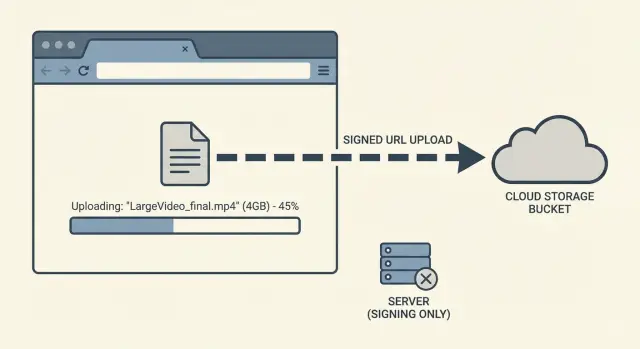
Téléversements directs vers le stockage d'objets pour éviter les délais d'attente
Les téléversements directs vers le stockage objet évitent les timeouts en envoyant les gros fichiers directement au stockage via des URL signées et des uploads résumables, gardant l'application réactive.
Pourquoi les gros téléversements échouent encore dans les vraies applis
Les utilisateurs le remarquent vite : la barre de progression grimpe à 90 % puis se fige. Ils actualisent, réessaient, et ça échoue ailleurs. Sur mobile ou un Wi‑Fi hésitant, ça devient du hasard, même si le fichier est correct.
Quand un upload échoue, on ne perd pas seulement du temps. On perd de la confiance. Un créateur qui a passé 20 minutes à exporter une vidéo ne va pas la retéléverser trois fois de bon cœur. Un recruteur qui attache un portfolio volumineux abandonnera le formulaire. Et votre équipe reçoit les retours : « Ça bloque », « Ça dit échec », « Où est mon fichier ? »
Les tentatives de reprise aggravent souvent la situation. Beaucoup de systèmes repartent de zéro, gaspillent de la bande passante et laissent des fichiers en double « presque uploadés » ou des enregistrements de base de données à moitié finis. Si votre appli sauvegarde des métadonnées avant la vraie fin de l'upload, vous vous retrouvez avec des entrées qui semblent réelles mais ne pointent sur rien.
Les gros fichiers mettent à l'épreuve les maillons faibles d'une architecture classique. Les connexions longues expirent. Les proxies et load balancers coupent les requêtes. Les serveurs voient CPU et mémoire monter s'ils mettent en tampon de gros payloads. Un upload lent peut monopoliser des ressources destinées à tout le monde.
L'objectif est simple : permettre le téléversement fiable de gros fichiers sans transformer votre serveur applicatif en intermédiaire fragile. Les téléversements directs vers le stockage objet répondent à ce besoin. Plutôt que de faire transiter des gigaoctets par votre backend, l'appareil de l'utilisateur envoie directement au stockage. Votre appli gère l'autorisation, le suivi et la confirmation du résultat.
C'est souvent là que les prototypes craquent : « ça marche sur les petits fichiers », puis ça s'effondre en production.
Qu'est‑ce qui provoque généralement les timeouts d'upload
La plupart des timeouts arrivent parce que votre serveur joue le rôle de relais. Le navigateur envoie un gros fichier à votre serveur, celui‑ci garde la connexion ouverte, puis renvoie les mêmes octets vers le stockage objet. Si l'utilisateur est lent, votre serveur est bloqué à attendre. Pendant ce temps, mémoire et CPU augmentent, et les autres requêtes commencent à ralentir.
Les timeouts peuvent aussi venir de n'importe où sur le chemin. Une seule limite suffit pour tuer un upload même si tout le reste est en bonne santé : l'onglet du navigateur (mise en arrière‑plan, veille, changement de réseau), un proxy ou load balancer avec une limite stricte, les timeouts des workers de votre serveur, les limites de taille/parsing du framework, ou l'appel du client de stockage lui‑même.
La réaction habituelle est « augmentez juste le timeout ». Ça peut vous donner un jour de répit, mais rarement la vraie solution. Des timeouts plus longs signifient plus de connexions longue durée et un risque de surcharge plus grand. Une personne téléversant une vidéo de 2 Go sur un Wi‑Fi instable peut occuper un worker pendant des minutes, et tout à coup les utilisateurs normaux voient des pages lentes ou des connexions échouées.
