Checks de readiness et liveness qui détectent de vraies pannes
Apprenez à concevoir des checks de readiness et liveness qui valident votre base de données, votre queue et vos API critiques pour que les pannes apparaissent avant que les utilisateurs ne les remarquent.
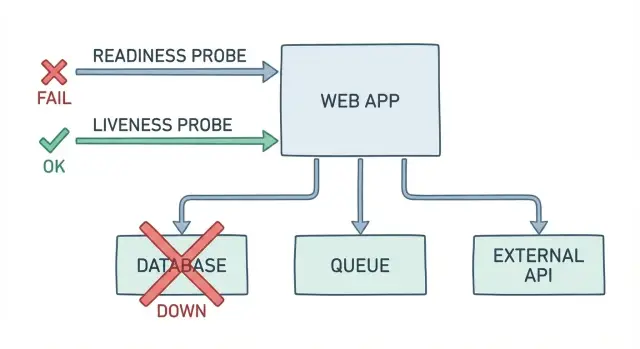
Pourquoi des checks « OK » laissent encore les utilisateurs bloqués
Un endpoint basique /health répond généralement à une question : le processus tourne-t-il ? Ce n’est pas la même chose que : un utilisateur peut-il se connecter, payer ou finir son travail maintenant. Quand votre check renvoie « OK » alors que l’app échoue sur son vrai métier, vous avez des faux-positifs et un incident plus lent et plus confus.
Voici comment ça se manifeste en vrai : le pod est up, le CPU semble normal et l’endpoint de santé dit « OK ». Mais la connexion échoue parce que la base de données est verrouillée lors d’une migration. Les paiements échouent suite à une rotation de secret et des identifiants expirés. Les jobs en arrière-plan s’entassent parce que la connexion à la queue est bloquée, et les confirmations de commande ne partent jamais.
Ces checks faux-verts coûtent du temps et de la confiance. L’équipe on-call court après un signal « tout va bien ». Le support est alerté avant le monitoring. Les utilisateurs réessaient, abandonnent et se souviennent du mauvais jour.
Les probes de readiness et liveness doivent refléter ce dont les utilisateurs ont besoin pour réussir. Une bonne sonde n’est pas un « OK » de façade. C’est un petit test rapide du chemin critique.
Une sonde consciente des dépendances devrait répondre à des questions comme :
- Pouvons-nous nous connecter à la base de données et exécuter une petite requête ?
- Peut-on s’authentifier auprès de la queue et publier un message (ou au moins vérifier que la connexion est vivante) ?
- Les identifiants requis sont-ils valides et non expirés ?
- Les quelques services externes dont nous dépendons vraiment sont-ils accessibles ?
Si vous avez hérité d’une app générée par IA qui « tourne » mais casse en production (souvent autour de l’auth, des secrets et des queues), de meilleures probes empêchent de mauvais déploiements de nuire silencieusement aux utilisateurs.
Readiness vs liveness en clair
La readiness répond : cette instance peut-elle recevoir du trafic en toute sécurité maintenant ? Si la réponse est non, elle doit rester en fonctionnement mais être retirée de la rotation pour que les utilisateurs ne soient pas dirigés vers une copie cassée.
La liveness répond : le processus est-il vivant et progresse-t-il, ou est-il bloqué d’une façon qu’un redémarrage corrigerait ? Si la réponse est non, la plateforme devrait le redémarrer.
Un exemple simple de readiness : votre app démarre, mais la base de données est down ou les identifiants sont erronés. Le processus tourne, pourtant toute connexion et chargement échouent. Une bonne probe de readiness échoue ici pour que les requêtes cessent d’atteindre cette instance jusqu’à rétablissement de la base.
Un exemple simple de liveness : un bug provoque un deadlock et l’app cesse de répondre même si le conteneur est toujours running. La readiness peut aussi échouer, mais cela ne résout pas la cause racine. Une probe de liveness détecte que l’app ne progresse plus et déclenche un redémarrage pour récupérer.
Une façon simple de s’en souvenir :
- Readiness protège les utilisateurs des instances défaillantes.
- Liveness aide le système à récupérer des instances bloquées.
Ces checks ne sont pas des tests end-to-end complets. Ils ne doivent pas rejouer des parcours utilisateurs complets ni appeler toutes les dépendances à chaque probe. Gardez-les petits et concentrés sur les quelques choses qui doivent être vraies pour que l’app serve le trafic en toute sécurité.
