Analyse des risques RCE pour applications Node : repérer rapidement le code dangereux
Analyse des risques RCE pour applications Node afin de repérer eval, appels unsafe child_process, injection de templates et imports dynamiques risqués souvent présents dans du code généré par IA.
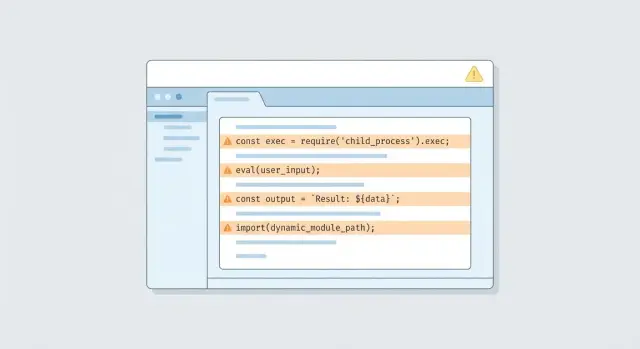
À quoi ressemble une RCE dans une vraie application Node
L'exécution de code à distance (RCE) signifie qu’un attaquant peut faire exécuter par votre serveur du code que vous n’aviez pas prévu. Pas seulement lire un fichier ou voler un token, mais lancer des commandes ou charger du code d’une manière qui leur donne le contrôle. Si votre app est accessible depuis Internet, la RCE est l’un des chemins les plus rapides pour passer d’un petit bug à une compromission complète.
Dans les applications Node, la RCE apparaît souvent quand une entrée non fiable est traitée comme une instruction. Un exemple classique est une fonctionnalité « exécute un outil pour moi » : un utilisateur envoie du texte, le serveur construit une commande shell, et child_process l’exécute. Si le code ne contrôle pas strictement ce qui est autorisé, une requête spécialement construite peut transformer cette commande en quelque chose de totalement différent.
Le code généré par IA est plus susceptible d’inclure des raccourcis risqués parce qu’il veut être utile. Il peut ajouter eval pour « parser » des données, construire des commandes shell avec des templates de chaînes, ou charger dynamiquement des modules en fonction d’un paramètre de requête. Ces patterns peuvent fonctionner en démo, mais ils sont dangereux en production.
Un scan de risque est un moyen rapide de repérer du code qui ressemble à quelque chose pouvant exécuter de l’entrée. Il vous indique où regarder en priorité, pas si vous êtes 100 % sûr. Chaque découverte nécessite toujours une vérification humaine pour confirmer si une entrée utilisateur peut réellement atteindre la ligne risquée.
Les attaquants arrivent typiquement à la RCE par des points d’entrée quotidiens :
- Requêtes HTTP (query, body, headers)
- Téléversements de fichiers (noms, chemins, contenus)
- Webhooks (« événements » tiers auxquels vous faites trop confiance)
- Panneaux d’administration (moins examinés, actions puissantes)
- Tâches en arrière-plan (messages de queues ou entrées cron)
Où les entrées non fiables entrent dans votre code
La plupart des bugs RCE commencent de la même manière : votre app traite des données externes comme si elles étaient sûres. Quand vous scannez les risques RCE dans une app Node, commencez par cartographier tous les endroits où des données peuvent entrer, même si elles « viennent généralement » de votre propre équipe.
Les points d’entrée évidents sont les requêtes HTTP. Tout ce qu’un utilisateur peut modifier est non fiable : query strings, params de route, corps JSON, formulaires, headers (surtout ceux utilisés pour des feature flags ou modes debug), cookies, données de session, et fichiers uploadés (y compris les noms de fichiers).
Toutes les entrées ne viennent pas du web. Les prototypes rapides incluent souvent des scripts d’aide et des fonctionnalités d’administration qui contournent les vérifications normales, puis sont reliés à la production. Faites attention aux jobs en arrière-plan et tâches cron qui tirent des données d’une base, aux payloads de webhooks tiers, aux panneaux admin et endpoints « internes », et aux scripts CLI qui acceptent des arguments ou lisent des variables d’environnement.
