Redimensionner les images sans timeout : workers et miniatures sûres
Apprenez à éviter les timeouts d'upload en déplaçant le redimensionnement vers des workers en arrière-plan, en limitant les dimensions et en stockant l'original séparément pour des uploads plus sûrs et rapides.
Pourquoi les téléversements d'images expirent en premier lieu
Quand un téléversement d'image expire, les utilisateurs voient généralement une animation qui ne se termine jamais, suivie d'un vague message « Upload failed ». Parfois l'upload réussit techniquement, mais la page se fige pendant que le serveur tente de finir le traitement de la photo.
La raison la plus courante est simple : la même requête qui reçoit le fichier essaie aussi de faire tout le travail lourd. Le téléversement est déjà plus lent qu'un appel API normal parce que vous transférez beaucoup de données sur le réseau. Si vous redimensionnez aussi l'image, générez plusieurs miniatures, la compressez et écrivez tout dans le stockage avant de répondre, vous dépendez de l'achèvement de toutes ces étapes avant qu'un délai d'attente ne survienne.
Le redimensionnement pendant une requête d'upload est imprévisible. Une photo qui a l'air normale peut être énorme (très haute résolution, conversion de format, métadonnées supplémentaires). Les bibliothèques d'images peuvent aussi provoquer des pics de CPU et de mémoire. Une seule image « problématique » peut prolonger une requête, et sous charge elle peut ralentir d'autres requêtes aussi.
La situation empire quand des gens téléversent depuis des réseaux mobiles, plusieurs images à la fois, ou que le trafic augmente et que votre serveur dispose de moins de cycles CPU libres.
Une solution fiable est l'approche « original + dérivés » : sauvegardez rapidement l'original, renvoyez un succès, puis créez les versions redimensionnées plus tard. Ces versions redimensionnées (miniatures, aperçus) sont des dérivés parce que vous pouvez les recréer à tout moment à partir de l'original.
Si vous voulez des uploads fiables, considérez le point de terminaison d'upload comme une étape d'ingestion rapide, pas comme un laboratoire photo. Tout ce qui peut être fait plus tard doit être fait plus tard.
Pourquoi le redimensionnement et les miniatures sont si coûteux
Redimensionner n'est pas juste « sauvegarder un fichier ». C'est du travail CPU : décoder une grande image, garder les pixels en mémoire, les transformer, puis encoder un nouveau fichier. Si vous faites cela pendant une requête web, vous êtes en compétition avec tout le reste que cette requête doit faire, comme les vérifications d'auth, les écritures en base et les opérations de stockage.
Les photos modernes de téléphone sont volumineuses même si elles paraissent ordinaires à l'écran. Une image de 12 MP fait environ 4000 x 3000 pixels. Pour la redimensionner, votre serveur l'expanse souvent en pixels bruts d'abord, ce qui peut temporairement utiliser des dizaines de mégaoctets par image. Avec plusieurs uploads concurrents, ces pics s'additionnent vite.
La configuration fragile, c'est quand une requête tente de tout faire : accepter l'upload, le valider, le redimensionner, générer des miniatures, convertir les formats et sauvegarder les métadonnées. Le moindre ralentissement (CPU occupé, stockage plus lent, un hic réseau transitoire) peut faire dépasser le délai d'attente.
Le travail se multiplie aussi quand vous créez de nombreuses tailles. Un upload devient plusieurs cycles décoder-redimensionner-encoder plus plusieurs écritures en stockage. Même si chaque étape ne prend qu'une seconde ou deux, cela peut submerger un petit serveur en période de trafic réel.
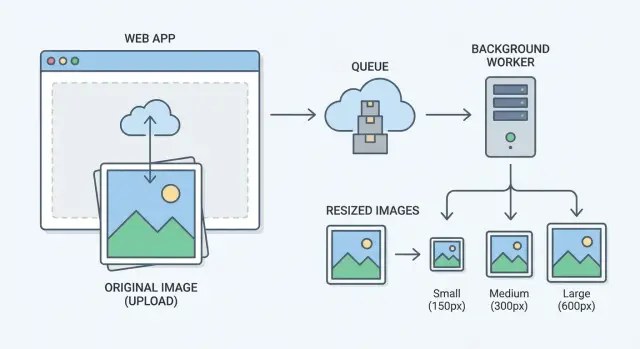
Une architecture simple et fiable : originaux + workers en arrière-plan
La façon la plus rapide d'arrêter les timeouts d'upload est de rendre les uploads ennuyeux. Votre point d'upload doit faire un seul travail : accepter le fichier, stocker l'original et répondre rapidement. Le redimensionnement, la compression et la génération des miniatures doivent se faire plus tard.
