Les tâches en arrière-plan ne s’exécutent pas ? Réparez files, cron et workers rapidement
Les tâches en arrière‑plan qui ne s’exécutent pas peuvent interrompre les e‑mails, la facturation et les synchronisations. Apprenez à identifier si le problème vient du cron, des files, des workers, des retries ou de l’idempotence, et comment le résoudre.
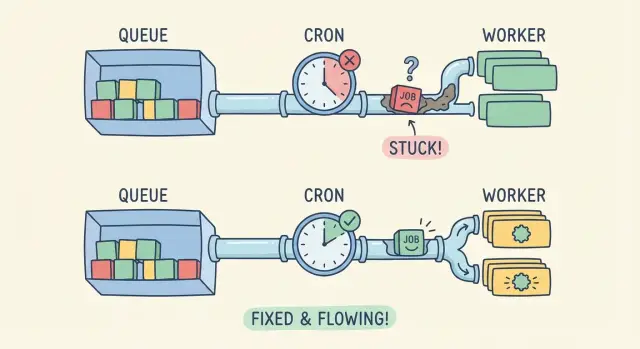
À quoi ressemble la panne des tâches en arrière-plan
Quand les tâches en arrière-plan ne s’exécutent plus, l’application peut sembler correcte au premier abord. Les pages se chargent, les utilisateurs naviguent et les formulaires sont envoyés. Mais le travail « après coup » n’a jamais lieu.
On remarque des effets secondaires manquants : le mail de bienvenue n’arrive pas, une importation CSV reste sur « en cours de traitement », un webhook de paiement est reçu mais la commande n’est jamais mise à jour, ou une synchronisation nocturne cesse de modifier les chiffres. Les tickets support sont vagues (« c’est bloqué ») parce que rien ne plante visiblement.
C’est particulièrement courant dans les prototypes générés par IA. Ils marchent souvent en local parce qu’une seule machine fait tout : servir l’app web, déclencher les horaires et exécuter les workers. En production, ces pièces sont séparées entre services, conteneurs ou machines. Un élément manquant casse la chaîne.
La plupart des pannes se rangent en quatre catégories :
- Planification : cron/minuteries qui ne se déclenchent jamais, dérive des fuseaux horaires, ou exécution dans le mauvais environnement.
- Déploiement du worker : le worker ne tourne pas, ne peut pas atteindre la file, ou écoute une autre file.
- Reprises : les jobs échouent et se réessaient indéfiniment, ou échouent une fois puis disparaissent sans alerte.
- Idempotence : une tâche s’exécute deux fois et corrompt l’état, donc elle est désactivée ou génère constamment des erreurs.
Avant de toucher au code, recueillez quelques éléments. Ça évite des heures de devinettes et montre plus clairement où la chaîne casse :
- L’horodatage de l’action utilisateur (ou du moment où la planification aurait dû se déclencher)
- Le nom/type de la tâche et tout ID de job noté par votre système
- Les logs du worker autour de ce moment (pas seulement les logs web)
- Les métriques de la file : en attente, en cours, échoués
- La dernière exécution réussie de la même tâche
Si vous avez hérité d’un prototype créé avec Replit, Cursor ou Bolt, ce « pack de preuves » est aussi ce que des équipes comme FixMyMess utilisent pour repérer s’il manque un scheduler, si un worker est mort, ou si une tâche échoue silencieusement.
Cron, files d’attente et workers : le modèle mental simple
Pensez au travail en arrière-plan comme à un service de livraison. Quelque chose décide quand le travail doit se faire, quelque chose stocke le travail, et quelque chose l’exécute.
Cron (ou un scheduler) est l’horloge. Il déclenche une tâche selon un planning comme « toutes les 5 minutes » ou « chaque lundi à 9h ». Une file d’attente est la boîte aux lettres. Elle garde les jobs jusqu’à ce qu’un worker soit prêt. Un worker est le facteur. Il récupère les jobs de la file et exécute le code.
