Panneau admin généré par IA sécurisé : routes, journaux et sécurité
Panneau admin généré par IA sécurisé : routes verrouillées, journaux d'audit, suppressions sûres et garde-fous pour éviter qu'un seul bug n'efface vos données.
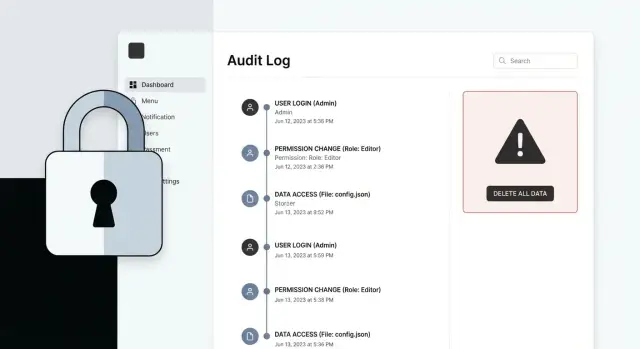
Ce qui casse généralement dans un panneau admin généré par IA
Les panneaux admin construits par l'IA ont souvent l'air terminés, mais ils tiennent rarement la route en matière de sécurité. L'interface masque les boutons, le chemin heureux fonctionne, et personne ne teste ce qui se passe quand un utilisateur curieux appelle directement l'API.
Le problème le plus fréquent est de confondre l'écran avec le système. Une page peut être étiquetée "Admin", mais le serveur répond toujours aux mêmes requêtes pour quiconque devine une URL, réutilise un ancien token ou lance un simple curl.
Voici les modes de défaillance que nous retrouvons sans cesse lors d'un audit d'un panneau admin généré par IA :
- Pages admin qui s'affichent sans véritable vérification côté serveur
- API qui font confiance aux données envoyées par le client (comme userId, orgId ou role)
- Absence de piste d'audit, on ne peut pas savoir qui a fait quoi après un incident
- Actions destructrices qui s'exécutent instantanément (delete, purge, mises à jour en masse)
- Comptes admin trop puissants utilisés pour des tâches courantes
Le risque du type « un bug efface tout » vient généralement de deux choses combinées : une requête trop large (par exemple delete all users where status = inactive) et une vérification de périmètre manquante (comme tenant ou environnement). Un petit bug dans un filtre, un WHERE manquant ou une valeur par défaut erronée peut transformer un nettoyage normal en suppression totale.
Imaginez un·e fondateur·rice utilisant une action groupée pour supprimer des comptes de test. L'UI indique "10 sélectionnés", mais le serveur ignore le tableau de sélection et exécute l'opération sur toutes les lignes correspondant à une condition lâche. Sans étape de confirmation et sans journal d'audit, le premier signe est des clients qui vous écrivent pour dire que leurs données ont disparu.
Cet article se concentre sur un durcissement pratique : verrouiller les routes côté serveur, ajouter des journaux qui répondent aux vraies questions, et mettre des garde-fous autour des actions destructrices. Si vous avez hérité d'un panneau généré par des outils comme Lovable, Bolt, v0, Cursor ou Replit, FixMyMess peut auditer rapidement les zones risquées avant qu'elles ne vous posent problème.
Définir les rôles et les rares actions qui nécessitent vraiment un accès admin
Un panneau admin sécurisé commence par une idée simple : la plupart des personnes doivent pouvoir voir plus qu'elles ne peuvent modifier. Si vous sautez cette étape, vous vous retrouvez avec un interrupteur « admin » qui octroie silencieusement le pouvoir de casser la production.
Notez les vrais métiers que votre espace admin supporte. Restez concis et précis, par exemple « réinitialiser le mot de passe d'un utilisateur », « mettre un abonnement en pause » ou « modifier le texte de la page d'accueil ». Si vous ne pouvez pas nommer la tâche, elle ne devrait probablement pas exister sous forme de bouton.
Choisir des rôles qui correspondent à des personnes réelles
Évitez les systèmes de rôles complexes. Quatre rôles couvrent la plupart des équipes :
- Propriétaire : accès total, y compris facturation et changements de rôle
- Admin : modifications quotidiennes, mais pas les contrôles réservés au propriétaire
- Support : actions d'aide aux utilisateurs avec accès en écriture limité
- Lecture seule : peut tout voir, ne peut rien modifier
Séparez ensuite les permissions en « voir » et « modifier ». Une personne support peut avoir besoin de voir des factures pour répondre à des questions, mais ne devrait pas pouvoir émettre des remboursements.
