Las apps creadas con IA fallan con usuarios reales: 3 trampas de demo para identificar
Las apps creadas con IA fallan con usuarios reales cuando las demos omiten casos límite. Revisa escenarios de login, correo y pagos, y comprobaciones para endurecer tu app antes del lanzamiento.
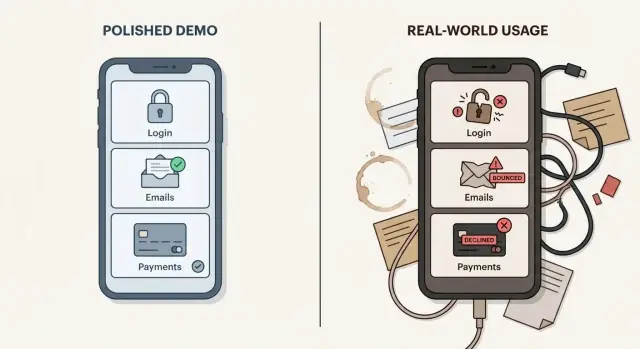
Lo que parece bien en una demo y lo que se rompe en producción
Una demo es un momento controlado. Usas un dispositivo, una cuenta, datos de muestra limpios y un flujo que ya sabes que funcionará. Los usuarios reales hacen lo contrario. Hacen clic fuera de orden, reutilizan enlaces antiguos, escriben mal contraseñas, actualizan en el momento equivocado y lo prueban en teléfonos que nunca testearon.
Por eso las apps creadas con IA fallan con usuarios reales incluso cuando la demo se siente perfecta. Un prototipo a menudo demuestra que una idea es posible, no que sea confiable.
Los usuarios tempranos también se comportan distinto de lo que espera el creador. No leen instrucciones. Se registran con correos laborales, personales y a veces temporales. Abren la app detrás de cortafuegos corporativos. Intentan pagar con tarjetas de distintos países. Y hacen preguntas al soporte el mismo día, porque algo “en vivo” debería simplemente funcionar.
En una demo, “funciona” muchas veces significa “puedo completar el camino feliz una vez”. En producción, “funciona” incluye fiabilidad, seguridad, capacidad de soporte y recuperación. Las acciones clave deben tener éxito repetidamente (incluso con mala conexión). Los datos privados deben permanecer privados. Cuando algo falla, necesitas visibilidad suficiente para entender qué pasó y ayudar rápido. Y necesitas formas seguras de reintentar, revertir o arreglar problemas sin romper el resto.
No necesitas perder la velocidad que te llevó al prototipo. Mantén el mismo flujo, pero añade las comprobaciones poco glamorosas: manejo sólido de errores, logging, límites de tasa, almacenamiento seguro de credenciales y pruebas con datos desordenados.
Por qué los prototipos generados por IA recortan esquinas
El código generado por IA suele optimizarse para “mostrar algo funcionando” lo más rápido posible. Las demos premian el camino feliz: una cuenta, un dispositivo, una red limpia y entradas predecibles. Producción premia lo contrario: resiliencia.
Los prototipos a menudo saltan las partes incómodas. ¿Qué pasa cuando una petición agota el tiempo, una API devuelve una respuesta parcial o dos acciones ocurren al mismo tiempo? En una demo haces clic una vez y sigues. En producción, la gente refresca, envía dos veces, cambia de pestaña, pierde señal y vuelve a intentar.
Otro problema común son las suposiciones ocultas. El código generado por IA puede fijar valores que parecen inofensivos el primer día: un rol de usuario fijo, una sola configuración de entorno, una API key temporal, una moneda o una zona horaria. Funciona localmente y luego se rompe tras el despliegue, el acceso del equipo o el primer cliente real.
La mayoría de piezas faltantes son aburridas, pero evitan que los tickets de soporte se acumulen: manejar timeouts y reintentos, validar entradas con mensajes útiles, lidiar con fallos parciales, eliminar configuraciones y secretos de demo, y añadir logs que apunten a la causa real.
