Valider les variables d'environnement au démarrage avec un schéma d'environnement
Validez les variables d’environnement au démarrage pour détecter tôt les configurations manquantes ou invalides, afficher des erreurs claires et empêcher les mauvais déploiements avant que les utilisateurs ne voient les pannes.
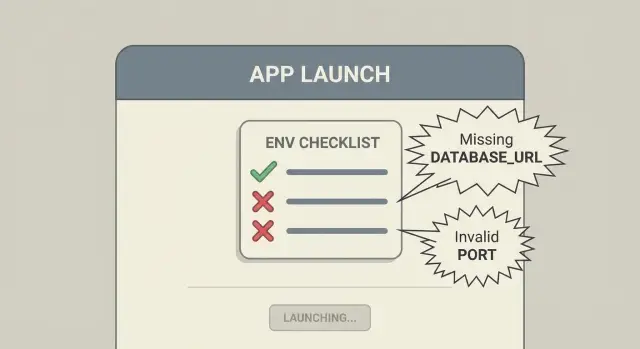
Pourquoi les problèmes de variables d’environnement apparaissent après le déploiement
Les variables d’environnement (env vars) sont des paramètres que votre application lit au démarrage. Elles incluent généralement l’URL de la base de données, des clés d’API, l’URL de base de l’application et l’environnement d’exécution (développement vs production). Les conserver en dehors du code permet de livrer le même build dans des environnements différents avec des paramètres différents.
La plupart des bugs liés aux env vars suivent la même histoire : tout fonctionne en local, puis casse après le déploiement. Sur votre ordinateur, un fichier .env s’est peut‑être constitué pendant des mois, ou votre framework fournit discrètement des valeurs par défaut. En production, vous devez ressaisir ces valeurs dans un tableau de bord d’hébergement ou un système CI. C’est là que surviennent fautes de frappe, clés manquantes et erreurs du type « staging en prod ».
Ces échecs apparaissent aussi tard. Beaucoup d’apps n’utilisent certaines variables que pour des pages spécifiques ou des jobs en arrière‑plan. Une EMAIL_API_KEY manquante peut ne pas échouer avant le premier reset de mot de passe. Une DATABASE_URL erronée peut n’apparaître que sous charge, quand le pool de connexions est sollicité. Ça paraît aléatoire, mais c’est toujours juste de la configuration.
La solution est d’échouer tôt. Quand l’app démarre, validez les env vars dont vous avez besoin, affichez une erreur claire (sans exposer les secrets) et terminez avec un code non nul. Un mauvais déploiement doit échouer immédiatement et bruyamment, pas fonctionner à moitié et casser devant de vrais utilisateurs.
Que valider (et que ne pas valider)
La validation au démarrage n’a pas pour but de prouver que tout fonctionne. Son but est d’attraper une mauvaise configuration tôt, avec des erreurs claires, avant que l’app ne gère du trafic.
Commencez par séparer les variables en deux groupes :
- Requises : l’app ne peut pas fonctionner en sécurité sans elles (URL de base de données, secret d’auth, URL de base).
- Optionnelles : flags de fonctionnalité ou réglages où une valeur par défaut sensée est acceptable.
Ce qui mérite d’être validé à chaque démarrage :
- Présence et valeurs non vides pour les clés requises (considérez les chaînes composées d’espaces et
""comme absentes). - Types : parsing strict pour nombres et booléens, et validation d’URL quand c’est pertinent.
- Valeurs autorisées et bornes : énumérations comme
ENV=production|staging|development, ports 1–65535, timeouts supérieurs à 0. - Règles inter‑champs : si
FEATURE_X=true, exigezFEATURE_X_KEY. - Règles spécifiques à l’environnement : la production demande souvent des exigences plus strictes (URLs HTTPS, secrets plus longs,
DEBUG=false).
Ce qu’il ne faut pas valider au démarrage : tout ce qui transforme le boot en test d’intégration lent et fragile. Ne bloquez pas le démarrage en appelant des APIs externes, en envoyant des emails ou en lançant de lourdes migrations. Concentrez‑vous sur la forme et la sécurité de la configuration.