Les jobs ponctuels et récurrents démarrent différemment. Un job ponctuel est généralement créé par votre app (par exemple « redimensionner cette image après l’upload »). Un job récurrent est généralement créé par cron (par exemple « envoyer les rapports hebdomadaires »). Si vous utilisez une file, les deux finissent au même endroit : un enregistrement de job en attente de traitement.
En production, l’état doit vivre quelque part de partagé et durable : une table en base pour les runs planifiés, Redis pour les messages de queue, ou un service de queue managé. Si un prototype dépend d’un état en mémoire, il peut fonctionner en local et échouer dès que vous avez plus d’un serveur ou après un redémarrage.
Le dev local masque les problèmes car tout tourne dans un seul processus. En production, c’est séparé. Si cron n’est pas installé, si le worker n’est pas déployé, ou si le worker ne peut pas atteindre Redis ou la base, vous avez le symptôme classique : les tâches en arrière-plan ne tournent pas alors que l’app semble « saine » en surface.
Triage rapide : où la chaîne casse-t-elle ?
Ne devinez pas. Déterminez quelle partie du pipeline échoue : les tâches ne sont-elles pas créées, pas récupérées, ou s’exécutent-elles puis échouent ?
1) Les tâches sont-elles créées ?
Commencez par la division la plus simple : « aucune tâche n’existe » vs « la tâche existe mais rien ne se passe ». Cherchez un enregistrement de job dans votre store/table de queue, ou un log confirmant qu’un job a été mis en file.
Si vous ne trouvez rien, c’est généralement la planification. Les cron/minuteries peuvent ne pas tourner en production, tourner dans le mauvais environnement ou ne pas avoir les permissions nécessaires. Une erreur fréquente sur les prototypes est de compter sur un scheduler local (votre laptop) sans déployer un vrai processus de scheduler.
2) Les tâches sont créées mais jamais traitées ?
Si les jobs existent mais restent « queued », vous avez probablement un worker qui ne traite pas les tâches. Confirmez qu’un worker tourne bien en production (pas seulement pendant le déploiement) et qu’il écoute le même nom de file que votre app utilise.
Vérifiez aussi la connectivité et les identifiants. Les workers ont besoin d’accéder au backend de la file (Redis/SQS/base) et des mêmes variables d’environnement que l’app. Une variable mal configurée peut faire paraître le worker « sain » alors qu’il ne voit jamais les jobs.
3) Les jobs s’exécutent mais échouent et se réessaient en boucle ?
Si vous voyez le nombre de tentatives augmenter, la planification est probablement correcte. On passe à l’exécution. Ouvrez la dernière erreur et cherchez la cause répétée (erreurs d’auth, secrets manquants, timeouts). Les retries doivent avoir un backoff et un nombre max d’essais.
Si un job touche à l’argent, aux e‑mails ou aux données utilisateur, supposez qu’il peut s’exécuter deux fois. L’absence d’idempotence est la raison pour laquelle « ça échoue » peut devenir « ça échoue bruyamment », avec des doubles prélèvements ou des e‑mails répétés.
Résoudre les problèmes de planification (cron et timers)
Vérifiez d’abord les bases : est‑ce que quelque chose déclenche la tâche, et au bon moment ?
Confirmez que le planning est bien celui attendu
Une expression cron peut sembler correcte et être quand même fausse. Les fuseaux horaires sont le piège le plus courant. Votre laptop peut être en heure locale tandis que la prod tourne en UTC. Cela transforme « chaque jour à 9h » en « chaque jour à 1h » ou en dehors de votre fenêtre de test.
Vérifiez aussi comment votre plateforme interprète le planning. Certains systèmes utilisent un cron à 5 champs, d’autres 6 (avec les secondes). Un champ en plus décale tout.
Contrôles rapides qui attrapent la plupart des erreurs :
- Affichez les 5 prochaines exécutions depuis votre scheduler (dans les logs) et confirmez qu’elles correspondent à vos attentes.
- Confirmez le réglage du fuseau horaire dans la config de l’app et dans l’environnement d’hébergement.
