Protection contre les replays de webhooks : stopper les doublons en toute confiance
La protection contre les replays de webhooks empêche les frais et actions en double en vérifiant les signatures, en appliquant des fenêtres temporelles et en stockant les clés d'idempotence en toute sécurité.
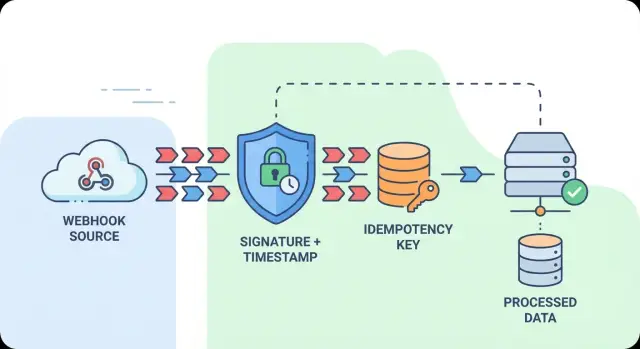
Pourquoi les webhooks en double arrivent et pourquoi c'est important
Un webhook est un message qu'un service envoie à votre application (généralement une requête HTTP) pour vous indiquer qu'un événement s'est produit, comme un paiement réussi ou une annulation d'abonnement.
Le problème, c'est que « envoyé » ne veut pas dire « traité une seule fois ». La plupart des fournisseurs livrent les webhooks avec une garantie « au moins une fois ». Si votre endpoint expire, renvoie un 5xx, ou que la réponse se perd au retour, le fournisseur réessaie. Ces réessais sont des doublons accidentels : le même événement du monde réel livré plusieurs fois.
Les replays sont différents. Une attaque par replay consiste à capturer une requête webhook valide et à la renvoyer plus tard pour déclencher deux fois le même effet. La requête peut sembler légitime, donc sans protection contre les replays vous pouvez accepter un ancien événement comme s'il était nouveau.
Si des doublons ou des replays sont traités comme des événements neufs, les conséquences sont douloureuses : doubles prélèvements ou remboursements, e-mails en double, stock décrémenté deux fois, abonnements ou factures en double, et des données d'analytics qui ne reflètent plus la réalité.
L'objectif est simple à énoncer et facile à rater : accepter chaque événement valide une fois, et ignorer les répétitions en toute sécurité. « En toute sécurité » compte parce que les réessais légitimes sont normaux, tandis que les requêtes altérées et les replays obsolètes doivent être rejetés.
Un bon handler traite chaque webhook entrant comme non fiable jusqu'à preuve du contraire. Il vérifie qui l'a envoyé, vérifie que c'est assez récent pour être crédible, et enregistre un marqueur stable « déjà traité » pour que la deuxième livraison devienne un no-op.
Sources courantes de doublons et de replays
Les livraisons en double sont un comportement attendu. Même quand tout fonctionne, le même événement peut arriver à nouveau.
La cause la plus courante est le réessai après un timeout ou une réponse 5xx. Vous avez peut-être terminé le traitement, mais le fournisseur n'a pas reçu un signal clair de succès. Des problèmes réseau créent le même résultat : la requête réussit, mais la réponse est perdue ou un proxy réinitialise la connexion.
Les doublons peuvent aussi venir de votre propre système et pourtant sembler être des « problèmes de webhook » quand vous analysez les résultats. Un utilisateur double-clique sur un bouton, une automatisation boucle, ou une file redélivre après un crash d'un worker.
Les sources typiques incluent les réessais du fournisseur, les renvois manuels via un tableau de bord, la perte de réponse après un traitement réussi, la redelivery depuis une queue, et des boucles d'intégration.
Les replays sont le cousin plus inquiétant. Un attaquant (ou un client bogué) peut renvoyer une ancienne requête qui était valide auparavant. Sans protection contre les replays, cela peut répéter des actions comme accorder l'accès, modifier l'état d'un compte ou générer des factures.
