Stratégie de réessai pour les tâches en arrière‑plan : backoff, limites et alertes
Stratégie de réessai pour tâches en arrière‑plan : ajoutez backoff, limite de tentatives, dead‑letter queue et alertes pour rendre les échecs visibles et récupérables.
Pourquoi « ça n'a pas tourné » est une mauvaise façon de détecter les échecs
Les tâches en arrière-plan sont les petits travaux que votre application exécute en coulisse pour que le produit principal reste réactif. Elles envoient des e-mails, importent des CSV, synchronisent des données, traitent des paiements et délivrent des webhooks. Les utilisateurs voient rarement la tâche elle‑même. Ils remarquent seulement le résultat.
C'est pourquoi l'échec le plus courant ressemble à ceci : ça fonctionnait en test, puis ça a silencieusement cessé en production. Personne ne voit une page d'erreur. Rien n'explose de façon évidente. Vous l'apprenez des jours plus tard quand un client dit « je n'ai jamais reçu l'e‑mail » ou qu'un export manque.
Les échecs silencieux sont pires que les échecs visibles parce qu'ils minent la confiance tout en cachant la cause. Les échecs visibles forcent une réponse. Les silencieux créent un arriéré de promesses non tenues : e‑mails non envoyés, données non synchronisées, onboarding bloqué, remboursements non traités. Quand vous vous en apercevez, vous réparez la tâche et nettoyez le désordre qu'elle a laissé.
Un bon plan de réessai n'est pas « réessayer pour toujours ». Il doit faire quatre choses :
- Se remettre des problèmes temporaires (timeouts, pannes brèves, limites de débit).
- S'atténuer sous pression pour ne pas bombarder votre base de données ou une API externe.
- S'arrêter après un nombre raisonnable de tentatives.
- Rendre les échecs évidents pour qu'un humain puisse intervenir.
Si un fournisseur d'e‑mails renvoie un 503 temporaire, réessayer plus tard a du sens. Mais si la tâche échoue à cause d'une mauvaise variable de template ou d'une authentification cassée, les réessais ne feront que brûler du temps et de l'argent sans corriger quoi que ce soit.
On voit souvent ça dans des prototypes générés par IA. L'application « marche en grande partie », puis le travail en arrière‑plan échoue silencieusement parce que des secrets manquent, la gestion des erreurs est fragile ou la logique des tâches est emmêlée. La première étape est de rendre les échecs bruyants, bornés et récupérables.
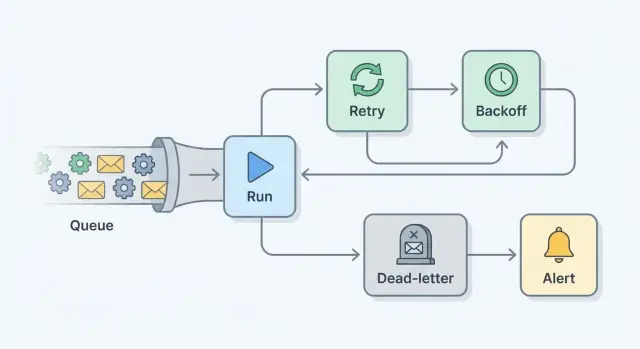
Éléments clés : réessais, backoff, nombre max de tentatives, dead‑letter, alertes
Un plan de réessai est en réalité un ensemble de petits garde‑fous qui transforme des échecs silencieux en travail visible et récupérable.
Un réessai exécute à nouveau la même tâche après un échec. Cela aide quand l'échec est temporaire, comme un appel réseau instable.
Le backoff est la pause entre les tentatives. Plutôt que de réessayer instantanément (et créer un "thundering herd"), on attend de plus en plus longtemps, souvent avec un peu d'aléatoire.
Le nombre maximal de tentatives est la limite stricte. Après N essais, on s'arrête pour qu'une tâche défectueuse ne boucle pas indéfiniment.
