Apagado ordenado para servidores Node: evitar 502s aleatorios
Aprende a hacer apagados ordenados en servidores Node para drenar conexiones keep-alive, terminar peticiones en curso, cerrar pools de BD y evitar 502s aleatorios durante despliegues.
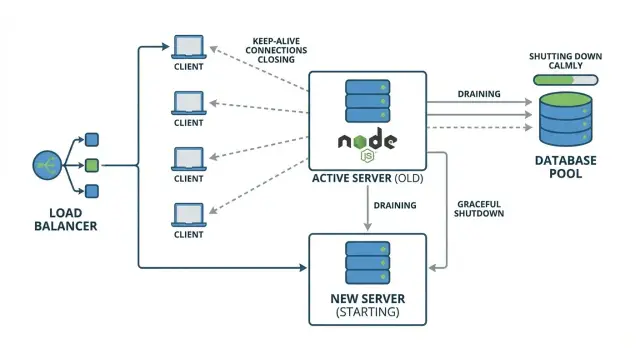
Por qué los despliegues pueden causar 502s "aleatorios"
Un “502 aleatorio” durante un despliegue normalmente significa que tu proxy inverso o balanceador de carga envió una petición a una instancia que ya estaba apagándose. Por un breve momento, el proxy puede seguir considerando esa instancia disponible, o puede reutilizar una conexión existente que ya no tiene un servidor sano al otro lado.
Parece aleatorio porque depende del timing. La mayoría de los usuarios tocan instancias que siguen en ejecución y obtienen una respuesta normal. Un grupo más pequeño cae en la ventana desafortunada: su petición llega justo cuando el proceso sale, justo cuando el servidor deja de escuchar, o justo después de que se corta una conexión.
Keep-alive puede agravar esto. Clientes y proxies reutilizan conexiones TCP existentes para múltiples peticiones, así que durante un despliegue puedes tener conexiones de larga duración todavía enviando peticiones a una instancia que estás intentando reemplazar. Si la aplicación cierra el servidor de inmediato, esas conexiones reutilizadas fallan de maneras confusas, y el proxy suele reportarlo como un 502.
La idea central es el apagado ordenado: dejar de aceptar trabajo nuevo, terminar el trabajo ya en progreso y luego salir.
Un ejemplo simple: despliegas una nueva versión, el orquestador envía una señal de parada y Node sale de inmediato. Un usuario está en medio de un checkout (una petición en curso). Otro navegador reutiliza una conexión keep-alive para pedir la siguiente página. Ambas peticiones se pierden. Todos los demás, enrutados a otras instancias, no se enteran.
Un apagado que drena conexiones y espera brevemente a que terminen las peticiones en curso evita esas fallas “aleatorias” y hace que los despliegues sean previsibles.
Qué es lo que realmente estás apagando
Un servidor Node no es solo “un proceso que se detiene.” Es un proceso en medio de una conversación con clientes, manteniendo recursos abiertos como sockets, timers y conexiones a bases de datos. El apagado ordenado va, sobre todo, de terminar esas conversaciones en el orden correcto.
Un ciclo típico de petición se ve así: un cliente se conecta, envía una petición, tu app ejecuta código (a menudo llamando a una BD u otra API), luego el servidor envía la respuesta y la petición termina. Si matas el proceso a la mitad, el cliente recibe una respuesta rota y tu balanceador puede reportarlo como un 502.
Las “peticiones en curso” son las que han empezado pero no han terminado. Son las que más probabilidades tienen de cortarse durante despliegues. Incluso las peticiones cortas pueden convertirse en en curso si la base de datos está lenta, una API externa se atrasa o el event loop está ocupado.
Keep-alive añade otra capa. Una conexión TCP puede transportar muchas peticiones con el tiempo. Durante el apagado quieres dejar de recibir peticiones nuevas, pero todavía puedes tener sockets keep-alive abiertos que están inactivos o esperando la siguiente petición.
Algunos trabajos permanecen “en curso” más tiempo y requieren cuidados extra: uploads (archivos grandes, clientes lentos), exportes/generación de reportes, respuestas en streaming y Server-Sent Events (SSE), y WebSockets (no son "peticiones" en el sentido habitual, pero siguen siendo conexiones activas).
Así que estás cerrando tres cosas: tráfico entrante nuevo, peticiones en curso y cualquier conexión de larga duración que mantiene el proceso ocupado incluso cuando parece inactivo.