Imagina un flujo simple: un usuario se registra, recibe un correo de confirmación y luego paga. Una demo prueba que los botones funcionan. Producción tiene que demostrar que toda la cadena resiste bajo estrés y falla con gracia cuando algo a monte se rompe.
Escenario 1 - El inicio de sesión funciona una vez y luego los usuarios quedan bloqueados
Un login en demo normalmente sigue el camino más feliz: una cuenta de prueba, tu portátil, un navegador y conexión estable. Inicias sesión, caes en un dashboard y todos asienten.
Los usuarios reales no se comportan así. Inician sesión desde un teléfono y un portátil del trabajo. Olvidan contraseñas. Hacen clic en “Iniciar sesión con Google” en un navegador dentro de la app. Cierran la pestaña, vuelven al día siguiente y esperan seguir conectados.
Muchos bugs de “funciona una vez” vienen de pocos puntos débiles:
- Los callbacks de OAuth son quisquillosos. La URL de callback debe coincidir exactamente, y pequeñas diferencias en los redireccionamientos pueden romper el paso final después de que el proveedor diga “Success”.
- Las cookies y sesiones pueden ser fijadas de una forma que solo funciona en localhost, en un solo navegador o falla con ajustes de privacidad más estrictos.
- Las sesiones expiran, pero la app no se recupera limpiamente, así que los usuarios quedan atrapados en bucles.
Lo que los usuarios reportan casi siempre es vago: “Puedo iniciar sesión una vez, luego deja de funcionar.” Esa frase puede ocultar desde una cookie mal configurada hasta una solicitud cross-site bloqueada o un redirect que pierde el token.
Antes de invitar gente, haz algunas comprobaciones simples (no se requiere tecnología profunda). Inicia sesión en tu teléfono y en un segundo dispositivo y confirma que ambos permanecen conectados. Cierra la pestaña y vuelve en 10 minutos, luego en 24 horas. Prueba restablecer la contraseña y confirma que la nueva contraseña funciona al instante. Prueba una ventana de incógnito y otro navegador. Pide a alguien fuera de tu red que se registre desde su conexión.
Si alguno de esos falla, pausa y diagnostica. La autenticación suele ser el bloqueo que convierte un prototipo “funcional” en algo de lo que los usuarios se van enseguida.
Escenario 2 - Los correos se envían en pruebas, pero nunca llegan a los clientes
En una demo, el correo parece “listo” porque lo pruebas una vez y aparece en tu bandeja. Eso puede ser cierto incluso cuando el sistema no está listo para usuarios reales.
La brecha aparece en el momento en que envías a personas fuera de tu equipo. Los buzones reales filtran agresivamente, y tu dominio tiene una reputación (o ninguna aún). Si SPF, DKIM y DMARC faltan o están mal configurados, muchos proveedores tratan los mensajes como sospechosos. Desde el punto de vista de tu app, el correo “se envió”, pero el usuario nunca lo ve.
Otros puntos débiles son más simples y igual de dolorosos. La dirección del remitente está mal. El nombre “from” activa reglas de spam. Una plantilla se ve bien en un cliente pero se rompe en otro. Los enlaces apuntan a localhost o a un dominio de staging. Si envías un pico (por ejemplo al importar una lista de espera), entran límites de tasa y pierdes mensajes a menos que hagas cola y reintentos.
El impacto en el usuario es inmediato: sin correo de verificación no hay cuenta. Sin restablecimiento de contraseña llegan tickets de soporte. Sin recibo de pago la gente piensa que fue cobrada y no recibió nada, aunque el cargo haya sido correcto.
Antes de culpar a “correo inestable”, revisa lo básico: logs del proveedor (accepted, deferred, rejected), eventos de rebote y queja, alineación SPF/DKIM/DMARC y una prueba en pequeña escala en Gmail, Outlook y Apple Mail. También revisa las plantillas por enlaces rotos y cualquier cosa que parezca de staging.
Un fallo común se ve así: tu registro funciona con tu propia dirección, pero un cliente en Outlook nunca recibe el correo de verificación. Hace clic en “reenviar” cinco veces y tu app lo limita o lo bloquea. A menudo la causa real es entregabilidad más un problema de plantilla, así que incluso correos entregados llevan a callejones sin salida.