Identifier d'abord les actions « les plus dangereuses »
Marquez les actions qui peuvent causer des dommages irréversibles ou des pertes financières. Elles incluent généralement :
- Suppression de données (utilisateurs, organisations, projets, tables)
- Changement de rôles ou de propriété
- Remboursements, crédits ou changements d'abonnement
- Rotation de clés API ou modifications des paramètres d'auth
- Actions groupées (suppression en masse, désactivation en masse)
Un exemple rapide : si le support peut « désactiver un utilisateur », cela peut être acceptable. Mais si le même écran propose aussi « supprimer l'utilisateur », la différence est cruciale. Désactiver est réversible. Supprimer ne l'est pas. Traitez-les comme des permissions différentes, même si elles se trouvent côte à côte dans l'interface.
Si vous avez hérité d'un panneau généré par IA où tout est regroupé sous un seul rôle admin, c'est une découverte fréquente pour FixMyMess. Le gain le plus rapide est de réduire qui peut effectuer les 3 actions destructrices principales avant de toucher à autre chose.
Verrouiller les routes admin de façon sûre (côté serveur, pas seulement l'UI)
Un panneau admin semble souvent protégé parce que l'UI masque des boutons. Ce n'est pas de la protection. Si quelqu'un peut deviner une URL, réutiliser une vieille session ou appeler une API directement, il peut toujours atteindre des endpoints admin. Un panneau admin sécurisé commence par une règle : chaque page admin et chaque API admin doivent appliquer l'accès côté serveur.
Confirmez que chaque écran admin exige une connexion, pas seulement le tableau de bord. Les oublis fréquents concernent les pages « secondaires » comme la gestion des utilisateurs, la facturation, les feature flags, les exports, les jobs en arrière-plan et les outils internes. Si une page se charge sans vérification serveur, elle peut devenir le point d'entrée.
Mettre la vérification là où elle ne peut pas être contournée
Faites la vérification d'autorisation à un seul endroit qui s'exécute sur chaque requête pour les routes admin (middleware, gardien de route, wrapper de contrôleur, quel que soit le terme de votre stack). Ne vous fiez pas à l'état côté client comme isAdmin stocké en localStorage.
Utilisez une allowlist explicite pour les routes admin et les API admin. C'est simple et sûr : vous déclarez ce qui est admin, et tout le reste est traité comme non-admin.
- Mettez en allowlist les chemins admin (par exemple,
/admin/*) et les préfixes d'API admin (par exemple,/api/admin/*). - Exigez une session valide, puis vérifiez le rôle côté serveur.
- Refusez l'accès si le rôle manque, est périmé ou non vérifié (pas de « fallback vers utilisateur »).
- Re-vérifiez sur les actions sensibles, pas seulement au chargement de la page.
- Loggez et renvoyez une réponse claire « forbidden », pas une boucle de redirection.
Refuser par défaut pour toute nouveauté
Le code généré par IA ajoute souvent des routes rapidement et oublie de les sécuriser. Ajoutez une règle simple : toute nouvelle route sous admin ou toute nouvelle API admin doit être bloquée à moins d'être enregistrée dans l'allowlist et couverte par le guard côté serveur.
Si vous avez hérité d'un projet généré par des outils comme Bolt ou Lovable, FixMyMess trouve souvent des endpoints admin « cachés » qui n'ont jamais reçu de vraie vérification serveur. Les détecter tôt est généralement la réduction de risque la plus rapide que vous puissiez faire.
Durcir les API admin derrière l'UI
Un panneau admin n'est sûr que si les API qu'il appelle le sont. Un bouton caché dans l'UI n'importe pas si l'endpoint fonctionne encore pour un utilisateur normal, une session fuitée ou une requête anonyme.
Commencez par traiter chaque endpoint admin comme une porte verrouillée. Exigez une authentification côté serveur, puis vérifiez le rôle ou la permission à chaque requête. Ne vous fiez pas à un simple drapeau isAdmin envoyé par le navigateur. Re-vérifiez côté serveur en utilisant des données de session fiables.
Ensuite, soyez strict sur les entrées. Les endpoints admin acceptent souvent des IDs, termes de recherche, plages de dates ou objets de filtre. Validez le type, la longueur et les champs autorisés, et rejetez tout ce qui est inattendu. Si un endpoint accepte des fragments SQL bruts, des regex non bornées ou « trier par n'importe quelle colonne », ça finira par vous nuire.