Un cas d'échec simple : votre handler crée une facture sur payment_succeeded. Si l'événement est réessayé trois fois, ou replayé un jour plus tard, vous pouvez vous retrouver avec plusieurs factures à moins que vous ne vérifiiez les signatures, n'appliquiez une fenêtre d'horodatage et ne dédupliquiez via une clé d'idempotence.
Validation des signatures : votre première ligne de défense
La validation des signatures bloque la plupart des webhooks usurpés avant qu'ils n'atteignent votre système. Une signature valide prouve que la charge utile n'a pas été modifiée en transit (intégrité) et qu'elle a été produite par quelqu'un qui connaît le secret partagé (authenticité).
C'est une partie importante de la protection contre les replays parce qu'elle empêche des tiers aléatoires d'inventer des événements. Elle n'empêche pas, à elle seule, qu'un expéditeur légitime livre le même événement deux fois. Elle garantit simplement que vous ne traitez que des messages réels.
L'erreur courante est de se contenter de la présence d'un en-tête sans le vérifier. Une requête avec X-Signature: abc123... ne signifie rien à moins que vous ne recalculiez la signature côté serveur en utilisant le corps brut et votre secret.
Un flux de vérification solide est :
- Rejeter immédiatement si l'en-tête de signature est absent.
- Lire les octets bruts du corps (pas un objet JSON parsé).
- Calculer le HMAC attendu (ou l'algorithme spécifié par le fournisseur) sur les octets exacts.
- Comparer en utilisant une fonction en temps constant.
- Ce n'est qu'ensuite qu'il faut parser le JSON et faire tout travail en base.
La comparaison en temps constant vaut le coup parce que les comparaisons normales de chaînes peuvent fuir des informations via des différences de timing.
Aussi, échouez vite. Si vous validez la signature après avoir parsé de gros payloads, vous offrez aux attaquants un moyen facile de consommer du CPU. Traitez les signatures manquantes ou invalides comme une porte verrouillée : arrêtez tôt, consignez peu de détails, et renvoyez une erreur sans faire de travail supplémentaire.
Fenêtres d'horodatage : faites expirer les replays
Une fenêtre d'horodatage limite la durée pendant laquelle une requête webhook capturée reste utile. Elle fonctionne mieux quand l'expéditeur inclut un horodatage et le signe avec le corps.
Le flux est simple : vérifiez la signature, puis contrôlez que l'horodatage est suffisamment récent. Si quelqu'un renvoie la même requête exacte des heures plus tard, elle échoue au contrôle de fraîcheur.
Comment choisir la fenêtre
Beaucoup d'équipes commencent par un petit décalage autorisé, comme 5 minutes. C'est généralement suffisant pour les délais réseau normaux et la mise en file, sans laisser passer de vieux messages.
Une approche pratique :
- Extraire l'horodatage depuis l'en-tête du fournisseur (ou la charge utile si c'est leur format).
- Vérifier la signature en utilisant la même valeur d'horodatage comme partie de l'entrée signée.
- La comparer à l'heure serveur et n'accepter que si elle est dans la fenêtre de tolérance.
- Hors de la fenêtre, traiter comme un replay même si la signature est valide.
La dérive d'horloge est le mode d'échec silencieux. Si l'heure de votre serveur est fausse, vous rejetterez de bons événements. Gardez les hôtes synchronisés et comparez avec l'heure serveur, pas l'heure client.
Pour les événements tardifs, décidez à l'avance si vous les rejetez strictement ou si vous les orientez vers une revue manuelle. Si votre fournisseur livre parfois des webhooks retardés, les logger et les examiner peut être plus sûr que de les traiter automatiquement hors fenêtre.
Clés d'idempotence : comment la déduplication fonctionne en pratique
Une clé d'idempotence est une étiquette « faire ceci une fois » pour un événement webhook. Quand le même événement arrive à nouveau, vous recherchez la clé et renvoyez le même résultat au lieu d'exécuter votre logique métier deux fois.
