SSRF dans les applis générées par l'IA : repérer les endpoints et durcir les fetchs
Le SSRF dans les applis générées par l'IA peut exposer des services internes. Apprenez à détecter les endpoints risqués et à appliquer des listes blanches, vérifications DNS/IP et durcissement des requêtes.
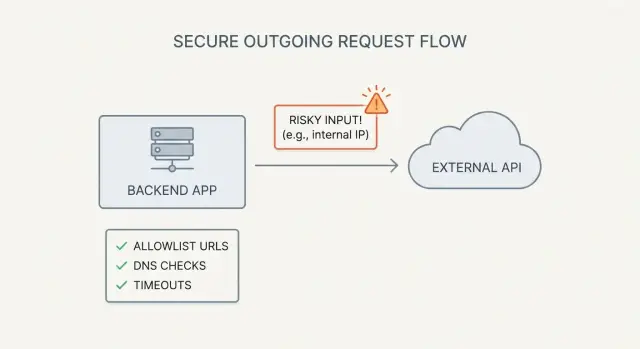
Qu'est‑ce que le SSRF (et pourquoi les applis générées par l'IA le déclenchent)
SSRF (server-side request forgery) se produit lorsque votre application peut être trompée pour effectuer une requête réseau pour le compte d’un attaquant.
L’attaquant n’a pas besoin d’accéder à vos serveurs. Il suffit d’une fonctionnalité qui accepte une URL (ou un nom d’hôte) et qui la récupère ensuite depuis le backend.
Un exemple simple : vous ajoutez un bouton « Importer depuis une URL ». Le navigateur envoie url=https://example.com/data.json à votre API, et votre serveur télécharge le fichier. Si ce même endpoint accepte aussi http://localhost:3000/admin ou http://169.254.169.254/ (métadonnées cloud), votre serveur peut finir par exposer des données internes.
On retrouve souvent ce cas dans des prototypes générés par l’IA. Ils incluent fréquemment des endpoints « récupérer n’importe quoi » (proxies d’images, aperçus de liens, testeurs de webhooks, générateurs de PDF/screenshot) parce que ça rend les démos complètes. Mais ils sont livrés sans les garde‑fous qui rendent les fetchs côté serveur sûrs.
Le SSRF est dangereux parce que les serveurs ont généralement des accès que les utilisateurs n’ont pas. Un SSRF réussi peut :
- Atteindre des panels d’administration et des services internes sur
localhostou des IP privées - Lire les endpoints de métadonnées cloud et voler des identifiants
- Scanner votre réseau interne et trouver des ports et services ouverts
- Contourner des règles basées sur l’IP (parce que la requête provient de votre serveur)
Le SSRF n’est pas la même chose que le navigateur d’un utilisateur effectuant des requêtes. Si le navigateur charge directement une URL, c’est côté client. Le SSRF concerne spécifiquement votre backend (ou une fonction serverless) qui fait le fetch, avec votre accès réseau et vos secrets.
Où le SSRF se cache généralement : endpoints à rechercher
Le SSRF se cache partout où le serveur va récupérer une URL que l’utilisateur peut influencer. Ces endpoints semblent inoffensifs parce qu’ils « récupèrent juste du contenu », mais ils peuvent servir à atteindre des services internes, des métadonnées cloud ou d’autres cibles privées.
Commencez par lister les fonctionnalités produit qui acceptent une URL, directement ou indirectement. Les endroits courants incluent les aperçus de lien, les outils d’import depuis une URL (CSV/JSON/modèles), les testeurs de webhooks, les téléchargements via proxy de fichiers et images, et les lecteurs RSS/flux.
Vérifiez aussi les outils réservés à l’administration. Les applis générées par l’IA incluent souvent des pages « tester la connexion » rapides, des checks de santé qui ping les dépendances, ou des écrans de configuration d’intégration qui vérifient une URL. Ceux‑ci sont à haut risque parce qu’ils peuvent s’exécuter avec un accès réseau élevé et contourner la validation normale.