Voici quelques garde-fous qui rendent un panneau admin généré par IA beaucoup plus difficile à casser :
- Exiger des IDs explicites pour les écritures (update, disable, delete). Évitez les écritures « appliquer à tous les filtres correspondants ».
- Ajouter de la pagination sur les lectures et des plafonds stricts pour les opérations en masse (par exemple, max 100 éléments par requête).
- Forcer une étape de « prévisualisation » pour les actions groupées : retourner le compte et des enregistrements exemples avant d'autoriser l'écriture.
- Limiter le taux sur les endpoints sensibles comme réinitialisations de mot de passe, changements de rôle et exports.
Les actions groupées sont la voie habituelle du désastre. Un bug courant est un filtre tenant manquant ou un paramètre null qui transforme « supprimer ces 3 utilisateurs » en « supprimer tous les utilisateurs ». Si vous devez supporter des mises à jour groupées, faites en sorte que la requête inclue à la fois un filtre et une limite explicite, et échoue si l'ensemble de résultats est plus grand que prévu.
Enfin, renvoyez des erreurs claires sans divulguer les internes. Dites « Not authorized » ou « Entrée invalide : userId doit être un UUID », mais n'échoez pas les stack traces, secrets, SQL ou chemins de fichiers. Si vous avez hérité d'une base de code fragile, FixMyMess commence souvent par auditer ces endpoints admin en priorité, car une seule API non sûre peut annuler tous les correctifs UI.
Empêcher que les actions destructrices ne tournent au désastre
Les panneaux admin ont souvent les boutons les plus tranchants du produit : supprimer des utilisateurs, réinitialiser la facturation, purger des données, mises à jour en masse. L'objectif dans un panneau admin sécurisé est simple : rendre difficile de causer un dommage irréversible par accident, et facile de récupérer quand ça arrive encore.
Commencez par séparer « retirer de la vue » et « effacer pour toujours ». Pour les enregistrements visibles par les utilisateurs ou critiques, privilégiez la suppression souple (soft delete) avec un chemin de restauration clair. La suppression définitive doit rester rare et fortement contrôlée. Mieux encore, faites-en une opération hors ligne et planifiée, pas un bouton normal à côté de « Modifier ».
Pour les actions irréversibles, un simple modal ne suffit pas. Utilisez une confirmation typée qui force l'attention, par exemple demander à l'admin de taper le nom exact de la ressource ou une phrase telle que DELETE PROJECT. Cela bloque les mauvaises manipulations et protège aussi contre les bugs UI qui soumettraient deux fois.
Les actions à haut risque doivent avoir une seconde vérification côté serveur, pas seulement dans le navigateur :
- Ré-authentification avant suppression (mot de passe ou revalidation SSO)
- Code à usage unique envoyé sur un canal de confiance
- Approbation par une seconde personne pour les actions touchant l'organisation
- Fenêtre de délai courte où l'action peut être annulée
Sous le capot, enveloppez les changements destructeurs dans une transaction de base de données pour éviter des suppressions partielles (certaines tables mises à jour, d'autres non). Si l'opération touche des fichiers, des files ou des services externes, enregistrez un « operation ID » unique et rendez le job idempotent pour que les réessais n'amplifient pas le dommage.
Enfin, ajoutez des limites de débit et des temps de recharge. Par exemple : autoriser une « désactivation en masse » par minute par admin, et plafonner la taille des lots. Cela transforme un script déchaîné ou une action groupée boguée en petit incident au lieu d'une suppression totale.
Si vous avez hérité d'un panneau généré par IA où ces protections manquent, FixMyMess peut auditer rapidement les chemins risqués et ajouter les garde-fous avant votre mise en production.
Ajouter des journaux d'audit qui répondent aux vraies questions pendant un incident
Quand quelque chose tourne mal dans un panneau admin généré par IA, la première question n'est pas « que s'est-il passé ? » mais « qui l'a fait, d'où et qu'est-ce qui a exactement changé ? » De bons journaux d'audit vous permettent de répondre à cela en quelques minutes, pas en quelques heures.