Commencez par ce qui doit fonctionner pour les utilisateurs
Un check de santé n’est utile que s’il correspond à ce que font réellement les utilisateurs. Avant d’écrire des probes de readiness et liveness, notez les quelques actions qui définissent « l’application fonctionne » pour votre produit. Si ces actions échouent, les utilisateurs sont cassés même si votre endpoint renvoie 200.
Gardez la liste petite et réelle : se connecter et charger le tableau de bord, créer un projet ou une commande, uploader un fichier et le voir apparaître, déclencher un job ou envoyer un message, finaliser un paiement (si vous en avez).
Mappez ensuite chaque action à ce dont elle a besoin. « Créer un projet » signifie généralement que la base est écrivable et que les migrations sont appliquées. « Uploader un fichier » peut nécessiter un stockage d’objets plus un worker en arrière-plan pour le traiter. « Envoyer un message » peut dépendre d’une queue accessible et de consommateurs en marche.
À partir de cette cartographie, choisissez les vérifications minimales qui représentent le mieux « les utilisateurs peuvent compléter le parcours ». Un ping DB n’est pas suffisant si les écritures sont bloquées. Une connexion à la queue n’est pas suffisante si la publication échoue. Visez une ou deux vérifications par chemin critique, en utilisant les dépendances qui cassent le plus souvent l’expérience.
Enfin, décidez ce que signifie « dégradé mais utilisable ». Les utilisateurs peuvent-ils naviguer mais pas créer ? Peuvent-ils se connecter mais les uploads sont temporairement désactivés ? Prenez cette décision volontairement, car elle contrôle le comportement de readiness (l’app doit-elle recevoir du trafic ou non).
Un scénario simple : votre app charge, mais les nouveaux projets n’apparaissent jamais parce que le worker ne peut pas mettre en file les jobs. Votre endpoint de santé UI affiche toujours « OK ». Une readiness qui inclut un enqueue léger (ou un check de publish) détecte la défaillance ressentie par les utilisateurs.
Que vérifier : DB, queue et vos dépendances critiques
Un endpoint de santé utile doit répondre à une question : si vous envoyez une vraie requête utilisateur maintenant, est-ce que ça marche ? Cela signifie que la readiness (et toute sonde de dépendance que vous ajoutez) doit toucher les mêmes dépendances que votre app utilise pour faire son travail, pas seulement renvoyer « OK » parce que le serveur web tourne.
Base de données
Commencez simple et sûr. Vérifiez que vous pouvez vous connecter avec les mêmes identifiants que l’app et exécuter une petite requête en lecture seule comme SELECT 1. Cela détecte un réseau cassé, des mots de passe expirés et des chaînes de connexion mal configurées. Gardez la vérification rapide, ne verrouillez pas de tables et n’exécutez pas de migrations depuis une sonde.
Queue et travail en arrière-plan
Si votre app dépend de jobs en arrière-plan, vérifier seulement l’API ne suffit pas. Votre sonde devrait confirmer que vous pouvez publier un message de test (ou au moins vous authentifier auprès du broker) et que les workers consomment réellement. Surveillez aussi un backlog qui croît continuellement, car une queue peut être « up » alors que le travail est effectivement bloqué.
Un point de départ pratique :
- Connexion DB + une requête légère
- Publication sur la queue (et idéalement un signal de consommation par un worker)
- Un appel interne critique que vous ne pouvez pas faire sans
- Un appel API externe dont dépend votre flux principal
- Sanity de config : variables d’environnement requises présentes et secrets correctement branchés
Les APIs externes méritent un soin particulier. Vous ne testez pas tout l’internet, mais vous devez savoir si les identifiants sont invalides, le DNS cassé ou les réponses ralenties au point d’impacter l’expérience.
Un exemple concret : une requête d’inscription écrit une ligne user, puis met en file un job « envoyer email de bienvenue ». Si le check DB passe mais que la queue n’accepte pas les messages, les utilisateurs peuvent « s’inscrire » sans jamais recevoir d’email de vérification. Une readiness qui inclut la queue bloque le trafic jusqu’à ce que le chemin soit opérationnel, au lieu de laisser des échecs silencieux.
Pas-à-pas : construire une readiness qui bloque le trafic
Une readiness doit répondre : cette instance peut-elle gérer de vraies requêtes utilisateur maintenant ? Si non, elle doit échouer pour retenir le nouveau trafic.