N’oubliez pas les fetchs différés. Les jobs en arrière‑plan, queues et tâches cron peuvent stocker une URL maintenant et la récupérer plus tard. Ce décalage rend le bug plus difficile à repérer.
Quand vous parcourez le code (et les logs de requêtes), surveillez les noms de paramètres qui transportent souvent des URL, même s’ils semblent innocents : url, callback, avatarUrl, webhookUrl, redirect.
Un exemple concret : un réglage « photo de profil depuis une URL » peut récupérer l’image côté serveur pour la redimensionner. Si l’endpoint accepte avatarUrl sans contrôles stricts, un attaquant peut le pointer vers une adresse interne et utiliser la récupération d’image comme un tunnel.
Un modèle de menace rapide pour l’abus de fetch côté serveur
Avant de corriger quoi que ce soit, clarifiez ce que l’attaquant cherche à atteindre.
D’abord, cartographiez ce que votre serveur peut atteindre depuis son réseau. Cela inclut généralement les services localhost (panels admin, ports de debug), les plages IP privées dans votre VPC, et les endpoints de métadonnées du fournisseur cloud qui peuvent fournir des identifiants. Si l’application tourne en container, incluez les noms de services internes et les sidecars.
Ensuite, décidez ce que vous devez protéger. Les plus gros enjeux sont les secrets et tokens (clés API, secrets de session), les identifiants de base de données, les dashboards internes et tout service qui fait confiance aux requêtes provenant de l’intérieur de votre réseau.
Enfin, rédigez les limites pour chaque fonctionnalité de fetch côté serveur :
- Qui peut le déclencher (public, utilisateur, admin)
- Ce qu’il est autorisé à récupérer (domaines exacts ou petite liste de partenaires)
- Ce qui ne doit jamais être atteignable (localhost, IP privées, métadonnées)
- Ce que la réponse va être utilisée pour (fichier stocké, données parsées, HTML rendu)
Si vous avez hérité d’un prototype venant d’outils comme Bolt ou Replit, ce modèle de menace rapide est un bon premier passage avant un audit plus profond.
Étape par étape : trouvez chaque fetch côté serveur dans votre codebase
Le SSRF commence souvent par une fonctionnalité simple : « récupère cette URL », « importe depuis un lien », « prévisualise un webhook » ou « vérifie si ce site est up ». Avant d’ajouter des défenses, il vous faut un inventaire complet de tous les endroits où votre serveur effectue des requêtes sortantes.
1) Chassez les requêtes sortantes (y compris les wrappers)
Commencez par une recherche en texte dans le repo. Cherchez les clients HTTP courants et les helpers, pas seulement fetch.
- JavaScript/Node :
fetch,axios,got,superagent,node-fetch - Python :
requests,httpx,urllib,aiohttp - Ruby :
Net::HTTP,Faraday - Wrappers shell :
curl,wget,exec(,spawn(
Cherchez aussi des mots qui entourent souvent ces fonctionnalités : « webhook », « callback », « import », « download », « proxy », « scrape ».
Si l’app a été générée par des outils comme Lovable, Bolt, v0, Cursor ou Replit, inspectez les modules helper qui cachent des appels réseau sous des noms comme getUrlContent() ou scrapePage().
2) Remontez l’origine de l’URL
Pour chaque site d’appel, suivez la variable en arrière jusqu’à la source. Les sources communes incluent les champs du corps de la requête, les paramètres de requête, les en‑têtes, les lignes en base de données, les variables d’environnement et les chaînes de templates qui combinent une entrée utilisateur avec une URL de base.
Faites attention au contrôle indirect, comme un sous‑domaine contrôlé par l’utilisateur, un baseUrl par client, ou un ID qui référence une URL en base.
3) Vérifiez les chemins de fetch cachés
Confirmez si le client suit les redirections, résout les liens courts ou réessaie avec des URLs alternatives. Une requête qui semble sûre peut devenir dangereuse après un 302 vers un hôte interne.
