Quand ajouter une réplique de lecture : signes, routage et pièges
Quand ajouter une réplique de lecture : signes clairs, routage sûr des lectures et comment éviter les surprises liées au retard de réplication et aux hypothèses cassées.
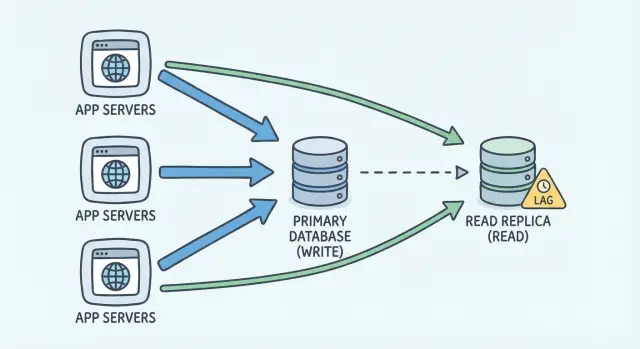
Quel problème résout vraiment une réplique de lecture
Une réplique de lecture aide quand votre base de données consacre tellement de temps aux lectures que les écritures commencent à en pâtir. Il ne s'agit pas seulement d'accélérer le rendu des pages. Il s'agit de protéger la base primaire pour qu'elle puisse continuer à accepter des mises à jour au lieu d'être bloquée par de lourdes requêtes SELECT.
Cela se manifeste généralement par un schéma familier : un ou deux écrans populaires (ou endpoints d'API) génèrent la majeure partie du travail sur la base. Un tableau de bord qui se rafraîchit souvent, une page de recherche ou une vue d'administration « lister tout » peuvent consommer beaucoup de CPU et d'I/O. Ensuite, les parties de l'app qui créent des commandes, mettent à jour des profils ou écrivent des logs commencent à avoir des timeouts ou des comportements imprévisibles.
Une réplique fait une chose principale : elle vous fournit une autre copie des données pour lire. Votre application peut envoyer certains SELECT vers la réplique afin que le primaire ait plus de marge pour les INSERT/UPDATE/DELETE.
Ce que ça ne corrige pas :
- Les requêtes lentes parce qu'elles sont mal écrites ou manquent d'indexes
- Les problèmes de verrou liés à des transactions longues sur le primaire
- Trop d'écritures (une réplique n'augmente pas la capacité d'écriture)
- La logique applicative qui suppose que toute lecture est immédiatement à jour
Ce dernier point montre pourquoi la décision relève de la correction fonctionnelle, pas seulement de la vitesse. Une réplique est généralement un peu en retard par rapport au primaire. Si vous lisez dessus au mauvais moment, un utilisateur peut ne pas voir ses paramètres tout juste modifiés, une page "paiement réussi" peut encore sembler impayée, ou un support peut penser qu'une action n'a pas eu lieu.
Une bonne règle : ajoutez une réplique de lecture lorsque vous avez clairement un trafic orienté lecture qui nuit à la réactivité des écritures, et que vous pouvez nommer quels endpoints sont sûrs d'être servis avec des données légèrement obsolètes.
Notions de base sur la réplique (sans jargon)
Une réplique de lecture est un second serveur de base de données qui contient une copie de votre base principale. Vous gardez une base "primaire" comme source de vérité. Toutes les écritures y vont, car c'est le seul endroit garanti d'avoir les données les plus récentes.
La réplique sert principalement à la lecture. Au lieu que chaque chargement de page, rapport ou graphique frappe le primaire, certaines requêtes en lecture seule peuvent aller vers la réplique pour que le primaire reste réactif pour les écritures et les requêtes critiques.
Comment la copie reste à jour
La plupart des configurations utilisent une réplication asynchrone. En termes simples : le primaire enregistre d'abord les changements, puis la réplique reçoit et applique ces changements un peu plus tard. Ce délai est le retard de réplication. Parfois il est minime (millisecondes). Sous charge, ou lors de pics, il peut atteindre des secondes ou plus.
Ce fait explique la plupart des surprises rencontrées.
Le compromis que vous choisissez
Une réplique peut rendre votre app plus rapide, mais vous payez avec la fraîcheur. Les lectures depuis la réplique peuvent être légèrement en retard par rapport au primaire.