Imaginez un scénario courant : un utilisateur téléverse depuis le Wi‑Fi d'un café. À mi‑parcours, la connexion coupe 10 secondes. Le navigateur réessaie, votre serveur tient toujours une requête à moitié finie, un proxy la tue au bout de 60 secondes, et l'utilisateur reçoit « Échec du téléversement » sans raison claire.
Les téléversements directs vers le stockage aident parce qu'ils retirent votre serveur du chemin des données lourdes.
Ce que signifient les téléversements directs vers le stockage (en clair)
Téléverser directement vers le stockage objet signifie que le fichier va directement de l'appareil de l'utilisateur (navigateur ou appli mobile) vers votre bucket de stockage, au lieu de transiter d'abord par votre serveur applicatif. Votre appli orchestre toujours l'opération, mais elle ne transporte pas les octets du fichier.
Pensez‑y ainsi : votre serveur donne à l'utilisateur un sésame limité dans le temps. L'utilisateur s'en sert pour téléverser directement vers le stockage. Cette permission peut être verrouillée pour un seul fichier, une seule destination et une courte fenêtre temporelle.
En pratique, votre backend fait trois petites choses :
- confirmer que l'utilisateur est autorisé à téléverser
- créer la permission de téléversement courte (souvent une URL signée)
- enregistrer les métadonnées et plus tard vérifier que l'upload est bien terminé
Le gain est immédiat : moins de timeouts, moins de pression sur la bande passante serveur et une expérience plus fluide. Les services de stockage sont conçus pour accepter beaucoup de gros uploads en parallèle.
Un exemple simple : un fondateur teste en téléversant une grosse vidéo de démonstration. Avec « upload via mon serveur », la requête peut mourir à 60 s, 120 s, ou quand un proxy juge qu'on a attendu trop. Avec l'approche directe, le navigateur envoie au stockage et votre appli ne gère qu'une petite requête « démarrer » et une petite requête « confirmer ».
Uploads signés : la façon sûre de laisser les utilisateurs téléverser directement
Une URL signée est ce sésame à courte durée que votre backend créé pour permettre à un utilisateur de téléverser sur le stockage objet sans que votre serveur soit au milieu.
Le côté « signé » compte car l'URL (ou les champs d'un formulaire) contient une preuve que votre backend a approuvé l'upload selon des règles précises. Si quelqu'un copie l'URL plus tard, elle devrait être inutilisable car elle expire rapidement et autorise une action restreinte.
Quelles restrictions inclure dans une URL signée ?
Les uploads signés doivent être stricts par défaut. De bonnes limites comprennent une durée d'expiration (des minutes, pas des heures), un plafond de taille, les types de contenu autorisés (par ex. video/mp4 ou image/png) et une clé/destination verrouillée ou un motif de chemin pour que les utilisateurs ne puissent pas écraser d'autres fichiers. Si vous comptez sur des métadonnées (comme un owner ID), validez‑les aussi.
Un flux typique : l'utilisateur choisit une vidéo de 1 Go. Votre backend vérifie le compte et le type/poids attendu, puis retourne une URL signée valable, disons, 10 minutes. Le navigateur upload directement vers le stockage, et votre backend reçoit ensuite un petit message « upload terminé ».
Requête unique vs uploads multipart
Utilisez une URL signée en une seule requête quand les fichiers sont suffisamment petits pour que la requête finisse en une fois et que vous n'ayez pas besoin de reprise.
Pour les gros fichiers, préférez le multipart. Le multipart coupe le fichier en morceaux afin de ne relancer que la partie qui a échoué au lieu de repartir de zéro. C'est souvent la différence entre « marche sur le réseau de bureau » et une vraie fiabilité.
Stratégies résumables qui survivent aux connexions instables
Les gros uploads échouent pour des raisons banales : coupures Wi‑Fi, mise en veille du portable, changement de réseau sur le téléphone. Si votre upload dépend d'une seule requête longue, la moindre alerte force l'utilisateur à recommencer.