4) Confirmez le comportement et documentez‑le
Provoquez des échecs volontairement (domaine invalide, timeout, réponse volumineuse) et observez : que loggue‑t‑on, quel texte d’erreur est renvoyé, et si des données de réponse sont renvoyées à l’utilisateur.
Documentez chaque endpoint avec ses entrées, sorties, exigences d’auth et domaines destinés. Cet inventaire devient votre plan de correction SSRF.
Listes blanches efficaces : valider l’hôte, le schéma et le port
Les listes noires échouent parce que les règles d’URL sont subtiles et les attaquants persistants. Une liste blanche stricte des destinations connues est la valeur la plus sûre par défaut, surtout lorsqu’une fonctionnalité permet aux utilisateurs d’importer du contenu depuis une URL.
Parsez et normalisez l’URL avant de la comparer. Ne vérifiez pas la chaîne brute. Décomposez‑la en schéma, nom d’hôte, port et chemin. Comparez le nom d’hôte normalisé et le port effectif (en tenant compte des ports par défaut comme 443 pour https).
Un flux de liste blanche pratique :
- Parsez l’URL avec un vrai parseur (pas une regex)
- Exigez le schéma
https(ouhttpseulement si c’est vraiment nécessaire) - Exigez un nom d’hôte (évitez les IP nues sauf si vous les autorisez explicitement)
- Autorisez seulement des ports approuvés (généralement 443, parfois 80)
- Faites correspondre le nom d’hôte avec vos règles de liste blanche
Les schémas et les ports sont des échappatoires courantes. Si vous ne validez que le domaine sans le schéma, un attaquant peut essayer des handlers inattendus dans certains environnements. Si vous autorisez n’importe quel port, l’attaquant peut sonder des services internes sur des ports inhabituels même si l’hôte paraît acceptable.
Les sous‑domaines nécessitent aussi des règles claires. La correspondance exacte est la plus simple (seulement api.example.com). Si vous devez utiliser des jokers, imposez une vraie frontière pour que example.com.evil.com ne passe pas.
Considérez la liste blanche comme de la configuration centralisée, pas du code dispersé. Conservez‑la en un seul endroit et logguez la règle qui a matché pour faciliter les revues et éviter que des exceptions ne s’installent discrètement.
Protections DNS : stoppez le rebinding et les astuces d’IP interne
Le rebinding DNS est une astuce simple avec un résultat fâcheux. Votre appli valide une URL comme https://example.com/image.png. Ça semble inoffensif. Mais l’attaquant contrôle example.com et peut changer la résolution après vos vérifications. Au moment où votre serveur se connecte, ce nom d’hôte peut pointer vers 127.0.0.1 ou une IP de métadonnées cloud.
C’est pourquoi les simples vérifications de nom d’hôte ne suffisent pas.
Un schéma plus sûr consiste à résoudre le nom d’hôte vous‑même, vérifier chaque IP obtenue, puis ne se connecter que si toutes sont sûres.
Ce qu’il faut bloquer (IPv4 et IPv6)
Quand vous résolvez le nom d’hôte, rejetez toute adresse dans des plages privées ou spéciales, y compris les réseaux privés (RFC1918) et les ULA IPv6, le loopback (127.0.0.1, ::1), le link‑local (169.254.0.0/16, fe80::/10), les plages réservées/non spécifiées (comme 0.0.0.0, ::) et les formes IPv4 mappées en IPv6.
Vérifiez tous les enregistrements retournés, pas seulement le premier. Les attaquants s’appuient souvent sur plusieurs enregistrements A/AAAA où l’un semble public (passe la validation) et un autre est interne.
Re‑vérifiez proche de la connexion
Si votre client HTTP le permet, résolvez et validez juste avant d’ouvrir la socket, et évitez les résolutions DNS ultérieures pendant les redirections. Si vous ne pouvez pas contrôler cela, réduisez au minimum le temps entre validation et fetch.
