Contrôles synthétiques pour inscriptions cassées : détectez les échecs tôt
Les contrôles synthétiques pour inscriptions cassées détectent les échecs de connexion, onboarding et paiement depuis l’extérieur de votre réseau et vous alertent avant que de vrais utilisateurs ne partent.
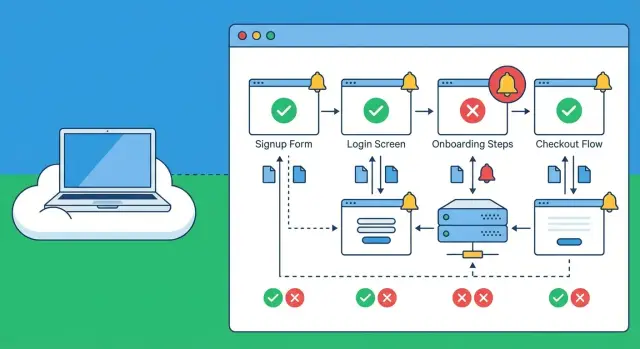
Pourquoi les inscriptions cassées passent entre les mailles et comment les utilisateurs le vivent
Une inscription cassée ne ressemble rarement à une panne dramatique. Pour une personne réelle, c’est comme si le site ne fonctionnait tout simplement pas : un bouton qui ne fait rien, un spinner qui tourne indéfiniment, un flou « Quelque chose a mal tourné », ou un formulaire qui se soumet puis renvoie discrètement à l’écran de connexion.
Parfois l’interface indique « Vérifiez votre email », mais le message n’arrive jamais. Ou il arrive en retard, le lien est expiré et l’utilisateur abandonne. Sur mobile, une seule étape supplémentaire (comme un CAPTCHA qui ne se charge pas) peut suffire à tuer le flux.
Ces échecs passent entre les mailles parce que les équipes testent généralement le chemin heureux depuis leur propre environnement. Les vérifications internes peuvent confirmer que le serveur est up et que la base répond, mais ça ne garantit pas que le parcours fonctionne depuis l’internet public. Les problèmes qui apparaissent souvent uniquement en externe incluent :
- Des problèmes CDN ou cache servant un ancien bundle JavaScript
- Des fournisseurs d’authentification ou d’email tiers bloqués ou limités par région
- Des cookies, redirections ou CORS mal configurés qui se comportent différemment hors réseau
- Un déploiement qui fonctionne pour les admins connectés mais casse les nouveaux comptes
L’impact business est direct et rapide. Une inscription cassée signifie des clics payants sans prospects, des paniers abandonnés au checkout, et plus de tickets de support commençant par « Je ne peux pas créer de compte ». Pire encore, beaucoup ne se plaindront pas : ils partiront simplement.
Les contrôles synthétiques pour inscriptions cassées aident car ils se comportent comme un vrai client. Ils répètent les mêmes étapes (inscription, vérification, première connexion) et alertent quand le parcours échoue. Ils ne remplacent pas le feedback réel des utilisateurs, l’analytics ou le support client, mais ils réduisent le temps entre « c’est cassé » et « vous le savez ».
Ce que sont (et ne sont pas) les contrôles synthétiques
Les contrôles synthétiques sont des scripts planifiés qui agissent comme un utilisateur réel. Ils ouvrent votre site ou appli, cliquent sur les étapes clés, saisissent des données et confirment un « moment de réussite » (par exemple, un nouveau compte arrive sur une page de bienvenue, ou le premier tableau de bord se charge). Pensez-y comme un client fiable et répétable qui se présente toutes les quelques minutes et rapporte ce qu’il a vu.
« Depuis l’extérieur de votre réseau » signifie que le contrôle s’exécute depuis l’internet public, pas depuis votre Wi‑Fi de bureau, VPN ou réseau cloud interne. C’est important car beaucoup d’échecs d’inscription n’apparaissent que dans le monde réel : problèmes DNS, edge CDN, cookies bloqués, routage géographique, ou scripts tiers qui se comportent différemment hors de votre environnement.