1) Prouvez le minimum important
Commencez par la plus petite opération de base de données qui prouve tout de même que l’app peut fonctionner. Une connexion TCP ne suffit pas. Préférez une petite requête qui utilise les mêmes identifiants, schéma et chemin réseau que l’app.
Un pattern courant est un endpoint comme /ready qui exécute une requête rapide et vérifie une ou deux dépendances critiques.
- Exécutez une requête DB légère (par exemple
SELECT 1) en utilisant la connexion normale de l’app. - Définissez des timeouts stricts (centaines de millisecondes, pas des secondes) pour que les défaillances apparaissent vite.
- Si la DB est inaccessible ou timeout, renvoyez « not ready » pour que le load balancer écarte le trafic.
- Incluez une raison lisible dans le corps de la réponse, mais n’exposez jamais de secrets, chaînes de connexion ou dumps d’erreur complets.
- Ajoutez une courte période de grâce au démarrage pour éviter le flapping pendant le warm-up.
2) Rendez les défaillances évidentes (mais sûres)
Renvoyez un code d’état clair (comme 503) et un payload petit et sûr :
{ "ready": false, "reason": "db_timeout" }
Le champ reason fait gagner du temps en incident car il pointe vers la dépendance en échec sans exposer de données privées.
3) Branchez-le pour qu’il bloque vraiment le trafic
Dans Kubernetes, c’est la readiness qui contrôle si un pod reçoit du trafic. Assurez-vous que votre app ne rapporte ready qu’après avoir réussi cette vraie opération.
Pas-à-pas : construire une liveness qui déclenche des redémarrages
La liveness répond : le processus progresse-t-il ou est-il bloqué ? Si bloqué, un redémarrage est souvent le moyen le plus rapide de revenir à la normale.
- Choisissez un « signal de progression » qui prouve que l’app n’est pas wedgée. Les bons signaux sont locaux et simples : un timestamp de watchdog mis à jour par la boucle principale, ou « temps depuis la dernière requête terminée ».
- Gardez-le léger et local. Une liveness ne doit pas appeler la DB, la queue ou des services externes. Les aléas réseau provoqueraient des redémarrages inutiles.
- Ajoutez des seuils pour éviter les boucles de redémarrage. Probez régulièrement, mais exigez plusieurs échecs avant de déclarer le conteneur mort. Ajoutez aussi une période de grâce au démarrage.
- Loggez la raison juste avant d’échouer. Écrivez une ligne claire avec le signal bloqué et quelques compteurs clés (tâches en attente, threads occupés, mémoire).
- Testez sous vraie charge, pas seulement en dev. Simulez haute charge, appels downstream lents et gros payloads. Beaucoup d’apps paraissent saines jusqu’à ce que les thread pools se remplissent et que le processus cesse de répondre.
Exemple : un service accepte des requêtes HTTP mais tous les threads workers sont bloqués sur un lock. Les requêtes pendent, les utilisateurs voient une roue, et la readiness peut rester verte. Une liveness surveillant le « temps depuis la dernière requête terminée » peut détecter le gel et déclencher un redémarrage.
Bien faits, readiness et liveness fonctionnent ensemble : readiness protège les utilisateurs des dépendances cassées, la liveness vous sauve des codes bloqués.
Timeouts, retries et thresholds qui se comportent bien en production
Les probes de santé doivent être rapides et ennuyeuses. Si une probe prend trop de temps, les requêtes s’entassent, votre app fait un travail supplémentaire, et la probe elle-même peut devenir la cause de la panne. Pour la plupart des apps, visez un timeout court (souvent 1–2s) et une quantité de travail fixe et limitée par probe.
Évitez les retries lourds dans la probe. Les retries peuvent masquer de vraies défaillances et ajouter de la charge quand les systèmes sont déjà en difficulté. Si la base timeoute, une probe qui retry trois fois peut retomber parfois sur succès, mais elle frappe la DB plus fort au pire moment.
Seuils simples pour séparer les blips des pannes
Plutôt que de retryer dans la probe, utilisez des seuils simples au niveau de l’orchestrateur. Dans Kubernetes, cela signifie généralement permettre quelques échecs avant d’agir.