Escenario 3 - Los pagos tienen éxito en sandbox, fallan con tarjetas reales
Los pagos en sandbox son amigables por diseño. Las tarjetas de prueba a menudo aprueban y el “camino feliz” luce perfecto. Los bancos reales no se comportan como un sandbox y la app debe manejar resultados desordenados.
Con tarjetas reales aparecen comprobaciones adicionales. Un usuario puede activar 3D Secure y abandonar el flujo. Las verificaciones AVS/CVC pueden fallar si la dirección de facturación difiere ligeramente. Los bancos declinan por razones impredecibles. Suma conversión de divisas, impuestos y reglas regionales, y tu “pagar con un botón” se convierte en un conjunto de ramas.
El fallo más común en producción no es el formulario de pago. Es todo lo que lo rodea, especialmente los webhooks. En una demo es tentador asumir “el pago tuvo éxito” y desbloquear acceso de inmediato. En producción, el evento del webhook es la fuente de la verdad, y puede llegar tarde, llegar dos veces o no llegar si el endpoint está mal configurado.
Vigila estos patrones del día uno:
- Acceso concedido antes de la confirmación, luego el cargo falla o se revierte.
- Webhooks ignorados, así que los usuarios pagan pero su cuenta no se actualiza.
- Falta de idempotencia, de modo que los reintentos crean cargos duplicados.
- Condiciones de carrera entre la página de “éxito” y el procesamiento del webhook.
Los tickets de soporte siguen el mismo guion: un cliente ve “pago fallido”, intenta de nuevo y luego encuentra dos cargos. O recibe acceso aun cuando el pago nunca se completó, lo que genera un caos de reembolsos.
Lo que debes validar antes de que usuarios reales paguen es simple pero innegociable: flujo de webhooks end-to-end, claves de idempotencia en acciones de creación/confirmación y rutas limpias de cancelación y reembolso. Prueba fallos a propósito (CVC erróneo, 3D Secure fallido, tarjeta declinada) y confirma que la base de datos se mantiene consistente.
Paso a paso - Convierte un prototipo en una versión lista para usuarios
Cuando las apps creadas con IA fallan con usuarios reales, rara vez es un gran bug. Son muchas pequeñas brechas que la demo nunca cubre. El camino más rápido es elegir unos pocos recorridos reales y hacerlos aburridamente fiables.
Empieza escribiendo los cinco recorridos de usuario más importantes en lenguaje llano: registrarse, iniciar sesión, verificar correo, restablecer contraseña y pagar. Para cada uno, define qué significa “éxito” para el usuario y qué debe ser verdadero en tu base de datos.
Luego añade logging básico para que puedas responder tres preguntas rápido: qué falló, para qué usuario y por qué. No necesitas dashboards sofisticados en esta etapa, solo migas de pan suficientes para dejar de adivinar.
Una secuencia práctica que funciona para la mayoría de equipos:
- Define los cinco recorridos y una breve lista de verificación de éxito para cada uno.
- Añade logs alrededor de puntos riesgosos (callbacks de auth, envíos de correo, confirmación de pago).
- Prueba casos límite a propósito: contraseña incorrecta, enlace de restablecimiento expirado, red lenta, doble clic en “Pagar”.
- Añade salvaguardas: timeouts, reintentos seguros y mensajes de error que indiquen al usuario qué hacer a continuación.
- Ejecuta un piloto pequeño (5–20 usuarios), luego arregla lo que encuentren antes de invitar a más.
Un cambio pequeño que rinde enseguida: si el restablecimiento de contraseña falla, no muestres “Algo salió mal.” Di al usuario si el enlace expiró, ofrece reenviarlo y registra la razón exacta (token inválido, usuario no encontrado, rechazo del proveedor).
Los riesgos ocultos: seguridad, secretos e integridad de datos
Un prototipo puede sentirse “listo” porque el camino feliz funciona. En producción, muchas fallas son en realidad problemas de seguridad y consistencia de datos que aparecen como “bugs aleatorios”.