Les uploads résumables transforment un transfert fragile en plusieurs transferts petits et retentables. Cela se marie naturellement avec le téléversement direct car votre serveur ne babysitte plus un gros fichier pendant des minutes.
Comment fonctionnent les uploads résumables
Plutôt que d'envoyer tout le fichier d'un coup, le client le découpe en morceaux (chunks). Chaque morceau s'upload séparément et le système garde la trace de ce qui est arrivé.
Une approche simple :
- découper le fichier en chunks de taille fixe (par ex. 5–25 Mo chacun)
- téléverser les chunks dans l'ordre (ou plusieurs en parallèle) et enregistrer les numéros de chunks complétés
- ne réessayer que les chunks qui ont échoué, avec un backoff (attendre de plus en plus entre chaque essai)
- reprendre plus tard en demandant « Quelles parties avez‑vous déjà ? » puis continuer
- finaliser en demandant au stockage d'assembler les parties en un seul objet
Si le navigateur plante ou que l'appareil se met en veille, la session suivante peut reprendre depuis le dernier chunk confirmé.
Ce que l'utilisateur doit ressentir
La reprise n'est pas qu'un choix backend. Elle change la sensation de l'upload. Les utilisateurs doivent voir une progression basée sur les chunks confirmés et disposer de contrôles réalistes : pause, reprise et un état clair « reconnexion » quand le réseau titube.
Exemple : quelqu'un téléverse une vidéo de 3 Go dans un train. La connexion coupe deux fois. Avec les uploads résumables, seules deux parties sont renvoyées, la progression reste honnête et l'upload se termine sans repartir à 0 %.
Étape par étape : un flux d'upload fiable à implémenter
Un flux fiable tient votre serveur hors du chemin des données. Votre serveur fixe les règles et confirme les résultats. Le navigateur envoie le fichier directement au stockage.
Une séquence pratique :
- Le client demande à téléverser (métadonnées seulement). Envoyez nom de fichier, taille, type et contexte (projet, utilisateur), mais pas le fichier.
- Le serveur valide et renvoie les infos signées. Faites respecter les limites, créez un enregistrement brouillon en base, puis retournez les infos d'upload signées plus un ID/clé d'upload.
- Le navigateur upload directement et affiche la progression. Téléversement du client vers le stockage et mise à jour de la progression. Si vous supportez le chunking, conservez l'état des chunks localement pour qu'un rafraîchissement puisse reprendre.
- Le client confirme la complétion. Après le succès côté stockage, le client appelle votre serveur avec l'ID/clé d'upload et la taille attendue.
- Le serveur vérifie et finalise. Confirmez que l'objet existe, correspond en taille/type et appartient au bon utilisateur. Puis marquez l'enregistrement comme prêt.
Un petit détail qui évite beaucoup de douleurs : traitez l'upload comme une machine à états. « Draft » n'est pas « ready ». Ne basculez en « ready » qu'après vérification côté serveur.
Dégagez le travail post‑upload de la requête d'upload. Mettez en file des tâches comme vignettes, scan antivirus ou transcodage pour que les utilisateurs n'attendent pas et que les timeouts ne s'additionnent pas.
Faire paraître les uploads dignes de confiance pour les utilisateurs
Les gens pardonnent un upload lent. Ils ne pardonnent pas un upload confus. Même avec le téléversement direct, la connexion reste souvent le maillon faible, donc votre UI doit poser les attentes et tenir ses promesses.
Rendez la progression honnête. Un pourcentage seul est trompeur pour les gros fichiers car la vitesse varie. Affichez les Mo uploadés sur le total et traitez « temps restant » comme une estimation. Si l'envoi stagne, dites‑le. « En pause, tentative de reconnexion » vaut mieux qu'un 72 % figé.
