Traversée de chemins dans les points de téléchargement : comment la repérer et la corriger
La traversée de chemins dans les endpoints de téléchargement peut exposer des fichiers privés. Apprenez à gérer les noms de fichiers en toute sécurité avec des allowlists, des chemins canoniques et des contrôles d'accès au niveau du stockage.
Pourquoi les endpoints de téléchargement sont faciles à rater
Un endpoint de téléchargement doit faire une chose simple : quand un utilisateur connecté clique sur "Télécharger", le serveur trouve le bon fichier et le renvoie (avec le bon nom et le bon type de contenu).
En pratique, c'est l'étape « trouver le fichier » qui casse tout. L'erreur la plus commune est de traiter l'entrée utilisateur comme si c'était un nom de fichier sûr. Un développeur prend quelque chose comme ?file=invoice.pdf et le concatène à un dossier, en supposant que l'utilisateur ne demandera que ses propres fichiers. Les attaquants ne pensent pas en noms de fichiers. Ils pensent en chemins.
C'est le risque central de la traversée de chemins dans les endpoints de téléchargement : un attaquant essaie de contrôler où le serveur lit, pas seulement quel document il reçoit. Si votre code construit un chemin à partir d'une entrée non fiable, une requête peut sortir du dossier prévu et atteindre des zones sensibles.
Quand cela arrive, l'impact peut être bien plus grave que « quelqu'un télécharge la mauvaise facture ». Un attaquant peut lire des fichiers de configuration qui révèlent des identifiants de base de données ou des clés d'API, le code source (utile pour trouver d'autres failles), des uploads privés, des exports, ou d'autres fichiers serveur qui l'aident à cartographier votre environnement.
Les endpoints de téléchargement sont aussi faciles à rater parce qu'ils paraissent inoffensifs. Ils sont souvent livrés tard, reçoivent moins de relecture, et « fonctionnent bien » dans des tests basiques. Le bug n'apparaît que quand quelqu'un envoie des entrées bizarres, des chemins encodés ou des séparateurs inattendus.
Comment la traversée de chemins se manifeste dans de vraies requêtes
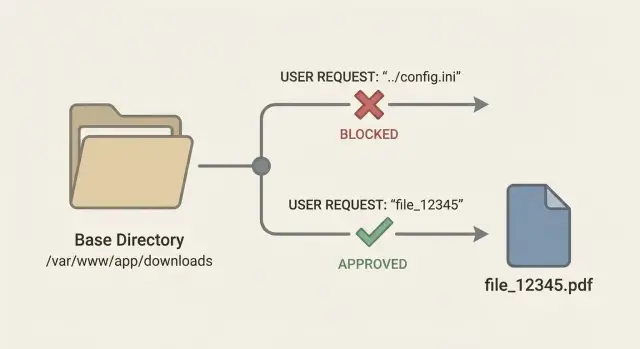
Un endpoint de téléchargement prend généralement quelque chose de la requête et le transforme en chemin de fichier. Le bug apparaît quand le serveur fait confiance à cette entrée. Si le code fait baseDir + "/" + filename, un attaquant peut changer ce que « filename » signifie.
De l'extérieur, une requête normale demande report.pdf. Un attaquant essaie des payloads qui remontent les dossiers ou vont sur un autre lecteur.
Formes communes de payloads :
../secrets.envou../../../../etc/passwd..\\..\\Windows\\System32\\drivers\\etc\\hosts/etc/passwd(chemin absolu sur Linux)C:\\Windows\\win.ini(chemin absolu sur Windows)- Séparateurs mixtes comme
..\\../..\\config.yml
L'encodage complique la détection dans les logs. Beaucoup d'apps décodent les paramètres URL avant de les valider, ce qui veut dire qu'une chaîne bloquée peut réapparaître après décodage. Les attaquants essaient souvent %2e%2e%2f (qui devient ../), ou le double-encodage comme %252e%252e%252f (décodé deux fois par certaines piles). Ils mélangent aussi la casse et les séparateurs, par exemple %2E%2E%5C pour obtenir ..\\.
Un scénario réaliste : votre endpoint est GET /download?file=invoice-123.pdf. Si le handler utilise cette valeur directement, l'attaquant essaie file=..%2f..%2f.env ou file=..\\..\\appsettings.json. Si le fichier existe et que votre processus peut le lire, le serveur peut le renvoyer comme un "download" sans erreur évidente.