Une dead‑letter queue (DLQ) (ou table des jobs échoués) est l'endroit où vont les tâches après abandon. Rien n'est perdu. Vous pouvez inspecter ce qui s'est passé, corriger la cause racine, puis relancer la tâche volontairement.
L'alerte est ce qui informe les humains. L'objectif n'est pas d'alerter à chaque réessai, mais d'alerter quand quelque chose nécessite une action, par exemple quand une tâche atteint le nombre max de tentatives ou que le volume de la DLQ augmente.
Une idée qui évite beaucoup de douleur : l'idempotence
Une tâche est idempotente si elle peut s'exécuter deux fois sans effet indésirable.
"Définir le statut de facture à PAYÉ" est plus sûr que "débiter la carte". Quand on ne peut pas rendre une action complètement idempotente, ajoutez une garde : une clé unique, un drapeau "déjà traité" ou un jeton d'idempotence du fournisseur.
Échecs transitoires vs permanents
Les échecs transitoires se résorbent généralement d'eux‑mêmes : timeouts, pannes brèves, lignes verrouillées. Les échecs permanents ne changent pas sans intervention : enregistrements manquants, adresses e‑mail invalides, clé API erronée.
Les réessais réduisent les incidents, mais n'éliminent pas tous les échecs. Le but est de contenir le périmètre, de faire remonter vite les vrais problèmes et de vous donner un endroit sûr (DLQ) pour récupérer.
Savoir ce que vous réessayez : erreurs transitoires vs permanentes
Un plan de réessai commence par une décision : cette erreur a‑t‑elle des chances de disparaître d'elle‑même, ou échouera‑t‑elle à chaque tentative tant que quelqu'un ne change rien ? Si vous réessayez tout, vous obtenez des files bruyantes, des factures plus élevées et des délais qui cachent le vrai problème.
Les erreurs transitoires sont temporaires. Les réessayer (avec backoff) aide souvent parce que l'environnement autour de la tâche change : le réseau se stabilise, le service revient, le verrou se lève ou la fenêtre de rate limit se réinitialise.
Les erreurs permanentes ne se corrigent pas seules. Les réessayer ne fait que brûler du temps pendant que les utilisateurs attendent. Ce sont en général des problèmes de données, de permissions, de migrations manquantes ou de bugs.
Se tromper d'étiquette a des conséquences. Traiter une erreur permanente comme réessayable peut créer un arriéré qui bloque le travail sain. Ça rend aussi les incidents plus difficiles à détecter parce que le système a l'air "occupé" plutôt que "cassé".
Règle simple : ne réessayez que si vous pouvez nommer une condition réaliste qui changera sans intervention humaine. Si la tâche réussirait probablement si on la relançait dans 1 à 10 minutes, elle est vraisemblablement réessayable. Si elle échouerait de la même façon demain, arrêtez, envoyez en DLQ et alertez.
Backoff qui se comporte bien sous pression
Quand une tâche échoue, le pire est de réessayer en boucle immédiatement. Si l'échec vient d'une panne partielle, d'une limite de débit ou d'une base de données lente, les réessais immédiats ajoutent de la charge au moment où le système peine déjà.
Le backoff exponentiel est un comportement sain par défaut : chaque réessai attend plus longtemps que le précédent. Un schéma simple peut être 5 s, 15 s, 45 s, 2 min, puis 5 min.
Ajoutez du jitter (un peu d'aléatoire) à chaque délai. Sans cela, des workers ayant échoué ensemble réessaieraient ensemble et créeraient des pics. Avec du jitter, une attente prévue de 2 minutes devient peut‑être 1 min 30 s à 2 min 30 s. Cette petite dispersion lisse les réessais.
Le backoff doit correspondre à la tâche. Un e‑mail de réinitialisation de mot de passe et un rapport nocturne n'ont pas le même rythme. En règle générale, les tâches visibles par l'utilisateur peuvent réessayer rapidement avec un plafond court, tandis que les tâches lourdes et les APIs externes strictes nécessitent des plafonds plus longs et du jitter à chaque fois.