Un modèle mental simple :
- Primaire : correct maintenant, gère les écritures
- Réplique : permet d'échelle en lecture, peut être en retard
- Lag : l'écart entre ce que vous venez d'écrire et ce que la réplique peut voir
Exemple : un utilisateur met à jour son adresse e-mail et rafraîchit immédiatement la page de profil. Si cette page lit depuis la réplique, elle peut encore afficher l'ancienne adresse pendant un instant. Ce n'est pas définitivement faux, mais c'est déroutant à moins de router ces lectures soigneusement.
Signes que vous êtes prêt à considérer une réplique
Une réplique de lecture aide quand votre base passe la plupart du temps sur des lectures (SELECT), pas sur des écritures. Si le CPU de la base est élevé et que vos requêtes en tête sont principalement des SELECT, c'est un signal fort.
Un autre signe courant est « le trafic de lecture pénalise les écritures ». Vous voyez la latence des écritures monter précisément lors des pics de lecture, même si le volume d'écriture n'a pas changé. Les lectures et écritures se battent pour le même CPU, mémoire et disque, donc des pages de reporting lourdes peuvent ralentir le checkout, les inscriptions ou toute mise à jour.
Examinez attentivement ce qui est lent. Les pages de liste, tableaux de bord, tables d'administration, résultats de recherche et exports sont souvent de bons candidats. Ces endpoints scannent souvent beaucoup de lignes et sont appelés fréquemment par des utilisateurs (ou des jobs en arrière-plan).
La pression sur le pool de connexions est un autre déclencheur pratique. Si vous atteignez le max de connexions principalement à cause d'endpoints orientés lecture, une réplique peut réduire la contention. Elle ne corrigera pas des requêtes inefficaces, mais elle peut donner de l'air.
Le caching peut retarder le besoin d'une réplique, mais ce n'est pas toujours suffisant. Vous êtes souvent prêt pour une réplique quand :
- Le taux de hit du cache reste faible parce que les données changent fréquemment ou que les clés sont difficiles à concevoir
- Le cache cause des problèmes d'affichage ("mauvais chiffres") visibles par l'utilisateur
- Vous avez besoin de données fraîches-ish, mais pas parfaitement instantanées
- Les exports et filtres ad-hoc ne se cachent pas en toute sécurité
- Votre couche de cache est déjà une source majeure de bugs
Un processus décisionnel à suivre
Considérez l'ajout d'une réplique comme une petite expérience avec un indicateur de succès clair. Le but n'est pas « ajouter plus de bases ». C'est « réduire la douleur sans casser la correction ».
Commencez par être précis. « L'app est lente » n'est pas suffisant. Vous voulez une liste courte d'endpoints et de requêtes mesurables avant et après.
Un processus qui marche pour la plupart des équipes :
- Identifiez vos principaux endpoints de lecture par nombre de requêtes et temps total (tableau de bord, recherche, feed, rapports).
- Confirmez que la base est le goulot (pas le CPU du serveur d'app, du code lent, un cache manquant ou des appels API bavards).
- Séparez les lectures en deux catégories : doivent être fraîches (soldes, permissions, checkout) vs peuvent être légèrement obsolètes (analytics, listes d'activité, pages publiques).
- Fixez un objectif vérifiable, par exemple « réduire la charge de lecture sur le primaire de 40% » ou « couper le p95 du tableau de bord de 3s à 1s ».
- Définissez un plan de rollback : comment vous reviendrez rapidement au primaire si quelque chose tourne mal.
Ensuite, décidez où vous routerez les lectures. Un bon premier pas est de router uniquement les endpoints « tolérant l'obsolescence » vers la réplique et de garder toutes les écritures sur le primaire. Évitez de mélanger lectures et écritures dans la même requête au départ. C'est là que le retard pose problème.
Avant toute mise en production, faites un rapide contrôle de sécurité :
- Pouvez-vous dire quelle DB a servi une requête (logs, tags ou tracing) ?
- Pouvez-vous détecter le retard et retomber temporairement sur le primaire ?
- Avez-vous un plan de test court pour la correction visible par l'utilisateur (connexion, paiements, permissions) ?
Si vous ne pouvez pas mesurer l'amélioration et revenir en arrière rapidement, faites une pause. Une réplique ajoute de la complexité ; il faut que le bénéfice soit évident.