Les différences de plateforme comptent assez pour être dangereuses. Linux utilise typiquement / et est sensible à la casse. Windows accepte \\ et tolère souvent /, supporte les lettres de lecteur et a des noms spéciaux comme CON et NUL. Si votre validation ne pense qu'en terme d'un seul style, elle peut manquer l'autre lors du déploiement, ou quand un attaquant teste des contournements.
Façons rapides de repérer un traitement de nom de fichier dangereux
La plupart des traversées commencent par une erreur : laisser la requête décider du chemin que vous lisez sur le disque. Vous pouvez souvent la repérer rapidement en suivant d'où la route de téléchargement prend son entrée et où cette entrée est utilisée.
Les signes à risque ressemblent généralement à :
- Un paramètre de query comme
file,path,nameoudownloadest lu et passé àopen(),readFile(),sendFile()ou à une jointure de chemin. - Le serveur fait confiance à un header (comme
X-File,Content-Disposition, ou mêmeReferer) pour choisir un fichier à servir. - Une « sanitisation » est faite avec des astuces de chaînes comme
replace("../", "")ou en supprimant des points, au lieu d'imposer un dossier de base sûr. - L'endpoint construit un chemin à partir d'une entrée utilisateur et d'un dossier de base, mais ne vérifie jamais où il aboutit après normalisation.
- Les téléchargements proviennent directement du système de fichiers de l'app alors que les fichiers pourraient être stockés ailleurs (object storage, blobs en base, ou un service d'uploads).
Vous pouvez confirmer un soupçon avec quelques tests sûrs en environnement dev. Si un endpoint accepte un nom de fichier, essayez des valeurs qui ne devraient jamais marcher : ../.env, ../../etc/passwd, ..\\..\\windows\\win.ini, ou des variantes URL-encodées comme %2e%2e%2f. Même si la réponse est une erreur, regardez les indices dans les logs (chemins résolus complets, stack traces, ou messages d'erreur qui mentionnent de vrais répertoires).
Un motif « semble sûr mais ne l'est pas » fréquent : le code vérifie que l'entrée se termine par .pdf, puis l'ouvre. Les attaquants peuvent utiliser des encodages, des doubles extensions ou d'autres cas limites pour tromper ces vérifications naïves. Même si d'anciennes techniques basées sur le caractère nul n'appliquent plus à votre stack, la leçon est la même : vérifier le suffixe n'est pas une frontière.
Schéma plus sûr : utiliser des IDs de fichier et une recherche côté serveur
La façon la plus simple d'éviter la traversée de chemins est d'arrêter de prendre des noms de fichiers depuis l'URL. Les noms de fichiers sont compliqués. Ils peuvent contenir des slashes, des backslashes, des séquences .., et des encodages qui changent de sens quand le serveur les joint dans un chemin.
Un schéma plus sûr est d'exposer un ID de fichier stable, par exemple GET /download/7f3a2c, et de conserver l'emplacement réel en backend. L'ID est juste un pointeur. Votre app décide du fichier mappé.
Quand une requête arrive, cherchez le fichier dans une table de base de données (ou tout store de confiance) en utilisant cet ID. Stockez les métadonnées nécessaires pour prendre une décision sûre : qui en est propriétaire, quelle est la clé de stockage, quel type de contenu renvoyer, et si le fichier est toujours valide.
Un flux simple :
- N'acceptez qu'un ID opaque (UUID, token aléatoire, ID de base).
- Récupérez les métadonnées du fichier par ID (propriétaire, org, clé de stockage, content-type).
- Vérifiez que l'utilisateur courant est autorisé à accéder à cet enregistrement.
- Téléchargez via la clé de stockage de confiance, pas via l'entrée utilisateur.
- Définissez les en-têtes de réponse depuis les métadonnées stockées, pas depuis la requête.
Exemple : un client clique sur "Télécharger la facture" et votre UI appelle /download/inv_12345. Votre serveur vérifie que inv_12345 appartient au compte du client, puis lit storage_key=accounts/889/invoices/2025-01.pdf. L'utilisateur ne peut jamais envoyer ../../etc/passwd parce qu'il n'y a pas de paramètre de nom de fichier à attaquer.
Cela facilite aussi les audits. Vous pouvez revoir un seul contrôle d'autorisation autour de la recherche au lieu d'essayer de prouver que chaque nom de fichier possible est sûr.