Aussi, ne validez jamais les secrets en les affichant. Il est acceptable d’indiquer que JWT_SECRET est manquant ou trop court. Ne renvoyez pas la valeur.
Schéma vs vérifications dispersées
Si vous n’avez que quelques env vars, if (!process.env.X) throw peut marcher… jusqu’à ce que ça ne marche plus. Au fil du temps, de nouvelles fonctionnalités ajoutent de nouvelles variables, et les vérifications se retrouvent dispersées dans des routes, jobs et fichiers utilitaires. Cela mène à :
- des noms incohérents (
DB_URLdans un fichier,DATABASE_URLdans un autre) - des vérifications trop tardives (n’exécutées que lorsqu’une route rare est appelée)
- des erreurs vagues (« cannot read property of undefined ») au lieu de « vous avez oublié de définir X »
Une approche basée sur un schéma conserve toutes les règles de config au même endroit : ce qui est requis, ce qui est optionnel, les types attendus, les valeurs autorisées et les règles inter‑champs. Quand la validation échoue, vous obtenez un résumé d’erreurs clair indiquant précisément le paramètre manquant ou invalide.
Exécutez la validation le plus tôt possible : avant de connecter la base de données, avant d’initialiser des SDKs tiers et avant que le serveur n’écoute les requêtes.
Étapes : ajouter une validation au démarrage qui échoue tôt
Considérez la configuration comme une entrée requise pour votre app, pas comme quelque chose que vous découvrez après la première requête échouée.
1) Charger les env vars une fois, en un seul endroit
Choisissez un module unique qui s’exécute au boot (souvent config ou startup). Lisez les env vars là, et transmettez la configuration parsée. Cela évite que différentes parties de l’app interprètent les valeurs différemment.
2) Définir un schéma d’env
Notez ce dont l’app a besoin pour démarrer : clés requises, type attendu et règles de format (URL, email, plage d’entiers). Décidez quelles valeurs peuvent avoir des défauts et lesquelles doivent être fournies.
Une approche simple en code ressemble à ceci (exemple en Node) :
const schema = {
DATABASE_URL: { required: true, format: 'url' },
JWT_SECRET: { required: true, minLen: 32 },
PORT: { required: false, type: 'int', default: 3000 },
};
3) Valider tout et collecter les erreurs
Ne vous arrêtez pas au premier problème. C’est frustrant de corriger une clé manquante, redéployer, puis tomber sur la suivante. Validez tout le schéma et renvoyez un résumé de tous les problèmes.
Maintenez des contrôles stricts :
- requis vs optionnel
- parsing des types (int, bool)
- règles de format (URL, longueur minimale)
- n’appliquez des valeurs par défaut que lorsque c’est clairement sûr
4) Afficher des erreurs claires et actionnables
La sortie d’erreur doit être facile à corriger en quelques minutes :
- quelles clés sont manquantes
- quelles clés sont invalides et quel format était attendu
- dans quel environnement vous pensez tourner
N’affichez pas les valeurs secrètes.
5) Quitter avec un code non nul
Si la validation échoue, arrêtez le processus (par exemple process.exit(1) en Node). Cela force le déploiement à échouer tôt au lieu d’aller en production et de casser l’auth, les paiements ou les jobs en runtime.
Valeurs par défaut, optionnelles et règles spécifiques
Les valeurs par défaut n’aident que si elles ne masquent pas de vrais problèmes. Un défaut sûr garde le comportement prévisible. Un défaut dangereux fait qu’un déploiement cassé semble correct jusqu’à ce que les utilisateurs tombent sur le mauvais chemin.
Par règle, ne définir par défaut que les valeurs non sensibles et avec un fallback évident (comme PORT en dev local). Ne mettez pas de défauts pour les secrets. Pour les secrets, l’absence ou la chaîne vide doit toujours faire échouer le démarrage.
Si une variable est vraiment optionnelle, marquez‑le explicitement dans le schéma et documentez ce qui se passe en son absence.
Un cas fréquent est la chaîne vide. Beaucoup de plateformes permettent d’enregistrer par erreur un secret vide. Pour les secrets, traitez "" comme absent.