Señales y timing: cómo se activa el apagado
La mayoría de los problemas en despliegues empiezan igual: tu proceso Node recibe la orden de detenerse, pero nadie está seguro de cuándo, ni cuánto tiempo tiene para terminar.
En Linux, dos señales importan sobre todo:
- SIGTERM: “Por favor sal ahora, pero limpia primero.” Es lo que las plataformas envían durante una parada o despliegue normal.
- SIGINT: “Detente porque un humano lo pidió.” Es lo que recibes con Ctrl+C en un terminal.
Los gestores de procesos y contenedores suelen seguir una secuencia simple: comienza el despliegue, la instancia vieja recibe SIGTERM y empieza una cuenta atrás (a menudo llamada periodo de gracia). Si la app sale a tiempo, perfecto. Si no, la plataforma envía un kill duro (SIGKILL) y el proceso desaparece al instante.
Si no haces nada, Node seguirá en ejecución hasta que lo fuerce. Eso significa que los sockets keep-alive pueden cortarse a mitad de una petición, el trabajo en curso puede nunca terminar y las conexiones a bases de datos pueden quedar colgando. El resultado aparece como “502s aleatorios”, incluso si los logs de tu app parecen normales.
Haz que el comportamiento de apagado sea consistente, no un esfuerzo por lo mejor que pueda. Decide de antemano qué señal manejas (normalmente SIGTERM), cuánto vas a esperar antes de forzar la salida y qué se detiene primero (tráfico nuevo) frente a qué intentas terminar (peticiones en curso).
Cuando el apagado es predecible, los despliegues dejan de depender de la suerte.
Paso a paso: dejar de aceptar tráfico nuevo de forma segura
Un despliegue no debería sentirse como desconectar la corriente. El objetivo es simple: dejar entrar tráfico nuevo al final, y terminar lo que ya está en progreso.
Empieza añadiendo una sola bandera draining en tu app. Cuando se pone a true, el servidor sigue vivo pero se está preparando para salir.
Un orden seguro para la mayoría de APIs HTTP:
- Poner
draining = truetan pronto como recibas la señal de apagado. - Hacer que tu check de readiness falle, para que el balanceador deje de enrutar nuevas peticiones a esta instancia.
- Para cualquier petición nueva que aún llegue, devolver un claro
503 Service Unavailablecon un mensaje corto. - Decirle al servidor HTTP que deje de aceptar nuevas conexiones.
- Mantener el proceso en ejecución mientras las peticiones existentes terminan (con un timeout, cubierto más abajo).
Un ejemplo mínimo (estilo Express):
let draining = false;
app.get('/ready', (req, res) => {
if (draining) return res.sendStatus(503);
res.sendStatus(200);
});
app.use((req, res, next) => {
if (draining) return res.status(503).send('Server is restarting, try again');
next();
});
process.on('SIGTERM', () => {
draining = true;
server.close(); // stop accepting new connections
});
Mantén los health checks honestos. Durante el apagado quieres que “ready” cambie a rojo rápidamente, pero aún quieres un check básico de “alive” que siga en verde hasta que realmente salgas. Eso ayuda a evitar que la plataforma mate el proceso temprano y cree precisamente los 502s que intentas prevenir.
Drenar conexiones keep-alive sin dejar usuarios colgados
Keep-alive significa que el navegador (o un balanceador) puede reutilizar la misma conexión TCP para múltiples peticiones. Eso es bueno para la velocidad, pero sorprende a mucha gente durante despliegues: dejas de aceptar conexiones nuevas, pero los sockets keep-alive antiguos siguen abiertos y pueden enviar otra petición a un proceso que está drenando.
server.close() de Node deja de aceptar conexiones nuevas, pero no cierra automáticamente los sockets keep-alive existentes. Para drenar de forma segura, haz seguimiento de los sockets cuando se conectan y luego cierra amablemente los inactivos dejando que las peticiones activas terminen.
Un patrón simple:
- Mantén un
Setde sockets desde el eventoconnectiondel servidor. - Marca los sockets como “ocupados” mientras una petición está en curso.
- En el apagado, llama a
server.close()y luego asocket.end()para los sockets inactivos. - Tras un plazo límite,
socket.destroy()para lo que siga abierto.
