Transactions de base de données pour écritures atomiques : stop aux données partiellement sauvegardées
Apprenez comment les transactions de base de données pour écritures atomiques empêchent les enregistrements partiellement sauvegardés, avec étapes simples, gestion des rollbacks et contrôles rapides pour des apps plus sûres.
Quels sont les enregistrements « partiellement sauvegardés » et pourquoi ils apparaissent
Un enregistrement « partiellement sauvegardé » apparaît lorsqu'une action utilisateur nécessite plusieurs modifications en base de données, mais que seules certaines réussissent. L'utilisateur pense avoir terminé l'action, mais la base contient maintenant une version incomplète.
Exemple : un passage en caisse devrait (1) créer une commande, (2) réserver du stock et (3) enregistrer une tentative de paiement. Si la ligne de commande est créée mais que la mise à jour du stock échoue, vous obtenez une commande qui ne peut pas être expédiée. Si le stock est réservé mais que la ligne de paiement est manquante, le support voit du stock disparaître sans revenu correspondant.
Ce type d'incohérence crée des bugs qui semblent aléatoires :
- lignes manquantes (une commande existe, mais pas ses articles)
- totaux décalés (le total de la facture ne correspond pas aux lignes)
- enregistrements orphelins (un paiement référence une commande qui n'a jamais été créée)
- doublons (une reprise crée une seconde commande)
- états « bloqués » (le statut indique « payé » mais rien d'autre ne le confirme)
Les utilisateurs vivent cela comme une confusion à conséquences importantes : une inscription qui affiche « Bienvenue » mais qui empêche de se connecter ensuite, un email de confirmation de commande avec une commande vide, ou un paiement qui semble réussi sans qu'aucun abonnement n'apparaisse.
Les données partiellement sauvegardées surviennent généralement quand le code exécute plusieurs INSERT/UPDATE séparément, sans les considérer comme une seule unité. Un léger problème réseau, un plantage serveur, une erreur de validation ou un timeout au milieu suffit à laisser les premières étapes engagées et les suivantes sautées.
C'est particulièrement fréquent dans les prototypes générés par l'IA, car ils se concentrent sur le chemin heureux. Les cas limites — échecs partiels, reprises, nettoyage — sont souvent absents, si bien que des actions qui devraient être atomiques deviennent une chaîne de requêtes indépendantes sans plan clair de rollback.
Quand utiliser une transaction (et quand ne pas l'utiliser)
Utilisez une transaction quand une action utilisateur crée ou modifie des données à plusieurs endroits et qu'un état « à moitié fait » est inacceptable. Le but est simple : soit toutes les modifications liées sont sauvegardées, soit aucune.
Les transactions conviennent quand les enregistrements dépendent les uns des autres, comme la création d'un en-tête de commande et de ses lignes. Si la commande est sauvegardée mais pas ses lignes, votre application a un enregistrement qui semble réel mais ne peut pas être honoré.
Elles sont aussi l'outil adapté lorsque les changements doivent échouer ensemble pour des raisons monétaires ou de limites : comptes, stocks, crédits, quotas. Si une mise à jour se produit sans l'autre, vous pouvez survendre, facturer en double ou laisser des utilisateurs dépasser leurs limites.
Règle pratique : si vous touchez plusieurs tables pour un même résultat, partez du principe que vous avez besoin d'une transaction.
Si un workflow traverse des services (écriture en base + envoi d'email ou prélèvement), gardez les effets externes hors de la transaction. Enregistrez l'état d'abord, validez (commit), puis déclenchez l'email ou le paiement de façon réessayable.
Signes que vous avez probablement besoin de transactions (ou de mieux les délimiter) : scripts de nettoyage récurrents après des échecs, tickets support du type « je le vois sur un écran mais pas sur un autre », dashboards qui divergent parce que des lignes manquent, et du code où les sauvegardes sont dispersées dans des helpers.
Quand ne pas utiliser une transaction : pour des travaux longs ou lents (traitement de fichiers, gros lots, attente d'APIs tierces). Garder une transaction ouverte trop longtemps peut bloquer d'autres utilisateurs et augmenter les timeouts.