Un point de départ pratique :
- Readiness timeout : 1–2s, failureThreshold : 2–3
- Liveness timeout : 1–2s, failureThreshold : 3–5
- periodSeconds : 5–10 (ne probez pas chaque seconde sauf si nécessaire)
- successThreshold : 1
Pensez à cela comme un petit budget d’échecs : une réponse lente unique ne doit pas provoquer le chaos, mais des échecs répétés doivent alerter.
Non-ready vs dead : choisissez l’action la moins perturbatrice
Readiness et liveness ne sont pas le même levier. Si une dépendance est down, le mouvement le plus sûr est souvent de marquer l’app non-ready pour qu’elle cesse de recevoir du trafic. Redémarrer ne réglera souvent pas une DB ou une queue cassée, et peut ralentir la reprise.
Utilisez readiness pour dire : « je ne peux pas servir correctement les utilisateurs maintenant ». Utilisez liveness pour dire : « je suis bloqué et j’ai besoin d’un redémarrage ».
Erreurs communes qui créent des faux-verts (ou du flapping constant)
La plupart des health checks échouent pour deux raisons : ils sont trop superficiels (tout est « OK » alors que les utilisateurs ne peuvent pas se connecter) ou trop profonds (ils échouent sur des aléas normaux et déclenchent des redémarrages).
Un faux-vert classique est une sonde qui prouve seulement que le serveur web est up. Si votre app accepte HTTP mais ne peut pas lire depuis la DB, publier dans la queue ou charger la config essentielle, les utilisateurs restent cassés.
Les erreurs qui reviennent le plus souvent :
- Utiliser un flux end-to-end comme liveness (login + DB + queue + API externe). Quand une dépendance flanche, l’orchestrateur tue un process sain et cause une perte de service auto-infligée.
- Faire dépendre la readiness de tiers instables. Si une API de paiement ou d’email est lente 30s, vous pouvez osciller entre ready et not-ready et perdre du trafic. Préférez des signaux adoucis plutôt que d’échouer systématiquement.
- Logger ou renvoyer des dumps d’erreur bruts. Les endpoints de santé sont tentants pour imprimer des stack traces, chaînes de connexion et tokens. Gardez les réponses minimales et épurées.
- Dire « ready » avant que l’app soit utilisable. Coupables fréquents : migrations encore en cours, caches non chauds, workers non connectés ou consommateurs de queue en panne.
- Ignorer timeouts et thresholds. Une probe sans timeouts serrés peut s’accumuler de requêtes. Une probe sans seuils d’échec peut osciller constamment.
Gardez la liveness peu profonde (le processus est-il gelé ?) et la readiness honnête (peut-elle servir les utilisateurs en sécurité ?).
Rendre les défaillances faciles à voir et à traiter
Une probe qui échoue silencieusement est presque aussi mauvaise qu’une probe qui renvoie toujours OK. Quand readiness et liveness échouent, vous voulez qu’un opérateur sache ce qui a cassé, l’ampleur et ce que le système fait pour y remédier.
Loggez les échecs de probe avec un code d’erreur court et stable. Gardez un petit ensemble de codes cohérents pour qu’ils soient traçables et visualisables. Incluez une phrase de contexte et évitez de déverser des stacks à chaque échec.
Une sortie de probe utile inclut généralement un code stable (comme DB_CONN_TIMEOUT ou QUEUE_AUTH_FAILED), le nom de la dépendance et l’opération qui a échoué (connect, query, publish, consume), et un statut basique comme ready ou not-ready. Si vous utilisez degraded, précisez ce que cela signifie et quel trafic reste sûr.
Vérifiez que « not-ready » a des conséquences. Testez en provoquant une vraie défaillance de dépendance (par ex. révoquer les identifiants de la queue en staging). Confirmez que l’instance est retirée du trafic et cesse de recevoir des requêtes. Si les utilisateurs la touchent encore, votre signal de readiness n’est pas connecté au routage comme vous le pensez.
Soyez aussi strict sur les redémarrages. Une liveness qui échoue doit déclencher des redémarrages seulement quand le process est vraiment wedgé. Si un hic DB temporaire cause des redémarrages répétés, vous avez transformé un problème de dépendance en panne.
Exemple concret : les connexions échouent parce que les migrations n’ont pas été exécutées. L’app renvoie HTTP 200 sur /health, mais chaque login renvoie une erreur. Une meilleure readiness rapporterait not-ready avec MIGRATION_PENDING, gardant les instances cassées hors du trafic.