Un schéma simple :
- afficher les Mo uploadés sur le total et la vitesse actuelle
- afficher une ETA seulement après quelques secondes de transfert stable
- détecter l'absence de progrès pendant N secondes, puis basculer en « reconnexion »
- offrir une action claire « Pause » ou « Réessayer »
Les uploads semblent aussi plus sûrs quand ils survivent aux comportements normaux. Si quelqu'un rafraîchit, ferme l'onglet ou met son portable en veille, conservez assez d'état local (nom, taille, ID de session d'upload, parties complétées) pour reprendre au lieu de recommencer.
Quand une erreur survient, soyez précis et proposez une suite. « Upload échoué » n'aide pas. « Votre connexion a été coupée. Nous avons sauvegardé votre progression. Cliquez sur Reprendre. » rassure. Si l'utilisateur a choisi le mauvais type de fichier ou dépassé une limite, précisez ce qui est autorisé.
L'accessibilité compte car le statut d'upload évolue dans le temps. Utilisez des libellés lisibles (pas seulement la couleur), gardez le focus sur l'action cliquée et annoncez les changements clés (démarré, en pause, repris, terminé) pour que les utilisateurs au clavier ou aux lecteurs d'écran ne soient pas laissés dans le doute.
Erreurs courantes et pièges à éviter
Le plus grand piège avec les uploads directs vers le stockage est de penser « le navigateur s'en est chargé, donc tout est bon ». Le stockage est fiable, mais votre appli doit toujours contrôler l'accès, confirmer la complétion et garder la base de données cohérente.
Faire trop confiance au navigateur
Une URL signée prouve que l'utilisateur avait la permission au départ. Elle ne prouve pas ce qu'il a uploadé, ni que l'upload est allé à son terme.
Après l'upload, vérifiez côté serveur que l'objet existe et correspond à la taille et au type attendus, qu'il est bien placé dans le préfixe/dossier prévu pour cet utilisateur ou projet, et que les métadonnées attendues correspondent. Ce n'est qu'après que vous marquez l'upload comme « ready ».
URLs signées trop permissives
Certains systèmes « règlent » les timeouts en donnant des URLs signées valables des heures et acceptant n'importe quel fichier. C'est risqué. Gardez l'URL courte et fortement limitée : taille, types MIME, destination verrouillée.
Enregistrements d'uploads jamais terminés
Si vous créez un enregistrement « uploaded » avant confirmation, vous allez accumuler des entrées cassées et des fichiers manquants. Créez‑le comme « pending », puis passez à « uploaded » seulement après vérification (ou après un événement callback du stockage si vous en utilisez un).
Traitement lourd dans la requête d'upload
Ne faites pas attendre l'utilisateur pendant que vous transcodez, scannez ou générez des vignettes. Acceptez l'upload, confirmez‑le, puis mettez le traitement en arrière‑plan et affichez un statut clair. Cela garde le chemin d'upload rapide et prévisible.
Renvoyer accidentellement les fichiers via votre API
Si votre frontend retombe sur l'envoi du fichier à votre API quand l'upload direct échoue, vous revenez aux timeouts. Gardez l'auth et le trafic de contrôle sur votre API, mais laissez les octets du fichier aller droit au stockage.
Liste de contrôle rapide avant mise en production
Avant de considérer la fonctionnalité d'upload comme « terminée », faites un rapide passage sur fiabilité et sécurité. La plupart des bugs d'upload n'apparaissent que lorsque de vrais utilisateurs tentent des gros fichiers sur un Wi‑Fi instable ou quand le traitement en arrière‑plan prend plus de temps que votre timeout HTTP.
- La reprise fonctionne sans repartir de zéro. Si la connexion tombe à 80 %, l'utilisateur doit continuer où il s'est arrêté.
- Les limites sont appliquées avant de donner la permission. Vérifiez type et taille tôt et refusez d'émettre une permission pour des fichiers que vous n'accepterez jamais.
- Les permissions signées sont courtes et strictes. Un fichier, un chemin, une méthode. Pas « upload anything anywhere ».
- La complétion est vérifiée dans le stockage. Ne marquez pas un upload comme terminé uniquement parce que le client l'a indiqué.
- Le travail lourd est déplacé hors de la requête d'upload. Convertir, scanner, OCR et vignettage après l'upload.