Pour les règles spécifiques à l’environnement, vous n’avez généralement pas besoin de schémas séparés. Utilisez un schéma de base et ajoutez quelques règles conditionnelles :
- développement : autoriser des valeurs par défaut locales et intégrations optionnelles
- staging : exiger la plupart des paramètres, accepter des identifiants de test
- production : exiger tous les secrets et formats plus stricts (par exemple forcer HTTPS)
Erreurs utiles sans fuite de secrets
Les contrôles de démarrage n’aident que si on peut agir rapidement. Mais les erreurs de config sont aussi une cause fréquente de fuite de secrets dans les logs, captures d’écran et tickets de support.
Les bons messages d’erreur incluent le nom de la variable, ce qui ne va pas (manquante, vide, mauvais type, format invalide) et un indice sûr sur ce qui est attendu (par exemple « doit commencer par postgres:// »). Si vous devez montrer « ce qui a été reçu », censurez‑le.
Considérez par défaut comme sensibles les noms contenant SECRET, TOKEN, KEY, PASSWORD, PRIVATE, SESSION ou COOKIE.
Surveillez aussi les règles de bundling côté client. Certains frameworks exposent des env vars au navigateur selon un préfixe. Ajoutez une règle interdisant que des noms ayant l’air secrets soient inclus dans la configuration exposée au client.
Erreurs courantes qui provoquent encore des échecs en runtime
La plupart des bugs runtime surviennent parce que la validation existe, mais elle s’exécute trop tard, vérifie trop peu ou rapporte de façon vague.
Faites attention à ces patterns :
- validation après le démarrage (le trafic peut atteindre du code à moitié initialisé)
- validation limitée à « ce qui a cassé la dernière fois » au lieu de l’ensemble requis
- gestion des types laxiste (traiter toute chaîne non vide comme
true, autoriserNaN) - erreurs génériques comme « Config invalid » sans détail champ par champ
Gardez le schéma à jour chaque fois que vous ajoutez une fonctionnalité. Les nouvelles fonctions ajoutent presque toujours de la configuration.
Vérifications rapides avant de livrer
La configuration est une fonctionnalité que vous pouvez tester. Avant de déployer :
- retirez une variable requise et confirmez que l’erreur nomme la clé exacte
- fournissez une valeur invalide (comme
"abc"pour un nombre) et confirmez que le message explique le type ou le format attendu - confirmez que les secrets sont censurés dans les logs, même en cas d’échec
- confirmez que la validation s’exécute avant les migrations, workers, files d’attente et appels réseau
- confirmez que le processus sort avec un code non nul pour que votre plateforme marque le déploiement comme échoué
Exemple : détecter un mauvais déploiement avant que les utilisateurs ne le voient
Une panne courante en production est une DATABASE_URL manquante. Sans contrôles au démarrage, le serveur démarre et échoue seulement quand la première requête tente de lire ou écrire des données. Les logs montrent une pile d’erreurs profonde du client de base de données, et vous devinez si c’est réseau, permissions ou requêtes.
Avec un schéma d’env en place, l’app refuse de démarrer et affiche une erreur simple :
- Variable d’environnement requise manquante :
DATABASE_URL - Format attendu : URL (par exemple
postgres://...)
Corrigez la valeur, redéployez, terminé. Les utilisateurs n’accèdent jamais à une app cassée.
La même idée s’applique aux URLs de callback d’auth : si AUTH_CALLBACK_URL est manquante, vide ou pas en HTTPS en production, il vaut mieux faire échouer le démarrage que laisser les utilisateurs découvrir une boucle de connexion plus tard.
Étapes suivantes : garder la configuration fiable à mesure que l’app grandit
Une fois que vous avez ajouté un schéma d’env, intégrez‑le dans le démarrage standard de l’app dans tous les environnements : dev local, staging, builds de preview et workers en arrière‑plan. La cohérence est importante. Si une variable est requise, l’app doit refuser de démarrer partout.
Un petit document de passation aide aussi : quelles variables existent, où elles sont définies (tableau de bord d’hébergement, secrets CI, config du conteneur) et comment les faire tourner.
Si vous avez hérité d’un prototype généré par IA, la gestion des env vars est souvent l’un des gains de stabilité les plus rapides, car la configuration a tendance à être dispersée et incohérente. FixMyMess (fixmymess.ai) aide les équipes à transformer des apps construites par IA en logiciels prêts pour la production, et un diagnostic rapide du code peut repérer la validation de config manquante et la gestion risquée des secrets avant que cela n’entraîne une journée de déploiement chaotique.