Les vérifications d’uptime de base répondent à une question : « La page d’accueil répond‑elle ? » Les contrôles synthétiques pour inscription cassée vont plus loin et suivent tout le parcours bout en bout. Un site peut être « up » tandis que l’inscription est silencieusement cassée à cause d’une erreur JavaScript, d’une mauvaise réponse API ou d’un secret expiré.
Les contrôles synthétiques sont bons pour détecter les problèmes d’UI (boutons non cliquables, formulaires bloqués, pages qui ne se chargent pas), les défaillances d’API (500, bugs de validation, auth cassée), les pannes tierces (paiements, captcha, scripts qui plantent la page) et les étapes lentes qui expirent.
Ce qu’ils ne peuvent pas prouver de manière fiable à eux seuls, c’est qu’un humain a reçu et utilisé un lien dans un email. Vous pouvez vérifier qu’un email a été demandé, mais la livraison en boîte varie. Une approche courante consiste à valider l’événement backend (« email de vérification créé ») et à considérer la livraison en boîte comme un contrôle séparé.
Choisissez les parcours qui comptent : inscription, onboarding, checkout
La plupart des équipes veulent tout surveiller et finissent par ne rien surveiller correctement. Commencez par choisir 2 à 4 parcours utilisateur qui affectent directement le CA ou la charge support. Pour la plupart des produits, les contrôles d’inscription rapportent le plus vite car de petites erreurs (email manquant, spinner bloqué) peuvent diviser les nouveaux utilisateurs par deux sans bruit.
Choisissez des parcours qui représentent une personne réelle essayant de devenir cliente, pas des chemins admin internes ou des écrans de paramètres rarement utilisés. Un ensemble de départ solide :
- Création de compte (email ou social)
- Connexion (incluant une tentative avec « mauvais mot de passe »)
- Onboarding (première action significative, par ex. créer un workspace)
- Checkout (du panier au reçu)
- Réinitialisation de mot de passe (demande + confirmation)
Pour chaque parcours, notez un signal de réussite vérifiable. Ne vous fiez pas à « page chargée ». Utilisez un moment clair qui prouve que le flux a fonctionné, comme une redirection vers une page de bienvenue, un message visible « Vous êtes connecté », ou un écran de reçu avec numéro de commande.
Décidez où le script s’arrête. Le meilleur point d’arrêt est le premier moment de réussite clé, pas tous les cas limites. Un contrôle d’inscription qui confirme l’écran de bienvenue suffit souvent. Gardez les cas profonds (plans multiples, coupons, formats d’adresse) pour plus tard, sinon vous générez des alertes bruyantes.
Faites en sorte que le script se comporte comme un nouveau visiteur : session navigateur fraîche, pas de cookies, taille de fenêtre normale. C’est là que les problèmes cachés apparaissent, comme les redirections d’auth cassées, les problèmes de cookies tiers, ou une étape d’onboarding qui échoue seulement quand le localStorage est vide.
Exemple : vous testez le checkout en étant connecté comme utilisateur ancien, mais les nouveaux utilisateurs doivent vérifier leur email d’abord. Votre script synthétique doit suivre le chemin nouveau‑utilisateur, sinon il manquera l’erreur.
Données de test et comptes : réaliste sans être risqué
Les contrôles synthétiques n’aident que s’ils se comportent comme un vrai client. Ça signifie écrans réels, emails réels, redirections réelles, et parfois même un vrai paiement. Mais n’utilisez jamais de données client réelles pour ça.
Commencez par des utilisateurs de test dédiés. Rendez‑les évidents (par ex. synth_signup_01) et taggez‑les dans la base si possible, afin que le support et l’analytics ne les confondent pas avec de vrais clients. Utilisez des adresses email de test et un moyen de paiement de sandbox fourni par votre prestataire, ou un produit à faible risque et petit montant si vous devez tester en production.