- Validez la chaîne cron contre la librairie de scheduler que vous utilisez réellement.
- Assurez-vous que le job est activé en production (feature flags et vars d’environnement diffèrent souvent).
- Confirmez qu’il n’y a qu’une seule instance de scheduler active (sinon vous aurez des doublons).
Rendre le scheduler sûr en production
Un scheduler qui tourne sur votre laptop ne s’exécute pas automatiquement après le déploiement. Dans les prototypes, il est courant d’intégrer le scheduler dans le processus web. Il s’arrête alors dès que le dyno web redémarre, scale-to-zero ou se met en veille.
Les runs manqués sont un autre échec silencieux. Si l’app redémarre à 9h01, le job de 9h00 ne se déclenche pas à moins que vous ne prévoyiez de le rattraper. Pour les tâches importantes, envisagez une approche de rattrapage : au démarrage, vérifiez ce qui aurait dû être exécuté et mettez-le en file.
Enfin, gérez les chevauchements. Si un job peut durer plus longtemps que son intervalle, il vous faut un verrou ou une règle « ne pas se chevaucher ». Sinon vous verrez des envois doublons, des facturations en double ou des mises à jour concurrentes.
Résoudre le déploiement du worker et la connectivité
Si la planification semble correcte mais que les jobs ne sont toujours pas traités, regardez du côté du worker. Une file n’avance que lorsqu’un processus worker est réellement en ligne, connecté et capable de tourner.
Confirmez qu’un processus worker tourne dans le même environnement que l’app (pas seulement sur votre laptop). Cherchez une preuve qu’il démarre, reste en fonctionnement et pointe vers la même file que votre app utilise. Vérifiez la liste des processus ou le tableau de bord du service, puis les logs pour une ligne de démarrage comme "listening" ou "connected".
Lacunes de déploiement souvent vues dans les prototypes générés par IA :
- Le worker n’a jamais été déployé (seul le web app l’a été).
- La commande du worker est incorrecte (lancement d’un script dev, ou sortie immédiate).
- Les variables d’environnement manquent dans le worker (URL de queue, identifiants, NODE_ENV).
- Le worker écoute une autre file/region que l’app.
- Le worker plante et redémarre en boucle (limites mémoire, dépendances manquantes).
Les problèmes de connectivité ressemblent : les jobs s’accumulent et rien ne les consomme. Causes courantes : hôte erroné, ports bloqués, identifiants expirés, ou service de queue accessible uniquement depuis un réseau privé où le worker n’est pas.
La concurrence compte aussi. Trop peu de workers = traitement lent ; trop = timeouts, limites de débit, ou plantages mémoire. Un point de départ simple : 1–2 workers avec faible concurrence, puis augmentez seulement si la mémoire reste stable et le temps d’exécution prévisible.
Exemple : une startup déploie un job « envoyer emails de facture ». L’app met en file correctement, mais le worker démarre sans les identifiants de la file en production et s’arrête. Corriger l’environnement du worker (et ajouter une ligne de log « connecté à la file ») rend le problème évident la fois suivante.
Reprises, backoff et gestion des échecs qui n’explose pas
Parfois, « les tâches ne tournent pas » veut dire en réalité : la tâche tourne, échoue instantanément et se réessaie si vite qu’elle n’avance jamais. De bonnes règles de retry gardent le système calme et les logs lisibles.
Classez les échecs en deux catégories :
- Erreurs transitoires qui s’arrangent : timeouts, limites de débit, verrous DB temporaires, coupures réseau brèves. Celles‑ci doivent se réessayer.
- Erreurs permanentes qui ne s’améliorent pas avec le temps : données manquantes, clé API invalide, « utilisateur introuvable », erreurs de validation, ou bug de code qui plante toujours au même endroit. Celles‑ci doivent échouer vite et aller en état « mort » pour revue.