Quels endpoints bénéficient (et lesquels doivent rester sur le primaire)
Une réplique de lecture aide surtout lorsque vous avez beaucoup de lectures qui n'ont pas besoin d'être parfaitement à jour. Le but n'est pas de tout déplacer. C'est d'enlever la pression sur le primaire tout en gardant l'app correcte.
Bons candidats pour une réplique
Ces endpoints sont généralement sûrs car orientés lecture et pas liés à l'argent ou aux accès :
- Pages publiques (marketing, blog, fiches produit publiques)
- Recherche et navigation (filtres, listings de catégorie)
- Analytique et reporting (graphiques, tendances, exports)
- Listes d'administration (tables d'utilisateurs, commandes, logs) où un clic creuse sur le primaire
- APIs en lecture seule utilisées par des partenaires ou outils internes
Les vues de profil utilisateur et catalogues produits sont souvent correctes avec précaution. La plupart des utilisateurs ne remarqueront pas si un avatar ou une bio met un instant à se mettre à jour.
Endpoints qui doivent rester sur le primaire
Si cela affecte l'argent ou l'accès, gardez-le sur le primaire. Cela inclut le checkout, les paiements, le statut d'abonnement et tout ce qui détermine ce qu'un utilisateur peut voir ou faire.
Surveillez aussi les endpoints qui semblent en lecture seule mais écrivent en réalité. Les équipes ajoutent souvent de petites écritures comme mise à jour de last_seen, incrément de counters, rafraîchissement de sessions ou enregistrement d'éléments « récemment vus ». Si vous routez ce endpoint vers une réplique, il peut échouer (les répliques sont souvent en lecture seule) ou se comporter de façon inconsistante.
Règle simple : envoyez uniquement des requêtes idempotentes et en lecture vers les répliques. Gardez tout ce qui change l'état, ou qui décide des accès, sur le primaire. Si vous n'êtes pas sûr à 100%, considérez-le comme primaire jusqu'à vérification.
Comment router les lectures sans fragiliser l'app
Routage des lectures : simple en théorie — envoyer les SELECT vers la réplique et garder les écritures sur le primaire. En pratique, la fragilité vient de tout le reste : gestion des connexions, moments « lire sa propre écriture » et ce qui arrive quand la réplique est en retard.
Deux approches pratiques de routage
Vous routez généralement à un des deux niveaux.
Si vous routez dans le code applicatif, vous choisissez la base par endpoint (ou par requête). C'est explicite : « parcourir les produits » peut utiliser la réplique tandis que « mettre à jour le profil » reste sur le primaire. L'inconvénient est que les règles de routage peuvent se disperser dans le code et devenir difficiles à raisonner.
Si vous routez via un proxy ou un routeur de base de données, les politiques sont centralisées, ce qui facilite le rollback. Le risque est que cela masque des surprises : une requête que vous pensiez sûre peut être routée vers une réplique et montrer des résultats obsolètes.
Rendre le système résilient (et facile à annuler)
Considérez primaire et réplique comme des ressources différentes, pas comme des hôtes interchangeables. Utilisez des connexions séparées et des pools séparés pour éviter qu'une réplique lente n'encombre le pool des écritures.
Un petit ensemble de règles de sécurité prévient la plupart des incidents :
- Après une écriture utilisateur, laissez-le « collé » au primaire pendant une courte fenêtre (souvent quelques secondes).
- Par défaut, utilisez le primaire pour tout ce qui implique l'argent, l'auth, les permissions ou du contenu utilisateur juste après création.
- Ajoutez un kill switch qui redirige toutes les lectures vers le primaire instantanément (flag de config, variable d'environnement, feature flag), et testez-le.
- Définissez des timeouts agressifs pour les lectures sur réplique et retombez sur le primaire au lieu d'échouer la requête.
Exemple : un tableau de bord charge 12 widgets. Routez les widgets lents et non critiques (graphiques hebdomadaires, pages principales) vers la réplique, mais gardez « plan actuel » et « dernière facture » sur le primaire. Si la réplique accuse du retard, la page fonctionne toujours ; seul les graphiques seront un peu en retard.
Comment gérer le retard de réplication en toute sécurité
Le retard de réplication est le temps qu'il faut pour que les nouvelles données écrites sur le primaire apparaissent sur la réplique. Si votre app lit sur la réplique trop tôt, les utilisateurs peuvent voir des informations anciennes et penser qu'il y a un bug.