Allowlists utiles (et ce qu'il faut éviter)
Une allowlist n'aide que si elle limite les téléchargements à des éléments que vous savez déjà sûrs. Pour les téléchargements, cela signifie généralement soit (1) une liste de clés d'objet connues que vous avez générées et stockées, soit (2) une courte liste de types de fichiers que vous supportez vraiment.
L'allowlist la plus sûre est par clé stockée exacte, pas par un nom de fichier fourni par l'utilisateur. L'utilisateur envoie un ID comme fileId=8f3c..., votre serveur cherche l'enregistrement stocké (propriétaire, chemin dans le bucket, clé objet exacte) et sert cela. L'utilisateur n'influence jamais le chemin.
Si vous devez accepter des noms de fichiers, traitez les allowlists d'extensions comme une sauvegarde, pas comme votre contrôle principal. Validez un petit ensemble (par exemple : pdf, csv) et rejetez tout le reste. Ne tentez pas de « nettoyer » les entrées pour les rendre acceptables. Rejeter est plus sûr.
Avant de valider quoi que ce soit, normalisez l'entrée pour empêcher les attaquants de passer les contrôles. Restez ennuyeux et cohérent : trim des espaces, normaliser la casse si cela convient à votre système, et rejeter les séparateurs de chemin (/ et \\) ainsi que les séquences comme ... Faites aussi attention aux noms trompeurs comme invoice.pdf.exe ou report.pdf .
À éviter : les listes noires (elles ratent des variantes), les vérifications endsWith sur l'entrée brute, et les allowlists qui laissent encore passer des parties de répertoires.
Chemins canoniques : imposer une limite par dossier de base
La règle la plus sûre pour les téléchargements est simple : l'utilisateur ne doit jamais pouvoir choisir un chemin de système de fichiers. Si vous devez accepter quelque chose comme un nom de fichier, convertissez-le en chemin canonique puis prouvez qu'il reste dans un dossier approuvé (par exemple downloads_root). Cela ferme l'astuce classique ../.
Canoniser signifie résoudre le vrai chemin que l'OS utilisera. Cela doit écraser . et .., normaliser les séparateurs et (si votre plateforme le permet) résoudre les symlinks. Les symlinks comptent parce qu'un chemin qui semble inoffensif dans votre dossier de téléchargement peut pointer vers l'extérieur.
Un modèle pratique ressemble à :
base = realpath(downloads_root)
requested = realpath(join(downloads_root, user_input))
if requested is null -> error
if not requested starts_with base + separator -> error
serve requested
Avant de canonicaliser, rejetez les entrées manifestement dangereuses. Cela réduit les cas limites et facilite le logging. Rejets courants : chemins absolus (/etc/passwd, C:\\Windows\\...) et entrées qui contiennent des séparateurs de chemin alors que vous attendiez un simple nom de fichier.
Règles qui tiennent bien :
- Acceptez seulement des entrées relatives (pas de leading
/, pas de lettres de lecteur). - Construisez le chemin avec des fonctions de jointure sûres, jamais avec une concaténation de chaînes.
- Canonicalisez en un vrai chemin, puis vérifiez qu'il reste sous
downloads_root. - Si le chemin canonique échoue, traitez-le comme bloqué, pas comme « essaye autre chose ».
Enfin, renvoyez la même erreur générique pour « non trouvé » et « bloqué ». Si vous retournez des messages différents, les attaquants peuvent sonder l'existence des fichiers sur votre serveur, même s'ils ne peuvent pas les télécharger.
Contrôles d'accès au niveau du stockage qui réduisent le périmètre d'impact
Même avec de bonnes vérifications d'entrée, considérez votre endpoint de téléchargement comme à haut risque. Si une traversée passe, le choix du stockage décide si l'attaquant obtient un fichier ou l'ensemble du serveur.
Évitez de servir les fichiers utilisateurs depuis le même disque que votre conteneur applicatif. Quand uploads et code applicatif partagent un filesystem, un bug peut exposer des fichiers de config, des clés et du code source. Gardez les fichiers hors du web root et désactivez le service statique direct pour ce répertoire, afin que seul votre applicatif puisse les lire et les renvoyer.