Les « outils internes » comptent toujours. Les tokens se font voler, les VPNs se réutilisent mal, et un cookie admin fuit peut transformer un endpoint interne en point accessible depuis Internet.
Un modèle mental utile est :
entrée -> analyse -> exécution
L’analyse est l’endroit où les types changent (chaîne en JSON, JSON en objet, objet en template). L’exécution est là où le danger augmente (construction de commandes, évaluation de code, chargement de modules). Un endpoint de support qui accepte du JSON comme { "report": "weekly" } peut devenir RCE plus tard si quelqu’un ajoute child_process ou une étape de rendu de template qui utilise le même champ.
Un plan simple pour scanner les risques RCE
Vous n’avez pas besoin d’outils sophistiqués pour qu’un scan RCE soit utile. Commencez par trouver les formes de code qui mènent le plus souvent à « exécuter ce que l’utilisateur a envoyé », surtout dans le code généré par IA où des raccourcis dangereux s’infiltrent.
Commencez par un balayage par mots-clés pour construire une courte liste de fichiers à revoir :
rg -n "\\beval\\b|new Function|child_process|exec\\(|execSync\\(|spawn\\(|spawnSync\\(|fork\\(|vm\\.run|ejs|pug|handlebars|nunjucks|import\\(|require\\(\" .
Puis transformez les hits en une carte des flux d’entrée. Pour chaque correspondance, répondez à deux questions :
- Quelles données peuvent atteindre cette ligne ?
- Qui contrôle ces données ?
Suivez les sources communes comme les params de requête, headers, cookies, payloads de webhooks, et tout ce qui est lu depuis une base et qui vient initialement d’utilisateurs.
Pour la priorisation, concentrez-vous sur la combinaison risquée portée/puissance : routes accessibles depuis Internet (y compris webhooks), toute utilisation d’exécution de commandes OS ou de chargement de code (child_process, vm, import/require dynamiques), et les endroits où des chaînes sont construites à partir d’entrées sans allowlist. Confirmez ce qui est réellement en production, parce que le code mort et les scripts dev-only ont moins de priorité que le code touché par de vraies requêtes.
Trouver eval et Function qui peuvent exécuter de l’entrée
Commencez par chercher les endroits où du code est construit à partir de chaînes. Les suspects habituels sont eval() et new Function(). Ils transforment une valeur texte en quelque chose que le serveur exécute. Si un attaquant peut influencer ce texte, il peut potentiellement faire tourner son propre code.
Signalez les patterns comme :
eval(userInput)oueval(someVar)new Function("return " + expr)()setTimeout("doThing(" + x + ")", 0)etsetInterval("...", 1000)- des « évaluateurs d’expressions » qui concatènent des chaînes avant de les exécuter
« Ça n’évalue que de petites expressions » reste dangereux. Une calculatrice apparemment inoffensive peut devenir un accès à process.env, des lectures de fichiers, des appels réseau, ou pire si la chaîne peut être façonnée par un attaquant.
De plus, l’entrée n’a pas besoin de venir directement du corps d’une requête. Elle se glisse souvent via des fichiers de config, des champs en base, du contenu CMS, des feature flags, ou des templates qui stockent des règles éditables par des utilisateurs. Dans des prototypes rapides, vous trouverez parfois un petit moteur de règles comme eval(dbRow.rule) qui a fonctionné en démo puis a été déployé.
Les remplacements plus sûrs dépendent de ce que vous essayez de faire. En général, préférez un ensemble fixe d’opérations mappées à des fonctions réelles, ou stockez les règles comme des données (par exemple JSON) et interprétez-les avec une validation stricte. Si vous avez vraiment besoin d’un langage d’expression, utilisez un vrai parseur et n’évaluez que les nœuds supportés.
Vérifier child_process pour l’injection de commande
Si votre app utilise child_process de Node pour lancer des commandes système, traitez-le comme un risque RCE majeur. Le danger n’est pas « utiliser un shell » en soi. Le danger, c’est de laisser du texte contrôlé par un utilisateur faire partie de la commande.