La clé doit être stable entre les réessais. Si le fournisseur vous donne un event_id ou un message_id, utilisez-le. Sinon, construisez-en une à partir de champs qui ne changeront pas entre les livraisons, comme le hash de nom du fournisseur + type d'événement + id de ressource + horodatage du fournisseur. N'utilisez pas votre propre heure de réception ou des UUID aléatoires, car les doublons ne correspondraient jamais.
La portée importe aussi. Si vous gérez plusieurs clients, incluez l'identifiant du locataire dans la clé stockée pour qu'un client ne puisse pas bloquer un autre par accident.
Un modèle simple consiste à stocker une ligne par clé d'idempotence avec un statut et (optionnellement) un résultat compact :
- in-progress (accepté, travail non terminé)
- processed (terminé, les doublons peuvent renvoyer succès immédiatement)
- failed (terminé avec une erreur, vous pouvez choisir de réessayer)
Conservez les clés assez longtemps pour couvrir votre risque. Si de l'argent bouge, gardez-les plus longtemps (jours ou semaines). Si l'impact est faible, une rétention plus courte peut suffire.
Une sauvegarde pratique : imposez l'unicité au niveau base de données. Une contrainte unique transforme la concurrence en « premier écrivain gagne », même si deux copies arrivent en même temps.
Stockage idempotent : le pattern le plus simple et fiable
Si vous voulez une déduplication qui résiste aux réessais, timeouts et requêtes parallèles, stockez l'idempotence dans votre base de données. Les caches mémoire expirent. Les verrous en processus cassent quand vous montez en charge. Une contrainte unique en base est ennuyeuse, rapide et difficile à contourner.
Choisissez une clé d'idempotence stable (souvent l'ID d'événement du fournisseur, ou un hash de tenant + event ID). Créez une table comme webhook_receipts avec une contrainte UNIQUE sur cette clé.
Insérer d'abord, puis traiter
Le flux le plus sûr est d'écrire un reçu avant de faire le vrai travail. Deux requêtes ne peuvent pas toutes deux « gagner ». Une insertion réussit, l'autre échoue, et le doublon devient un no-op.
Un pattern fiable :
- Valider la signature et l'horodatage, puis calculer la clé d'idempotence.
- Tenter d'insérer une ligne de reçu avec le statut
received. - Si l'insertion échoue à cause de la contrainte unique, le traiter comme un doublon et renvoyer un 2xx sûr.
- Si l'insertion réussit, exécuter la logique métier, puis mettre à jour le reçu en
processed(oufailed).
Renvoyer 2xx sur les doublons peut sembler étrange, mais c'est généralement correct. L'expéditeur demande « L'avez-vous reçu ? » et vous l'avez fait. retraiter est la partie risquée.
Stocker un reçu minimal
Gardez le reçu petit mais utile : idempotency_key, tenant_id, event_type, received_at, processed_at, status, et peut-être un court champ result comme « created invoice 123 ». Cela vous donne aussi une trace d'audit quand vous devez expliquer pourquoi quelque chose s'est produit.
Étape par étape : construire un handler webhook sûr
Fiabilité et protection contre les replays poursuivent le même but : accepter un événement une fois, et une seule fois, même s'il est livré plusieurs fois.
Un flux de requête qui tient face aux réessais
Gardez le chemin critique court et divisez-le en étapes :
- Vérifier avant de parser le JSON. Lire le corps brut, valider la signature et vérifier une fenêtre d'horodatage. Si cela échoue, renvoyer 4xx.
- Parser et valider le schéma. Décoder le JSON et confirmer les champs requis (event id, type, tenant/account).
- Calculer une clé d'idempotence. Préférer l'ID d'événement du fournisseur.
- Enregistrer la clé avec une écriture unique. Si elle existe déjà, renvoyer 2xx immédiatement. Si elle est nouvelle, continuer seulement après que l'écriture ait réussi.