Les emails et codes à usage unique sont le point le plus pénible. Vous avez quelques options sûres : garder une boîte de test que le script peut lire, autoriser un code de test connu uniquement pour les utilisateurs synthétiques, ou ajouter un chemin de vérification séparé qui fonctionne seulement avec un flag synthétique. L’objectif : tester le même flux que les clients utilisent, sans transformer votre système d’auth en cible facile.
Le staging est utile pour des contrôles rapides, mais beaucoup d’équipes exécutent aussi les inscriptions en production parce que c’est là que surviennent les vraies pannes : limites de taux, pannes tierces, redirections mal configurées, ou secret expiré. Si vous surveillez en prod, gardez le script peu impactant : une exécution, un utilisateur, un achat (ou une autorisation $0) et nettoyez après.
Les identifiants font partie du produit maintenant, traitez‑les comme tels :
- Stockez les identifiants de test dans un gestionnaire de secrets, pas dans le script ou le repo.
- Utilisez le moins de droits possibles (un rôle test, pas un admin).
- Faites tourner mots de passe, clés API et cartes de test selon un planning.
- Restreignez l’accès à la boîte de test au seul système de monitoring.
- Enregistrez chaque connexion synthétique pour repérer les abus.
Où et à quelle fréquence exécuter les contrôles depuis l’extérieur
Si votre script synthétique ne s’exécute que depuis l’IP de bureau (ou le même cloud que votre appli), il peut manquer les pannes que voient les vrais clients. Lancez des contrôles depuis l’internet public, depuis plusieurs lieux, pour capturer les problèmes liés au routage, DNS, edge CDN ou pannes tierces régionales.
Une configuration simple : 2 à 4 régions correspondant à là où sont vos utilisateurs. Si la majorité est aux États‑Unis et en Europe, lancez un contrôle depuis US East, un depuis US West et un depuis l’Europe de l’Ouest. Ça aide à repérer les problèmes « ça marche pour moi » comme un fournisseur d’auth qui timeout uniquement dans une région.
Cadence : quelle fréquence est « suffisante » ?
La fréquence est un compromis entre rapidité, bruit et coût. Choisissez une cadence par parcours, pas une taille unique pour tout :
- Toutes les 1 minute : checkout et paiements, ou inscriptions à fort trafic pendant un lancement
- Toutes les 5 minutes : inscription et connexion de base pour un produit stable
- Toutes les 15 minutes : étapes d’onboarding qui changent rarement
- Après déploiements : lancez un tour supplémentaire immédiatement après la release
Rendez les échecs faciles à lire en mettant des timeouts par étape. Utilisez des limites séparées pour chargement de page, réponse API et écran de confirmation. Si « Créer un compte » n’affiche pas le message de succès dans les 20 secondes, l’alerte doit l’indiquer clairement, pas seulement « test failed ».
Capturer des preuves quand ça casse
Quand quelque chose casse à 3 h du matin, vous voulez des preuves, pas des suppositions. Configurez vos contrôles pour sauvegarder une capture d’écran à l’étape de l’échec, les logs console et erreurs réseau, l’étape exacte et le timeout déclenché, et une courte trace des requêtes clés (signup, échange de token, confirmation).
Pas à pas : construire un script synthétique qui reflète vraiment la réalité
Un contrôle synthétique utile se lit comme une vraie user story. Faites‑vous passer pour un visiteur première fois sur une connexion lente, sans cookies, venant de l’extérieur du réseau. Votre script doit suivre ce chemin, pas celui que vous connaissez par cœur.
Un ordre de construction pratique
Commencez simple, puis renforcez jusqu’à attraper les pannes que rencontrent les clients.
- Écrivez d’abord le parcours en étapes claires, puis automatisez‑le : ouvrez la page publique, attendez son chargement, remplissez les mêmes champs que l’utilisateur voit, soumettez et confirmez l’état attendu (par ex. « Bienvenue » plus en‑tête connecté).