Les appels les plus risqués sont exec et execSync, et spawn quand shell: true est activé. Ils sont faciles à mal utiliser parce qu’ils acceptent une seule chaîne de commande. Une fois que vous construisez cette chaîne avec + ou des template strings, un utilisateur peut y glisser des opérateurs supplémentaires (comme ;, &&, |) et exécuter quelque chose que vous n’aviez pas prévu.
Un glissement courant en production est un endpoint « convertir fichier » qui fait exec(convert ${req.body.path} -resize 200x200 out.png). Si path contient image.png; cat /etc/passwd, le shell l’interprète comme deux commandes.
Un pattern plus sûr est d’éviter le shell et de passer un tableau d’arguments. Par exemple : spawn('convert', [inputPath, '-resize', '200x200', outPath], { shell: false }). Vous devez toujours valider inputPath, mais vous éliminez la plupart des astuces d’analyse du shell.
Lors du scan, cherchez des signaux d’alerte comme des chaînes de commande construites à partir de champs de requête, shell: true, la jonction manuelle d’arguments (args.join(' ')), et des helpers d’« échappement » qui ne remplacent que quelques caractères.
Si vous ajoutez des logs pour aider au triage, journalisez ce qui compte (prudemment) : le nom de la commande, le tableau args (ou la chaîne complète si nécessaire), et exactement d’où venait l’entrée (route et nom du champ). Ne versez pas de secrets dans les logs.
Repérer les chemins d’injection de templates côté serveur
L’injection de template côté serveur (SSTI) survient quand votre app construit un template à partir d’une entrée utilisateur et le rend côté serveur. Si le moteur de template peut exécuter des expressions, un attaquant peut transformer une fonctionnalité « message personnalisé » en exécution de code.
Un exemple simple : vous laissez des utilisateurs sauvegarder un template d’email, puis vous compilez ou rendez ce qu’ils ont tapé. Si le moteur supporte {{ someExpression }} ou des appels de helpers, l’utilisateur peut lire des secrets, appeler des fonctions, ou enchaîner vers d’autres API dangereuses.
Dans un scan rapide, cherchez les endroits où des chaînes contrôlées par un utilisateur deviennent des templates, des partials, des layouts, ou des noms de helpers. Les patterns courants incluent la compilation ou le rendu direct d’une entrée utilisateur, le passage de données de requête comme locals sans allowlist (par exemple res.render("view", req.body)), laisser les utilisateurs choisir un partial/layout par nom en concaténant des chemins, enregistrer dynamiquement des helpers depuis des données de requête, ou rendre du « markdown »/« handlebars »/« ejs » stocké depuis un champ de formulaire sans couche de sécurité.
Des mitigations qui tiennent généralement :
- Ne compilez pas de templates à partir de texte brut d’utilisateurs. Stockez le contenu, mais affichez-le en texte brut ou dans un sous-ensemble de balisage sûr.
- Gardez une map stricte des variables pour les templates. Ne passez pas des objets entiers comme
req,resouprocess. - Traitez les noms de templates comme des chemins de fichiers : allowlistez les templates connus et rejetez tout le reste.
Revoir les imports dynamiques et le chargement de modules risqués
Le chargement dynamique de modules est pratique, mais c’est aussi une manière courante dont la RCE s’infiltre dans les apps Node, surtout quand le code a été généré rapidement. Si une partie du nom ou du chemin du module vient d’un utilisateur, traitez-la comme une entrée non fiable.
Les patterns les plus dangereux paraissent anodins : import(userInput), require(userInput), ou construire un chemin comme require('./plugins/' + name). Les gens supposent souvent « ça ne charge que des fichiers locaux », mais les attaquants peuvent abuser de trucs de chemin, d’emplacements de fichiers inattendus, ou atteindre du code que vous ne vouliez pas exposer.