Si le traitement prend du temps, affichez deux statuts séparés : « Uploadé » et « En traitement ». Les utilisateurs font davantage confiance aux systèmes qui expliquent ce qui se passe.
Un exemple réaliste : un gros upload qui ne tombe pas en échec
Un créateur est assis dans un café et tente de téléverser une vidéo de 3 Go. Le Wi‑Fi coupe quelques secondes de temps en temps, et son ordinateur passe en veille une fois. Il s'attend à ce que l'upload finisse sans repartir à zéro.
Avec l'ancienne approche, le navigateur envoie tout d'abord le fichier à votre serveur, qui le retransmet ensuite au stockage. Après 30 à 120 secondes (selon votre configuration), quelque chose timeoute : le load balancer, un reverse proxy, une limite serverless, ou une requête lente. L'utilisateur voit une erreur, rafraîchit, et l'upload recommence à 0 %. Le support reçoit des messages du type « J'ai essayé trois fois et ça ne marche jamais. »
Comparez cela au téléversement direct via URL signée + uploads résumables. Votre serveur ne fait que fournir une permission courte et un plan d'upload. Le navigateur envoie le fichier en parties (par ex. chunks de 10–50 Mo). Quand le Wi‑Fi du café saute, seule la partie en cours échoue.
Au lieu de tout perdre, le client réessaie la partie manquante, continue depuis la dernière partie confirmée, garde une progression crédible et termine même si la connexion est imparfaite.
Votre équipe produit peut mesurer la différence rapidement : taux de complétion des uploads, moyenne de tentatives par upload et temps jusqu'à l'actif prêt à être lu ou traité. Le meilleur signe est moins de tickets « uploads bloqués » ou « uploads qui recommencent », parce que le système récupère silencieusement et que votre serveur reste réactif.
Prochaines étapes si votre flux d'upload actuel est déjà fouillis
Si les uploads sont déjà instables, ne réécrivez pas tout d'un coup. Les gains les plus rapides viennent de réduire la portée, rendre les échecs visibles et enlever la partie la plus risquée (votre serveur qui proxy des fichiers lourds).
Commencez par un type d'upload, comme les vidéos ou les PDF. Choisissez celui qui génère le plus de tickets de support ou les fichiers les plus volumineux. Gardez l'ancien chemin pour les autres types jusqu'à ce que le nouveau prouve son efficacité.
Avant de changer le comportement, ajoutez un suivi basique pour voir ce qui casse. Les timeouts cachent souvent plusieurs problèmes : réseaux lents, tempêtes de retries, CORS mal configuré, tokens expirés, utilisateurs qui quittent l'onglet.
Un plan de nettoyage qui marche souvent :
- migrer un écran et un type de fichier vers un téléversement direct vers le stockage
- instrumenter le démarrage d'upload, les octets envoyés, la complétion et une raison d'échec claire
- confirmer les frontières d'auth : créer des permissions signées courtes, ne jamais envoyer de clés longue durée au navigateur
- supprimer les secrets exposés et la logique emmêlée (clés en dur, endpoints dupliqués, responsabilités mélangées, boucles de retry infinies)
- centraliser le flux d'upload (un module client, un endpoint API qui émet les signatures)
Si vous avez hérité d'une appli générée par IA, passez plus de temps sur l'authentification et la gestion des secrets. « Ça marche sur ma machine » passe souvent outre les vérifications côté serveur ou couple les uploads au serveur d'une façon qui s'effondre sous la vraie charge.
Si vous voulez un second regard, FixMyMess (fixmymess.ai) peut faire un audit de code gratuit pour trouver les problèmes d'upload et de sécurité, puis aider à réparer le flux pour qu'il tienne en production.
Questions Fréquentes
Pourquoi les téléversements volumineux échouent-ils même si mon serveur semble OK ?
La plupart des échecs surviennent parce que le téléversement passe d'abord par votre serveur applicatif. Cela crée une requête longue qui peut être interrompue par le navigateur, un proxy, un load balancer, une limite serverless ou le timeout d'un worker sur votre serveur. En sortant les octets du fichier du backend (téléversement direct vers le stockage), on supprime la partie la plus fragile du chemin.