- Utilisez des sélecteurs stables et des attentes prévisibles. Préférez des attributs que vous contrôlez (comme
data-testid) plutôt que des IDs aléatoires ou des chaînes CSS fragiles. Attendez un élément spécifique qui indique que la page est prête, pas un sleep fixe. - Validez le bon résultat, pas seulement « pas de crash ». Un écran de succès peut être simulé par un bug front. Quand c’est possible, confirmez aussi la réalité serveur, par ex. « enregistrement utilisateur créé » ou « cookie de session défini » via une vérification API.
- Ajoutez des retries avec prudence. Retenter un chargement de page est acceptable. Retenter une action métier (création de compte, soumission d’une commande, débit d’une carte) peut créer des doublons et masquer de vrais erreurs.
- Capturez des preuves en cas d’échec. Sauvegardez capture d’écran, logs console et erreurs réseau pour que la personne on‑call voie ce qui a cassé sans avoir à le reproduire localement.
Le rendre résistant aux faux positifs
Les contrôles d’inscription synthétiques échouent souvent parce qu’ils ne testent que l’UI. Un exemple courant : le formulaire se soumet, vous voyez un message de succès, mais l’auth est cassée et la page suivante renvoie à la connexion. Ajoutez une étape finale « puis‑je accéder à la page compte » pour prouver que la session fonctionne vraiment.
Alertes et triage : attraper les échecs sans créer du bruit
Les alertes doivent répondre vite à deux questions : « Est‑ce réel ? » et « Qui doit agir ? ». Sinon, les gens finissent par les ignorer et la prochaine vraie panne passe inaperçue.
Commencez par des seuils qui tiennent compte de la volatilité d’internet. Une seule exécution ratée peut être un glitch (fournisseur temporaire, coupure réseau brève). Des échecs consécutifs indiquent généralement une vraie rupture du flux.
Une approche simple qui marche pour la plupart :
- Pager sur 2 échecs consécutifs depuis le même emplacement
- Créer un ticket ou notifier sur 1 échec si c’est le checkout ou un paiement
- Résoudre automatiquement seulement après 1 à 2 exécutions propres
- Ajouter un résumé quotidien des « presque‑ratés » pour voir les tendances sans bruit
Le routage importe autant que la détection. Une étape d’inscription cassée peut relever du product (texte ou consentement), de l’ingénierie (API ou auth), ou d’un partenaire agence (release récente). Si vous ne savez pas qui possède quelle étape, décidez‑le d’abord et consignez‑le.
Rendez les alertes actionnables en incluant le contexte répondant aux premières questions : quelle étape a échoué, ce que le script attendait, ce qu’il a vu à la place, d’où il a tourné et quand il a fonctionné pour la dernière fois. Incluez l’heure de la dernière réussite et un court extrait d’erreur (code d’état, texte UI ou message de validation). « Signup failed » est du bruit. « Échec à la vérification email : champ de code absent ; dernière réussite 03:12 UTC ; US‑East » est utile.
Gardez un runbook court pour un triage cohérent :
- Relancer une fois depuis un autre emplacement pour confirmer
- Vérifier les déploiements récents, feature flags et le statut des tiers (email, SMS, paiements)
- Essayer le même flux en fenêtre incognito avec un compte test
- Capturer l’étape exacte et le texte d’erreur avant d’escalader
- Escalader au propriétaire avec le contexte joint
Erreurs courantes qui rendent les contrôles synthétiques inutiles (ou dangereux)
Les contrôles synthétiques n’aident que s’ils se comportent comme un vrai client et échouent pour les mêmes raisons. Quelques raccourcis courants peuvent rendre les contrôles « verts » tandis que les utilisateurs sont bloqués, ou pire, créer des dégâts en production.
Un oubli fréquent : tester seulement le chemin heureux. Une inscription qui affiche « compte créé » peut toujours être cassée si la vérification email n’arrive jamais, le lien de vérif échoue, ou la première connexion après vérif plante. Il en va de même pour la réinitialisation de mot de passe — beaucoup d’équipes ne la scriptent pas et ne remarquent donc jamais que le template email est cassé ou que le token expire instantanément.