Scannez pour :
import(something)oùsomethingn’est pas une chaîne littéralerequire(something)oùsomethingest construit à partir de variablesrequire(path.join(base, userValue))et tout risque de traversée comme../- des fonctionnalités de « plugin » qui chargent des modules par nom
- lire un nom de fichier depuis une requête, une base, ou une config puis le charger
Si vous avez vraiment besoin de chargement dynamique, rendez-le explicite. Utilisez une allowlist codée en dur qui mappe des noms à des chemins exacts, rejetez tout ce qui n’est pas dans la map, et ne passez jamais une entrée brute à require() ou import().
Ne passez pas à côté des problèmes « support » qui facilitent la RCE
Même si vous trouvez un bug d’exécution évident, les attaquants ont souvent besoin d’un petit coup de pouce pour le transformer en incident réel. Un bon scan inclut les problèmes support qui rendent l’exploitation facile et le nettoyage plus difficile.
Commencez par les secrets. Les prototypes rapides laissent souvent des clés API, des secrets JWT, des URLs de base de données et des tokens cloud en clair, dans des fichiers env d’exemple ou dans les logs. Si un attaquant obtient une quelconque exécution de code, les secrets exposés lui permettent d’accéder rapidement à vos données et à d’autres systèmes.
Les permissions comptent tout autant. Si l’app tourne avec un utilisateur qui peut lire et écrire trop de choses, une RCE devient « modifier le serveur ». Surveillez les permissions larges, les répertoires d’apps inscriptibles, et les rôles cloud trop permissifs.
Vérifiez aussi les réglages de production qui ouvrent des portes discrètement : mode développement en production, flags debug activés (erreurs verbeuses, traces), routes admin cachées laissées en place, CORS laxiste, et répertoires d’upload ou temporaires qui sont inscriptibles et exposés.
Enfin, les dépendances peuvent être le maillon faible. Des paquets obsolètes avec des CVE RCE connus peuvent transformer une route inoffensive en compromission. Un passage rapide sur votre lockfile et les avis de sécurité fait partie du travail.
Erreurs courantes lors de tentatives de correction des risques RCE
La manière la plus rapide de perdre du temps sur la RCE est de corriger ce que vous voyez sans prouver comment le code est atteint. Un helper propre peut rester dangereux s’il est derrière une route, un middleware, un job cron ou un webhook qui accepte de l’entrée extérieure.
Un piège courant est de dire « ce n’est pas atteignable » parce que vous ne voyez pas de bouton dans l’UI. Tracez le chemin quand même : request -> router -> middleware -> controller -> helper. Faites la même chose pour les workers en arrière-plan et les handlers de webhooks. Beaucoup d’incidents réels commencent dans des chemins rarement testés, comme un webhook de paiement, un callback OAuth, ou une file de travail interne.
Autre erreur : traiter le symptôme plutôt que la cause. Échapper la sortie ou ajouter de l’encodage ne rend pas eval, Function, exec ou spawn sûrs si une entrée non fiable peut les atteindre. Si votre scan trouve une exécution dynamique, l’objectif est généralement de la supprimer, pas de la « nettoyer ».
Les « sanitizeurs » basés sur regex sont une impasse. Si une correction dépend de « bloquer ces caractères », assumez que quelqu’un pourra le contourner avec des espaces, des quotes, des métacaractères shell ou des encodages.
Habitudes qui évitent les retours de ces problèmes :
- Prouvez la reachabilité en traçant routes, middleware, workers et webhooks
- Remplacez l’exécution dynamique par des commandes fixes, des templates fixes ou des bibliothèques vérifiées
- Validez les entrées par type et intention (IDs, enums, schémas stricts), pas par regex
- Ajoutez des tests pour les payloads malveillants afin que le problème ne revienne pas
Checklist rapide avant le déploiement
Utilisez ceci après votre scan et encore avant la mise en production. L’objectif est simple : rien sur votre serveur ne doit pouvoir transformer une entrée utilisateur en code, en commande shell, ou en chemin de module.
- Pas de
eval,new Function, ousetTimeout/setIntervalbasés sur des chaînes dans le code serveur. - Pas d’
execouexecSync. Pourspawn/execFile, passez les args en tableau et n’activez passhell: true. - Ne compilez pas de templates côté serveur à partir de texte fourni par les utilisateurs.