Enregistrez les faits dont vous aurez réellement besoin
Capturez suffisamment de détails pour rejouer l'histoire sans deviner. Pour chaque action admin (create, update, delete, actions groupées, changements de permission), enregistrez :
- Qui : ID utilisateur, email, rôle au moment de l'action
- Quoi : type d'action (par exemple, UPDATE_USER_ROLE) et la route UI ou API
- Quand : horodatage en un seul fuseau standard (souvent UTC)
- Où : adresse IP et un user agent simple ou empreinte d'appareil
- Cible : l'enregistrement touché (table/entité + ID), y compris le nombre pour les actions groupées
Pour les champs à haut risque comme rôle, statut, permissions, paramètres de paiement ou feature flags, incluez les valeurs avant et après. Pas besoin d'enregistrer tous les champs à chaque mise à jour, mais assez pour prouver ce qui a changé.
Ajoutez un request ID à chaque entrée de log et incluez-le dans les réponses serveur. Quand un rapport arrive (« tous les utilisateurs ont été rétrogradés »), vous pourrez chercher par request ID et suivre cette seule chaîne à travers les services.
Rendre les logs consultables et protégés
Les logs ne servent que si vous pouvez les filtrer rapidement : par utilisateur, type d'action, ID cible et plage temporelle. Pendant un incident, vous voudrez aussi « montrer tout ce que cet utilisateur a fait la dernière heure » et « montrer toutes les actions DELETE aujourd'hui ».
Décidez de la rétention à l'avance (par exemple 30-180 jours selon le risque) et restreignez qui peut voir les logs. Les journaux d'audit peuvent contenir des données sensibles, traitez-les comme des données de production : contrôle d'accès, résistance à la falsification et redaction soignée des secrets.
Si vous avez hérité d'un panneau généré par IA avec des logs manquants ou trop bruyants, FixMyMess commence généralement par cartographier les vraies actions admin et ajouter des événements d'audit cohérents, puis vérifie avec un court scénario de type incident.
Exemple réaliste : l'action groupée qui efface plus que prévu
Une panne fréquente dans un panneau admin généré par IA est l'action groupée qui suppose que l'UI va protéger. Voici un scénario réel : un admin support veut désactiver un utilisateur qui spamme les tickets. Il filtre par domaine d'email pour trouver le compte, mais le filtre est lâche (par exemple @gmail.com) et correspond à des milliers d'utilisateurs.
L'UI affiche une ligne sélectionnée, mais le backend accepte « appliquer à tous les correspondants ». Parce que les vérifications de rôle sont manquantes ou trop larges (n'importe quel membre du staff connecté peut appeler l'endpoint), un seul clic déclenche une mise à jour massive : des milliers d'utilisateurs sont désactivés, des sessions sont invalidées et le volume de support explose.
Les garde-fous qui empêchent ce type d'accident sont simples et ennuyeux, exactement ce qu'il faut :
- Mettez des vérifications de rôle côté serveur pour chaque action admin, pas seulement sur la page.
- Limitez les actions groupées (par exemple, max 25 enregistrements) et exigez une sélection explicite et étroite.
- Affichez une prévisualisation : « Vous allez modifier 3 214 utilisateurs » avant toute action.
- Demandez une confirmation typée pour les actions destructrices (taper le mot exact ou le nombre).
- Enveloppez le changement dans une transaction pour éviter des mises à jour partielles.
Quand quelque chose tourne encore mal, les journaux d'audit transforment la panique en plan. Une entrée utile répond : qui l'a fait, d'où, quel endpoint, quel filtre ou quels IDs ont été utilisés, combien d'enregistrements ont changé, et un court résumé avant/après des champs clés.
La récupération doit être conçue, pas improvisée. Si « désactiver » est une action souple, vous pouvez restaurer en inversant le flag avec les mêmes IDs extraits du journal d'audit. Pour les suppressions, privilégiez la soft delete avec une fenêtre de restauration simple. Si vous devez hard delete, vous avez besoin d'un chemin de restauration testé (sauvegardes et procédure de restauration répétable). Les équipes demandent souvent à FixMyMess d'ajouter ces garde-fous après qu'un panneau généré par IA ait montré ce mode d'échec en production.
Réduire le rayon d'explosion : secrets, sessions et moindre privilège
Un panneau admin sécurisé ne consiste pas seulement à bloquer les mauvaises personnes. Il s'agit de faire en sorte qu'une seule erreur n'expose pas tout.
Commencez par les secrets. Les panneaux générés par IA codent souvent en dur des clés API, des URLs de base de données ou des tokens d'initialisation dans des fichiers de config, des scripts de seed ou même des écrans admin visibles. Déplacez tous les secrets vers des variables d'environnement, faites tourner tout ce qui a pu fuir, et retirez les widgets « afficher la config » ou les endpoints de debug qui impriment des valeurs sensibles.
