Agotamiento del pool de conexiones de la base de datos: ajuste para serverless
Aprende por qué puede producirse el agotamiento del pool de conexiones incluso con tráfico ligero y cómo ajustar el pooling para serverless frente a servidores de larga duración para evitar interrupciones.
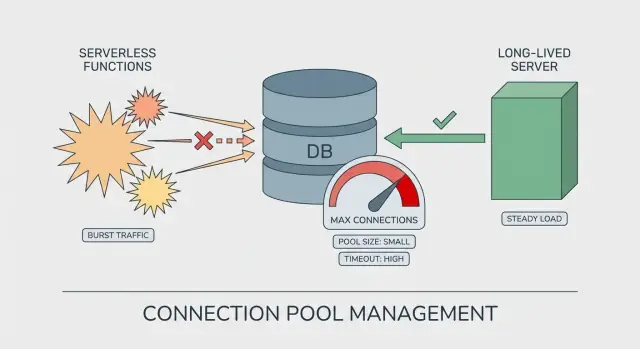
Cómo se ve el agotamiento del pool en producción
El agotamiento del pool de conexiones significa que tu app no puede obtener una conexión a la base de datos cuando la necesita. Las solicitudes se acumulan, la app espera y finalmente falla por un timeout. Para los usuarios, parece que el sitio se rompe de forma aleatoria.
La mayoría de los equipos lo detecta primero como “todo está lento” aunque CPU y tráfico parezcan normales. Páginas que normalmente cargan en un segundo se quedan colgadas 10–30 segundos y luego fallan. Suele golpear primero flujos sensibles: login, checkout, guardar un formulario.
Los síntomas visibles suelen ser:
- Páginas lentas que a veces se recuperan al refrescar
- Errores 500 aleatorios que desaparecen y vuelven
- Fallos en el inicio de sesión o sesiones que se cortan
- Trabajos en background que dejan de avanzar
- Apps móviles que expiran en acciones simples
Desde el lado de ingeniería, el patrón es más específico: crecen las colas de solicitudes, se pasa más tiempo esperando la base de datos y los logs muestran errores como “timeout acquiring connection.” En la base de datos, las conexiones activas pueden estar cerca del límite o aparecen picos cortos.
Lo confuso es la descoordinación: el tráfico puede parecer “ligero” mientras el sistema está bloqueado esperando.
Una causa común es que unas pocas solicitudes mantengan conexiones más tiempo del esperado. Una consulta lenta, una transacción abierta o código que olvida liberar un cliente puede bloquear el pool. A partir de ahí, aunque haya pocos usuarios, se puede desencadenar un atasco.
Por qué ocurre incluso con tráfico ligero
“Usuarios online” no es lo mismo que “conexiones activas a la base de datos.” La mayoría de las bases permiten menos conexiones concurrentes de lo que se piensa, y cada conexión consume memoria y CPU.
En Postgres, max_connections suele fijarse de forma conservadora. Incluso un límite de 100 puede ser demasiado si cada conexión es pesada. Añade herramientas admin, trabajadores en background, migraciones y scripts puntuales, y te puedes quedar sin conexiones antes de lo previsto.
Además, una sola petición puede tocar la base de datos varias veces: la consulta principal, una escritura de analítica, una actualización de sesión y quizá encolar un job. Si eso no se gestiona bien, el “tráfico ligero” sigue generando mucho trabajo concurrente.
El agotamiento del pool suele venir de una o varias de estas causas:
- Conexiones filtradas tras errores o timeouts, que nunca vuelven al pool
- Consultas lentas que mantienen conexiones más tiempo, forzando a otras solicitudes a hacer cola
- Reintentos que multiplican el tráfico (reintentos del cliente, del servidor, del ORM)
- Ruido de fondo como bots, cron jobs, health checks, polling de colas
- Tareas de arranque o migraciones que abren conexiones extras en el peor momento
Un ejemplo concreto: tienes 10 usuarios, pero un endpoint a veces ejecuta una consulta de 4 segundos. Con un pool de 10, un pequeño pico (por refrescos, reintentos o un bot) puede ocupar todas las conexiones. Las nuevas solicitudes esperan, alcanzan el timeout del pool, fallan, reintentan y empeoran el pico.