Durcissement des requêtes : timeouts, redirections et valeurs sûres
Même avec une bonne liste blanche, les clients HTTP côté serveur restent souvent trop permissifs par défaut. L’objectif est simple : échouer vite, récupérer moins et ne jamais suivre des redirections vers des lieux non prévus.
Commencez par définir des limites strictes sur chaque fetch côté serveur. Si une requête est lente, volumineuse ou ambiguë, considérez‑la comme suspecte et arrêtez‑vous.
Valeurs sûres par défaut pour les fetchs côté serveur
Un baseline qui fonctionne bien en pratique :
- Définissez des timeouts serrés (séparez connect et read) et limitez la taille de réponse.
- Désactivez les redirections pour les URLs fournies par l’utilisateur, ou n’autorisez qu’une redirection si la destination finale est re‑validée.
- Restreignez les méthodes à GET (et éventuellement HEAD).
- Supprimez les en‑têtes sensibles. N’ajoutez pas de cookies, clés API ou tokens d’auth internes aux requêtes sortantes.
- Logguez un résumé court (hôte, chemin, statut, temps). Évitez de logger des URL complètes si elles peuvent contenir des secrets.
Un schéma d’échec fréquent : une fonction « prévisualiser cette URL » permet les redirections. Un attaquant soumet une URL qui 302‑redirige vers un panel admin interne ou une adresse de métadonnées cloud. Votre appli suit la redirection et transmet accidentellement un en‑tête Authorization réutilisé pour des appels internes.
Erreurs : protéger les utilisateurs, informer les ingénieurs
Quand un fetch est bloqué ou échoue, affichez un message générique à l’utilisateur (par exemple « Impossible de récupérer cette URL »). Mettez la raison détaillée (timeout vs redirection vs hôte bloqué) uniquement dans les logs internes. Les messages d’erreur trop explicites côté UI enseignent aux attaquants vos règles.
Erreurs courantes qui laissent encore le SSRF ouvert
Des bugs SSRF survivent souvent à des « corrections basiques ». Le résultat semble protégé, mais un attaquant peut toujours faire parler votre serveur avec des services internes ou des endpoints de métadonnées.
Beaucoup d’équipes commencent par des vérifications de chaîne comme startsWith('https://'). Ça casse avec des URLs tordues, des encodages inhabituels, ou des URLs qui semblent sûres mais résolvent vers quelque chose de dangereux.
Autres oublis fréquents :
- Autoriser les redirections sans re‑vérifier chaque étape
- Valider l’hôte, puis se connecter en utilisant une valeur différente plus tard
- Bloquer seulement
127.0.0.1en oubliant le loopback IPv6 (::1),0.0.0.0, et les plages privées comme10.*,172.16.*,192.168.* - Omettre les protections contre le rebinding DNS (validation faite une fois puis utilisée plus tard)
Si vous renvoyez le contenu récupéré directement au navigateur, vous pouvez créer un second problème : votre serveur devient un proxy. Sans limites strictes, les attaquants peuvent télécharger des fichiers énormes pour générer des coûts, ou envoyer des types de contenu inattendus que votre front maltraite.
Checklist pré‑lancement pour les défenses SSRF
Avant le lancement, supposez que quelqu’un essaiera de transformer n’importe quel fetch côté serveur en tunnel.
Inventoriez chaque endroit où un utilisateur (ou un autre système) peut influencer une URL, un hôte ou une référence de fichier distant. Incluez les champs évidents comme « importer depuis une URL », ainsi que les testeurs de webhook, prévisualiseurs d’images, générateurs de PDF, lecteurs de flux, fonctions « vérifier mon site » et intégrations qui acceptent des callback URLs.
En staging, validez quelques essentiels :
- Chaque endpoint et job en arrière‑plan qui accepte une URL/nom d’hôte est listé.