Commencez par définir ce que signifie « obsolescence sûre » pour votre produit. Pour un tableau de bord, être en retard de 5 à 30 secondes peut être acceptable. Pour la facturation, les mots de passe ou les permissions, même 1 seconde peut être trop.
Règles pratiques pour éviter les surprises
Quelques règles couvrent la plupart des cas réels :
- Utilisez la lecture-après-écriture : après qu'un utilisateur met à jour quelque chose, routez les prochaines requêtes de cet utilisateur vers le primaire (ou vers l'enregistrement concerné).
- Gardez les écrans critiques sur le primaire : paiements, connexion, contrôle d'accès et tout ce qui peut bloquer quelqu'un.
- Si vous devez afficher des données de réplique sur un écran critique, affichez un état « en cours de mise à jour » et évitez d'affirmer que c'est définitif.
- Détectez le retard et cessez d'utiliser la réplique quand il devient trop élevé.
- Évitez de mélanger résultats du primaire et de la réplique dans la même réponse (cela crée des combinaisons impossibles).
Exemple concret : un utilisateur change son e-mail et arrive sur sa page de profil. Si cette page lit depuis la réplique, elle peut encore afficher l'ancien e-mail. Avec la lecture-après-écriture, vous routez ce profil vers le primaire pendant 30 à 60 secondes après la mise à jour. Après cette fenêtre, les lectures normales depuis la réplique sont acceptables.
Le routage sensible au retard compte aussi pendant les pics et les déploiements. Les répliques prennent souvent du retard quand le primaire est occupé ou qu'une longue requête apparaît. Si votre app peut mesurer le lag (ou utiliser un simple contrôle de seuil), vous pouvez renvoyer les lectures au primaire jusqu'à ce que la réplique rattrape son retard.
Ce qui casse en premier quand vous ajoutez une réplique
Les premières cassures sont souvent celles que les utilisateurs remarquent immédiatement : « J'ai sauvegardé, mais ça n'a pas changé. » Un petit délai peut devenir un gros problème de confiance.
Les tickets de support augmentent souvent quand des gens modifient un profil, changent des paramètres ou postent un commentaire, puis rafraîchissent et voient l'ancienne valeur. Prévoyez les moments « lire sa propre écriture », pas seulement plus de capacité.
Les vérifications d'auth et de permissions échouent aussi tôt. Si un utilisateur vient de monter en plan, a été ajouté à une équipe ou a perdu un droit, une lecture sur la réplique peut renvoyer l'état précédent. Cela mène à des « pourquoi suis-je toujours bloqué ? » ou pire, « pourquoi puis-je encore voir ça ? »
Les jobs en arrière-plan peuvent mal réagir également. Beaucoup de systèmes de job lisent une ligne pour décider s'il faut agir. Avec des lectures obsolètes, deux workers peuvent penser que le job est pendings et l'exécuter en double, ou le manquer parce que la réplique n'a pas encore les changements.
Même quand rien n'est vraiment cassé, l'interface peut paraître incohérente. La pagination et le tri peuvent sauter si une requête touche le primaire et la suivante la réplique en retard. Vous verrez des doublons, des éléments manquants ou des comptes de pages qui changent entre deux clics.
Les compteurs dérivent plus vite qu'on ne l'imagine : limites de débit, compteurs de vues, badges non lus, totaux de notifications. Si une requête incrémente sur le primaire et que la suivante lit depuis une réplique en retard, les chiffres peuvent reculer.
Par défaut, gardez ceci sur le primaire à moins d'une validation rigoureuse :
- Écrans juste après une écriture (sauvegarde, checkout, paramètres)
- Connexion, vérifications de permissions et lectures liées aux sessions
- Tables de type work-queue utilisées par des jobs en arrière-plan
- Tout ce qui dépend d'un ordre exact ou de comptes précis
- Limites, quotas et compteurs de badges
Erreurs et pièges courants
Le plus grand piège est d'envoyer tous les SELECT vers la réplique parce que ce sont « juste des lectures ». Beaucoup de lectures font partie d'un flux qui attend la dernière écriture : « créer un compte » puis « charger le profil », ou « ajouter au panier » puis « afficher le panier ».
Un autre problème fréquent est les dépendances lecture-après-écriture cachées. Une page de paramètres peut sauvegarder des préférences puis immédiatement les recharger. Un endpoint de connexion peut lire un enregistrement de session juste après l'avoir écrit. Si ces lectures touchent la réplique pendant un lag, l'application semble cassée même si l'écriture a réussi.