Los incidentes con tráfico “ligero” suelen ser por la vida útil de las conexiones y la concurrencia, no por el conteo bruto de solicitudes.
Serverless vs servidores de larga duración: la diferencia en pooling
En un servidor de larga duración (VM, contenedor, servidor de aplicaciones clásico), el proceso permanece activo horas o días. El pool de la base de datos se reutiliza entre muchas peticiones. Se “calienta”, se estabiliza y puedes razonar sobre cuántas conexiones hay en un momento dado.
Serverless es distinto. Tu código puede correr en muchas instancias de corta vida. Cada instancia puede crear su propio pool, aunque solo atienda unas pocas peticiones. Ahí es donde el agotamiento del pool aparece con tráfico que parece ligero: el tráfico se reparte entre más instancias de las que esperabas.
Por qué serverless multiplica las conexiones
El salto suele venir de cold starts y eventos de escalado. Cuando la plataforma quiere más paralelismo, arranca más instancias y cada una puede abrir su propio conjunto de conexiones.
Un tamaño de pool que parece seguro en un servidor puede ser arriesgado en serverless:
- Servidor de larga duración: 1 instancia x pool de 20 = ~20 conexiones
- Explosión serverless: 30 instancias x pool de 20 = ~600 conexiones
Aunque ese pico sea breve, puede bastar para alcanzar límites de Postgres, ralentizar consultas y provocar timeouts.
Una forma simple de pensarlo
En servidores de larga duración, ajustas el pool para la reutilización y el throughput. En serverless, lo ajustas para el radio de daño: asume que puede haber muchas copias de tu app ejecutándose a la vez.
Números que recopilar antes de cambiar ajustes
Adivinar con los ajustes del pool convierte problemas pequeños en incidentes en producción. Antes de tocar nada, recoge algunas cifras para saber si te faltan conexiones, si las mantienes demasiado tiempo o ambas cosas.
Empieza por el límite de la base. Encuentra max_connections de Postgres y luego lista quién las usa: tu app, herramientas admin, trabajadores en background, migraciones, herramientas BI, réplicas de lectura. Muchos equipos creen tener “100 conexiones” cuando 30 ya están ocupadas.
Luego céntrate en concurrencia, no en tráfico diario. Un sitio con 200 usuarios al día puede picos de 20 solicitudes concurrentes si una página dispara múltiples llamadas o varias personas refrescan simultáneamente. Observa las solicitudes concurrentes pico durante tus 5–15 minutos más ocupados y desglósalo por instancia (o por función en serverless).
La velocidad de las consultas importa tanto como el número de conexiones. Extrae las consultas lentas por tiempo total y por latencia p95/p99. Unas pocas consultas de 2–5 segundos pueden mantener ocupadas las conexiones lo suficiente para bloquear todo lo demás.
Las señales que normalmente explican los “apagones” repentinos:
- Conexiones abiertas frente al límite de Postgres y qué tan rápido crecen
- Tiempo de espera por conexión (tiempo pasando esperando una conexión libre)
- Timeouts del pool y ráfagas de errores (frecuencia y marcas temporales)
- Concurrencia de solicitudes en el momento en que empiezan los errores
- Si los trabajadores en background comparten la misma base y pool
Una comprobación rápida: si tu timeout de adquisición de pool es 10 segundos y ves latencias de API de 12 segundos, los usuarios culpan “al servidor” cuando la demora real es esperar una conexión.
