mark ignored (pour des events test ou du bruit connu), ajouter une note interne, et copier un résumé pour le support (event ID, statut, dernière erreur).
Verrouillez cette vue aux seuls admins et loggez chaque action admin (qui l’a fait, quand, pourquoi).
Erreurs courantes qui rendent le débogage des webhooks plus difficile
Un webhook peut « fonctionner » et pourtant être impossible à comprendre quand quelque chose casse. La plupart des douleurs viennent de petits choix qui cachent la vraie défaillance ou créent des effets de bord bruyants.
Une grosse erreur est de logger les payloads bruts. Beaucoup de bodies contiennent par accident emails, adresses, tokens ou secrets. Loggez plutôt un résumé sûr : type d’événement, provider, event ID, timestamp de la requête et un court hash du body. Si vous avez besoin du détail, stockez une copie chiffrée avec une rétention courte et un accès restreint.
Les retries peuvent aussi devenir auto-infligés. Si un événement a déjà été traité, renvoyer une réponse non-2xx déclenche souvent des retries sans fin et des actions en aval en double. Faites de « déjà traité » un résultat explicite et renvoyez 2xx tout en enregistrant qu’il a été deduped.
Un autre piège courant est de mélanger les échecs de vérification et les échecs de traitement. Si la vérification de signature échoue, c’est un signal de sécurité. Si la logique métier échoue après vérification, c’est un bug applicatif ou un problème de données. Si les deux ressemblent à un « 500 error », vous perdez la capacité d’agir rapidement.
Problèmes opérationnels fréquents :
- Pas de timeout sur les appels DB ou API, donc le handler bloque jusqu’à ce que le provider abandonne
- Erreurs loggées sans nom du provider, type d’événement, event ID et request ID interne
- Ne logguer que les exceptions, pas la décision prise (ignored, queued, processed, deduped)
- Formats de logs différents entre environnements, rendant les comparaisons difficiles
Exemple : un fournisseur de paiement réessaie un événement 12 fois. Vos logs montrent 12 lignes « 500 » mais aucune indication si la signature a échoué, si la base a timeouté, ou si l’événement a déjà été traité. Avec de l’observabilité, la première entrée montrerait « verified ok », la suivante « DB timeout after 3s », et les retries suivants seraient deduped une fois l’event stocké.
Vérifications rapides avant de considérer le travail terminé
Testez l’observabilité des webhooks comme une personne stressée, fatiguée et pressée. Si vous ne pouvez pas répondre aux questions de base rapidement, le futur vous en voudra quand le provider va réessayer le même événement pendant des heures.
Commencez par un benchmark simple : prenez un event ID réel du provider et chrono en main. Vous devriez pouvoir trouver cet événement unique (et son historique de livraisons) en moins de 30 secondes, sans deviner quel serveur l’a traité.
Une courte checklist pré-vol détecte la plupart des lacunes :
- La recherche fonctionne : coller l’event ID du provider affiche un enregistrement clair, pas cinq quasi-doublons
- Le statut de signature est évident : les logs montrent vérifié oui/non, et la raison en cas d’échec
- Les retries sont visibles : nombre de tentatives et heure de la dernière tentative sont faciles à trouver
- Le type d’échec est clair : on distingue exception vs timeout vs erreur de validation
- Les données sont sûres : secrets et données personnelles sont exclues ou rédigées dans les logs et le stockage
Faites un exercice réaliste. Déclenchez un événement que vous savez échouer (par exemple, un payload manquant un champ requis). Confirmez que vous pouvez répondre : est-ce qu’il est arrivé, la vérification a-t-elle passé, qu’avons-nous renvoyé, est-ce que c’était lent, et a-t-il été réessayé ?
Enfin, scannez pour des fuites accidentelles. Les webhooks contiennent souvent emails, adresses, tokens ou métadonnées de carte. Les logs ne doivent stocker que ce dont vous avez besoin pour déboguer : event ID, nom du provider, timestamps, résultat de la signature, statut et un court message d’erreur.