Fixer des limites de tentatives et des conditions d'arrêt claires
Les réessais illimités rassurent, mais ils peuvent transformer un échec en boucle sans fin. La tâche continue de tourner, accumule du temps en file et des coûts d'API, et cache un vrai bug parce qu'il n'y a jamais d'échec « final ».
Il y a aussi un risque pratique : des réessais répétés peuvent causer des dégâts. Vous pouvez envoyer le même e‑mail plusieurs fois, créer des enregistrements en double ou débiter une carte à nouveau si la tâche n'est pas idempotente.
Choisissez le nombre maximal de tentatives selon l'impact. Les actions à haut risque comme les paiements doivent échouer vite (souvent 1 à 3 tentatives). Les notifications peuvent tolérer un peu plus. Pour des APIs externes lentes, plus de tentatives peuvent aller, tant que le backoff reste conservateur.
Ajoutez aussi une limite de durée totale, pas seulement un nombre. Par exemple : "Réessayer jusqu'à 5 fois, mais s'arrêter après 2 heures." Cela empêche une tâche de traîner pendant des jours.
Quand une tâche atteint le nombre maximal de tentatives, traitez‑la comme un événement réel. Enregistrez suffisamment d'informations pour déboguer et rejouer en sécurité : dernière erreur, type d'erreur, horodatages des tentatives et le payload (ou une version masquée). Capturez les IDs externes (user_id, order_id) qui aident à tracer l'impact.
Utiliser une dead‑letter queue pour rendre les échecs récupérables
Les réessais sont pour les problèmes temporaires. Certaines tâches ne réussiront jamais sans une modification. Une DLQ est l'endroit sûr pour placer ces tâches après qu'elles aient atteint le nombre max de tentatives : elles cessent de consommer des ressources et deviennent visibles pour un humain.
Considérez la DLQ comme une boîte "à traiter". Au lieu de perdre du travail ou de boucler à l'infini, vous capturez suffisamment de détails pour diagnostiquer, corriger et relancer volontairement.
Que stocker dans un enregistrement dead‑letter
Une entrée DLQ doit répondre à deux questions : que la tâche essayait‑elle de faire, et pourquoi a‑t‑elle échoué ?
Gardez‑le petit mais complet : nom de la tâche (et version si vous en avez une), payload d'entrée (ou référence si volumineux), message et type d'erreur (plus stack trace si disponible), comptage des tentatives avec horodatages, et IDs de corrélation (user ID, order ID, request ID) pour rattacher aux logs.
Faites attention aux secrets. Si les payloads peuvent inclure des tokens ou mots de passe, masquez‑les avant de sauvegarder.
Comment réenfiler en toute sécurité
Le réenfilage doit être délibéré, pas une boucle automatique. Corrigez la cause racine, puis relancez la tâche depuis un écran d'admin ou un petit script.
Ajoutez une trace d'audit minimale : quand vous réenfilez, réinitialisez le compteur de tentatives et enregistrez qui l'a fait et pourquoi. Si l'échec vient d'une mauvaise entrée qui ne validera jamais, permettez de marquer "ne pas réessayer" avec une courte note.
La rétention compte aussi. Conservez les éléments DLQ assez longtemps pour repérer des motifs et gérer des corrections lentes, mais pas au point que des données sensibles restent indéfiniment.
Des alertes utiles, pas bruyantes
Les alertes doivent répondre rapidement à une question : "Qu'est‑ce qui a cassé, qui est affecté et que dois‑je faire ensuite ?" Si les échecs restent cachés pendant des heures, vous l'apprenez par un client.
Commencez par des déclencheurs qui représentent une vraie douleur, pas chaque tentative ratée. Signaux utiles : échecs répétés d'un même type de tâche, augmentation de messages dans la DLQ, temps en file long (tâches attendant plus longtemps que promis aux utilisateurs), chute soudaine du débit et pics d'erreurs pour une tâche spécifique.
Adressez les alertes à qui peut agir. Pour les petites équipes, c'est souvent l'ingénieur on‑call ou le fondateur. Fournissez assez de contexte pour éviter 20 minutes de recherche : nom de la tâche, environnement, première heure d'échec, dernier message d'erreur, nombre de tâches affectées et si des messages vont en DLQ.