- Faire le travail métier hors du chemin critique. Enfilez un job avec la charge utile (ou une référence). Dédupez au point d'entrée du webhook, pas à l'intérieur du worker.
Après avoir renvoyé 2xx, vous pouvez en toute sécurité effectuer des actions plus lentes comme appeler des API de paiement, envoyer des e-mails ou mettre à jour votre base.
Pour le dépannage, attachez un ensemble de corrélation aux logs : request id, event id (idempotency key), tenant id, event type, et la décision (accepté vs duplicate). Si un client signale un double prélèvement, vous pouvez tracer rapidement un événement à travers les réessais.
Ordre, concurrence et cas multi-tenant
Les webhooks ne sont pas une queue. Vous pouvez recevoir l'événement B avant l'événement A, ou obtenir le même événement deux fois en même temps. Si votre code suppose un ordre propre, vous finirez par écraser de bonnes données avec des données plus anciennes ou appliquer deux fois des effets de bord.
Livraisons hors ordre : acceptez-le
Concevez les handlers pour être sûrs même lorsque les événements arrivent en retard. Pour les événements de type update, n'appliquez les changements que s'ils sont plus récents que ce que vous avez déjà stocké. « Plus récent » peut être un numéro de version, une séquence, ou un updated_at fourni par l'expéditeur. Si vous n'avez rien de tout cela, conservez votre propre marqueur « last processed » par objet et traitez les mises à jour plus anciennes comme des no-op.
Aussi, ne traitez pas les créations comme spéciales. Si vous traitez un « update » avant un « create », votre handler devrait faire un upsert sur l'enregistrement et plus tard ignorer la create obsolète.
Concurrence : le même événement peut frapper deux fois en même temps
La déduplication doit être race-safe. Deux requêtes peuvent toutes deux réussir un contrôle « ai-je déjà vu ça ? » avant que l'une n'écrive la réponse.
La contrainte unique en base de données est la correction la plus propre. Insérez d'abord l'enregistrement de déduplication, puis faites le travail, puis marquez-le terminé. Si le travail est long, stockez un statut (received, processing, succeeded, failed) et ne réessayez que quand une tentative précédente a clairement échoué ou expiré.
Clés multi-tenant : éviter les collisions inter-clients
Si vous servez plusieurs locataires, incluez l'identifiant du locataire dans votre clé de déduplication. Sinon, deux clients pourraient partager le même event_id et se bloquer mutuellement.
Un format de clé pratique est tenant_id + provider + event_id (ou tenant_id + provider + object_id + version).
Les échecs partiels comptent aussi. Si vous débitez une carte mais que vous plantez avant de marquer l'événement comme réussi, un réessai peut débiter à nouveau à moins que vous n'ayez enregistré ce qui a déjà été fait.
Erreurs fréquentes qui causent un double traitement
La plupart des problèmes de double traitement sont prévisibles, pas aléatoires.
Valider la signature trop tard est un classique. Si vous écrivez en base, envoyez un e-mail, ou débitez une carte et que vous ne contrôlez la signature qu'après, une requête forgée ou replayée peut encore faire des dégâts. La validation doit précéder tout effet de bord.
Un autre problème fréquent est de lire le corps de la requête de la mauvaise façon. Certains frameworks parsèrent le JSON puis le re-sérialisent (changeant les espaces, l'ordre des champs ou l'encodage). Si la signature du fournisseur est calculée sur les octets bruts, la vérification échouera si vous validez contre un corps modifié. N'« acceptez pas temporairement » les signatures échouées pour garder le système en marche. Cela transforme les vérifications de signature en théâtre.
Autres patterns fréquents :
- Déduper seulement sur la base des horodatages. Deux événements réels peuvent partager un horodatage, et un attaquant peut en copier un.
- Renvoyer 500 pour des doublons. L'expéditeur voit une erreur et réessaie plus fort, créant une tempête de réessais.
- Traiter « déjà traité » comme une exception au lieu d'un résultat normal.