Exemple : un webhook de paiement échoué et comment le tracer
Un ticket support courant ressemble à ceci : votre fournisseur de paiement envoie un webhook invoice.paid, la carte du client est débitée, mais il n’a toujours pas accès au plan payé.
Avec de l’observabilité en place, vous arrêtez de deviner. Vous ouvrez la vue admin et cherchez par plage horaire. Vous trouvez l’appel webhook exact.
Les premières questions trouvent immédiatement une réponse : la vérification de signature est « pass », l’event ID du provider est enregistré (par ex. evt_01H...) et le timestamp de la requête correspond à celui affiché par le provider. Vous savez que c’est réel et que ça a atteint votre serveur.
Dans les détails de l’événement, le cycle de vie montre :
- Received : 2026-01-20 14:03:12
- Verified : pass
- Processing : failed
- Responded : 500
Le champ d’erreur pointe la cause, par exemple « Cannot insert subscription row: missing user_id. ». Cela indique que le bug est dans votre propre code, pas chez le provider.
Ensuite les retries arrivent. Là où l’idempotence compte : comme vous stockez l’event ID et le traitez comme unique, le handler n’accorde pas l’accès deux fois. Les livraisons suivantes sont enregistrées comme duplicates et sautées, ou retraitées en toute sécurité selon votre conception.
Après avoir corrigé le bug, vous pouvez relancer le reprocessing depuis la vue admin. L’état passe à processed, la réponse devient 200, et le client obtient l’accès.
Pour le support, vous disposez désormais de faits propres à partager : l’horodatage de l’événement original, l’event ID et l’état actuel (received, verified, processed, failed).
Étapes suivantes si votre code webhook reste fragile
Si votre handler webhook ressemble encore à une boîte noire, commencez par le plus petit changement qui apporte du signal : loggez le résultat de la vérification de signature (pass ou fail) et stockez l’event ID du provider. Cela suffit souvent à transformer « ça ne marche pas » en un chemin clair vers la correction, sans toucher à la logique métier.
Gardez ces premiers logs ennuyeux et sûrs. Enregistrez des résultats et des durées, pas des secrets. Loggez que la vérification a échoué, quel provider c’était et quel event ID était inclus, mais ne loggez jamais les headers bruts ou les valeurs de signature.
Une fois que vous capturez de façon fiable les event IDs et les statuts, ajoutez une petite vue admin. Ne construisez pas tout un dashboard dès le départ. Une simple table répondant « l’avons-nous reçu, l’avons-nous vérifié, l’avons-nous traité, quelle erreur est survenue, et qu’avons-nous renvoyé ? » suffit.
Si le code webhook a été généré par un outil IA et semble peu fiable, prévoyez une passe de nettoyage. Signes fréquents : hypothèses d’auth cassées, comportement de retry désordonné (double-charges, emails en double), et secrets éparpillés dans la config ou les logs.
Un ordre de travail pratique :
- Ajouter des logs structurés pour le résultat de signature et le request ID
- Stocker les event IDs webhook et faire de la déduplication
- Enregistrer un cycle de vie clair (received, verified, processed, failed)
- Ajouter une petite vue admin pour événements récents et erreurs
- Faire un refactoring ciblé pour retries, idempotence et gestion des secrets
Si vous héritez d’un prototype IA cassé et devez le rendre production-ready, FixMyMess (fixmymess.ai) se concentre sur le diagnostic et la réparation du code généré par IA, y compris les handlers webhook avec auth instable, bugs de retry et logging dangereux.
Questions Fréquentes
Quelle est la façon la plus simple de rendre mon handler webhook observable ?
Commencez par enregistrer trois éléments sur chaque requête : si la vérification de la signature a réussi, l’event ID du fournisseur, et un résultat clair comme processed, failed ou deduped. Ajoutez les temps (reçu et terminé) pour repérer les timeouts. Cette base minimale transforme généralement un 500 mystérieux en un incident actionnable.