Pour éviter le bruit, utilisez trois leviers : seuils (alerter après N échecs), regroupement (une alerte par type de tâche par fenêtre de temps) et une fenêtre de cooldown (ne pas relancer l'alerte pendant 15 minutes sauf si la situation empire).
Si vous avez besoin d'escalade, faites simple : notifier le on‑call principal, puis un backup après un court délai, puis un canal plus large avec un résumé d'impact si la situation continue de croître.
Rendre les échecs visibles avec logs et métriques basiques
Un plan de réessai ne fonctionne que si vous pouvez voir ce qui se passe. Sinon vous aurez sans cesse le même rapport : "la tâche n'a pas tourné." L'objectif est simple : chaque tentative laisse une trace claire, et quelques nombres disent si la situation empire.
Pour les logs, gardez des champs cohérents pour pouvoir tracer facilement un échec à travers les réessais. Chaque tentative doit inclure un ID de tâche (ou ID de corrélation), le numéro de tentative, l'heure de début et de fin, et le résultat. En cas d'échec, loggez une classe d'erreur (timeout, auth, validation) plus un message court. Indiquez aussi la file et le nom du worker.
Protégez les logs. N'y mettez pas de tokens, mots de passe, clés API, en‑têtes complets ou données personnelles brutes. Utilisez des IDs internes ou des valeurs masquées.
Pour les métriques, vous n'avez pas besoin de beaucoup pour obtenir de la valeur. Suivez le taux de succès par type de tâche, les réessais par tâche (moyenne et p95), le compte et le taux de la DLQ, et le temps jusqu'à réussite (combien de temps les tâches passent en réessai).
Pendant un incident, un petit tableau de bord doit répondre : la DLQ monte‑t‑elle, un type de tâche concentre‑t‑il la majorité des réessais, et les échecs ont‑ils commencé à un moment précis (signe d'un déploiement ou d'une panne externe) ?
Exemple : une tâche d'envoi d'e‑mail qui échoue puis se rétablit en sécurité
Une tâche courante est l'envoi d'un e‑mail d'onboarding après inscription. Ça marche pendant des semaines, puis le support signale : "certains utilisateurs n'ont jamais reçu l'e‑mail." Si vous ne cherchez que "ça n'a pas tourné", vous manquerez la vraie histoire : la tâche a tourné, a échoué et a disparu.
Ce qui se passe quand les échecs commencent
À 09:02, la tâche essaie d'envoyer un e‑mail, mais le fournisseur timeoute. C'est transitoire, donc le worker réessaie avec un backoff exponentiel. Il attend 30 s, puis 2 min, puis 10 min. Le backoff ménage le fournisseur et votre propre système.
À la 5ᵉ tentative, ça échoue encore. La tâche atteint le nombre max de tentatives et s'arrête. Au lieu d'être perdue, elle va en DLQ avec des détails utiles : user ID, type d'e‑mail (onboarding), dernière erreur, compteur de tentatives et moment du début des échecs.
Une alerte se déclenche une seule fois, pas 50 fois : "OnboardingEmailJob : 12 messages en DLQ dans les 15 dernières minutes. Erreur principale : timeout." La personne on‑call voit que c'est réel, que ça grandit et qu'il faut agir.
Comment réparer et réenfiler en sécurité
Vous enquêtez et trouvez la cause racine : la clé API a été tournée, mais le worker utilise encore l'ancien secret. C'est courant dans des bases de code où les secrets sont codés en dur ou chargés de façon incohérente.
Après avoir mis à jour le secret et redéployé, vous réenfilez les messages DLQ. Avant de clôturer l'incident, vous vérifiez que le nombre dans la DLQ diminue, que les nouvelles inscriptions reçoivent les e‑mails dans les délais normaux, que les alertes se calment et qu'elles restent silencieuses pendant une fenêtre complète de réessai, et que les logs montrent des envois réussis sans timeouts répétés.