Une configuration simple ressemble à ceci :
- Le service d'upload valide le fichier et stocke l'original immédiatement.
- Une file de jobs enregistre « make thumbnails for image 123 » pour que le travail ne soit pas perdu sous la charge.
- Des workers en arrière-plan consomment les jobs et génèrent les versions redimensionnées.
- Les originaux sont stockés séparément des miniatures et autres dérivés.
- Le client affiche un espace réservé jusqu'à ce que la miniature soit prête.
Cela transforme « pas de timeouts » d'une promesse fragile en un résultat naturel. La requête d'upload reste petite et prévisible, tandis que les workers gèrent le gros du travail selon leur propre calendrier.
Vous pouvez garder une expérience utilisateur rapide. Après l'upload, l'API renvoie un ID d'image et un état comme « processing ». L'appli affiche la publication avec un espace réservé temporaire, puis remplace la miniature réelle une fois le worker terminé. En back-end, le worker met à jour un drapeau d'état (ou écrit des métadonnées aux côtés du dérivé) pour que l'appli sache que c'est prêt.
Un exemple réaliste : quelqu'un téléverse une photo de 12 Mo depuis un téléphone sur un Wi‑Fi lent. Si le serveur tente de redimensionner pendant la requête, la connexion peut tomber et l'utilisateur retente, créant des doublons. Avec une file et des workers, l'upload se termine, l'original est en sécurité, et le redimensionnement peut prendre 5 à 20 secondes sans bloquer l'utilisateur.
Pas à pas : implémenter la génération de miniatures en tâche différée
Séparez deux préoccupations : des uploads rapides pour les utilisateurs, et du travail image plus lent pour votre système. L'objectif est de garder la requête d'upload petite et prévisible.
1) Traiter l'upload rapidement
Validez le fichier immédiatement : type MIME, taille de fichier et dimensions de base. Si ça échoue, rejetez-le avant de stocker quoi que ce soit. Soyez strict pour qu'une photo surdimensionnée ou un format bizarre ne passe pas et n'étouffe pas les étapes suivantes.
Après validation, stockez l'image originale telle quelle. Créez un enregistrement image (un ID) et marquez-le comme « original saved » ou « processing ». Ne redimensionnez pas pendant la requête.
2) Créer un job en arrière-plan
Une fois l'original stocké, mettez en file un job avec seulement ce dont le worker a besoin : l'ID de l'image et les tailles cibles.
Un flux propre est :
- La requête d'upload valide et sauvegarde le fichier original.
- L'appli écrit une ligne image avec un statut comme « processing ».
- L'appli met en file un job avec
{image_id, sizes}. - Un worker charge l'original, génère les miniatures et stocke chaque dérivé.
- Le worker met à jour le statut en « ready » (ou « failed » avec une erreur).
3) Servir la meilleure taille disponible
Quand la page se charge, servez la plus petite miniature qui reste correcte pour cet écran. Si une miniature n'est pas encore prête, affichez un espace réservé (ou, si vous devez absolument, utilisez temporairement l'original) et réessayez plus tard.
Assurez-vous que l'UI gère proprement les états partiels. Un upload peut réussir pendant que les miniatures sont encore en traitement. L'appli doit afficher quelque chose de stable plutôt que de tourner indéfiniment.
Limiter les dimensions et standardiser les tailles pour contrôler la charge
Un upload surdimensionné peut poser plus de problèmes qu'une centaine de photos normales. Une image de 12 000 x 9 000 force votre serveur à décoder un tampon énorme, la redimensionner et la réencoder.
Fixez une largeur et une hauteur maximales strictes pour tout dérivé que vous générez, même pour les vues « grandes ». Conservez l'original séparément pour ne pas perdre de données, mais ne laissez pas l'original déterminer votre coût de traitement.
Choisir quelques tailles et des règles claires
Choisissez un petit jeu de tailles standard pour pouvoir mettre en cache, réutiliser et prévoir la charge. Par exemple :
- Small : 320 px de large (flux, listes)
- Medium : 800 px de large (pages détail)
- Large : 1600 px de large (lightbox)
Décidez quand recadrer vs adapter, puis appliquez la règle partout. Le recadrage est mieux pour des grilles cohérentes (avatars, vignettes produit). L'adaptation dans les limites est mieux quand l'image entière compte.