La gestion des connexions est une source de douleur silencieuse. Si vous partagez un pool de connexions pour primaire et réplique, l'app peut envoyer accidentellement des écritures à la réplique (ou appliquer des réglages réplique-only sur le primaire). Même quand ça « marche », le débogage devient plus difficile car les logs et métriques n'indiquent pas clairement quelle DB a servi la requête.
Le monitoring arrive souvent trop tard. Surveillez le lag, les erreurs de requêtes sur réplique et les requêtes lentes séparément, et alertez sur les changements soudains après les déploiements.
Quelques pièges à noter :
- Router par nom d'endpoint plutôt que par besoin de fraîcheur
- Oublier que les outils d'admin et les jobs tournent aussi et font des requêtes
- Ne pas tester le comportement en cas de panne (réplique down, pics de lag)
- Cacher des lectures lentes et les rendre obsolètes plus longtemps que prévu
- Ne pas avoir de bascule rapide vers le primaire
Planifiez un rollback avant la mise en production. Un feature flag forçant toutes les lectures vers le primaire peut vous faire gagner des heures.
Checklist rapide avant d'activer
Ne commencez pas par l'infrastructure. Commencez par un contrôle de sécurité pour ne pas échanger des pages lentes contre des bugs « pourquoi ma modification n'a pas été prise ? ».
- Listez vos écrans les plus lourds en lecture et indiquez la fraîcheur requise.
- Définissez une règle lecture-après-écriture (qui reste sur le primaire, combien de temps, quels écrans sont couverts).
- Mesurez le retard de réplication et décidez d'un seuil où vous cessez d'utiliser la réplique.
- Prouvez que vous avez un kill switch et qu'il fonctionne.
- Déployez progressivement et surveillez timeouts, taux d'erreur et incohérences visibles par les utilisateurs.
Exemple simple : accélérer un tableau de bord sans casser l'UX
Imaginez une petite SaaS. Le tableau de bord contient des graphiques, « top clients » et des filtres par date qui lancent des requêtes lourdes. La zone des paramètres gère la facturation, les membres d'équipe et les permissions. Le trafic augmente, le tableau devient lent et les écritures ralentissent aux heures de pointe.
C'est un bon moment pour envisager une réplique : pas parce que vous voulez une nouvelle base, mais parce que vous voulez que les lectures coûteuses cessent de concurrencer les écritures importantes.
Une séparation propre ressemble souvent à ceci :
- Rapports, exports et widgets analytiques du tableau de bord lisent depuis la réplique.
- Paramètres, permissions, invitations et tout ce qui doit refléter un changement immédiatement restent sur le primaire.
- Endpoints mixtes (par ex. cartes du tableau de bord qui affichent aussi le plan courant de l'utilisateur) lisent le plan depuis le primaire ou acceptent un court délai.
Ensuite, ajoutez une stickiness courte après les écritures. Si un utilisateur change un rôle de « Viewer » à « Admin » et est redirigé vers le tableau, lire depuis la réplique peut afficher l'ancien rôle pendant quelques secondes. Marquez la session « lire depuis le primaire jusqu'à l'instant X » (souvent 30 à 60 secondes) après une sauvegarde réussie. Pendant cette fenêtre, routez les lectures vers le primaire. Après expiration, revenez à la réplique.
Si vous héritez d'une base de code générée par IA où le routage lecture/écriture est déjà dispersé ou fragile, FixMyMess (fixmymess.ai) se concentre sur le diagnostic et la réparation des problèmes comme le split lecture/écriture non sûr et l'absence de basculements sur le lag, pour que les répliques améliorent les performances sans créer de bugs de correction.
Questions Fréquentes
Quel problème résout réellement une réplique de lecture ?
Une réplique de lecture aide lorsque le trafic de lecture est si important qu'il ralentit les écritures sur votre base principale. L'objectif est de garder le primaire réactif pour les mises à jour en déchargeant certaines requêtes en lecture uniquement vers une autre copie des données.
Si votre application semble lente mais que la base de données n'est pas réellement le goulet d'étranglement, une réplique ne résoudra pas le vrai problème.
Quand devrais-je ajouter une réplique plutôt que d'optimiser les requêtes ?