Que doit exactement faire mon backend dans un flux de téléversement direct vers le stockage ?
Votre serveur doit uniquement gérer l'autorisation, le suivi et la vérification. Il peut valider l'utilisateur, créer une permission signée courte pour l'upload, créer un enregistrement brouillon en base, et finaliser l'enregistrement après vérification que l'objet existe dans le stockage. Le serveur ne doit pas streamer ni mettre en mémoire tampon le fichier lui‑même.
Qu'est-ce qu'un upload signé, et pourquoi est-ce plus sûr ?
Un upload signé est une permission à courte durée que votre backend crée pour permettre au client de téléverser directement vers le stockage d'objets selon des règles strictes. C'est plus sûr que d'exposer des identifiants longue durée car l'URL expire vite et peut être limitée à un seul fichier, une seule destination et des contraintes précises.
Quelles limites dois-je mettre sur les permissions d'upload signées ?
Commencez strict et assouplissez seulement si nécessaire. Utilisez une expiration courte (des minutes), un plafond de taille, des types MIME autorisés et une clé ou un préfixe de destination qui empêche d'écraser les fichiers d'autres utilisateurs. Ces limites réduisent les abus et évitent les fichiers « téléversés mais inutilisables ».
Quand dois‑je utiliser les multipart uploads plutôt qu'une URL signée unique ?
Les uploads en une seule requête conviennent aux petits fichiers où une requête unique termine généralement. Pour les gros fichiers ou quand il faut pouvoir reprendre, préférez le multipart/fragmentation : une interruption n'oblige pas à tout recommencer. Le multipart est la solution pratique pour les utilisateurs sur réseau mobile ou Wi‑Fi instable.
Comment fonctionnent en pratique les uploads résumables ?
On découpe le fichier en parties, on téléverse chaque partie indépendamment et on conserve la trace des parties reçues. Si la connexion tombe, on ne réessaie que les parties manquantes. L'important est de stocker suffisamment d'état (comme un ID de session d'upload et les numéros de parties complétées) pour que, après un rafraîchissement ou une reprise, on puisse continuer là où on s'est arrêté.
Comment empêcher ma base de données de se remplir d'enregistrements « uploaded » sans fichier ?
Ne marquez pas un upload comme terminé simplement parce que le client l'a dit. Après le signal de succès du client, votre serveur doit vérifier dans le stockage que l'objet existe, correspond à la taille et au type attendus, puis basculer l'enregistrement de « pending » à « ready ». Ainsi on évite les enregistrements cassés pointant vers des fichiers manquants.
Quelles modifications UI rendent les uploads plus fiables aux yeux des utilisateurs ?
Affichez la progression en octets confirmés, pas seulement un pourcentage qui peut se figer. Indiquez clairement quand l'envoi stagne (par exemple « Reconnexion ») et proposez un bouton Reprendre ou Réessayer. Si possible, conservez l'état localement pour qu'un rafraîchissement n'oblige pas à repartir de zéro, c'est le moyen le plus rapide de garder la confiance des utilisateurs.
Pourquoi ne pas transcoder ou scanner pour virus pendant la requête d'upload ?
Le traitement en ligne augmente le risque de timeout et fait attendre l'utilisateur pour des opérations qui ne doivent pas bloquer l'upload. Acceptez et vérifiez l'upload puis lancez l'analyse, la génération de vignettes ou la transcodification en arrière‑plan avec un statut « Processing » séparé. Cela garde le chemin d'upload rapide et prévisible.
Mon code d'upload est désordonné (en partie généré par l'IA). Quelle est la façon la plus rapide de le corriger ?
Migrez d'abord un écran et un type de fichier vers un flux direct, vérifié et basé sur une machine à états, puis mesurez le taux de réussite et les raisons d'échec. Si le code est généré par IA, vérifiez en priorité les frontières d'authentification, supprimez les secrets exposés et éliminez les retours accidents qui renvoient les octets via votre API. Si vous le souhaitez, FixMyMess (fixmymess.ai) peut réaliser un audit de code gratuit et réparer le flux d'upload pour la production.