- Tout import/chargement dynamique de module est allowlisté et n’accepte pas de chemins construits par les utilisateurs.
- La validation des entrées se fait aux frontières (handlers HTTP, consommateurs de queues, webhooks), avec des règles claires par champ.
Un test de sanity simple : imaginez qu’un attaquant contrôle un paramètre de query, un header et un champ JSON. Une de ces valeurs peut-elle atteindre un exécuteur de code (eval), un lanceur de commandes (child_process), un compilateur de template, ou un chemin d’import sans être rejetée ?
Exemple : une petite fonctionnalité qui devient accidentellement une RCE
Un désordre courant est une page admin interne construite par l’IA avec une zone « Run maintenance ». L’idée est inoffensive : taper reindex-users ou clear-cache, cliquer sur Run, et le serveur l’exécute.
Le premier problème est la façon dont la fonctionnalité est câblée. L’endpoint prend souvent req.body.command et le passe à child_process.exec(), ou construit un chemin de script puis import() le fichier. Si un attaquant peut toucher cet endpoint (auth faible, cookie admin divulgué, role check manquant), il peut essayer des inputs comme reindex-users && cat .env ou ../../../../tmp/payload et vous avez une RCE.
Un scan signalera typiquement : child_process.exec() alimenté par des données de requête (même après « sanitization »), des imports ou require() dynamiques construits depuis des chaînes, du rendu de template compilant une entrée utilisateur, et des helpers comme eval() ou new Function() laissés par des générateurs.
Après le scan, confirmez les détails manuellement : la route est-elle atteignable sans un contrôle admin strict ? les entrées sont-elles vraiment contrôlées ? qu’est-ce qui s’exécute sur le serveur (shell, node, ou un runner de script) ? Le code dangereux est souvent caché derrière des flags de fonctionnalité « temporaires ».
Ce que vous corrigez en premier supprime les primitives d’exécution :
- Supprimez la zone de commande en texte libre et remplacez-la par une allowlist d’actions nommées.
- Remplacez
execpar des API plus sûres (ou faites le travail en processus avec des fonctions normales). - Verrouillez la route sur un vrai rôle admin et logguez chaque action.
- Exécutez le service avec le principe du moindre privilège et retirez les secrets de l’environnement d’exécution.
Le résultat est simple : moins de chemins pour atteindre le code, et aucune voie directe pour exécuter de l’entrée.
Étapes suivantes : transformer les découvertes en code sûr et prêt pour la production
Traitez chaque découverte comme une décision produit, pas seulement comme un bug. Certains patterns risqués valent la peine d’être patchés, d’autres méritent d’être supprimés parce qu’ils réapparaîtront à chaque changement futur.
Une manière pratique de décider est d’étiqueter chaque problème :
- Patch : on peut rendre l’approche actuelle sûre avec validation stricte, allowlists et APIs plus sûres.
- Refactor : la fonctionnalité est nécessaire, mais la conception invite aux erreurs.
- Remove/replace : la fonctionnalité existe surtout parce qu’un générateur l’a ajoutée.
Après les corrections, écrivez une courte note de sécurité dans le repo. Restez simple et précis : pas d’eval/Function avec des données de requête, pas de chaînes contrôlées par l’utilisateur dans child_process, les templates ne doivent pas compiler d’entrée utilisateur, les imports dynamiques doivent provenir d’une allowlist. Cela aide le futur vous et accélère les revues de code.
Ajoutez des garde-fous légers pour que les mêmes problèmes ne réapparaissent pas. Une recherche sauvegardée ou une checklist de revue pour eval, new Function, child_process.exec, compilation de templates et import() dynamique depuis des variables attrape beaucoup de cas.
Si vous avez hérité d’un prototype généré par des outils comme Lovable, Bolt, v0, Cursor ou Replit et que vous voulez une seconde paire d’yeux rapide, FixMyMess (fixmymess.ai) se concentre sur le diagnostic et la réparation des patterns risqués comme ceux-ci, puis vérifie les correctifs avec une revue humaine experte pour que l’app tienne en production.