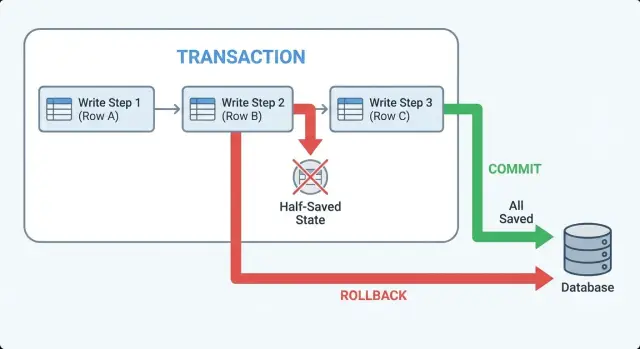
Transactions en termes simples : commit, rollback, atomique
Une transaction est une enveloppe de sécurité autour d'un ensemble d'écritures en base. Elle transforme « sauvegarder ces 3 choses » en une action tout-ou-rien.
« Atomique » signifie que toutes les modifications du groupe sont sauvegardées, ou aucune. Il n'existe pas d'état intermédiaire où certaines lignes existent et d'autres non.
Pensez à un checkout où vous (1) créez une commande, (2) réservez du stock et (3) enregistrez une tentative de paiement. Sans transaction, un plantage entre les étapes peut laisser une commande qui semble réelle mais sans articles réservés, ou des articles réservés sans commande. Avec une transaction, la base considère ces étapes comme une seule unité.
Voici les termes que vous verrez dans le code et les logs :
- Begin : démarrer la transaction. Les modifications sont temporaires jusqu'à la fin.
- Commit : rendre permanent. Toutes les modifications tombent en même temps.
- Rollback : annuler. La base ignore tout depuis le begin.
Commit et rollback sont les deux fins propres. Si votre app peut quitter prématurément (erreur, timeout, validation), vous voulez que le code rende évident quelle fin a eu lieu.
Une phrase sur l'isolation
L'isolation signifie que votre transaction est protégée des surprises causées par d'autres opérations concurrentes, pour ne pas lire ou écrire sur des données qui changent sous vos pieds.
Si vous ne devez retenir qu'une règle : regroupez les INSERTs et UPDATEs liés qui doivent réussir ensemble, et n'exécutez pas d'effets secondaires (emails, webhooks, jobs) avant le commit.
Étape par étape : encapsuler une écriture multi-étapes dans une transaction
Les données partiellement sauvegardées surviennent lorsqu'une étape initiale réussit (par exemple créer une ligne) et qu'une étape suivante échoue (par exemple mettre à jour un solde). La solution est de traiter l'ensemble des modifications comme une unité de travail.
Commencez par définir la frontière : tout ce qui doit être vrai ensemble doit être à l'intérieur de la transaction. Par exemple, « créer commande + réserver stock + enregistrer l'intention de paiement » doit soit tout se produire, soit ne pas se produire.
Un flux fiable ressemble à ceci :
- Démarrer une transaction avant le premier INSERT/UPDATE de l'unité de travail.
- Exécuter les instructions dans un ordre sûr (ligne parente d'abord, puis enfants, puis mises à jour dérivées).
- Après chaque instruction critique, vérifier que le résultat correspond à l'attendu (nombre de lignes, id retourné, contraintes).
- Si une étape échoue, arrêter immédiatement et rollback.
- Commit uniquement quand chaque étape a réussi, puis renvoyer une réponse claire de succès.
Voici la forme en pseudocode :
BEGIN;
-- 1) Create parent
INSERT INTO orders(...) VALUES(...) RETURNING id;
-- 2) Create children
INSERT INTO order_items(order_id, ...) VALUES (...);
-- 3) Update derived state
UPDATE inventory SET reserved = reserved + 1 WHERE sku = ? AND available > 0;
COMMIT;
Deux détails font la différence.
D'abord, ne pas avaler les erreurs. Si l'étape 3 met à jour 0 lignes, considérez cela comme une erreur, levez une exception et faites un rollback.
Ensuite, n'envoyez pas une réponse de succès avant que le commit soit terminé. « OK » avant le commit est la façon dont du travail partiel fuit en tant que « succès ».
Si vous avez hérité d'un code généré par l'IA, surveillez les fausses transactions où chaque requête ouvre sa propre connexion. Le code peut sembler transactionnel alors que les requêtes s'exécutent en réalité sur des sessions différentes.