Aquí tienes un ejemplo compacto:
const sockets = new Set();
const busy = new Set();
server.on('connection', (socket) => {
sockets.add(socket);
socket.on('close', () => { sockets.delete(socket); busy.delete(socket); });
});
server.on('request', (req, res) => {
busy.add(req.socket);
res.on('finish', () => busy.delete(req.socket));
});
async function shutdown() {
server.close();
for (const s of sockets) if (!busy.has(s)) s.end();
setTimeout(() => { for (const s of sockets) s.destroy(); }, 10_000);
}
Ese plazo para forzar el cierre importa. Sin él, un cliente bloqueado puede mantener la instancia vieja viva y convertir un rollout en una mezcla de timeouts y errores intermitentes del proxy.
Terminar peticiones en curso con un timeout claro
Cuando comienza un despliegue, quieres que las peticiones existentes terminen de forma normal, pero también necesitas un corte duro para que el proceso viejo no se quede colgado para siempre. El enfoque más simple es llevar la cuenta de peticiones activas y usar una bandera draining.
Aquí hay un patrón pequeño que funciona con la mayoría de frameworks HTTP de Node:
let draining = false;
let active = 0;
app.use((req, res, next) => {
if (draining) return res.status(503).set('Connection', 'close').send('Server restarting');
active += 1;
res.on('finish', () => { active -= 1; });
res.on('close', () => { active -= 1; });
next();
});
function beginShutdown() {
draining = true;
}
Mientras estés drenando, evita crear trabajo nuevo que sobreviva a la petición. Un error común es permitir que una petición encole tareas en background (emails, reportes, limpieza) después de que ya decidiste apagar. Si debes encolar, protégelo con la misma bandera draining y sáltate la encolación durante el apagado.
Define un timeout de apagado que se ajuste a tu tráfico. Muchos equipos empiezan con 10 a 30 segundos y luego ajustan según los endpoints realmente lentos.
El flujo es directo: empieza a drenar y deja de aceptar peticiones nuevas, espera hasta que active === 0 y, si el temporizador vence, cierra forzosamente las conexiones restantes y sal.
Si llega una petición después de que comienza el drenado, devuelve 503 Service Unavailable y añade Connection: close. Eso le dice a clientes y balanceadores que no mantengan el socket, lo que reduce los extraños fallos de keep-alive medio cerrados que suelen aparecer como 502s.
Cerrar pools de BD y otros recursos limpiamente
Cerrar tu servidor HTTP no es lo mismo que dejar que el proceso Node termine. Un pool de base de datos mantiene sockets TCP abiertos (y a veces timers), así que el event loop sigue teniendo trabajo. Por eso un despliegue puede parecer “terminado” mientras la instancia vieja sigue viva, y luego la matan y aparecen errores.
“Cerrar el pool” normalmente significa: dejar de entregar nuevas conexiones, cerrar las inactivas y esperar a que las consultas activas terminen. Ejemplos comunes:
- PostgreSQL (
pg):await pool.end() - MySQL (
mysql2):await pool.end() - Mongoose:
await mongoose.connection.close()(y dejar de aceptar nuevas operaciones)
El orden importa. Deja de aceptar tráfico nuevo primero (para no iniciar trabajo nuevo en la BD), luego deja que las peticiones en curso terminen y después cierra el pool de BD. Después de eso, apaga el resto.
Las consultas y transacciones pendientes necesitan una regla clara. Durante el apagado, bloquea nuevas peticiones que comiencen escrituras, deja que las actuales terminen hasta un timeout y luego falla rápido. Si tienes transacciones largas, intenta cerrarlas pronto y hacer rollback si alcanzas la fecha límite.
async function shutdown() {
server.close(); // stop new HTTP connections
await Promise.race([
waitForInFlightToFinish(),
sleep(10_000),
]);
await dbPool.end();
await redis?.quit();
await queue?.close();
}
Otros recursos que mantienen vivo un proceso incluyen clientes Redis, colas de trabajo, conexiones Kafka/Rabbit, cron timers y archivos abiertos. Cerrarlos explícitamente convierte el apagado en algo en lo que se puede confiar.
Trabajos en background: no olvides el trabajo oculto
El tráfico HTTP es solo la mitad de la historia. Muchos servidores Node ejecutan trabajo en background en el mismo proceso: consumidores de colas, tareas cron, refreshs programados y bucles de worker. Durante un despliegue, estos pueden mantener el proceso vivo más de lo esperado o seguir tocando la base de datos después de que empezó el apagado.
La primera regla: una vez que comience el apagado, deja de arrancar trabajo background nuevo. Pausa el consumo de colas, detén el polling y evita que cron inicie nuevas ejecuciones. Si usas una librería, busca un método real de pause/stop (no solo disconnect), porque desconectarse puede disparar reintentos y ruido extra.