Paso a paso: ajustar pooling para servidores de larga duración
En servidores de larga duración (VMs, contenedores, pods siempre activos), la mayor trampa es olvidar que cada proceso puede tener su propio pool. Diez workers web con un pool de 20 no son 20 conexiones, son hasta 200.
Empieza con un objetivo que deje margen bajo el límite de la base. Si Postgres permite 100 conexiones, rara vez quieres que tu app pueda tomar las 100. Deja espacio para migraciones, sesiones admin, herramientas y deployments. Presupuesta aparte para workers de jobs.
1) Fija un tamaño de pool que coincida con la concurrencia real
Piensa en “cuántas consultas se ejecutan al mismo tiempo”, no en “cuántos usuarios”. Las consultas lentas hacen que cada conexión esté prestada más tiempo, lo que aumenta el pool que necesitas.
Un enfoque práctico es fijar un presupuesto total de conexiones para toda la app (a menudo 60%–80% del límite de la BD) y luego dividirlo entre los procesos que se conectan. Empieza pequeño y súbelo solo si ves colas y la BD aún tiene margen. Presupuesta separado para trabajadores de jobs.
2) Añade timeouts que fallen rápido (y se recuperen)
Dos ajustes previenen acumulaciones silenciosas: timeout de adquisición (cuánto espera una solicitud por una conexión libre) y timeout de inactividad (cuánto tiempo permanece abierta una conexión sin usarse). Timeouts de adquisición cortos convierten un desmelene lento en un error visible y contenido que puedes alertar.
Si tienes que elegir, un pool más pequeño con timeouts claros es más seguro que un pool grande que lleva a la base a sobrecargarse.
3) Limita la concurrencia por encima del pool
Si tu servidor puede aceptar 500 solicitudes concurrentes pero tu presupuesto total de BD es 60 conexiones, necesitas un límite: número de workers, concurrencia de solicitudes o paralelismo del runner de jobs.
Luego verifica que las conexiones siempre se devuelvan, incluyendo rutas de error. Busca bloques finally faltantes, transacciones abandonadas o sesiones ORM de larga duración.
Paso a paso: ajustar pooling para serverless
Serverless cambia las matemáticas. El código puede verse igual, pero la plataforma puede crear muchas instancias de corta vida a la vez.
1) Establece límites estrictos por instancia
Haz que cada instancia sea “pequeña” desde el punto de vista de la base de datos. En muchas configuraciones serverless, no quieres un pool grande dentro de cada función.
Manténlo simple:
- Limita el tamaño del pool a un número bajo (a menudo 1 a 4 por instancia)
- Usa un timeout de adquisición corto para que las solicitudes fallen rápido en vez de acumularse
- Usa un timeout de inactividad para que las conexiones no usadas se cierren rápido
- Reutiliza el pool entre invocaciones (créalo una vez, fuera del manejador de la petición)
- Asegura que cada consulta libera la conexión, incluso ante errores
Chequeo de cordura: si Postgres permite 100 conexiones y la plataforma puede arrancar 50 instancias, un pool de 5 por instancia puede intentar 250 conexiones. Eso basta para romper producción.
2) Controla la concurrencia antes de tocar la BD
Tu mejor “pool” suele ser un límite de concurrencia. Corta cuántas solicitudes puede procesar una versión del servicio a la vez. Esto evita que un nuevo despliegue, una tormenta de reintentos o un pico de jobs inunden la base.
Atento también a paralelismos ocultos: batching con Promise.all, handlers de webhooks que se ramifican, consumidores de colas que procesan varios mensajes a la vez. Estos pueden multiplicar conexiones incluso con tráfico de usuario reducido.
3) Usa un pooler externo o proxy gestionado cuando sea posible
Si tu plataforma ofrece un proxy de base de datos (o puedes ejecutar un pooler externo), puede absorber la expansión serverless y mantener estables las conexiones a la BD. Aun así, conoce sus límites: el proxy puede quedarse sin capacidad o encolar peticiones más allá del timeout de tus funciones.