Gérer les échecs : chemins de rollback explicites et erreurs claires
Les données partiellement sauvegardées viennent souvent d'une logique qui considère les erreurs comme « le problème de quelqu'un d'autre ». Décidez à l'avance ce qui compte comme un échec et rendez chaque chemin d'erreur explicite dans le code.
Rollback sur plus que des plantages. Faites rollback sur les exceptions (timeouts, erreurs de contrainte, deadlocks), les vérifications ratées (une mise à jour affecte 0 lignes alors qu'elle doit en affecter 1), les validations dépendant de l'état courant (« l'utilisateur a déjà un abonnement actif ») ou les écritures dépendantes qui retournent des valeurs inattendues.
Ensuite, rendez le rollback explicite. Évitez les patterns comme « catch et ignorer » ou retourner false sans nettoyage. Une structure simple vous garde honnête :
begin transaction
try:
write A
write B
verify row counts
commit
return success
except error:
rollback
log safe context
return clear failure
finally:
close connection
Les erreurs claires sont importantes. L'appelant doit savoir quoi faire ensuite (« réessayer » vs « entrée invalide »), mais le message ne doit pas divulguer des secrets comme du SQL, des tokens ou des variables d'environnement. Une approche pratique : une raison courte plus un identifiant d'erreur interne que vous pouvez retrouver dans les logs.
Ne laissez jamais une transaction ouverte. Les transactions ouvertes peuvent verrouiller des lignes, bloquer d'autres utilisateurs et faire échouer plus tard des requêtes de façon étrange. Engagez toujours un commit ou un rollback, et libérez la connexion (ou rendez-la au pool) dans un bloc finally.
Consignez suffisamment pour reproduire le problème sans divulguer de données privées : nom de l'opération (signup, checkout), ids pertinents, comptes de lignes et type d'erreur. Un échec courant dans les bases de code générées par l'IA est de capturer les erreurs, renvoyer « succès » et laisser la base divisée entre deux réalités.
Reprises et idempotence : rester sûr face aux timeouts
Les timeouts créent une situation délicate : le client abandonne, mais le serveur peut encore terminer le travail et commit. Si le client réessaye, vous pouvez créer la même commande deux fois, accorder un accès deux fois ou facturer en double.
Les transactions maintiennent chaque tentative en tout-ou-rien, mais elles n'empêchent pas qu'une même tentative soit rejouée. C'est là qu'intervient l'idempotence.
L'idempotence signifie que la même requête répétée produit le même résultat. Un pattern courant est d'exiger une clé d'idempotence (un ID aléatoire du client) et de la stocker avec le résultat final. Lors d'une reprise, vous cherchez cette clé et renvoyez le résultat original au lieu de relancer tout le flux.
Façons pratiques de rendre les reprises sûres :
- Ajouter des contraintes uniques qui reflètent des règles métiers réelles (un profil par utilisateur, un abonnement par utilisateur par workspace).
- Stocker la clé d'idempotence avec un index unique et sauvegarder l'ID de l'enregistrement créé associé.
- Utiliser upsert quand cela correspond à la règle métier (créer si manquant, sinon réutiliser la ligne existante).
- Traiter une violation de contrainte unique comme un résultat normal de reprise : récupérer la ligne existante et la renvoyer.
- Rendre aussi idempotents les effets externes (paiements, emails).
Exemple : une requête de checkout timeoute juste après le commit en base, mais avant que la réponse n'arrive au navigateur. La reprise arrive. Avec une contrainte unique sur (user_id, cart_id) et une clé d'idempotence stockée avec payment_intent_id, la seconde requête renvoie la même commande et ne crée pas un second prélèvement.
Conseils de conception : garder les transactions courtes et séparer les effets secondaires
Les transactions fonctionnent mieux quand elles couvrent une action métier claire. Placez les règles clés à la frontière : validez ce qui doit être vrai, écrivez les lignes liées, puis commit.
Les transactions longues nuisent car elles maintiennent des locks ouverts. D'autres requêtes s'accumulent derrière elles et les timeouts deviennent plus probables. Faites le minimum nécessaire pour rendre la base cohérente, puis sortez.
Garder la transaction ciblée
Une erreur courante est de traiter une transaction comme un « try/catch » général pour tout ce qui pourrait échouer. Gardez le travail non lié en dehors.
Règles empiriques :
- Placez uniquement les lectures et écritures qui doivent réussir ensemble dans la transaction.
- Évitez d'appeler des services externes pendant que la transaction est ouverte.