Autre piège : exécuter les contrôles seulement depuis votre réseau interne. Si le script tourne dans votre VPC, il peut passer outre exactement ce dont les clients dépendent : résolution DNS, comportement CDN, règles WAF, géorestrictions, ou une redirection mal configurée à la périphérie. L’app peut sembler OK en interne tandis que les vrais utilisateurs subissent timeouts, requêtes bloquées ou asset mis en cache mauvais.
Les scripts fragiles sont souvent auto‑infligés. Si le contrôle clique un bouton qui bouge, attend un spinner en devinant le timing, ou cible un sélecteur qui change à chaque build, vous aurez de la fatigue d’alerte. Attendez des signaux de page stables (titre clair ou réponse API connue) et choisissez des sélecteurs pensés pour les tests.
Faites attention aux retries « utiles ». Retenter une soumission de formulaire peut créer des utilisateurs en double, des abonnements d’essai en double, ou même des commandes en double si votre backend n’est pas idempotent. Si vous devez retenter, retentez des étapes sûres (chargement de page), pas des achats ou créations de compte.
Une checklist rapide de sécurité :
- Couvrez la vérification et la réinitialisation, pas seulement l’inscription initiale
- Exécutez depuis l’extérieur de votre réseau dans au moins une vraie région
- Utilisez des sélecteurs stables et des waits fiables
- Évitez de resoumettre des actions qui créent des données
- Gardez les identifiants hors du code et des logs
Enfin, traitez les secrets comme des données de production. Les comptes test doivent avoir des permissions minimales, et les identifiants doivent vivre dans un store de secrets, pas dans le repo ou les payloads d’alerte.
Checklist rapide : votre monitoring couvre‑t‑il la vraie douleur utilisateur ?
Si votre monitoring ne vérifie que la page d’accueil, il manquera les échecs qui stoppent réellement le chiffre d’affaires. Utilisez cette checklist pour vérifier si votre monitoring d’inscription suit ce qu’un vrai nouveau client fait, dans le bon ordre, avec des preuves exploitables.
Un bon contrôle se termine par un signal de réussite clair. « 200 OK » n’est pas suffisant. Vous voulez voir le premier écran qui confirme que l’utilisateur est vraiment dedans (page de bienvenue, tableau de bord, ou étape « vérifiez votre email » qui n’apparaît qu’après soumission réussie).
Voici une checklist rapide qui correspond à la vraie douleur utilisateur :
- Un tout nouveau utilisateur peut soumettre le formulaire d’inscription et arriver sur le premier écran de réussite (pas une redirection générique).
- La connexion fonctionne juste après l’inscription dans une session fraîche (fermez et rouvrez le contexte navigateur pour ne pas dépendre d’une authentification en cache).
- L’onboarding change réellement l’état de l’app (par ex. un champ de profil est enregistré, ou le premier workspace/projet est créé et visible après rafraîchissement).
- Le checkout atteint un état de confirmation sans retries, et ne déclenche pas une seconde charge en cas de rafraîchissement de la page.
- Quand quelque chose échoue, l’alerte inclut une capture d’écran et l’étape exacte qui a cassé (quel bouton, quelle URL, quel texte d’erreur).
Un contrôle de réalité simple : imaginez que votre formulaire d’inscription réussit, mais que la page suivante plante uniquement pour les premiers utilisateurs parce qu’un enregistrement « équipe par défaut » n’a pas été créé. Les tests locaux ne le verront jamais car vos comptes ont déjà les données. Une exécution synthétique qui crée un nouvel utilisateur à chaque fois le détectera rapidement.
Scénario d’exemple : l’inscription marche pour vous mais pas pour les clients
Un fondateur lance un lundi. Le trafic est normal, mais les nouveaux comptes chutent presque à zéro. L’équipe vérifie l’uptime, tout a l’air OK : la page d’accueil se charge, l’API répond, pas d’erreurs serveur.