Le backoff empêche qu’un petit incident devienne une tempête. Un réglage sensé : un nombre réduit de tentatives (par ex. 3–10) avec des délais croissants. Ajoutez un peu de jitter aléatoire pour éviter qu’un millier de jobs ne se réessaient à la même seconde.
Capturez à chaque échec les éléments de base pour reproduire :
- Nom du job, ID unique du job, et numéro de tentative
- Le payload exact (ou un résumé sûr) et les IDs pertinents
- Le message d’erreur et la stack trace, ainsi que le code de réponse upstream si appel API
- Les durées : combien de temps la tâche a tourné, et combien de temps avant la prochaine tentative
Les alertes peuvent être simples. Si la profondeur de la file augmente pendant 10 minutes, ou si l’âge du job le plus ancien dépasse un seuil, notifiez quelqu’un ou au moins postez dans un canal partagé. Ça attrape les échecs « silencieux » où le worker est vivant mais chaque job est bloqué.
Exemple : un job hebdomadaire d’e‑mail rencontre une limite de débit du fournisseur le lundi matin. Sans backoff, il se réessaie immédiatement, consomme toutes les tentatives et perd les e‑mails. Avec backoff et un log clair « rate limited », il attend, récupère, et on peut confirmer la correction.
Idempotence : rendre les jobs sûrs à exécuter plusieurs fois
Quand les jobs refonctionnent (ou que les retries se mettent en marche), un nouveau problème survient souvent : le même job s’exécute deux fois. Si la tâche n’est pas idempotente, « deux fois » peut signifier doubler la facturation, envoyer des e‑mails en double, ou créer des enregistrements dupliqués.
Idempotence = pouvoir exécuter la même tâche plusieurs fois et obtenir un seul résultat correct. Imaginez un job « facturer la carte et envoyer le reçu ». Un glitch réseau peut arriver après que le paiement ait réussi mais avant que votre app n’enregistre le résultat. La queue réessaie, et le client est facturé une seconde fois.
Où les clefs d’idempotence aident le plus
Pour tout ce qui parle à l’extérieur (paiements, envoi d’e‑mails, SMS, webhooks), ajoutez une clef d’idempotence qui reste la même pour l’action logique, pas pour la tentative. Une bonne clef se lie à un ID métier stable, comme invoice_1234 ou order_987.
Protégez aussi votre base contre les duplicatas. La garde la plus simple : une contrainte d’unicité, par exemple « une seule receipt par invoice ». Alors votre job peut « tenter d’insérer » et considérer « déjà présent » comme un succès.
Patterns pratiques qui marchent bien pour passer du prototype à la production :
- Enregistrer d’abord un état de job (par ex.
payment_pending), appeler l’API externe, puis marquerpayment_completed. - Stocker une « processed key » (ID de job ou ID métier) et la vérifier avant d’exécuter les effets secondaires.
- Utiliser des contraintes uniques pour les opérations one‑time (receipts, e‑mails, abonnements).
- Retourner un succès si le résultat existe déjà.
Si vous héritez d’un prototype IA, c’est souvent absent : les jobs font l’effet secondaire d’abord, puis essaient d’enregistrer. Corriger cet ordre suffit souvent à éliminer la plupart des doubles prélèvements et e‑mails.
Étapes détaillées : une procédure de débogage répétable
Arrêtez de deviner et testez un point du pipeline à la fois. L’objectif : transformer un symptôme vague (e‑mails non envoyés, rapports non générés) en un point de défaillance clair et réparable.
Utilisez un petit job de test avec un payload connu, et laissez tout le reste identique à la production :
- Prouvez que la planification déclenche : lancez le scheduler à la demande (ou mettez le cron à chaque minute temporairement) et confirmez qu’il tente d’enfiler le job.
- Prouvez que le job est créé : vérifiez la file, la table de jobs ou le broker pour une nouvelle entrée avec votre payload et horodatage.
- Prouvez qu’un worker peut le voir : lancez un worker unique au premier plan et observez‑le récupérer le job.
- Lisez la vraie erreur : trouvez le premier échec (var env manquante, mauvaise URL DB, envoi d’e‑mail bloqué, permissions).