Les sessions et tokens méritent des limites strictes. Si un token admin vit des semaines, il devient une clé maître.
Rendre l'accès facile à révoquer
Gardez l'accès admin de courte durée, restreint et facile à invalider. Une politique simple qui fonctionne pour la plupart des équipes :
- Durée de session courte pour les admins (heures, pas jours)
- Ré-authentification pour les actions risquées (exports, changements de rôle, suppressions)
- Sessions par utilisateur pour pouvoir révoquer une seule personne sans déconnecter tout le monde
- Scope des tokens limité à l'app admin, pas à toute la plateforme
Ensuite, limitez ce que l'app admin peut faire au niveau de la base de données. Beaucoup de prototypes IA se connectent en superuser parce que "ça marche simplement". Donnez à l'app admin un utilisateur de base de données dédié avec seulement les permissions nécessaires. Si l'UI admin n'a jamais besoin de dropper des tables, elle ne doit pas pouvoir le faire.
Les uploads et exports peuvent devenir des fuites de données silencieuses. Traitez les uploads comme non fiables, validez le type et la taille, et stockez-les hors du serveur applicatif avec un accès privé. Pour les exports, évitez de mettre des fichiers bruts dans un dossier public et ajoutez une durée d'expiration pour que les exports anciens ne traînent pas.
Enfin, ajoutez des défenses basiques qui réduisent l'exposition accidentelle : en-têtes de sécurité pour limiter les comportements risqués du navigateur, et protection CSRF si votre admin utilise des cookies pour l'auth. Si vous ne savez pas où se trouvent les points faibles, FixMyMess peut réaliser un audit de code gratuit et pointer les endroits où un bug peut devenir une brèche totale.
Erreurs courantes qui rendent les panneaux admin fragiles
La raison la plus commune pour laquelle un panneau admin échoue à une vérification de sécurité est simple : l'UI masque des boutons, mais le serveur fait toujours confiance au navigateur. Si quelqu'un peut appeler l'API directement (ou si votre front-end commet une erreur), les vérifications côté client ne servent à rien. Un panneau admin généré par IA a besoin de règles côté serveur appliquées sur chaque requête, même si l'UI a l'air parfaite.
Un autre pattern fragile est un unique drapeau isAdmin qui signifie « tout pouvoir, partout ». Il grossit généralement au fil du temps jusqu'à ce qu'un compte puisse éditer des utilisateurs, voir la facturation, changer des permissions et lancer des suppressions en masse. Quand quelque chose tourne mal, il n'y a pas de moyen simple de répondre : qui a fait quoi, et pourquoi avait-il·elle cet accès ?
Les endpoints destructeurs sont souvent les plus effrayants. Le code généré par IA peut inclure des « delete all », « reset » ou des actions groupées sans plafonds et sans prévisualisation. Une faute de frappe dans un filtre ou un bug dans une boucle peut supprimer bien plus que prévu. Si l'endpoint n'est pas idempotent (sûr à réexécuter) et n'a pas de garde-fous, vous pouvez aussi obtenir des doubles suppressions lors de réessais ou timeouts.
Les journaux d'audit sont un autre piège. Les équipes enregistrent soit trop peu (pas de record cible, pas d'avant/après, pas d'acteur), soit trop (tokens, mots de passe, corps de requête complet, données personnelles). L'objectif est d'enregistrer des faits utiles sans faire des logs une seconde fuite de données.
Surveillez ces signaux d'alerte dans les builds de production :
- Vérifications de rôle uniquement côté front-end, pas sur l'API
- Routes de debug, comptes admin de test, ou flags de contournement temporaires laissés activés
- Actions groupées sans prévisualisation, sans limite et sans étape de confirmation
- Absence d'IDs de requête ou d'IDs d'action, rendant les incidents difficiles à tracer
- Logs qui incluent des secrets, des tokens de session ou des champs de mot de passe bruts
Un petit exemple : une action groupée « Désactiver des utilisateurs » prend une liste d'IDs, mais un bug envoie une liste vide. Le serveur interprète le vide comme « tous les utilisateurs » et désactive tout le monde. Une garde simple (rejeter le vide, plafonner le max, exiger un compte de prévisualisation) empêche le désastre.