Checklist rapide avant de déployer des health checks
Avant de vous reposer sur readiness et liveness en production, assurez-vous que vos probes échouent pour les mêmes raisons que les vrais utilisateurs. Si une dépendance est down, la probe doit le signaler vite et clairement.
La readiness doit bloquer le trafic quand des dépendances centrales se cassent : DB inaccessible, identifiants erronés ou une simple requête qui timeoute. Les checks de queue doivent refléter le flux réel de messages, pas seulement « puis-je atteindre le serveur ». Chaque probe nécessite un timeout ferme. Les réponses en cas d’échec doivent être sûres à exposer (codes et raisons courtes, pas de stack traces ni de secrets). Et les déploiements ne doivent pas flapper : ajoutez une période de grâce au démarrage pour les travaux de warm-up.
Un test en staging qui vaut le coup
Simulez une vraie panne : bloquez l’accès à la DB pendant quelques minutes, ou arrêtez vos workers de queue. Confirmez que la readiness devient rouge rapidement, que le trafic s’arrête et que l’app récupère proprement quand la dépendance revient.
Exemple : l’app semble ok, mais la queue est cassée
Une panne fréquente : les utilisateurs peuvent passer commande, le checkout renvoie 200 et votre endpoint « health » répond « OK ». Mais les clients ne reçoivent jamais de confirmations et les tickets support s’accumulent.
Que s’est-il passé ? Le web app sert encore des requêtes, mais le chemin message queue est cassé. Peut-être que l’app ne peut pas publier à cause d’identifiants erronés. Peut-être que la queue est up mais tellement backlogée que les messages ne seront traités que dans des heures. De l’extérieur, l’app semble saine.
C’est là que readiness et liveness comptent. L’ancienne probe ne prouvait qu’une chose : le serveur web peut répondre. Une meilleure readiness ressemble plus à une sonde de dépendance et vérifie ce qui doit marcher pour les vrais utilisateurs.
Une readiness simple pour ce cas :
- Tenter une publication légère sur la queue (ou un appel API vérifiant les permissions) avec un court timeout.
- Optionnellement vérifier le retard de la queue (par ex. âge du message le plus ancien) et échouer la readiness si un seuil est franchi.
- Renvoyer « not ready » pour que le trafic cesse d’aller vers cette instance jusqu’à ce que le chemin queue soit rétabli.
La liveness est différente. Si le worker de queue est bloqué (deadlock, fuite mémoire, boucle de message empoisonné), vous voulez souvent redémarrer le process worker tandis que le process web peut rester up. Cela implique souvent des probes séparées : gardez le conteneur web vivant et laissez le conteneur worker échouer la liveness quand il cesse de progresser.
Traitez le suivi comme une investigation, pas des suppositions. Loggez l’échec exact (publish timeout, auth error, backlog spike), puis isolez la cause : service de queue, identifiants, politique réseau ou code consommateur.
Prochaines étapes : améliorer les probes, puis corriger les causes racines
Si vos endpoints de santé existent déjà, l’étape suivante est de les rendre utiles. De bons checks de readiness et liveness ne se contentent pas de dire que le process tourne. Ils détectent de vraies ruptures tôt et empêchent des pods cassés de servir des utilisateurs.
Notez ce qui doit marcher pour qu’un utilisateur complète l’action principale de votre app (login, paiement, upload, envoi de message). Choisissez les trois dépendances principales qui doivent être saines pour que l’action réussisse. Pour chacune, ajoutez une seule vérification qui prouve que l’app peut réellement l’utiliser, pas seulement atteindre un hostname.
Ensuite, réparez ce que les probes révèlent. Si la readiness échoue parce que les connexions DB fuient, la probe fait son travail. Le travail consiste à fermer les connexions, définir des limites de pool, gérer les timeouts et échouer avec des erreurs claires. Si les checks de queue échouent parce que les messages s’accumulent, inspectez les consommateurs, la logique de retry et les dead-letter handling.
Si vous avez hérité d’un prototype généré par IA qui paraît « vert » dans les checks basiques mais casse sous charge réelle, un audit ciblé aide. FixMyMess (fixmymess.ai) se spécialise dans la prise en charge d’apps générées par IA et la réparation de problèmes comme l’auth cassée, les secrets exposés et les jobs background peu fiables, en commençant souvent par un audit de code gratuit pour mettre en lumière ce qui casse réellement en production.
Questions Fréquentes
Why does my /health endpoint say OK when users can’t log in or pay?