- La liste blanche est appliquée côté serveur pour chaque fetch (pas seulement côté UI).
- Schéma, hôte et port sont validés avant la requête.
- Les vérifs DNS/IP bloquent les plages internes pour IPv4 et IPv6, et la vérification a lieu proche de la connexion.
- Timeouts, limites de taille de réponse et règles de redirection sont en place.
Pour des tests simples de « cible connue mauvaise », essayez localhost, une IP privée, un nom d’hôte interne utilisé dans votre environnement et l’adresse de métadonnées cloud commune. Vous ne cherchez pas à exploiter quoi que ce soit, juste à confirmer que votre appli refuse la requête sans divulguer d’erreurs utiles.
Exemple : corriger en toute sécurité une fonctionnalité « importer depuis une URL »
Un schéma courant est une fonctionnalité pratique comme « Importer l’avatar depuis une URL. » Un générateur ajoute un endpoint backend qui prend une URL, télécharge l’image côté serveur et la stocke.
Le chemin d’exploitation est prévisible. Un attaquant soumet une URL qui n’est pas du tout un hébergeur d’images, mais une adresse interne comme un service de métadonnées, un panel admin privé, ou un port HTTP de base de données exposé uniquement dans votre réseau. Si votre serveur la récupère, l’attaquant peut apprendre des secrets, des noms d’hôtes internes, ou obtenir du HTML si vous stockez ou prévisualisez la réponse.
Rendez le fetch banal et strict :
- Liste blanche seulement des hébergeurs d’images spécifiques que vous contrôlez ou en qui vous avez confiance.
- Exigez
httpset bloquez les ports non standards. - Résolvez le DNS vous‑même et bloquez les IPs privées, loopback et link‑local avant de vous connecter.
- Désactivez les redirections, ou autorisez une seule redirection qui reste validée.
- Définissez des timeouts serrés et une petite taille max de téléchargement, et vérifiez le type de contenu et les magic bytes.
Ajoutez de la surveillance pour détecter le probing. Il se manifeste souvent par de nombreuses requêtes échouées sur différents hôtes, des tentatives répétées vers 169.254.169.254 ou localhost, ou des pics de résultats DNS bloqués et de redirections filtrées.
Prochaines étapes : simplifiez les fonctionnalités de fetch et faites une revue ciblée
Si vous trouvez ne serait‑ce qu’un fetch côté serveur pouvant atteindre une URL fournie par l’utilisateur, supposez qu’il y en a d’autres. La réduction rapide du risque consiste à diminuer la surface d’exposition.
Décidez quelles fonctionnalités de fetch sont réellement nécessaires. Beaucoup d’applis livrent des extras comme « importer depuis une URL », « prévisualiser ce lien », « récupérer les données Open Graph », « testeur de webhook », « proxy d’images » ou « se connecter à n’importe quelle API ». Chacune est un point d’entrée SSRF potentiel. Si une fonctionnalité n’est pas essentielle, la supprimer est souvent plus sûr que la durcir indéfiniment.
Ensuite, définissez quelques règles qui doivent être vraies pour chaque fetch côté serveur :
- Seuls schémas, ports et hôtes approuvés sont autorisés (pas « n’importe quelle URL »).
- Les vérifs DNS et IP se font au moment de la requête, pas seulement une fois lors de la validation.
- Timeouts, limites de redirection et de taille de réponse sont toujours activés.
- Les fetchs sont centralisés dans un helper pour éviter que de nouveaux endpoints contournent les protections.
Si vous voulez un contrôle externe rapide pour une base de code générée par l’IA, FixMyMess (fixmymess.ai) réalise un diagnostic de code et un renforcement de sécurité pour les prototypes construits avec des outils comme Lovable, Bolt, v0, Cursor et Replit. Ils proposent aussi un audit de code gratuit pour identifier rapidement les risques de fetch SSRF et d’autres problèmes à fort impact avant la mise en production.
Questions Fréquentes
What is SSRF in plain English?