Un modo de fallo realista es “nuevo pool por petición” más reintentos. Diez invocaciones concurrentes pueden convertirse en 30 intentos de conexión en segundos.
Guardarraíles que evitan que problemas pequeños sean incidentes
La mayoría de los incidentes por agotamiento del pool empiezan como una pequeña ralentización. Unas pocas solicitudes esperan un poco más y luego todo se acumula. Los guardarraíles buscan fallar rápido, retroceder y mantener la app usable mientras la base se recupera.
Decide un comportamiento claro ante fallos. Si una solicitud no puede obtener una conexión rápido, debería detenerse y devolver un error claro, no quedarse colgada hasta que falle el upstream. Timeouts cortos del pool también protegen a tus workers porque liberan hilos y permiten que tu servicio siga respondiendo.
Los reintentos necesitan límites estrictos. Reintentar cada consulta fallida puede convertir un tropiezo en una estampida. Limita reintentos a operaciones seguras (lecturas idempotentes), añade jitter (retraso aleatorio) y pon un tope al tiempo total de reintentos.
Los circuit breakers son el siguiente paso. Cuando ves fallos repetidos en la BD, abre el breaker por una ventana corta y falla inmediatamente las nuevas solicitudes dependientes de la BD. Es mejor fallar rápido que arrastrar todo el sistema a un colapso lento.
La degradación elegante mantiene a los usuarios en movimiento. Según tu producto, eso puede significar modo solo lectura cuando fallan los writes, servir resultados cacheados para lecturas comunes, desactivar temporalmente funciones pesadas como informes, o devolver un mensaje amable del tipo “inténtalo de nuevo en 30 segundos” para endpoints dependientes de la BD.
Alerta sobre señales tempranas, no solo sobre errores duros. El aumento del tiempo de espera por conexión, la profundidad de colas y la subida de p95 suelen aparecer minutos antes de “demasiadas conexiones”.
Errores comunes que disparan un agotamiento repentino
La mayoría de los incidentes no vienen por un gran pico de tráfico. Ocurren cuando varias decisiones pequeñas se apilan y quitan tu margen de seguridad.
Una trampa común es dimensionar el pool de la app al límite de la base. Si Postgres permite 100 conexiones y pones tu pool a 100, no dejas espacio para migraciones, trabajadores, herramientas admin o una segunda copia de la app durante un deploy.
El escalado serverless es otra causa frecuente. Si cada instancia de función crea su propio pool, no tienes “un pool de 20”; tienes “20 por N instancias”, lo que puede convertir tráfico ligero en una tormenta de conexiones en segundos.
Los errores que más a menudo provocan una caída repentina:
- Usar el máximo de la BD como tamaño del pool de la app en lugar de reservar margen
- Crear un pool separado por instancia serverless (o por petición)
- Filtrar conexiones en rutas de error (retornos tempranos, excepciones, solicitudes canceladas)
- Mantener conexiones demasiado tiempo (consultas lentas, índices faltantes, transacciones largas)
- Dejar que el ruido de fondo compita con usuarios reales (health checks, cron jobs, polling de colas)
Un patrón realista es una app “inactiva” donde un health check ocurre cada pocos segundos, un cron corre cada minuto y una consulta lenta tarda 10 segundos. Con un pool pequeño, solo un par de solapamientos pueden llenarlo.
Lista rápida antes del lanzamiento
Muchos incidentes clasificados como agotamiento del pool son en realidad falta de comprobaciones finales: límites desconocidos, timeouts inconsistentes y concurrencia a la deriva.
Primero, escribe el techo duro. Postgres tiene un límite de conexiones y los proveedores gestionados suelen reservar algunas para tareas admin. Si no conoces tu máximo utilizable, no puedes dimensionar pools de forma segura.