Une endpoint basique /health prouve généralement seulement que le processus web peut répondre. Les utilisateurs peuvent pourtant être bloqués si la base de données est verrouillée, les identifiants ont expiré, des migrations sont en attente ou la queue est bloquée. Un contrôle utile doit refléter si l’application peut accomplir le travail minimum dont les utilisateurs dépendent.
What’s the simplest way to explain readiness vs liveness?
La readiness signifie « cet instance doit-elle recevoir du trafic maintenant ? » : elle doit échouer quand des dépendances clés nécessaires aux requêtes réelles ne sont pas utilisables. La liveness signifie « le processus est-il bloqué d’une façon qu’un redémarrage pourrait résoudre ? » : elle ne doit échouer que lorsque l’application cesse de progresser, pas quand une dépendance a un incident court.
What should a readiness check do for the database?
Commencez par une toute petite opération utilisant le même chemin que l’app, par exemple exécuter SELECT 1 via la connexion normale avec un timeout strict. Cela détecte les problèmes réseau, les mauvais identifiants et beaucoup d’incidents DB. Si votre flux principal nécessite des écritures, envisagez un signal sûr lié aux écritures (par ex. vérifier que les migrations sont appliquées) plutôt que seulement une lecture.
How do I include the queue in readiness without making probes heavy?
Si vous dépendez de jobs en arrière-plan, la probe de readiness doit vérifier que l’app peut publier dans la queue (ou au moins effectuer une vérification de permission/handshake) avec un court timeout. C’est souvent le point où tout « paraît up » mais les confirmations ou emails échouent silencieusement. Gardez la vérification légère pour ne pas ajouter de charge pendant un incident.
Should my liveness check call the database or external APIs?
Évitez d’appeler des services externes depuis la liveness : un hic chez un tiers peut déclencher des boucles de redémarrage et aggraver la panne. La liveness doit être locale : horodatage d’un watchdog mis à jour par la boucle principale, heartbeat de la boucle d’événements ou « temps depuis la dernière requête terminée » suffisent généralement. Utilisez la readiness pour refléter la santé des dépendances externes.
How should I set timeouts and retries for readiness and liveness probes?
Utilisez des timeouts serrés pour que les probes échouent vite, puis laissez l’orchestrateur gérer les petits incidents avec des thresholds de défaillance. Cela réduit le trafic de probe pendant les pannes partielles et évite de masquer de vrais problèmes avec des retry internes. Si une dépendance est lente, il vaut mieux devenir non-ready rapidement plutôt que garder des pods partiellement fonctionnels en rotation.
How do I stop readiness checks from flapping when a third-party API is unstable?
Un choix fréquent qui cause des oscillations est de dépendre d’un tiers instable dans la readiness. Préférez des signaux plus souples (succès récent mis en cache, état d’un circuit breaker) au lieu d’échouer systématiquement. Également, évitez que les probes effectuent trop de travail : elles ne doivent pas devenir des mini-tests de charge.
What should my health endpoints return when something is wrong?
Retournez un code d’état clair (souvent 503) et une courte chaîne de raison stable comme db_timeout ou queue_auth_failed. Enregistrez le même code dans les logs pendant la fenêtre de défaillance pour qu’il soit searchable sans spammer. N’incluez jamais de stack traces, tokens, chaînes de connexion ou dumps d’exception bruts dans les réponses de probe.
Can my app be “degraded but usable,” and how should readiness handle that?
Oui, si c’est le bon compromis pour votre produit. Vous pouvez rester ready pour la navigation en lecture seule tout en désactivant les actions de création, mais l’application doit appliquer les mêmes règles afin que les utilisateurs n’accèdent pas à des chemins cassés. Si vous ne pouvez pas séparer de manière fiable « sûr » et « non sûr », échouez la readiness et stoppez le trafic jusqu’à réparation.
My app was generated by an AI tool and breaks in production—can you help?
Les générateurs d’apps AI souvent « tournent » mais échouent sur l’auth, les secrets, les migrations et les jobs background, ce que les checks basiques ne captent pas. FixMyMess se concentre sur le diagnostic et la réparation de ces pannes en production, y compris le durcissement des probes pour que des déploiements cassés ne nuisent pas silencieusement aux utilisateurs. Si vous ne savez pas par où commencer, un audit de code gratuit peut rapidement révéler les points de défaillance.