Utilisez une réplique quand vos requêtes les plus lourdes sont principalement des SELECT et que vous observez une dégradation de la latence des écritures lors des pics de lecture. Un signe courant est que quelques écrans (tableaux de bord, recherche, listes d'administration) consomment la majeure partie du temps CPU de la base.
Si la douleur vient d'une mauvaise conception de requête ou d'index manquants, corrigez cela en priorité avant d'ajouter de la complexité.
Quels endpoints sont généralement sûrs d'envoyer vers une réplique ?
Commencez par router des endpoints qui tolèrent des données légèrement obsolètes : widgets analytiques, fils d'activité, résultats de recherche et grandes tables d'administration sont de bons candidats. Ils génèrent souvent beaucoup de lecture sans nécessiter une fraîcheur parfaite.
Gardez le déploiement initial étroit pour pouvoir mesurer l'impact et annuler rapidement si les utilisateurs signalent des résultats déroutants.
Qu'est-ce qui doit toujours rester sur la base primaire ?
Conservez sur le primaire tout ce qui touche à l'argent, aux accès ou à une confirmation immédiate utilisateur. Cela inclut le paiement, l'état d'abonnement, la connexion, les vérifications de permissions et les pages consultées juste après une sauvegarde.
Ces flux nécessitent souvent de « lire sa propre écriture », et le retard de réplication peut faire paraître l'application cassée ou inconsistante.
Qu'est-ce que le retard de réplication et pourquoi est-ce important ?
Le retard de réplication est le délai entre l'écriture sur le primaire et la visibilité de ce changement sur la réplique. Avec une réplication asynchrone, la réplique est généralement un peu en retard, et sous charge elle peut prendre plusieurs secondes.
C'est pourquoi la décision d'ajouter une réplique concerne la correction fonctionnelle, pas seulement la vitesse.
Comment empêcher l'effet « je viens de mettre à jour, mais je vois toujours l'ancienne valeur » ?
Un réglage simple : après qu'un utilisateur a écrit, routez ses lectures vers le primaire pendant une courte fenêtre (souvent quelques secondes). Cela évite l'expérience « j'ai sauvegardé mais rien n'a changé ».
Vous pouvez implémenter cela via de la stickiness de session ou des règles de routage des requêtes pour les endpoints qui suivent des écritures.
Qu'est-ce qui casse en premier après l'ajout d'une réplique ?
La défaillance la plus courante est l'incohérence visible par l'utilisateur : quelqu'un modifie des paramètres, rafraîchit la page et voit l'ancienne valeur parce que la lecture a touché la réplique. Les changements de rôle ou d'accès qui n'ont pas encore atteint la réplique créent aussi des problèmes.
Les jobs d'arrière-plan peuvent mal se comporter si eux aussi prennent des décisions sur des lectures obsolètes et exécutent un travail en double ou manquent du travail à faire.
Quelles sont les plus grosses erreurs que font les équipes avec les répliques ?
Évitez d'abord d'envoyer tous les SELECT vers la réplique parce que beaucoup de lectures font partie d'un flux qui attend la dernière écriture : « créer un compte » puis « charger le profil », ou « ajouter au panier » puis « afficher le panier ».
Autres erreurs : dépendances lecture-après-écriture cachées, pool de connexions partagé entre primaire et réplique, et absence de monitoring du retard. Gardez les règles de routage simples et prévoyez un rollback rapide.
Comment rendre le routage vers la réplique sûr à annuler ?
Ayez un kill switch qui renvoie toutes les lectures vers le primaire instantanément, et testez-le avant d'en avoir besoin. Définissez des timeouts agressifs pour les lectures sur réplique et basculez vers le primaire plutôt que de faire échouer la requête.
Surveillez le retard de réplication et cessez d'utiliser la réplique lorsque le retard dépasse le seuil acceptable pour votre produit.
Que faire si mon codebase est désordonnée (ou générée par IA) et que le routage des lectures est risqué ?
Si la base de code a des accès à la DB dispersés, des écritures cachées dans des endpoints « lecture » ou aucune façon claire d'appliquer des règles lecture-après-écriture, ajouter une réplique peut provoquer des bugs déroutants. Dans ce cas, il vaut souvent mieux réparer le routage, le pooling et les basculements liés au retard avant d'ajouter une réplique.
FixMyMess aide les équipes à réparer le code généré par IA ou hérité où le split lecture/écriture est fragile, pour que les répliques améliorent les performances sans casser la correction.