Les réglages de qualité et de format influent aussi sur le temps CPU. Une qualité trop élevée peut doubler le temps d'encodage pour un gain visuel minime. Points de départ raisonnables :
- Qualité JPEG : 75 à 85 pour les photos
- Qualité WebP : 70 à 80 si vous le supportez
- Supprimez les métadonnées sur les miniatures
- N'utilisez l'encodage progressif que si vous l'avez testé
Exemple : si quelqu'un téléverse une photo de 10 Mo et 6000 px, votre worker conserve l'original, puis génère des versions 320/800/1600 limitées à 1600 px max. L'UI reste rapide, et les workers restent prévisibles.
Stocker les originaux séparément et considérer les miniatures comme des dérivés
Conservez l'original téléversé comme un fichier source en lecture seule, même si votre appli sert principalement des images redimensionnées. Cela vous donne un fallback propre en cas de problème, et vous permet de générer de nouvelles tailles plus tard sans demander une ré‑upload aux utilisateurs. Cela évite aussi la perte de qualité en redimensionnant une image déjà redimensionnée.
Une bonne règle est de ne jamais écraser l'original pendant le traitement. Écrivez les dérivés dans un chemin ou un bucket différent, et n'utilisez un dérivé dans l'UI que lorsqu'il est entièrement généré.
Nommer les dérivés pour qu'ils soient faciles à trouver
Rendez les clés des dérivés prévisibles. Utilisez un ID d'image stable plus un label de taille, et traitez l'original comme une variante spéciale.
Par exemple, si l'original est lié à l'ID img_7F3, vous pouvez stocker :
img_7F3/originalimg_7F3/w_200_h_200_fillimg_7F3/w_1200_fit
Cela simplifie les recherches : l'appli peut demander une taille spécifique sans deviner les noms de fichiers, et les workers peuvent régénérer des dérivés sans scanner tout le stockage.
Stocker des métadonnées pour garder l'appli honnête
Suivez ce que vous avez et ce qui est en attente. Dans votre base, stockez la largeur/hauteur originale, le type de contenu et un statut des dérivés.
Un petit ensemble de champs :
- Dimensions originales et taille du fichier
- Statut de traitement (pending, ready, failed)
- Quelles tailles existent (et quand elles ont été générées)
- Checksum optionnel pour détecter les doublons
Si un dérivé échoue, l'UI peut continuer d'afficher un espace réservé pendant que la tentative de réessai tourne.
Garder les workers stables : limites, réessais et visibilité
Les workers sont l'endroit où vous gagnez ou perdez en fiabilité. Si la file de redimensionnement surcharge les CPU, se bloque ou échoue silencieusement, les utilisateurs le ressentiront, juste plus tard.
Commencez par des limites de concurrence. Le redimensionnement est gourmand en CPU et mémoire. Un pic d'uploads peut priver le reste de votre appli. Plutôt que d'exécuter le plus de jobs possible, commencez petit (souvent 1 à 4 jobs par hôte) et scalez seulement quand vous pouvez en voir l'impact.
Les réessais aident, mais seulement avec backoff. Beaucoup d'échecs sont temporaires : problèmes de stockage brefs, redémarrages, courtes pertes réseau. Réessayer instantanément peut créer un entassement. Utilisez un backoff exponentiel avec jitter et un nombre max de tentatives raisonnable, puis marquez le job comme failed.
Ajoutez aussi des limites de temps. Un job de redimensionnement ne devrait jamais tourner indéfiniment. Mettez un timeout dur par job, et enregistrez les erreurs avec assez de contexte pour déboguer (type de fichier, dimensions et identifiants que vous pouvez rechercher).
Enfin, ajoutez de la visibilité pour détecter les problèmes tôt : profondeur de la file, taux d'échec des jobs, temps de traitement médian et p95, et âge du job le plus ancien.
Erreurs communes qui causent encore des timeouts
Les timeouts réapparaissent souvent après que vous ayez « corrigé » les uploads une fois, puis que le trafic augmente ou que quelqu'un téléverse une photo énorme.
La plus grosse erreur est encore de faire le redimensionnement pendant la requête web parce que ça paraît plus simple. Ça marche en test, puis quelques gros uploads arrivent en même temps et votre serveur consomme tout son budget de requêtes à décoder et compresser des images. Les requêtes s'accumulent, d'autres pages ralentissent, et les uploads échouent.