Pour beaucoup d'équipes, l'object storage est la façon la plus simple de réduire le risque. Plutôt que de lire des chemins locaux, stockez les fichiers comme objets et appliquez l'accès via des permissions par objet ou des accès signés de courte durée. Votre app vérifie l'identité de l'utilisateur, quel ID de fichier il demande et s'il en est propriétaire. Ensuite, elle génère un token de téléchargement limité dans le temps ou fait le proxy du fichier.
Contrôles qui payent vite :
- Gardez les buckets privés par défaut.
- Préférez les accès signés de courte durée plutôt que des URLs publiques permanentes.
- Si vous devez utiliser le disque local, stockez hors du web root.
- Exécutez l'app avec des permissions minimales sur le filesystem (lecture seulement quand nécessaire).
- Séparez environnements et buckets (dev vs prod).
Le logging compte autant que le blocage. Pour chaque requête de téléchargement, journalisez l'ID utilisateur, l'ID de fichier et la décision (autorisé ou bloqué), plus un code raison comme "not owner" ou "expired token". Ce journal aide à détecter les sondages et prouve ce qui s'est passé.
Erreurs courantes et contournements que les attaquants utilisent
La plupart des correctifs échouent parce que le code suppose que l'attaquant enverra un simple ../. Les vraies attaques sont en couches et conçues pour contourner ce que vous avez ajouté.
Une erreur classique est de faire confiance aux règles côté client ou aux champs cachés. Si votre UI ne permet qu'une sélection dans un menu, mais que le serveur accepte toujours un paramètre path, un attaquant peut le modifier dans la requête. Le serveur doit agir comme si l'UI n'existait pas.
Les astuces d'encodage sont un autre contournement fréquent. Les équipes décodent une fois, valident, et plus tard un framework ou un proxy redécodent encore. Cela peut transformer une chaîne sûre en ../ après validation. La solution est la cohérence : normalisez et validez en un seul endroit, et assurez-vous que la valeur utilisée pour ouvrir le fichier est exactement celle que vous avez validée.
Les vérifications d'extension sont faciles à tromper. Bloquer tout sauf .pdf semble sûr, mais les attaquants peuvent encore traverser vers des dossiers sensibles et récupérer des fichiers qui se terminent par .pdf, ou abuser de segments supplémentaires si votre gestion des chemins est bâclée. Si l'objectif est de servir uniquement des factures, le chemin ne devrait pas être contrôlé par l'utilisateur.
Contournements fréquents :
- Chemins cachés ou générés côté client traités comme fiables
- Décodages à différents niveaux (app, framework, proxy)
- Vérifications « Autoriser .pdf seulement » qui ignorent les répertoires et segments
- Symlinks dans un dossier autorisé pointant vers l'extérieur
- Zip Slip : extraction d'une archive contenant des chemins
../qui écrivent en dehors du dossier cible
Les symlinks méritent une attention spéciale. Même si vous joignez un dossier de base avec un nom de fichier, un symlink placé à l'intérieur de ce dossier peut sauter la limite. La solution fiable est la vérification de chemin canonique (après résolution des symlinks) plus des permissions strictes sur le filesystem.
Checklist rapide avant de livrer une fonctionnalité de téléchargement
Les endpoints de téléchargement paraissent simples, mais ce sont des vecteurs courants pour que la traversée atteigne la production. Quelques petits choix (comme accepter un nom de fichier dans l'URL) peuvent transformer un téléchargement d'une facture normale en "lire n'importe quel fichier sur le serveur".
L'approche par défaut la plus sûre
Commencez par décider ce que l'utilisateur est autorisé à demander. Les utilisateurs doivent demander un fichier par un ID que vous contrôlez, pas par un chemin qu'ils peuvent façonner.
- Input : acceptez seulement un ID de fichier (ou un numéro de facture), jamais un chemin brut ou un nom de fichier.
- Lookup : mappez cet ID vers un enregistrement stocké contenant la vraie clé de stockage ou le chemin absolu côté serveur.
- Validation : si vous devez gérer des noms, utilisez une allowlist stricte (extensions attendues, caractères autorisés), puis canonicalisez et confirmez que le résultat reste dans le répertoire de base.
- Authorization : vérifiez la propriété et le rôle avant de lire le fichier, pas après.
- Response : définissez des en-têtes sûrs et évitez de refléter l'entrée utilisateur dans
Content-Dispositionsans la nettoyer.