Tras detener nuevos jobs, deja que los actuales terminen, pero solo hasta un límite claro. De otro modo, un job atascado puede retrasar el apagado hasta que la plataforma mate el proceso, y entonces los errores se disparan.
Cancelar de forma segura vs esperar
Elige según lo que haga el job:
- Esperar trabajo con un límite conocido (enviar un email, redimensionar una imagen).
- Cancelar jobs largos sin fin claro (importaciones grandes, llamadas a terceros que se cuelgan).
- Cancelar todo lo que mantenga una transacción DB abierta.
- Esperar jobs que puedan hacer checkpoint y reanudarse después.
- Cancelar jobs que podrían ejecutarse dos veces y causar daño (doble cobro, doble reembolso).
Si cancelas, hazlo a propósito: pon una bandera isShuttingDown, deja de tirar mensajes y permite que los jobs consulten la bandera en puntos seguros para salir limpiamente.
Qué registrar para saber qué impidió la salida
Loggea lo suficiente para responder “¿qué seguía en ejecución?” Captura el tiempo de inicio del apagado y la señal, recuentos de jobs activos (por nombre de cola), la edad del job más antiguo y sus IDs, qué subsistema sigue abierto (cliente de cola, cron, timers) y si golpeaste la fecha límite de apagado y forzaste algo a parar.
Casos especiales: WebSockets, streaming y uploads
El apagado es más fácil cuando las peticiones son cortas. El problema aparece cuando las conexiones permanecen abiertas minutos.
WebSockets: cerrar sin sorprender a los usuarios
Los WebSockets son de larga duración por diseño, así que no los mates sin más. Durante el apagado, deja de aceptar nuevas conexiones socket, notifica a los clientes activos y dales una ventana corta para reconectar.
Un patrón práctico: enviar un evento “server restarting”, dejar de procesar nuevos mensajes y cerrar con un código de cierre normal (no un error). Si tienes un balanceador, asegúrate de que deje de enrutar nuevas conexiones a la instancia antes de empezar a cerrar sockets.
Streaming, SSE y long polls
SSE y otros endpoints en streaming pueden parecer “inactivos” para los proxies aunque estén trabajando. Durante el apagado, termina streams limpiamente para que el cliente pueda reconectar, y fija un tiempo máximo de drenado para no esperar para siempre.
Con long polling, los clientes reintentan rápido. Devolver una respuesta clara de “intenta de nuevo” es mejor que dejar que la conexión muera y aparezca como 502.
Un enfoque práctico: deja de aceptar nuevas conexiones primero, marca la instancia como draining en tu health check, envía un mensaje final y cierra streams/sockets limpiamente, da a las subidas un breve periodo de gracia y luego aborta, y usa un timeout único para todo para que los despliegues terminen.
Subidas de archivos en curso
Si un cliente está en medio de un upload, matar la conexión puede corromper el archivo y hacer perder minutos. Prefiere uploads reanudables cuando sea posible. Si no, escribe en un archivo temporal y solo “confirma” cuando la subida termine.
También revisa los timeouts del proxy inverso (Nginx, ALB, etc.). Un timeout de inactividad más corto que tu stream o upload puede parecer un 502 relacionado con el despliegue aunque el código de tu app esté bien.
Errores comunes que aún conducen a 502s
La mayoría de los 502s “aleatorios” durante despliegues no son aleatorios. Ocurren cuando el apagado se hace en el orden equivocado o cuando el balanceador sigue enviando tráfico a un proceso que ya está camino a apagarse.
Un error de timing es esperar demasiado para dejar de aceptar tráfico. Si empiezas a drenar solo después de empezar a cerrar cosas, creas una ventana donde llegan peticiones nuevas pero recursos críticos (como conexiones a BD) ya no están disponibles. El resultado parece una red inestable.
Otro problema clásico es cerrar el pool de BD primero. Las peticiones que ya pasaron el enrutamiento todavía necesitan consultas, sesiones o transacciones. Si el pool se fue, esas peticiones fallan a mitad de camino.
Los entornos de despliegue normalmente envían SIGTERM, no SIGINT. Si solo probaste con Ctrl+C localmente, tu handler de apagado puede nunca ejecutarse en producción. Esto aparece mucho en código generado por IA: funciona hasta el primer despliegue real, y luego la plataforma lo mata porque no responde a la señal esperada.