- Relancez le même job : confirmez qu’il se termine, puis que son exécution double n’applique pas deux fois les changements.
Une fois que ça marche une fois, vous savez quelle couche est cassée : planification, enqueue, déploiement/connectivité du worker, ou logique du job.
Après qu’il fonctionne une fois, ajoutez des garde‑fous
Un job qui ne tourne que quand vous le regardez n’est pas vraiment réparé. Ajoutez quelques protections pour que les échecs n’accumulent pas silencieusement :
- Timeouts et limites (pour éviter que les jobs restent bloqués)
- Règles de retry claires avec backoff (pour éviter les boucles)
- Dead‑letter ou file d’échec (pour que les jobs cassés n’arrêtent pas les bons)
- Vérifications d’idempotence (pour que les retries n’envoient pas deux fois de mails ou ne débitent pas deux fois)
- Logs incluant ID de job et champs clés
Pièges courants qui empêchent les jobs de se terminer
Souvent, l’origine n’est pas le système de queue lui‑même mais un petit décalage entre où tourne le scheduler, où tourne le worker, et ce dont la tâche a besoin pour réussir.
Un échec fréquent : vous séparez la chaîne par accident. Par exemple, cron tourne sur un serveur web, mais le worker est déployé sur une autre machine ou conteneur qui n’est pas actif en production. Le scheduler enfile le travail, mais personne n’est là pour le récupérer.
Autres pièges répétitifs :
- Utiliser une queue en mémoire (ou un adaptateur dev‑only) : les jobs disparaissent au redémarrage ou au scale‑out.
- Attraper les erreurs et renvoyer « succès » quand rien n’a été fait, donnant l’illusion que la tâche est terminée.
- Aucune visibilité sur les échecs, laissant les jobs cassés s’accumuler pendant des jours.
- Secrets et endpoints codés en dur qui diffèrent entre local, staging et prod.
- Jobs qui dépendent de fichiers locaux ou d’un dossier temporaire inexistant sur le worker.
Petit exemple : un job envoie des factures et appelle une API externe. En local, tout fonctionne parce que la clé API est dans votre .env. En production, le container worker n’a pas cette variable, le code attrape l’exception et considère la tâche comme terminée sans envoyer la facture. Vous ne le remarquez que quand les clients se plaignent.
Si vous suspectez un de ces cas, répondez à deux questions : où la tâche s’exécute‑t‑elle (quel service), et où voyez‑vous ses logs ? Si vous ne trouvez pas les deux, les échecs peuvent rester cachés longtemps.
Checklist rapide avant de re‑livrer
Avant de pousser un autre build, faites un passage rapide sur tout le pipeline. La plupart des rapports « tâches en arrière‑plan ne tournent pas » ne viennent pas d’un seul bug. Ce sont de petits décalages entre planification, enqueuing et configuration des workers.
Commencez par le scheduler. Dans beaucoup de prototypes, le processus cron ne tourne jamais en production, ou dans un conteneur qui est mis à l’échelle vers zéro. Confirmez qu’il tourne maintenant (pas seulement qu’il est « configuré »), et qu’il a les mêmes variables d’environnement que l’app.
Ensuite, confirmez que les jobs sont bien créés. Vérifiez que l’horodatage du job correspond au fuseau horaire de production, et que le payload contient de vrais IDs (pas des chaînes vides, des emails placeholders ou des user ID nuls). Si les jobs sont créés mais planifiés loin dans le futur, ils sembleront « bloqués » même si rien n’est cassé.
Puis vérifiez le worker. Assurez‑vous qu’au moins un processus worker tourne en continu et écoute exactement le nom de file utilisé par l’app. Une simple faute de frappe ou un nom de file par défaut différent peut créer des accumulations silencieuses.