Réduire le périmètre d'impact avec le stockage et les tests
Un stockage privé par défaut vous sauve quand le code fait une erreur. Gardez les fichiers téléchargeables hors du web root et évitez les buckets publics où deviner un nom suffit.
Un test pratique rapide : essayez des séquences ../, des variantes URL-encodées et des slashes supplémentaires contre votre route de téléchargement. Les tentatives bloquées doivent être journalisées avec assez de détails pour déboguer (ID utilisateur, ID demandé, raison bloquée), mais sans exposer de secrets.
Scénario d'exemple : des téléchargements de factures qui exposent des fichiers serveur
Un fondateur lance rapidement une fonctionnalité de facture : les clients cliquent et l'app appelle /download?filename=invoice-1042.pdf. Le serveur prend filename, construit un chemin, lit le fichier et le renvoie.
Ça marche en test parce que tout le monde demande des fichiers normaux. Le problème est que le serveur fait confiance à l'entrée utilisateur pour choisir un fichier. Un attaquant peut changer le paramètre en ../../.env ou ../../../etc/passwd. Si le code joint des chaînes (ou décode les valeurs URL-encodées puis joint), l'app peut lire des fichiers en dehors du dossier des factures.
Un plan de correction qui garde la fonctionnalité tout en supprimant le risque :
- Passez des noms de fichiers à des IDs (
/download?id=inv_1042) et cherchez le vrai chemin côté serveur. - Appliquez des vérifs d'authentification et de propriété pour que seul le bon client puisse télécharger sa facture.
- Stockez les factures dans un stockage privé (pas un dossier public) et servez-les via des téléchargements contrôlés.
- Ajoutez des allowlists simples : seuls les formats connus (par ex. PDF) sont autorisés, rejetez le reste.
- Journalisez les demandes refusées pour repérer rapidement les tentatives de sondage.
Pour confirmer que c'est corrigé, ne vous contentez pas de « ça a l'air bon » :
- Tentez des payloads
../et vérifiez que vous renvoyez systématiquement une erreur générique. - Regardez les logs pour confirmer que les patterns de traversée sont bloqués et enregistrés.
- Ajoutez un test automatisé qui essaye
../../.envet attend un refus.
Étapes suivantes : auditez vos endpoints et corrigez vite
Commencez par supposer que vous avez plus d'un chemin de "download". Dans beaucoup d'apps, les fichiers sont servis depuis plusieurs endroits : une route de factures, une route d'exports, un aperçu d'attachement, et parfois un helper de debug qui a fait son chemin en production.
Un audit pratique :
- Listez chaque endpoint qui renvoie un fichier (download, export, report, image, attachment, backup).
- Tracez d'où chaque endpoint prend son nom de fichier ou son chemin (query, param route, corps JSON, headers, base de données).
- Notez chaque emplacement de stockage utilisé (répertoires locaux, dossiers temporaires, montages réseau, buckets d'objets).
- Cherchez les constructions de chemin et lectures de fichiers (
join,resolve,open,readFile,sendFile, création d'archives zip). - Vérifiez les contrôles d'accès : qui peut demander quel fichier, et comment ce mapping est appliqué.
Une fois la surface connue, faites une passe de remédiation ciblée. Préférez les IDs de fichiers avec lookup côté serveur (ID -> chemin stocké) plutôt que de laisser l'entrée utilisateur influencer un chemin filesystem. Ajoutez la validation de chemin canonique pour imposer une frontière de répertoire de base unique pour tout accès disque restant, et utilisez une allowlist stricte seulement pour les fichiers véritablement statiques.
Terminez par des tests qui prouvent que la correction tient :
- Les requêtes contenant
../et variantes encodées sont rejetées. - Les chemins absolus (Unix et Windows) sont rejetés.
- Les cas limites de symlinks ne peuvent pas s'échapper du répertoire de base.
- Seuls les fichiers appartenant à l'utilisateur ou à l'organisation courante peuvent être téléchargés.
Si vous avez hérité d'une base de code générée par IA, cela vaut la peine d'avoir un deuxième regard sur les routes qui servent des fichiers. FixMyMess (fixmymess.ai) se concentre sur le diagnostic et la réparation d'apps générées par IA, et un audit rapide peut révéler des problèmes comme des handlers de téléchargement non sûrs, des contrôles d'auth cassés, des secrets exposés et des patterns de stockage risqués avant qu'ils n'atteignent la production.