Los problemas que más suelen romper el apagado son sencillos: no entrar en modo drain temprano, no tener un plazo de apagado (o uno tan corto que corta a usuarios activos), mantener la readiness en verde mientras drenas para que siga llegando tráfico, cerrar sockets keep-alive demasiado agresivamente en vez de drenarlos, y olvidar que el trabajo en background puede mantener vivo el proceso después de cerrar el servidor HTTP.
Si vas a arreglar solo una cosa, arregla los health checks. Una vez que empieza el drenado, la instancia debe dejar de parecer "ready" rápidamente para que el tráfico se mueva a otro lado antes de que rompas algo.
Lista rápida antes de desplegar
Haz un run en staging justo antes de un release. Cuando el proceso recibe la orden de parar, debe dejar de tomar trabajo nuevo, terminar lo que empezó y no dejar cabos sueltos.
Una lista rápida:
- Envía una señal real de apagado (SIGTERM) y confirma que la app reacciona de inmediato: una línea clara en el log, readiness cambia y el servidor deja de aceptar nuevas conexiones.
- Mientras drena, confirma que las peticiones nuevas obtienen una respuesta controlada (por ejemplo, 503 con un mensaje corto) en vez de quedarse colgadas hasta que el balanceador haga timeout.
- Crea una petición lenta (sleep, query pesada o render largo) y confirma que puede terminar. También confirma que tienes un timeout duro para que el proceso salga a tiempo si algo se queda atascado.
- Revisa la limpieza: el pool de BD se cierra, los clientes de colas se desconectan y los timers se detienen. Tras la salida, el proceso no debe quedarse vivo por handles abiertos.
- Revisa los logs de apagado de principio a fin: tiempo de inicio, cuándo empieza el drenado, recuento de peticiones activas y una línea final “shutdown complete”.
Una forma simple de detectar problemas es lanzar dos curls a la vez: uno para una petición larga y otro justo después de enviar SIGTERM. Si la larga termina y la nueva obtiene una respuesta rápida y predecible, estás cerca.
Si tu servidor fue generado por una herramienta de IA (Lovable, Bolt, v0, Cursor, Replit), esos hooks suelen faltar o estar medio conectados. Arreglarlos temprano previene la sensación de “502 aleatorio” durante despliegues.
Ejemplo: deploy rolling sin perder peticiones
Imagina un entorno de producción pequeño: dos instancias Node API (A y B) detrás de un balanceador. Los clientes usan keep-alive, así que una pestaña del navegador puede reutilizar la misma conexión TCP con A durante minutos.
Durante un rolling deploy, el balanceador empieza a enviar peticiones nuevas a B mientras A se reemplaza. El problema es keep-alive: aunque el balanceador deje de escoger A para conexiones nuevas, algunos clientes siguen teniendo una conexión abierta a A y seguirán enviando peticiones por ella.
Ahí es donde aparecen los 502s intermitentes. Si A recibe SIGTERM y sale rápido, esas conexiones reutilizadas apuntan a un proceso que ya no existe. La siguiente petición en ese socket falla y el proxy reporta un 502.
Un apagado ordenado evita esto haciendo tres cosas en orden:
- dejar de aceptar nuevas conexiones en A
- drenar las conexiones keep-alive existentes
- esperar a las peticiones en curso hasta un timeout claro, luego cerrar pools de BD y salir
Para probar localmente o en staging: añade un endpoint lento (por ejemplo, una ruta que espere 10 segundos), envía peticiones repetidas con keep-alive activado y luego reinicia solo una instancia. Si el drenado funciona, la petición lenta termina y no ves 502s intermitentes.
Siguientes pasos: hacer los despliegues aburridos otra vez
El apagado ordenado solo ayuda si puedes verlo funcionar bajo tráfico real. Añade logs de apagado que muestren el orden de eventos: señal recibida, readiness cambiado, dejar de aceptar peticiones, recuento activo de peticiones, drenado de keep-alive, pool de BD cerrado y salida del proceso.
Antes del próximo release, corre una prueba de “petición lenta” en staging: haz un endpoint intencionalmente lento (10–20 segundos) y despliega mientras esa petición está en curso. Quieres dos resultados: la petición lenta termina correctamente y las peticiones nuevas van a la instancia nueva sin errores.
Si la base de código está desordenada o fue generada por IA y los despliegues siguen siendo impredecibles, una auditoría enfocada puede ser más rápida que probar ajustes al azar. FixMyMess (fixmymess.ai) ayuda a equipos a diagnosticar rutas de apagado, drenado de conexiones y problemas de limpieza en apps Node heredadas generadas por IA para que los rollouts dejen de producir 502s sorpresa.