Enfin, rendez les échecs visibles et sûrs à réessayer :
- Journalisez les erreurs avec assez de contexte pour agir (nom du job, ID, champs clés)
- Limitez les retries et utilisez un backoff, pour éviter les boucles
- Rendez les jobs idempotents, pour qu’un retry n’envoie pas deux fois ou ne débite pas deux fois
Exemple : le job d’e‑mail hebdomadaire qui marche en local mais pas en prod
Histoire classique « ça marche sur ma machine » : un prototype envoie un rapport hebdomadaire chaque lundi à 9h. Après déploiement, rien n’arrive. Le dashboard est propre, les utilisateurs se connectent, et il n’y a pas d’erreurs visibles.
Premier contrôle : le scheduler existe‑t‑il en production ? En local, votre serveur dev peut lancer automatiquement un scheduler (ou vous l’avez démarré une fois). En prod, l’entrée cron est présente en config, mais aucun processus scheduler ne tourne réellement. Le code est correct, mais rien ne déclenche la file.
Après avoir déployé un scheduler (ou activé le cron de la plateforme), les jobs commencent à apparaître. Cela révèle un second problème : le worker réessaie sans cesse parce qu’une var d’environnement pour le provider d’e‑mail est manquante. Chaque exécution échoue, se remet en file, et crée un backlog. Les nouvelles tâches sont retardées et la file semble « bloquée », alors que le worker travaille… à échouer.
Ce qui corrige durablement :
- Ajouter un log de santé simple quand le scheduler enfile des jobs (pour prouver que les déclenchements ont lieu).
- Echouer vite si des vars env manquent au démarrage (pour que le worker plante bruyamment au lieu de réessayer sans fin).
- Limiter les retries avec backoff (par exemple 5 tentatives sur 30 minutes), puis basculer le job en dead‑letter pour revue.
- Rendre le job d’e‑mail idempotent en sauvegardant une clef unique comme
report:teamId:weekStartDateavant l’envoi, et sauter l’envoi si elle existe déjà.
Avec ces changements, vous pouvez relancer les workers, redéployer ou récupérer d’un crash sans envoyer de doublons ni créer de boucles de retry infinies.
Étapes suivantes : durcir le pipeline et le stabiliser
Une fois les jobs remis en route, l’objectif est d’éviter que la même panne ne revienne. Traitez les tâches en arrière‑plan comme un risque de production, pas comme un bug ponctuel.
Transformez ce que vous avez appris en un court runbook afin que n’importe qui puisse suivre :
- Où sont définis les schedules (config cron, scheduler de la plateforme, timers app)
- Comment démarrer les workers (nom du process, commande, vars env requises)
- À quoi ressemble un état « sain » (profondeur de file, dernière exécution réussie)
- Les principaux modes d’échec observés (timeouts, auth, payloads incorrects)
- La méthode sûre pour rejouer les jobs (et comment éviter les envois en double)
Ajoutez une surveillance minimale qui répond à deux questions : les jobs s’accumulent‑ils, et échouent‑ils ? Même des alertes basiques sur la croissance de la profondeur de file et un décompte quotidien des jobs échoués détectent la plupart des problèmes tôt.
Si votre prototype mélange logique de requête web et logique de job, planifiez une petite refactorisation. Extrayez le cœur du travail du job dans une fonction unique exécutable par le worker, et faites que la requête web ne fasse que mettre en file et valider l’entrée. Cela rend les retries plus sûrs et supprime les dépendances cachées à l’état de la requête.
Si vous avez hérité d’une app générée par IA et voulez un second regard rapide, FixMyMess (fixmymess.ai) se concentre sur le diagnostic et la réparation des prototypes cassés pour que queues, workers, retries et comportement de déploiement correspondent à ce que vous voyez en local — avec une vérification humaine avant livraison.
Questions Fréquentes
How do I know it’s a background job problem and not a normal app bug?
Si les pages se chargent mais que les actions « après coup » ne se produisent jamais (pas d’e-mails, importations bloquées, webhooks reçus mais pas de mises à jour), supposez que ce sont les tâches en arrière-plan. Confirmez en vérifiant si une tâche a bien été mise en file d’attente et si un worker a tenté de l’exécuter autour du moment où l’action utilisateur a eu lieu.