- Évitez les requêtes lentes ou les grosses mises à jour dans la même transaction que des écritures côté utilisateur.
- Gardez le chemin d'exécution simple (un point d'entrée, un commit).
Séparer les effets secondaires des changements de données
Les effets secondaires comme l'envoi d'emails, le prélèvement de cartes, la création de fichiers ou le téléchargement d'images ne sont pas du travail de base de données. Si vous les faites dans la transaction, vous risquez d'envoyer une confirmation puis d'annuler les données.
Un pattern plus sûr : écrire les données, commit, puis déclencher les effets secondaires.
Si vous avez besoin d'une forte fiabilité, écrivez un enregistrement « outbox » dans la même transaction (par exemple « envoyer email de bienvenue pour l'utilisateur 123 »). Après le commit, un worker lit l'outbox et exécute l'effet. S'il échoue, vous réessayez sans corrompre vos enregistrements principaux.
Erreurs courantes qui causent encore des données partiellement sauvegardées
Beaucoup de bugs de données partiellement sauvegardées ne viennent pas d'un manque de transaction. Ils surviennent quand une transaction est utilisée d'une manière qui brise silencieusement la garantie tout-ou-rien.
Une erreur classique est de sauvegarder l'enregistrement « principal », committer, puis créer ensuite des lignes liées requises (log d'audit, profil, table de jointure). Si la seconde étape échoue, vous vous retrouvez avec un enregistrement valide dans une table mais sans ses compagnons requis.
Un autre problème fréquent est une gestion des erreurs qui évite le nettoyage. Une transaction peut être ouverte correctement, mais une branche retourne tôt (ou jette une exception dans un callback) sans rollback. Selon la pile, cela peut laisser la connexion dans un état incorrect ou mener à des commits inattendus.
Patterns d'échec souvent vus dans le code généré par l'IA :
- Catcher une erreur, la logger, et continuer à renvoyer « succès ».
- Appeler une API tierce (email, paiement, upload) pendant que la transaction est ouverte, donc un réseau lent maintient des locks.
- Mélanger des clients DB, si bien qu'une écriture s'exécute sur une connexion différente et ne fait pas partie de la même transaction.
- Réessayer la requête sans idempotence, ce qui crée des doublons après un timeout.
Exemple : un flow d'inscription INSERT dans users, puis user_profiles, puis org_members. Si l'INSERT du profil échoue mais que l'INSERT user a déjà committé, la tentative suivante peut échouer sur « email déjà utilisé » et l'utilisateur reste en limbo.
Deux règles pratiques préviennent beaucoup de cas : limitez la transaction au travail de base de données, et rendez chaque chemin de sortie explicite. Si vous avez besoin d'un appel externe, commitez d'abord, puis effectuez l'appel ; s'il échoue, enregistrez un statut « à réessayer ».
Contrôles rapides avant mise en production
Avant de déployer une fonctionnalité qui fait des inserts et updates multi-étapes, rédigez l'« unité de travail » en une phrase. Exemple : « Créer une commande, réserver le stock et enregistrer une intention de paiement. » Si vous ne pouvez pas le dire clairement, vos frontières de transaction sont probablement floues.
Un test de sanity simple est de suivre la connexion. Chaque requête qui doit réussir ou échouer ensemble doit s'exécuter sur la même session/connexion de base. C'est une source fréquente d'erreur dans le code généré par l'IA : un helper utilise une connexion du pool alors qu'un autre en ouvre une nouvelle, si bien que la transaction ne couvre qu'une partie du travail.
Petite checklist avant déploiement :
- Définir l'unité de travail en une phrase et la regrouper dans une seule transaction.
- Vérifier que chaque écriture liée utilise le même objet connexion/session du BEGIN au COMMIT.
- Rendre les chemins d'échec ennuyeux : sur toute erreur, rollback, renvoyer une erreur claire et s'arrêter.
- Ajouter des contraintes qui rendent les reprises sûres (clés uniques « un par utilisateur », clés d'idempotence pour les requêtes).
- Garder les effets secondaires hors de la transaction : envoyer emails, webhooks et uploads seulement après commit (ou les mettre en file).
Puis faites un essai « cassez-le » : forcez une erreur à l'étape 2 sur 3 (par exemple violer une contrainte sur la troisième table). Après la requête échouée, vérifiez la base. Vous devriez voir zéro nouvelle ligne, pas « quelques lignes avec des morceaux manquants ».