Un autre problème est de générer trop de tailles. Si vous créez 8 à 12 tailles par upload et que vous les traitez toutes en même temps, vous pouvez encore surcharger les workers. La solution la plus sûre est moins de tailles standard et seulement celles dont vous avez vraiment besoin.
L'absence de garde‑fous sur les entrées est aussi fréquente. Une seule image 8000 x 8000 peut consommer la mémoire et faire planter les workers. Pour l'utilisateur, cela peut donner l'impression que « ça ne se termine jamais » parce que le job ne se termine pas.
Les pièges récurrents :
- Redimensionner ou compresser dans le handler de requête, même « juste pour la première miniature »
- Créer beaucoup de tailles par upload et les traiter toutes dans un seul job
- Accepter des dimensions ou des tailles de fichier illimitées
- Servir par erreur les originaux dans l'UI au lieu des miniatures
- Ne pas gérer les états partiels (original sauvegardé, miniatures encore en attente)
Les états partiels sont sournois. Si la page suppose que les miniatures existent tout de suite, elle peut se remettre à réessayer, bloquer le rendu ou déclencher des traitements répétés. Affichez un espace réservé jusqu'à ce que le dérivé soit prêt, et rendez la génération idempotente pour que les réessais soient sûrs.
Checklist rapide avant la mise en production
Traitez la route d'upload comme un agent de circulation, pas comme un atelier. L'upload doit accepter le fichier, le stocker et répondre rapidement, même quand quelqu'un envoie une photo énorme depuis un téléphone moderne.
Avant la sortie, testez avec quelques images cas extrêmes (très grandes dimensions, JPEG haute qualité, PNG avec transparence). Surveillez le parcours depuis l'upload jusqu'à l'affichage de la miniature.
Checklist :
- La requête d'upload finit vite et n'attend jamais le redimensionnement.
- Le fichier original est stocké immédiatement et l'enregistrement est clairement marqué comme processing.
- Un job en arrière-plan est créé immédiatement et les workers le récupèrent rapidement.
- Les miniatures sont écrites à des emplacements prévisibles et vous vérifiez leur présence après traitement.
- L'UI gère l'écart : elle affiche un espace réservé et remplace les miniatures à leur arrivée.
Un test simple : téléversez une photo de 12 Mo sur une connexion lente, puis rafraîchissez la page. Vous devriez voir un résultat stable à chaque fois : l'entrée image existe, l'appli ne tourne pas indéfiniment, et les miniatures apparaissent un peu plus tard.
Scénario exemple : corriger les uploads photo dans une vraie appli
Une petite appli marketplace permet aux vendeurs d'uploader 5 à 10 photos de téléphone par annonce. La plupart des images font 3 à 8 Mo, et certaines dépassent 4000 px de large. Tout semble OK en test, mais le soir, les uploads commencent à échouer.
La cause racine est que l'appli redimensionne les images et génère les miniatures dans la même requête qui sauvegarde l'annonce. Quand plusieurs utilisateurs cliquent sur « Post listing » en même temps, le serveur est occupé à décoder de grands JPEG, les redimensionner et écrire plusieurs fichiers. Les requêtes s'empilent, les autres pages ralentissent et les uploads échouent.
La correction ne nécessite pas de gros changements d'UI. Conservez le flux, mais changez ce qui se passe en coulisse :
- Sauvegardez rapidement l'image originale (stockage objet ou bucket séparé).
- Créez un enregistrement en base pour chaque image avec un statut pending.
- Poussez un job dans une file d'arrière-plan pour générer des miniatures standards.
- Affichez l'annonce immédiatement en utilisant une miniature placeholder jusqu'à la fin du job.
Si certaines miniatures échouent, traitez-le comme un problème opérationnel plutôt qu'une erreur visible par l'utilisateur. Remettez le job en file quelques fois avec un court délai. Après le dernier réessai, conservez l'original disponible, continuez d'afficher le placeholder et déclenchez une alerte pour inspecter le fichier qui a cassé le redimensionnement.
Prochaines étapes : fiabiliser, puis faciliter la maintenance
Une fois que les uploads ne expirent plus, l'objectif est de conserver cet état quand l'appli grandit. Le plus gros gain est d'écrire quelques règles pour que tout le monde construise de la même façon dans les mois qui viennent.
Commencez par un court « contrat image » qui inclut vos tailles de miniatures, les dimensions et tailles max acceptées, les formats et réglages de qualité de sortie, ce que signifie « ready », et ce qui arrive en cas d'échec.