Antes de lanzar, confirma:
- Tu presupuesto de conexiones:
max_connections, conexiones reservadas y el tope objetivo para la app - Tamaño de pool y timeouts con margen, incluyendo un timeout de adquisición claro
- Ajustes de concurrencia (especialmente en serverless) para que un deploy no cree una ola de nuevas conexiones
- Las consultas más lentas y las correcciones principales (indexes y N+1 accidentales son comunes)
- Visibilidad: dashboards y alertas para conteo de conexiones, tiempo de espera por conexión y timeouts del pool (no solo 500 genéricos)
Una prueba práctica: haz una pequeña prueba de carga que imite “tráfico ligero” (unos pocos usuarios navegando) y observa tiempo de espera del pool y conexiones activas. Si cualquiera sube de forma sostenida, ya estás cerca de un incidente.
Un ejemplo realista: un fallo con pocos usuarios online
Un pequeño SaaS tuvo una tarde tranquila: seis personas conectadas, un par de vistas de dashboard por minuto. Luego los usuarios reportaron que el login giraba indefinidamente y el dashboard lanzaba 500 aleatorios.
En los logs, la app no estaba “caída” en el sentido clásico. CPU bien. Memoria bien. La pista real eran mensajes repetidos como “timeout acquiring a client” y “remaining connection slots are reserved.” Clásico agotamiento del pool, aunque el tráfico parecía bajo.
Dos cambios pequeños se desplegaron a la vez.
Primero, un nuevo job en background corría cada minuto para refrescar una tabla de estadísticas. Segundo, una consulta del dashboard se hizo más lenta por un índice faltante. Esa consulta empezó a tardar 8–12 segundos y el job mantenía una conexión todo ese tiempo.
Después el despliegue movió la app de un servidor de larga duración a serverless. Nada en el código parecía más riesgoso, pero el paralelismo subió de la noche a la mañana. Unos pocos loads concurrentes más unos jobs concurrentes significaron muchos más intentos de conexión a la vez. Cada instancia tenía su propio pool, así que el número total de conexiones abiertas creció rápido.
La solución no fue un ajuste mágico, sino un conjunto de guardarraíles pequeños:
- Reducir el tamaño del pool por instancia para que ninguna instancia pueda agarrar demasiadas conexiones
- Limitar la concurrencia para que la plataforma no pueda crear trabajo paralelo ilimitado
- Acortar timeouts del pool para que las solicitudes fallen rápido y se recuperen en vez de acumularse
- Optimizar la consulta lenta (añadir el índice y reducir joins innecesarios)
Tras eso, la app se mantuvo estable. Las alertas sobre “pool wait time” y “active connections” dieron aviso minutos antes de que los usuarios lo notaran.
Próximos pasos: estabilizar el pooling y pedir una segunda opinión
Si acabas de pelear con agotamiento del pool, no empieces por cambiar números al azar. Empieza por nombrar tu modelo operativo: serverless (muchas instancias cortas), servidores de larga duración (pocos procesos estables) o híbrido. El pooling es un problema distinto en cada caso.
Escribe un presupuesto de pooling que haga imposible que tu capa de app demande más conexiones de las que Postgres puede dar con seguridad. Captura tres cosas: tu techo utilizable de conexiones Postgres, tu conteo pico de instancias (o conteo de ráfaga) y el tope por instancia, y tus timeouts “stop sign” para que las solicitudes fallen rápido en vez de acumularse.
Luego realiza una prueba de carga enfocada que refleje la realidad. Muchos equipos prueban throughput alto pero fallan en reproducir el patrón que provoca agotamiento: ráfagas breves, consultas lentas y reintentos. Incluye flujos de login/signup, tu página más lenta y tareas en background ejecutándose al mismo tiempo.
Si heredaste una base de código generada por IA, vale la pena revisar los errores comunes: “conectar por petición”, limpieza faltante en rutas de error y reintentos ocultos que multiplican la concurrencia. Si quieres una comprobación rápida, FixMyMess (fixmymess.ai) ofrece una auditoría de código gratuita que señala exactamente dónde se crean, filtran o mantienen las conexiones demasiado tiempo para que puedas arreglar la causa en vez de adivinar números del pool.