- Logger des secrets ou les embarquer dans du code côté client.
Si vous détectez le même ID d'événement deux fois, répondez avec un 2xx et ne faites rien d'autre. C'est généralement la façon la plus sûre d'arrêter les réessais.
Un exemple concret : prévenir les doubles prélèvements
Un cauchemar fréquent pour le support : un client dit avoir été débité deux fois. Votre fournisseur de paiement envoie un webhook payment_succeeded, votre serveur crée une commande, puis un réessai ou un replay frappe à nouveau le même endpoint. Si votre handler exécute la logique de facturation ou fulfillment deux fois, vous avez un vrai problème.
La protection contre les replays fonctionne en couches. La vérification de signature assure que seul votre fournisseur peut envoyer des événements valides. Une fenêtre d'horodatage limite la durée pendant laquelle une requête capturée reste exploitable. Mais les réessais légitimes restent normaux, et c'est là que la déduplication via une clé d'idempotence compte le plus.
Un pattern propre est :
- Extraire l'ID d'événement du fournisseur (ou en construire un à partir de champs stables).
- L'utiliser comme clé d'idempotence, par exemple
provider:event_id:account_id. - Insérer la clé en stockage avec une contrainte d'unicité.
- Si l'insertion réussit, traiter la commande.
- Si elle existe déjà, renvoyer 200 et ne rien faire.
Ce que voit le client : un prélèvement, un seul reçu, et un statut de commande cohérent même si le fournisseur réessaie cinq fois.
Liste de contrôle et prochaines étapes
Si vous voulez une protection contre les replays de webhooks qui tient en production, concentrez-vous sur quelques points non négociables :
- Vérifiez la signature avant toute logique métier (et avant de logger des champs que vous ne faites pas entièrement confiance).
- Rejetez les requêtes avec des horodatages en dehors de votre fenêtre autorisée, et gardez vos serveurs synchronisés.
- Dédupliquez avec une clé d'idempotence unique stockée de façon atomique.
- Renvoyez des 2xx cohérents pour les doublons afin que l'expéditeur arrête de réessayer.
- Loggez en sécurité : pas de secrets, et incluez des champs de corrélation (event ID, request ID, tenant ID) pour le traçage.
Un test rapide qui attrape la plupart des erreurs : envoyez exactement la même charge utile de webhook cinq fois de suite, puis envoyez-la à nouveau après l'expiration de votre fenêtre d'horodatage. Vous devriez voir une action métier unique, plusieurs réponses rapides « déjà traitée », et un rejet propre une fois trop ancien.
Si vous avez hérité d'un handler webhook généré par AI qui double-traite lors des réessais, c'est souvent un petit ensemble de corrections : vérification du corps brut, fenêtre d'horodatage, et idempotence en base. Si vous voulez un deuxième avis, FixMyMess (fixmymess.ai) peut réaliser un audit de code gratuit pour identifier où la vérification, le durcissement de la sécurité et la déduplication échouent avant que vous ne déployiez d'autres changements.
Questions Fréquentes
Why am I receiving the same webhook multiple times?
La plupart des fournisseurs de webhooks garantissent seulement une livraison au moins une fois. Si votre point de terminaison expire, renvoie un 5xx, ou que la réponse se perd, le fournisseur réessaie le même événement. Ces réessais sont normaux et vous devez concevoir votre handler pour ne rien faire en cas de répétition.
What’s the difference between webhook duplicates and replay attacks?
Un doublon est généralement un réessai légitime du même événement réel, causé par des timeouts, des erreurs ou une perte de réponse. Un replay est quand une ancienne requête, auparavant valide, est renvoyée plus tard pour déclencher le même effet deux fois. Vous devez accepter les réessais légitimes en toute sécurité, mais rejeter les replays obsolètes en appliquant une vérification de fraîcheur et en dédupliquant via une clé d'événement stable.
If I verify the signature, do I still need idempotency?