Le problème est simple : le fondateur (et son équipe) teste l’inscription depuis le réseau du bureau dans un pays, sur un navigateur, alors que les vrais utilisateurs viennent de plusieurs régions et appareils.
Ils ajoutent des contrôles synthétiques pour inscriptions cassées qui tournent depuis l’extérieur. Un contrôle tourne depuis les US, un depuis l’UE et un depuis l’Asie. Les exécutions US et EU passent, mais l’exécution Asie échoue tout le temps juste après le bouton « Continuer avec Google ».
L’alerte est utile car elle inclut ce qu’un vrai utilisateur verrait :
- Une capture d’écran d’une boucle de redirection qui rebondit entre l’app et le provider d’identité
- Un court message console comme « redirect_uri_mismatch » et l’URL finale qui se répète
- L’étape exacte qui a échoué (après l’auth, avant la création du compte)
Il s’avère que l’URL de callback d’auth était mal configurée. L’app avait un callback qui fonctionnait pour le domaine principal, mais un edge régional ou un domaine alternatif en Asie produisait une URL de redirection légèrement différente. Depuis l’ordinateur du fondateur, ça n’apparaissait jamais.
La correction est simple : mettre à jour les callback URLs autorisées chez le fournisseur d’auth et garantir que l’app retourne toujours la même cible de redirection. Puis relancer le script synthétique depuis toutes les régions, confirmer que chaque exécution atteint l’écran « Compte créé » et clôturer l’incident.
Avant de passer à autre chose, ajoutez un contrôle de régression : lancer le même script d’inscription après chaque déploiement, depuis au moins un emplacement externe, et n’alerter que si ça échoue deux fois de suite.
Prochaines étapes : déployez vos premiers contrôles et stabilisez l’app
Commencez petit et mettez‑en un en production cette semaine. Un script pour l’inscription et un pour le checkout suffisent pour attraper la plupart des moments « rien ne marche ». Choisissez d’abord le chemin heureux le plus simple, puis ajoutez des variantes plus tard (plans différents, codes promo, moyens de paiement, nouveau vs ancien utilisateur).
Lancez vos deux premiers scripts comme une release produit :
- Écrivez un parcours d’inscription et un parcours de checkout qui correspondent à ce qu’un client réel fait, depuis l’extérieur de votre réseau.
- Enregistrez une baseline : taux de réussite et temps moyen pour finir chaque parcours.
- Ajoutez des règles claires pass/fail (par ex. : compte créé, écran de bienvenue affiché, paiement confirmé).
- Configurez une alerte par parcours et orientez‑la vers la personne qui peut agir.
- Review hebdomadaire des résultats et étendez la couverture seulement après stabilisation des bases.
Une fois les contrôles en place, surveillez les chiffres quelques jours. Une petite baisse du taux de réussite peut être aussi importante qu’une panne complète. Suivez aussi le temps d’exécution : si l’inscription prend subitement deux fois plus longtemps, quelque chose est souvent à moitié cassé (API lente, spinner bloqué, retard de livraison d’email) avant de tomber en panne complète.
Si les échecs sont fréquents, marquez une pause et stabilisez l’app avant d’ajouter plus de surveillance. Les coupables habituels : cas limites d’authentification, étapes d’onboarding fragiles, et gestion d’erreurs manquante (une mauvaise réponse ou un champ vide casse tout). Corrigez la cause racine, puis renforcez le script pour qu’il vérifie les bons messages et changements d’état.
Si vous avez hérité d’une base générée par IA et que vous ne savez pas si le script est faux ou si l’app est cassée, une passe de remédiation ciblée peut faire gagner du temps. FixMyMess (fixmymess.ai) se concentre sur le diagnostic et la réparation de problèmes comme l’auth cassée, le routage chaotique, les secrets exposés et les lacunes de sécurité afin que votre monitoring d’inscription reflète la santé réelle des utilisateurs au lieu d’alertes constantes.