Why do background jobs work locally but not in production?
En développement local, tout tourne souvent au même endroit : serveur web, planificateur et worker. En production, ces éléments sont séparés en processus ou services distincts. Il suffit qu’un élément manque (aucun scheduler en production, worker non déployé, mauvaise connexion à la file) pour casser la chaîne alors que l’application web semble fonctionner.
What’s the fastest way to triage where the pipeline is breaking?
Commencez par déterminer quelle étape est cassée : création de la tâche, prise en charge par le worker, ou exécution. Cherchez d’abord un log d’enqueue ou un enregistrement de tâche ; s’il n’y en a pas, c’est souvent la planification. Si les tâches existent mais restent « queued », c’est généralement un problème de worker ou de connectivité. Si le nombre de tentatives augmente, la tâche s’exécute mais échoue — concentrez-vous alors sur l’erreur et les règles de retry.
What are the most common scheduling (cron) mistakes?
La planification échoue quand aucune tâche n’est créée à l’heure attendue. Causes fréquentes : le scheduler ne tourne pas en production, décalage de fuseau horaire (local vs UTC), configuration pour le mauvais environnement, ou format cron incorrect (5 champs vs 6 champs). Un contrôle simple : journaliser les prochaines exécutions et vérifier qu’elles correspondent à vos attentes.
What’s the difference between the queue and the worker, and what breaks most often?
La file d’attente est l’endroit où les tâches attendent, le worker est le processus qui les récupère et les exécute. Si les tâches s’accumulent en « queued », cela signifie généralement que le worker ne tourne pas, écoute une autre file, ou n’a pas accès au backend de la file (mauvaises identifiants, réseau bloqué).
Why does my worker look “healthy” but still never processes jobs?
Souvent, l’application web et le worker n’ont pas les mêmes variables d’environnement. L’app peut mettre les tâches en file, tandis que le worker manque du queue URL, database URL ou d’une clé API : il démarre mais ne traite rien. Vérifiez que le worker a les mêmes variables critiques que le process web et qu’il journalise clairement « connected to queue » au démarrage.
If retries keep happening, does that mean scheduling is fine?
Pas forcément : cela peut vouloir dire que la tâche échoue instantanément et se réessaie. Vérifiez si le compteur de tentatives augmente et si la même erreur se répète. Si oui, ajoutez un nombre max de tentatives et un backoff pour éviter les boucles infinies, et faites en sorte que les erreurs permanentes aillent dans un état d’échec à revoir plutôt que de se réessayer indéfiniment.
How do I prevent duplicate emails or double charges when jobs retry?
L’idempotence permet d’exécuter la même tâche plusieurs fois sans produire plusieurs effets secondaires. Utilisez des clefs d’idempotence stables pour les appels externes (paiements, e-mails, SMS) et protégez la base avec des contraintes d’unicité (par exemple : une seule receipt par invoice). Si le résultat existe déjà, considérez l’opération comme un succès pour éviter double-paiements ou courriels en double lors des retries.
What information should I collect before changing code?
Récupérez : l’horodatage de l’action utilisateur (ou du déclenchement attendu), le nom/type de la tâche et tout ID de job, les logs du worker pour cette période, la profondeur de la file et les échecs, et la dernière exécution réussie de la même tâche. Ce « pack de preuves » indique vite si les tâches ne sont pas créées, ne sont pas consommées, ou échouent pendant l’exécution.
When should I bring in FixMyMess instead of debugging longer?
Si vous avez hérité d’un prototype généré par IA et que les tâches sont bloquées, échouent silencieusement ou dupliquent des effets, c’est souvent un problème de déploiement ou de pipeline plutôt qu’un bug isolé. FixMyMess peut faire un audit gratuit du code pour repérer s’il manque un scheduler, si un worker est mort, ou s’il y a des problèmes de secrets et retries, puis réparer et durcir la configuration avec une vérification humaine.