SSRF, c’est quand votre backend (ou une fonction serverless) peut être manipulé pour récupérer une URL contrôlée par un attaquant. Comme la requête provient de votre serveur, elle peut atteindre des services internes, des IP privées ou des métadonnées cloud qu’un utilisateur normal ne peut pas voir.
Why do AI-built apps get SSRF bugs so often?
Les prototypes générés par l’IA ajoutent souvent des fonctionnalités « pratiques » qui font des requêtes côté serveur, comme les aperçus de lien, les proxies d’images, l’import depuis une URL, les testeurs de webhooks ou les générateurs de captures/PDF. Elles fonctionnent pour des démos, mais sont rarement livrées avec des listes blanches strictes, des vérifications DNS/IP et des contrôles sur les redirections.
What endpoints should I check first for SSRF?
Cherchez tout endpoint ou job qui accepte des champs comme url, webhookUrl, callback, avatarUrl, redirect ou une adresse d’« intégration » de test. Vérifiez aussi les workers en arrière-plan et les tâches cron qui stockent une URL maintenant et la récupèrent plus tard : SSRF peut se cacher hors des chemins de requête normaux.
How do I find every server-side fetch in my codebase?
Commencez par inventorier toutes les requêtes sortantes du serveur en cherchant les clients HTTP (comme fetch/axios/requests) et tout helper interne qui les encapsule. Pour chaque appel, remontez la trace de la variable jusqu’à sa source et vérifiez si une entrée utilisateur peut influencer une partie, même indirectement via la base de données ou une config par client.
Should I use an allowlist or a blocklist to prevent SSRF?
Privilégiez une liste blanche des domaines exacts attendus et rejetez tout le reste. Analysez et normalisez l’URL avec un vrai parseur, exigez https et n’autorisez que des ports sûrs (généralement 443, parfois 80), pour éviter que des ports inattendus servent à sonder des services internes.
How do I protect against DNS rebinding and “it resolves to localhost” tricks?
Comme le DNS peut changer après que vous avez validé le nom d’hôte, résolvez vous‑même le nom d’hôte, inspectez chaque IP retournée et rejetez les plages privées, loopback, link-local et autres plages spéciales, pour IPv4 et IPv6. Faites ce contrôle le plus près possible de la connexion réelle, pas seulement au moment de la validation initiale.
What are the safest defaults for server-side HTTP requests?
Resserrez les timeouts, limitez la taille de réponse maximale et considérez les redirections comme dangereuses pour les URL fournies par les utilisateurs. Le défaut le plus sûr est d’interdire les redirections ; si vous devez les autoriser, réévaluez la destination après chaque saut et n’envoyez jamais de cookies ou d’en‑têtes d’auth internes au serveur distant.
What are the most common SSRF “fixes” that still leave me vulnerable?
Des vérifications basées sur des chaînes comme startsWith('https://') ou simplement « bloquer localhost » ratent des contournements courants (IPv6 loopback, plages privées, redirections, changements DNS entre validation et connexion). Un autre écueil fréquent : valider un hôte puis se connecter en utilisant une valeur différente dérivée plus tard.
How can I quickly test whether my SSRF defenses actually work?
Testez des cibles connues comme localhost, des plages d’IP privées et l’adresse de métadonnées cloud courante, et vérifiez que l’application les bloque sans divulguer de détails techniques côté utilisateur. Testez aussi le comportement des redirections pour vous assurer que la destination finale est validée.
Can FixMyMess help harden an AI-generated codebase against SSRF?
Si votre appli a été générée par des outils comme Lovable, Bolt, v0, Cursor ou Replit, il est courant qu’un fetch caché ou une tâche en arrière-plan manque à l’appel. FixMyMess peut exécuter un audit de code gratuit pour inventorier les fetchs côté serveur, puis durcir le code (listes blanches, vérifications DNS/IP, règles de redirection, timeouts) et vous amener rapidement à un état prêt pour la production.