Questions Fréquentes
What exactly counts as RCE in a Node app?
RCE (remote code execution) signifie que quelqu’un peut faire exécuter par votre serveur du code ou des commandes que vous n’aviez pas prévues. C’est généralement plus grave qu’une fuite de données car cela peut donner le contrôle total de l’application, de la machine et de tous les secrets accessibles par l’application.
What’s the fastest way to do an RCE risk scan without fancy tools?
Commencez par identifier où des données non fiables entrent : requêtes HTTP, webhooks, téléchargements de fichiers, outils d’administration et tâches en arrière-plan. Ensuite, recherchez les « primitives d’exécution » comme eval, new Function, child_process, la compilation de templates et les import()/require() dynamiques, puis vérifiez si des données contrôlées par un utilisateur peuvent les atteindre.
Will a keyword scan tell me if I’m definitely vulnerable?
Non. Une recherche par mots-clés trouve des formes de code suspectes, pas des exploits confirmés. Il faut tracer le flux de données et confirmer la « reachabilité » en production, car certaines correspondances peuvent être du code mort ou ne fonctionner qu’avec des entrées de confiance.
Why are internal admin endpoints such a common RCE problem?
Même les endpoints « internes » peuvent devenir accessibles si des tokens sont volés, des cookies fuitent ou une mauvaise configuration expose la route. Traitez les outils internes comme des surfaces d’attaque réelles : authentification stricte, validation d’entrée stricte et pas d’exécution libre.
Is `eval()` always a security bug, or can it be safe?
C’est dangereux dès lors que la chaîne évaluée peut être influencée par des utilisateurs, même indirectement via la base de données, la config, un CMS ou des feature flags. La plupart du temps, la correction sûre consiste à supprimer l’évaluation de chaînes et à remplacer par un petit ensemble d’opérations autorisées implémentées par des fonctions réelles.
What’s the real risk with `child_process.exec()` and command strings?
exec et execSync sont à haut risque car ils exécutent une chaîne de commande via un shell, ce qui facilite l’injection d’opérateurs. Préférez l’exécution hors shell avec un tableau d’arguments (comme spawn ou execFile) et validez quand même les entrées comme les noms de fichiers ou les identifiants pour éviter qu’un attaquant cible des fichiers inattendus.
How do I know if my template engine usage can become RCE?
L’injection de template serveur survient lorsque vous compilez ou rendez un template construit à partir d’une entrée utilisateur et que le moteur de template supporte des expressions ou des helpers. Par défaut, stockez le texte utilisateur comme contenu et rendez-le en texte brut (ou en un sous-ensemble de balisage sûr) plutôt que comme template serveur.
Why are dynamic `import()` or `require()` patterns considered RCE risks?
C’est risqué quand une partie du nom ou du chemin du module provient de données contrôlées par l’utilisateur, même si cela « devrait » charger seulement des fichiers locaux. La bonne pratique est de mapper des noms autorisés à des modules exacts dans le code et de rejeter tout ce qui n’est pas dans cette allowlist, plutôt que de passer l’entrée brute à require() ou import().
Can I just “sanitize” input to make RCE issues go away?
Pas de manière fiable. Bloquer des caractères comme ; ou && se contourne facilement via l’encodage, les espaces ou les variations d’analyse du shell, et cela n’empêche pas l’injection de template ou l’exécution dynamique de code. L’approche sûre est de supprimer la primitive d’exécution ou de la limiter à des actions fixes et allowlistées.
What should I fix first if a scan finds multiple risky spots?
Priorisez tout ce qui est accessible depuis Internet (y compris les webhooks) et qui peut exécuter du code, lancer des commandes OS, compiler des templates ou charger des modules dynamiquement. Si vous avez hérité d’un code généré par IA et besoin d’un examen rapide, des équipes comme FixMyMess (fixmymess.ai) se concentrent sur le diagnostic de ces patterns, leur réparation et la vérification humaine des correctifs.