Si vous avez hérité d'un panneau généré par IA et que vous ne savez pas où ces risques se cachent, FixMyMess peut exécuter un audit de code gratuit pour identifier rapidement les parties fragiles.
Checklist rapide de durcissement avant de livrer
Exécutez cette checklist quand vous pensez que votre panneau admin est "terminé". Elle attrape les échecs qui n'apparaissent que face à de vrais utilisateurs et de vraies données.
Cinq tests à faire en 15 minutes
- Test d'accès anonyme : copiez une URL réservée aux admins, ouvrez-la en fenêtre privée et essayez sans vous connecter. Ça doit échouer à chaque fois, même si l'UI masque le bouton.
- Test de permission côté serveur : choisissez une action admin (par exemple « créer un utilisateur » ou « rembourser »), puis appelez-la avec un compte normal. L'API doit la refuser, pas seulement la page.
- Test de piste d'audit : faites trois actions (voir, éditer, supprimer) et confirmez que chacune crée un enregistrement d'audit avec qui l'a fait, ce qui a changé, quand et l'ID cible. Si vous ne pouvez pas répondre à « qui a supprimé ceci ? » en une minute, la journalisation n'est pas terminée.
- Test de sécurité des actions groupées : essayez une opération groupée avec un filtre trop large (par exemple, "tous les utilisateurs créés ce mois-ci"). Vous devez rencontrer un plafond strict et une étape de confirmation supplémentaire qui énonce le compte exact et l'impact.
- Test de récupération et hygiène des clés : faites une suppression souple, puis restaurez-la de bout en bout (UI, API, base). Profitez-en pour faire tourner les secrets qui ont déjà été imprimés dans des logs, affichés dans l'UI ou commités dans un repo.
Un contrôle rapide de réalité : si un bug peut transformer un « Supprimer un » en « Supprimer tout », vous n'avez pas encore un panneau admin généré par IA sécurisé. Ajoutez des plafonds, des confirmations et des valeurs par défaut sûres avant de livrer.
Si vous avez hérité d'un panneau généré par IA et que vous ne savez pas quoi tester, FixMyMess peut exécuter un audit de code gratuit pour trouver rapidement les parties risquées.
Prochaines étapes : obtenir un audit rapide et corriger d'abord les parties risquées
Si vous voulez un panneau admin généré par IA sécurisé, commencez par choisir ce que vous pouvez durcir aujourd'hui et ce qui mérite un refactor plus profond. De petits changements peuvent éliminer les plus gros risques rapidement, même si la base de code est en désordre.
Un bon plan « aujourd'hui » est tout ce qui bloque les désastres faciles : vérifications de routes côté serveur, actions destructrices plus sûres et journaux d'audit qui vous permettent de répondre à qui a fait quoi. Un plan « refactor plus tard » concerne généralement l'architecture : démêler les permissions, nettoyer les patterns d'accès aux données et supprimer la logique copiée-collée qui rend les bugs difficiles à repérer.
Si votre panneau admin a été généré par Lovable, Bolt, v0, Cursor ou Replit, supposez qu'il existe des cas limites cachés. L'UI peut sembler correcte alors que l'API accepte encore des requêtes directes, les actions groupées s'exécutent sans limites, ou une page « admin only » se charge avec une session utilisateur normale.
Une manière rapide de réduire le risque en 48-72 heures
Un diagnostic focalisé du code devrait couvrir les parties qui causent de réels dégâts :
- Auth et gestion des sessions (comment on décide qu'un compte est « admin »)
- Protection des routes et API admin (côté serveur uniquement)
- Actions destructrices (delete, édition en masse, imports) et garde-fous
- Journalisation d'audit (ce qui est enregistré, ce qui manque)
FixMyMess peut effectuer un audit de code gratuit, pointer d'abord les problèmes à haut risque, puis aider à transformer un prototype fragile en logiciel prêt pour la production avec des corrections vérifiées par un humain.
Ce qu'il faut préparer avant de le confier
Vous aurez de meilleurs résultats si vous récupérez quelques éléments en amont :
- Accès au repo (ou une copie exportée du code)
- Une liste simple des rôles admin (même si c'est « propriétaire » et « staff »)
- Les actions les plus effrayantes dans votre panneau (suppression en masse, remboursements, bannissements, exports de données)
- Un incident réel qui vous inquiète ("un bug efface tout")
Avec cela, vous pouvez corriger d'abord les parties les plus risquées, livrer sereinement et planifier un nettoyage plus profond quand vous aurez un peu d'air.