Questions Fréquentes
Pourquoi l’inscription marche pour nous mais échoue pour de vrais utilisateurs ?
Parce que la plupart des équipes testent le « chemin heureux » dans leur propre environnement, où DNS, bords CDN, cookies et fournisseurs tiers se comportent différemment. Les vrais utilisateurs touchent la version publique, donc des problèmes comme un JavaScript ancien mis en cache, des cookies mal configurés ou des limites de taux régionales peuvent casser l’inscription sans apparaître en interne.
Quelle est la différence entre la surveillance d’uptime et un contrôle synthétique d’inscription ?
Un contrôle d’uptime ne vous dit que si une page répond. Un contrôle synthétique d’inscription clique à travers tout le parcours et confirme un véritable signe de réussite, comme atteindre une page de bienvenue ou charger le premier tableau de bord après création d’un compte.
Quels parcours utilisateurs devrions-nous surveiller en priorité ?
Commencez par 2 à 4 parcours qui affectent directement le chiffre d’affaires ou la charge support. Pour la plupart des produits : création de compte, première connexion, réinitialisation de mot de passe et checkout — ce sont les chemins que les utilisateurs abandonnent rapidement si quelque chose cloche.
Quel est un bon signal de réussite pour un contrôle synthétique d’inscription ?
Choisissez une seule preuve que le parcours a réellement fonctionné, pas seulement qu’une page s’est chargée. Par défaut, vérifiez que l’utilisateur peut accéder à un écran authentifié dans une session fraîche, pour éviter les faux positifs liés à un simple message côté front.
Comment tester la vérification par email si la livraison en boîte est peu fiable ?
La méthode la plus simple est de vérifier l’événement backend indiquant qu’un email a été généré et mis en file, puis de traiter la livraison en boîte comme un contrôle séparé. Si vous devez valider le lien de bout en bout, utilisez une boîte de réception de test dédiée que le script peut lire, et gardez cet accès verrouillé.
Quelle est la façon la plus sûre de gérer les comptes et identifiants de test ?
Utilisez des utilisateurs de test dédiés clairement identifiables et distincts des vrais clients, et évitez les données client réelles. Stockez les identifiants de test dans un gestionnaire de secrets, limitez les permissions, et faites tourner régulièrement ce dont dépend le script pour qu’il ne devienne pas un point faible durable.
D’où devraient s’exécuter les contrôles synthétiques pour détecter des échecs réels ?
Exécutez-les depuis l’internet public et depuis plusieurs régions, sinon vous manquerez les problèmes de DNS/CDN edge et les pannes tierces géo-spécifiques. Un paramètre pratique : 2 à 4 régions qui correspondent à vos utilisateurs pour détecter les cas « ça marche ici, ça casse là-bas ».
Quelle fréquence pour exécuter les contrôles d’inscription sans générer du bruit d’alerte ?
Pour un produit stable, toutes les 5 minutes pour l’inscription et la connexion est une bonne base, avec une exécution supplémentaire juste après un déploiement. Augmentez la fréquence pendant les lancements ou pour le checkout, et fixez des timeouts par étape pour que l’alerte indique précisément où ça bloque.
Comment éviter des scripts fragiles et des faux positifs ?
Utilisez des sélecteurs stables que vous contrôlez (par ex. des data-testid) et attendez des signaux prêts spécifiques plutôt que d’utiliser des sleeps fixes. Évitez aussi de réessayer des actions qui créent des données (comme créer un compte ou passer une commande), car les retries peuvent masquer des erreurs réelles et générer des duplications.
Que faire si notre application est générée par IA et que l’inscription est déjà instable ?
Si vous voyez des pannes répétées et que vous ne savez pas si c’est le script ou l’application, corrigez d’abord le flux sous-jacent. FixMyMess peut auditer une base de code générée par IA, réparer l’authentification, le routage et les problèmes de sécurité, et vous aider à stabiliser l’inscription pour que la surveillance devienne fiable plutôt que bruyante.