L'échec devient visible, contenu et récupérable, et aucun utilisateur n'est ignoré silencieusement.
Erreurs courantes qui causent des incidents répétés
Les incidents récurrents ne sont généralement pas de la « malchance ». Ils viennent de quelques schémas qui transforment un petit échec en un arriéré.
L'un des plus gros est de réessayer une tâche qui n'est pas idempotente. Si "exécuter deux fois" signifie "débiter deux fois" ou "envoyer deux e‑mails", les réessais peuvent créer un problème client même si l'erreur initiale était mineure. Ajoutez une clé de requête unique, vérifiez l'état courant avant d'agir et enregistrez le résultat pour que la deuxième exécution soit un no‑op.
Un autre piège est d'attraper toute erreur et de réessayer pour toujours. Ça semble sûr, mais ça cache de vrais bugs (mauvaises données, logique cassée, permissions manquantes) et consume de la capacité.
Les sources les plus communes de douleur répétée sont :
- Pas de nombre maximal de tentatives ou de condition d'arrêt, donc les échecs bouclent jusqu'à ce que quelqu'un le remarque.
- Pas de DLQ (ou équivalent), donc on ne peut pas revoir et récupérer les tâches échouées.
- Alertes sans propriétaire, ou alertes tellement bruyantes qu'on les coupe.
- Secrets ou données personnelles dans les payloads et logs, transformant le débogage en problème de sécurité.
- Relances manuelles sans savoir ce qui a déjà réussi, provoquant des doublons.
Un exemple réaliste : une tâche d'envoi de reçu de paiement timeoute après que le débit a réussi, puis réessaye et envoie deux reçus. Des semaines plus tard, quelqu'un relance un lot "au cas où" et les clients se retrouvent spamés.
Checklist rapide avant mise en production
Avant d'activer un nouveau worker ou une nouvelle file en production, décidez à quoi ressemble un "échec sûr".
- Définissez ce qui est réessayable (timeouts, 503, limites de débit) vs ce qui doit échouer vite (mauvaise entrée, enregistrement manquant, erreurs de permission).
- Utilisez un backoff avec jitter, et un plafond sensé pour qu'une panne ne crée pas un énorme entassement de réessais.
- Fixez un nombre maximal de tentatives et une limite temporelle (par exemple « arrêter après 10 minutes au total »), puis marquez comme échoué.
- Activez une DLQ (ou table des jobs échoués) et vérifiez que vous pouvez réenfiler en toute sécurité sans doublons.
- Rendez les échecs observables : loggez l'ID de tâche, le numéro de tentative, le nom de la file, le message d'erreur et un contexte sûr (IDs internes, pas de secrets).
Testez ensuite toute la boucle une fois. Choisissez une tâche (comme l'envoi d'un reçu), forcez un échec transitoire (retournez un faux 502 une fois) et vérifiez qu'elle réessaye avec les délais attendus, réussit à la tentative suivante et produit exactement un e‑mail.
Étapes suivantes : améliorer une tâche, puis généraliser le modèle
Choisissez une tâche qui compte chaque jour et qui coûte cher quand elle échoue. Bons candidats : envoi de reçus, synchronisation de paiements ou génération de factures. Si vous pouvez rendre une tâche sûre en cas d'échec, la récupérer automatiquement et être alerté quand elle ne l'est pas, vous aurez un modèle réutilisable.
Commencez petit : classez les erreurs et ne réessayez que les transitoires. Ajoutez backoff, limite de tentatives et une voie DLQ pour tout ce qui échoue encore. Ajoutez une alerte actionnable quand une tâche atteint le max de tentatives ou atterrit en DLQ. Conservez une ligne de log claire par tentative avec ID de tâche, numéro de tentative et dernière erreur.
Si vous avez hérité d'une base de code générée par IA où les workers "échouent parfois", évitez d'abord de faire de gros refactors. Encapsulez les tâches avec des garde‑fous (suivi des tentatives, backoff, conditions d'arrêt), puis nettoyez la logique une fois que les échecs sont visibles.