Preguntas Frecuentes
¿Qué significa realmente “agotamiento del pool de conexiones”?
Significa que tu app está esperando una conexión libre a la base de datos y no hay ninguna disponible. Las solicitudes se acumulan, alcanzan un timeout de adquisición y los usuarios ven páginas lentas seguidas de fallos intermitentes.
¿Por qué ocurre el agotamiento del pool aunque el tráfico parezca bajo?
La CPU y el tráfico pueden parecer normales porque la app no está haciendo más trabajo; está esperando. Algunas solicitudes que mantienen conexiones más tiempo de lo esperado pueden bloquear todo el pool, así que incluso tráfico “ligero” puede paralizarse.
¿Cuáles son los síntomas más comunes visibles por los usuarios en producción?
Busca bloqueos largos (a menudo 10–30 segundos) seguidos de errores 500, fallos de inicio de sesión o trabajos en background que dejan de avanzar. A veces refrescar arregla temporalmente porque se libera una conexión, y vuelve a fallar cuando el pool se llena otra vez.
¿Cómo ocurren normalmente las fugas de conexión en código real?
Sucede cuando el código obtiene una conexión pero no la devuelve en todos los caminos, especialmente en rutas de error. Excepciones no manejadas, retornos tempranos, solicitudes canceladas y lógica de limpieza faltante son formas comunes de que las conexiones queden bloqueadas.
¿El problema real es “demasiados usuarios” o es otra cosa?
Piensa en concurrencia y tiempo de retención de conexiones. Un pool puede manejar pocas consultas concurrentes; si las consultas son lentas o las transacciones quedan abiertas, cada petición mantiene la conexión más tiempo y el pool se agota antes.
¿En qué se diferencia el pooling en serverless frente a servidores de larga duración?
En servidores de larga duración, el pool se reutiliza dentro de un proceso estable y es más predecible. En serverless, muchas instancias de corta vida pueden arrancar a la vez y cada una puede crear su propio pool, multiplicando rápidamente las conexiones totales.
¿Qué cifras debo recopilar antes de cambiar los ajustes del pool?
Empieza por el límite de la base de datos (como max_connections) y resta las conexiones reservadas para sesiones admin, migraciones y trabajadores. Luego mide peticiones concurrentes pico, tiempo de espera por conexión y qué consultas son lentas en p95/p99, porque esos números explican la mayoría de los incidentes “repentinos”.
¿Qué timeouts y guardarraíles evitan un colapso lento?
Define un timeout de adquisición para que las solicitudes fallen rápido en vez de acumularse, y un timeout de inactividad para que las conexiones no utilizadas se cierren pronto. Después limita la concurrencia de peticiones y jobs para que la app no acepte más trabajo paralelo del que tu presupuesto de conexiones puede soportar.
¿Cuáles son los mayores errores que provocan el agotamiento del pool?
Evita poner el tamaño del pool igual al máximo de la BD — eso deja cero margen para migraciones, herramientas admin y workers. Tampoco crees un pool por solicitud, permitas reintentos sin control, ni ejecutes consultas lentas dentro de transacciones largas que mantienen ocupadas las conexiones.
¿Cómo estabilizo rápido una app generada por IA que agota el pool?
Revisa si el código hace “conectar por solicitud”, falta limpieza en errores, reintentos ocultos o consultas lentas que mantienen transacciones abiertas; los prototipos generados por IA suelen incluir esos patrones. Si quieres una segunda opinión rápida, FixMyMess (fixmymess.ai) ofrece una auditoría de código gratuita que señala dónde se crean, filtran o mantienen las conexiones demasiado tiempo para que arregles la causa en vez de adivinar números del pool.