Une signature prouve que la charge utile n'a pas été modifiée et que l'expéditeur connaît votre secret partagé, ce qui bloque la plupart des requêtes usurpées. Elle n'empêche pas qu'un même événement valide soit livré plusieurs fois, car les réessais portent toujours une signature correcte. Les vérifications de signature sont nécessaires, mais la déduplication empêche le double traitement.
How do I validate webhook signatures correctly without false failures?
Validez contre les octets bruts du corps de la requête exactement tels qu'ils ont été reçus, puis calculez le HMAC attendu (ou l'algorithme spécifique du fournisseur) et comparez avec une fonction en temps constant. Si vous vérifiez un corps JSON parsé ou re-sérialisé, de minuscules différences de formatage peuvent casser la vérification et pousser les équipes à « accepter temporairement » des signatures invalides, ce qui est dangereux.
What timestamp window should I use to block replays?
Utilisez une petite fenêtre de tolérance par défaut, souvent autour de 5 minutes, pour laisser passer les délais réseau normaux mais faire expirer rapidement les requêtes capturées. L'horodatage doit faire partie de ce qui est signé ; sinon un attaquant peut le modifier. Gardez vos serveurs synchronisés, car la dérive d'horloge est une cause fréquente de rejet d'événements valides.
What should I use as an idempotency key for webhook dedupe?
Commencez par l'event_id ou le message_id du fournisseur s'il existe, car il reste identique entre les réessais. Si vous devez en construire un, dérivez-le de champs stables comme le nom du fournisseur, le type d'événement, l'ID de la ressource, l'ID du locataire et un horodatage du fournisseur, souvent hachés ensemble. N'utilisez pas votre propre heure de réception ou un UUID aléatoire, car les doublons ne correspondront pas.
Why is database-backed dedupe better than using a cache or in-memory lock?
Un écrit en base avec une contrainte d'unicité est le moyen le plus fiable pour rendre la déduplication race-safe entre plusieurs serveurs et requêtes parallèles. Le pattern courant est « insérer le reçu d'abord, puis traiter », ainsi une seule requête « gagne » et les autres deviennent des no-op. Les verrous en mémoire et les caches échouent souvent lors de la montée en charge ou des redémarrages.
Should I return 200 or an error when I detect a duplicate webhook?
Pour les doublons, renvoyez un 2xx cohérent une fois que vous avez confirmé avoir déjà traité l'événement, afin que le fournisseur arrête les réessais et que vous évitiez une tempête de réessais. Pour les signatures invalides ou les horodatages hors de votre fenêtre, renvoyez un 4xx et n'effectuez aucun travail. L'idée clé est d'éviter les effets de bord sauf si la requête est à la fois authentique et suffisamment récente.
How do I handle out-of-order webhooks and concurrent deliveries?
Supposez que les événements peuvent arriver dans le mauvais ordre et concevez vos handlers pour rester sûrs dans ce cas. Appliquez les mises à jour seulement si elles sont plus récentes que ce que vous avez (utilisez une version du fournisseur, une séquence ou un updated_at quand c'est disponible), et préférez les upserts pour que « update before create » ne vous casse pas. Séparement, rendez la déduplication race-safe avec une clé d'idempotence unique pour que deux livraisons identiques ne puissent pas toutes deux s'exécuter.
How do I stop webhook retries from causing double charges or duplicate invoices?
Une cause fréquente est le traitement de la webhook deux fois parce qu'il n'y a pas de garde d'idempotence à l'entrée, ou parce qu'un crash survient après le débit mais avant l'enregistrement du succès. Vérifiez vos logs pour le même event_id du fournisseur apparaissant plusieurs fois, et assurez-vous d'insérer un reçu d'idempotence avant les effets de bord. Si vous avez hérité d'un handler généré par AI qui double-traite, FixMyMess peut faire un audit de code gratuit et appliquer les correctifs typiques — vérification du corps brut, fenêtres d'horodatage, et idempotence en base — pour que les réessais deviennent des no-op.