Exemple : flow d'inscription qui écrit dans 3 tables
Imaginez une inscription qui doit écrire trois lignes :
users(email, hash du mot de passe)profiles(user_id, display_name)subscriptions(user_id, plan)
Si vous exécutez ces trois écritures séparément, vous pouvez obtenir des données partiellement sauvegardées. Par exemple, la ligne users est créée, mais profiles échoue parce que display_name est trop long ou qu'un champ requis manque. Vous avez maintenant un compte réel qui ne peut pas terminer l'onboarding, et les tentatives ultérieures peuvent échouer car l'email est déjà pris.
À quoi ça ressemble sans transaction
Un pattern courant généré par l'IA : INSERT user, puis INSERT profile, puis INSERT subscription, chacun dans son propre appel. Quand l'étape 2 échoue, l'étape 1 a déjà committé. Il vous faut alors un code de nettoyage (supprimer l'user) et décider quoi faire si ce nettoyage échoue aussi.
Le même flux avec transaction et rollback explicite
Avec des écritures atomiques, vous traitez les trois INSERTs comme une seule unité : soit les trois réussissent, soit aucune n'existe.
BEGIN;
INSERT INTO users (email, password_hash)
VALUES (:email, :hash)
RETURNING id INTO :user_id;
INSERT INTO profiles (user_id, display_name)
VALUES (:user_id, :display_name);
INSERT INTO subscriptions (user_id, plan)
VALUES (:user_id, :plan);
COMMIT;
-- If any statement fails, ROLLBACK;
Deux règles rendent cela fiable :
- N'envoyez le « succès » à l'utilisateur qu'après que le COMMIT a réussi.
- Si quelque chose jette, attrapez l'erreur,
ROLLBACKet renvoyez un message d'erreur clair.
Les actions post-commit comme les emails de bienvenue doivent se produire après le commit (ou être mises en file), afin de ne pas envoyer d'email pour un compte qui n'a jamais été sauvegardé.
Pour tester, ajoutez une erreur volontaire au milieu (par exemple forcer un display_name invalide) et confirmez que la base n'a aucune ligne pour cet email après l'échec de la requête.
Prochaines étapes : corriger les bugs de transaction dans les apps générées par l'IA
Si vous avez hérité d'une app générée par des outils comme Lovable, Bolt, v0, Cursor ou Replit, les données partiellement sauvegardées pointent souvent vers des frontières de transaction manquantes ou incomplètes. Tout semble correct en tests happy-path, puis casse sous trafic réel, timeouts ou une valeur nulle inattendue.
Signes courants que le code manque d'une transaction correcte (ou ne l'utilise qu'à moitié) :
- Un appel API écrit dans plusieurs tables, mais chaque écriture se fait dans des fonctions séparées avec leurs propres appels DB.
- Les erreurs sont catchées et loggées, mais le code continue et renvoie succès.
- Des jobs en background, emails ou paiements interviennent au milieu des écritures en base.
- Une reprise crée des doublons parce qu'aucune idempotence n'est appliquée.
- Vous voyez des lignes orphelines (un profil sans user, une commande sans articles).
Quand vous demandez un audit de code, ne vous contentez pas de « utilisons-nous des transactions ? » Demandez où elles commencent et où elles se terminent, et ce qui se passe en cas d'échec. Un bon audit doit signaler les risques d'intégrité des données (clés étrangères, contraintes, écritures partielles), ainsi que les problèmes souvent associés au code généré par l'IA, comme des flux d'authentification cassés, des secrets exposés et des risques d'injection SQL.
Si vous hésitez entre refactorer ou reconstruire : refactorez quand le modèle de données est sain et que le flux manque surtout d'une frontière de transaction claire et d'une gestion d'erreur propre. Rebuild quand le workflow est embrouillé, les tables ne correspondent pas au produit, ou chaque correctif crée un nouveau cas limite.
Si vous observez activement des données partiellement sauvegardées dans une base de code générée par l'IA, FixMyMess (fixmymess.ai) se concentre sur le diagnostic du code, la réparation de la logique, le renforcement de la sécurité, le refactoring des zones à risque et la mise en production sécurisée. Leur audit de code gratuit est un moyen pratique pour repérer exactement l'endpoint où l'atomicité se brise et quel comportement de rollback est le plus sûr.