Ajoutez juste assez de visibilité pour détecter les problèmes tôt. Deux métriques suffisent souvent : la durée des requêtes d'upload (p95) et le temps de traitement des jobs de miniatures (p95). Si l'une ou l'autre augmente, vous le verrez avant que les utilisateurs ne se plaignent.
Si vous avez déjà des images en production, planifiez un backfill sûr. Évitez de lancer un gros batch qui entre en concurrence avec le trafic réel. Générez les miniatures par petits lots, limitez la concurrence et suivez la progression pour pouvoir mettre en pause et reprendre.
Si vous avez hérité d'un prototype généré par IA où les uploads sont fragiles (hangs aléatoires, règles de stockage confuses, limites workers manquantes), une passe de remédiation peut être plus rapide que d'essayer de colmater les symptômes. FixMyMess (fixmymess.ai) se concentre sur le diagnostic et la réparation de codebases générés par IA, y compris le déplacement du traitement d'images vers des workers, l'ajout de garde‑fous et le durcissement de la pipeline pour la production.
Questions Fréquentes
Why do image uploads time out even when the server seems fine?
Cela signifie généralement que votre serveur essaie d'en faire trop dans la même requête : recevoir le fichier, le redimensionner, encoder de nouvelles versions et écrire plusieurs sorties avant de répondre. Sous charge ou avec une photo volumineuse, ce travail dépasse le délai d'attente de la requête.
Should I resize images during the upload request?
Non. Sauvegardez d'abord l'original et renvoyez un succès, puis générez les miniatures en arrière-plan. Si vous devez afficher quelque chose immédiatement, affichez un espace réservé et remplacez-le par la miniature quand elle est prête.
Why is thumbnail generation so CPU and memory expensive?
Les images modernes ont beaucoup de pixels même si elles semblent normales à l'écran. Le redimensionnement demande de décoder en pixels bruts, d'utiliser beaucoup de mémoire et de CPU, puis de réencoder, ce qui peut provoquer des pics d'utilisation et ralentir d'autres requêtes.
What’s the simplest architecture to stop upload timeouts?
Stockez rapidement l'original, mettez en file un job avec l'ID de l'image et les tailles cibles, et laissez des workers en arrière-plan générer les dérivés. Votre API peut renvoyer un ID et un état “processing” pour que l'interface reste réactive pendant que le worker termine.
How should the client behave while thumbnails are still processing?
Traitez les téléversements comme un état en deux étapes : « uploaded » et « ready ». Après le succès de l'upload, affichez une miniature d'attente stable, et interrogez ou actualisez les métadonnées jusqu'à ce que le dérivé soit disponible, puis remplacez-la sans bloquer la page.
Do I really need to cap image dimensions and file size?
Oui. Un plafond ferme sur les dimensions et la taille des fichiers empêche une seule image énorme d'épuiser la mémoire ou de faire planter les workers. Conservez l'original, mais veillez à ce que vos dérivés ne dépassent jamais la largeur/hauteur max pour que le coût de traitement reste prévisible.
How many thumbnail sizes should I generate?
Choisissez un petit ensemble de largeurs standard qui couvrent votre UI, comme flux, détail et vue large. Moins de tailles signifie moins de calcul, moins de stockage, des caches plus simples et moins de points de défaillance, tout en restant esthétique sur les appareils.
Why store originals separately from thumbnails?
Considérez l'original comme la source de vérité et ne l'écrasez jamais. Les dérivés peuvent être régénérés à tout moment, ce qui rend les réessais sûrs, permet d'ajouter des tailles plus tard et évite la perte de qualité due à des redimensionnements successifs.
What worker settings prevent the resize queue from becoming the new bottleneck?
Commencez avec une faible concurrence pour que les workers ne privent pas le reste de votre application de ressources, puis scalez en fonction des métriques réelles. Ajoutez des timeouts par job, des réessais avec backoff et un bon logging d'erreurs pour éviter que des échecs ne laissent des images bloquées en “processing”.
What if my AI-built app keeps breaking uploads and I’m not sure where to start?
Si votre projet est un prototype généré par IA avec des uploads qui bloquent, des secrets exposés ou des règles de stockage confuses, il est souvent plus rapide de faire une passe de remédiation ciblée que de recoller les symptômes. FixMyMess (fixmymess.ai) peut auditer la pipeline, déplacer le redimensionnement vers des workers, ajouter des garde-fous et stabiliser les uploads pour la production.