Si vous n'êtes pas à l'aise de modifier le code en sécurité, FixMyMess (fixmymess.ai) peut réaliser un audit de code gratuit pour repérer les problèmes de logique de tâches, réessais, gestion des secrets et readiness production, puis livrer des correctifs vérifiés prêts à déployer, souvent en 48 à 72 heures.
Questions Fréquentes
Qu'est-ce qu'un « échec silencieux » dans une tâche en arrière-plan ?
Les échecs silencieux surviennent lorsqu'une tâche s'exécute en arrière-plan, échoue et personne ne le remarque. Les utilisateurs ne voient que le résultat manquant plus tard, par exemple aucun reçu par e-mail ou un export qui n'arrive jamais.
Quel plan de réessai par défaut est adapté pour la plupart des tâches en arrière-plan ?
Ne réessayez pas indéfiniment par défaut. Réessayez seulement les erreurs susceptibles de se résoudre rapidement, ajoutez un backoff pour ne pas surcharger les systèmes, arrêtez après une limite fixe et rendez l'échec final visible pour qu'un humain intervienne.
Comment distinguer les erreurs transitoires des erreurs permanentes ?
Les erreurs transitoires se résolvent sans changer le code ni les données : timeouts, pannes brèves, limites de débit, verrous temporaires. Les erreurs permanentes viennent de mauvaises données, enregistrements manquants, identifiants invalides ou bugs : les réessais ne font que retarder la correction.
Pourquoi utiliser le backoff exponentiel et le jitter au lieu de réessayer immédiatement ?
Le backoff exponentiel espace de plus en plus les réessais, ce qui réduit la charge quand un service est déjà sollicité. Ajoutez du jitter (un peu d'aléatoire) pour éviter que plusieurs workers ne réessaient exactement au même instant et recréent des pics.
Pourquoi les réessais illimités sont-ils une mauvaise idée ?
Les réessais illimités masquent les vrais bugs et peuvent augmenter le temps en file, le coût des API et les effets secondaires en double. Une limite de tentatives force un moment clair « ceci nécessite une intervention » et empêche qu'une tâche cassée n'étouffe le reste du travail.
Combien de réessais devrais-je autoriser et combien de temps devrais-je continuer à réessayer ?
Commencez par évaluer l'impact et le risque : les actions à risque élevé comme les paiements doivent échouer vite (souvent 1 à 3 tentatives). Les notifications peu risquées peuvent tolérer plus de tentatives, mais fixez toujours un plafond temporel pour ne pas réessayer pendant des jours.
Qu'est-ce qu'une dead-letter queue et pourquoi en ai-je besoin ?
Une dead-letter queue (ou table des jobs échoués) est l'endroit où une tâche va après avoir atteint le nombre maximal de tentatives. Elle évite la perte de travail, capture le contexte pour le débogage et permet de relancer la tâche volontairement après correction.
Comment réenfiler des tâches échouées sans provoquer de doublons ?
Relancez uniquement après avoir corrigé la cause. Assurez-vous que la tâche ne produira pas de doublons si elle s'exécute deux fois. Enregistrez qui a relancé et pourquoi, et évitez de relancer des tâches avec des entrées qui ne valideront jamais.
Que veut dire « tâche idempotente » et quand est-ce important ?
Idempotent signifie que lancer la tâche deux fois n'entraîne pas un second paiement, un deuxième e‑mail ou des enregistrements en double. Préférez les opérations « définir l'état » quand c'est possible, et sinon ajoutez une clé unique ou un jeton d'idempotence fourni par le prestataire.
Sur quoi dois‑je alerter et que dois‑je logger pour les tâches en arrière-plan ?
Alertez quand une tâche devient exploitable, par exemple lorsqu'elle atteint le nombre maximal de tentatives ou atterrit dans la DLQ — pas à chaque réessai. Loggez chaque tentative avec un ID de tâche et un type d'erreur, et suivez des métriques simples comme la croissance de la DLQ et le taux de réessais pour détecter les problèmes avant les clients.