Questions Fréquentes
Qu'est-ce que la traversée de chemins (path traversal) dans un point de téléchargement ?
Un endpoint de téléchargement devient risqué lorsqu'il transforme une saisie contrôlée par l'utilisateur en un chemin de fichier sur le disque. Si votre code fait quelque chose comme “dossier de base + entrée utilisateur”, un attaquant peut tenter ../ ou des variantes encodées pour s'échapper du répertoire prévu et lire d'autres fichiers accessibles par le processus de l'application.
Que peuvent réellement obtenir les attaquants si la traversée de chemins fonctionne ?
Si un attaquant peut lire des fichiers en dehors du dossier de téléchargement, il peut récupérer des fichiers de config contenant des secrets, le code source de l'application, des uploads privés, des exports ou d'autres fichiers serveur. Le vrai dommage provient souvent d'un accès secondaire : utiliser des identifiants volés pour atteindre la base de données ou des services tiers.
Comment repérer rapidement un traitement de nom de fichier dangereux dans mon code ?
Cherchez toute route qui lit file, path, name ou un paramètre similaire depuis une query, un paramètre de route, le corps JSON ou un header, puis qui passe cette valeur à des API fichier comme open, readFile ou sendFile. Considérez comme suspect toute « sanitisation » fondée sur des manipulations de chaînes (par exemple replace("../", "")), car cela manque généralement d'encodages et de cas limites.
Pourquoi bloquer la chaîne "../" ne suffit-il pas ?
Parce que les attaquants n'envoient généralement pas ../ en clair. Ils utilisent l'encodage d'URL, le double-encodage, des séparateurs mixtes et des chemins spécifiques à la plateforme, de sorte que la séquence dangereuse peut n'apparaître qu'après décodage ou normalisation dans la chaîne de traitement. Bloquer littéralement ../ n'est donc pas fiable.
Quelle est la conception la plus sûre pour un point de téléchargement ?
Le plus sûr est d'exposer un ID opaque dans l'URL et de faire une recherche côté serveur pour obtenir la clé de stockage ou le chemin réel. L'utilisateur demande « fichier 123 », et votre application décide où ce fichier se trouve et si l'utilisateur peut y accéder.
Les allowlists d'extensions comme « seulement .pdf » suffisent-elles ?
Pas de manière fiable. Une vérification du type « doit se terminer par .pdf » n'empêche pas la traversée de chemins et n'évite pas qu'un attaquant télécharge un PDF sensible situé ailleurs sur le serveur. Utilisez les vérifications d'extension comme garde-fou supplémentaire uniquement après avoir supprimé le contrôle utilisateur sur les chemins.
Que signifie en pratique la vérification de « chemin canonique » ?
Résoudre le chemin demandé en un chemin canonique (real path) puis vérifier qu'il reste à l'intérieur d'un répertoire de base approuvé. Si le résultat canonique s'en échappe, bloquez la requête et retournez une erreur générique pour éviter que des attaquants ne sondent l'existence de fichiers.
Pourquoi les différences Windows vs Linux comptent-elles pour la validation ?
Ce sont des formats de chemin différents qui peuvent contourner une validation pensée pour l'autre système. Windows accepte les backslashes, tolère souvent les slashs, supporte les lettres de lecteur et a des noms d'appareils spéciaux, tandis que Linux utilise les slashs et est généralement sensible à la casse. Valider pour un seul style peut laisser des contournements possibles.
Comment le choix du stockage réduit-il les dégâts si un bug passe ?
N'utilisez pas le même emplacement de stockage pour les fichiers téléchargeables par les utilisateurs que pour le code et les secrets de l'application. Préférez un stockage d'objets privé avec des jetons d'accès à courte durée de vie ou un proxy côté serveur, et exécutez votre application avec des permissions minimales pour réduire l'impact d'un bug.
Que dois-je journaliser et surveiller pour les points de téléchargement ?
Enregistrez l'identité utilisateur, la valeur demandée (ID de fichier ou valeur soumise) et si l'accès a été autorisé ou bloqué, avec un code de raison simple, mais n'enregistrez pas de chemins résolus complets ni de contenus sensibles. Si vous héritez d'un code généré par IA et suspectez des routes de fichiers risquées, FixMyMess peut faire un audit rapide et corriger les handlers de téléchargement non sûrs, les contrôles d'auth et l'exposition de secrets.