Pourquoi les bugs de webhook sont-ils plus difficiles à déboguer que des appels API normaux ?
Les webhooks échouent en silence parce que vous ne contrôlez ni le moment ni l’origine des envois, et les providers réessayent souvent en arrière-plan. Sans event ID stocké et logs structurés, chaque retry ressemble à une nouvelle requête : vous ne pouvez pas dire si c’est un doublon, un problème de signature ou un bug de traitement.
Que dois-je logger pour la vérification de signature sans divulguer de secrets ?
Enregistrez le résultat et la raison, pas les éléments secrets. Un bon enregistrement est verified=true/false avec une courte raison comme missing_signature ou timestamp_out_of_window, ainsi que l’en-tête vérifié et le nom de l’algorithme. Ne loggez jamais la clé de signature, la signature brute ou les en-têtes non rédigés.
Comment empêcher que les retries provoquent des doubles prélèvements ou des enregistrements doublons ?
Enregistrez l’event ID du fournisseur le plus tôt possible et appliquez une contrainte d’unicité sur (provider, event_id). Si vous l’avez déjà vu, retournez une réponse 2xx sûre et sautez l’action métier, en notant qu’il s’agissait d’un doublon. Cela évite les doubles prélèvements, la provision double ou les emails répétés pendant les retries.
Que faire si mon fournisseur de webhook n’inclut pas d’event ID fiable ?
Générez un ID dérivé stable à partir d’éléments qui ne changent pas entre retries, par exemple un hash de provider + request path + raw body bytes ou un header stable + body. Évitez d’inclure des timestamps ou tout ce qui change à chaque tentative. Traitez ensuite cet ID comme un event ID normal pour la déduplication et le traçage.
Quelles sont les données de cycle de vie à enregistrer pour savoir où ça a échoué ?
Séparez « réception de la livraison » et « traitement métier ». Enregistrez quand la requête est arrivée, quand la vérification a fini, quand le traitement a commencé et s’est terminé, et quel code de réponse vous avez renvoyé. Ainsi, il est évident quand vous avez répondu 200 mais que le travail réel a échoué après coup.
Comment logger les données de webhook sans poser un problème de confidentialité ou de conformité ?
Par défaut, conservez seulement des résumés sûrs : provider, event ID, type d’événement, timestamps, statut et un court message d’erreur qui n’inclut pas de secrets ni de données personnelles. Si vous stockez des bodies bruts, chiffrez-les, limitez l’accès et réduisez la durée de conservation. Traitez les logs de webhook comme des données utilisateur.
Que doit contenir une vue minimale d’administration pour les webhooks ?
Une table d’événements récents et une vue détail suffisent. Affichez event ID, provider, type, heure de réception, statut, nombre de tentatives/dernière tentative, résultat de la signature, code de réponse, durée et dernière classe d’erreur. Si vous proposez un bouton de reprocessing, assurez-vous que le handler est idempotent pour éviter d’appliquer les effets deux fois.
Quelles sont les erreurs les plus courantes qui compliquent le débogage des webhooks ?
Ne loggez pas le payload brut, n’enregistrez pas d’en-têtes, tokens ou signatures non rédigés. Séparez les échecs de vérification de signature des échecs de traitement. N’oubliez pas les timeouts sur les appels DB et externes. Et stockez toujours des event IDs, sinon vous perdez la capacité à voir clairement doublons et retries.
Mon code webhook a été généré par un outil IA et se casse sans arrêt—que faire ?
Si le handler a été généré par une IA et est instable, faites un audit rapide de la vérification de signature, de l’idempotence, de la gestion des secrets et de la sécurité du logging. Si vous avez besoin d’une réparation rapide, FixMyMess (fixmymess.ai) propose un diagnostic et une réparation des handlers générés par IA, renforcement de la sécurité et correction des retries, souvent en 48–72 heures après un audit de code gratuit.