Questions Fréquentes
Pourquoi mon application marche en local mais plante juste après le déploiement ?
Parce que votre ordinateur portable a souvent un fichier .env qui s’est accumulé pendant des mois et des comportements par défaut fournis par le framework. En production, vous ressaisissez généralement les valeurs dans un tableau de bord ou un système CI : c’est là que les clés manquantes, les fautes de frappe et les mauvaises valeurs d’environnement apparaissent après le déploiement.
Que signifie réellement « échouer tôt » pour la validation des variables d’environnement ?
Valider les variables d’environnement requises le plus tôt possible pendant le démarrage, afficher une erreur claire qui nomme les clés manquantes ou invalides (sans afficher les valeurs secrètes), et quitter avec un code non nul. Ainsi, un mauvais déploiement échoue immédiatement plutôt que de fonctionner à moitié jusqu’à ce qu’un utilisateur rencontre l’erreur.
Quelles vérifications de variables d’environnement valent la peine d’être faites au démarrage ?
Validez la forme et la sécurité de la configuration : présence requise, valeurs non vides, parsing des types (int/bool), format basique d’URL, et valeurs autorisées comme production|staging|development. Évitez les vérifications lentes comme appeler des APIs tierces ou lancer de lourdes migrations au démarrage.
Quand dois-je utiliser des valeurs par défaut pour les variables d’environnement, et quand les éviter ?
Les valeurs par défaut conviennent pour des paramètres non sensibles ayant un fallback évident, comme PORT en développement local. N’appliquez pas de valeur par défaut pour des éléments sensibles (secrets, tokens, mots de passe) car cela peut masquer un déploiement cassé et créer un comportement non sûr.
Comment gérer les chaînes vides dans les variables d’environnement ?
Traitez "" et les chaînes ne contenant que des espaces comme absentes pour les variables requises, surtout pour les secrets. Beaucoup d’outils d’hébergement permettent d’enregistrer par erreur une valeur vide, ce qui semble « défini » mais est inutilisable.
Ai-je besoin d’un schéma d’environnement séparé pour développement, staging et production ?
Garder un seul schéma pour tous les environnements, puis ajouter des règles conditionnelles pour la production. Les règles courantes en production : exiger des URL HTTPS, imposer des longueurs minimales pour les secrets, et s’assurer que les flags de debug sont désactivés.
Quel est l’intérêt d’un schéma plutôt que des vérifications dispersées `if (!process.env.X)` ?
Regrouper toutes les règles au même endroit (un module config ou de démarrage), valider une fois, et distribuer la configuration parsée. Cela évite les noms incohérents comme DB_URL vs DATABASE_URL et les vérifications qui ne s’exécutent que lorsqu’une route rare est appelée.
Comment montrer des erreurs utiles sans divulguer de secrets dans les logs ?
N’affichez jamais les valeurs secrètes dans les erreurs ou les logs, même en cas d’échec. Indiquez le nom de la variable et ce qui ne va pas ; si vous devez montrer ce qui a été reçu, masque-le pour que captures d’écran ou tickets de support ne fassent pas fuiter des identifiants.
Où la validation des variables d’environnement doit-elle s’exécuter dans la séquence de démarrage ?
Faites la validation avant que le serveur n’écoute les requêtes, avant d’ouvrir les connexions à la base de données et avant d’initialiser les SDKs tiers ou les workers. Si vous validez après le démarrage, le trafic peut toucher du code à moitié initialisé et échouer de façon confuse.
FixMyMess peut-il aider si mon prototype généré par IA plante souvent à cause de problèmes de configuration ?
Si vous héritez d’une application générée par IA, les variables d’environnement sont souvent incohérentes entre routes, jobs et étapes de build, ce qui cause des échecs runtime imprévisibles. FixMyMess peut réaliser un audit gratuit du code pour repérer la validation manquante, les secrets exposés et les hypothèses de déploiement dangereuses, puis corriger ou reconstruire la configuration pour éviter les incidents le jour du déploiement.