Problemas de seguridad que parecen fallos ordinarios
Los equipos no técnicos a menudo experimentan esto como comportamiento inestable: alguien se desconecta, una función funciona para una persona pero no para otra, o los datos “desaparecen”. Bajo el capó puede ser una brecha de seguridad.
Problemas comunes en código generado por IA incluyen secretos expuestos (API keys en repos, bundles de navegador o logs), autorización rota (usuarios pueden acceder a registros de otros cambiando un ID) y riesgos de inyección (entradas concatenadas en consultas sin manejo seguro). Un ejemplo realista: una pantalla de administrador se ve bien en pruebas, pero en producción cualquier usuario autenticado puede cargarla porque la app verifica “está autenticado” y olvida “es admin”.
Integridad de datos: la app funciona hasta que deja de hacerlo
Los problemas de datos son más difíciles de detectar que errores de UI. A menudo solo los ves después de que el uso real crea casos límite.
Atento a acciones duplicadas (doble clic o reintentos creando pedidos duplicados), transacciones faltantes (paso 1 exitoso, paso 2 falla dejando datos a medias) y actualizaciones parciales (la UI dice “guardado” pero solo algunos campos cambiaron).
Trampas comunes que los equipos pasan por alto al lanzar rápido
Una demo premia el camino feliz. Los usuarios reales traen contraseñas olvidadas, conexiones lentas, sesiones expiradas y temporización extraña.
Un error es confiar en el primer éxito. Si probaste login una vez en tu portátil, aún no has probado qué pasa tras un logout, un refresh, un segundo dispositivo o una sesión que expira durante la noche. La app puede parecer estable mientras está a un caso límite de bloquear a la gente.
Otra trampa es posponer funciones de recuperación. Restablecer contraseña, cambiar correo y recuperación de cuenta parecen extras hasta que el primer cliente no puede entrar. Entonces el soporte se vuelve tu producto y parcheas flujos que tocan código sensible a la seguridad bajo presión.
El trabajo de fondo es donde muchos prototipos recortan esquinas. Correos, actualizaciones de pago y sincronización de datos a menudo dependen de webhooks, colas y jobs programados. Si esas piezas faltan o son frágiles, todo parece bien cuando haces clic, pero el estado real del sistema deriva en horas o días.
Algunas trampas recurrentes:
- Una función “funciona una vez” pero falla en el segundo intento porque el estado se guarda en el navegador en lugar del servidor.
- Falta recuperación de cuenta, de modo que un mal intento de login se convierte en un usuario perdido.
- Los eventos de webhook no se manejan por completo, así que reembolsos, pagos fallidos y rebotes nunca actualizan la DB.
- No hay plan de monitoreo, así que te enteras de caídas por mensajes enojados, no por alertas.
- La estructura del código se convierte en espagueti rápido, haciendo que cada arreglo sea arriesgado.
Ejemplo: lanzas una beta paga el lunes. El martes un usuario tiene la tarjeta declinada, pero tu app aún marca el pedido como pagado porque solo chequeó la respuesta inicial del checkout. Para el jueves tu bandeja de soporte está llena y no puedes reproducir el problema porque depende del timing del webhook.
Lista rápida antes de invitar usuarios reales
Antes de enviar invitaciones, haz un pequeño “ensayo con usuario real.” Las demos ocultan lo cotidiano: cambiar dispositivos, olvidar contraseñas, hacer doble clic y usar datos desordenados.
Ejecuta estas comprobaciones en un entorno de staging con dos cuentas (una nueva y una existente). Anota qué pasa y cuánto tarda cada paso.
- Bucle de cuenta: crea una cuenta, confírmala (si es necesario), cierra sesión y vuelve a iniciar en otro dispositivo o perfil de navegador.
- Bucle de restablecimiento de contraseña: solicita un reset, confirma que el correo llega rápido (apunta a menos de 2 minutos) y verifica que el enlace funcione solo una vez.
- Bucle de pagos: prueba un cargo exitoso, una tarjeta declinada, un reembolso y un doble clic en Pagar.
- Revisión de secretos: inspecciona el build frontend y las llamadas de red y confirma que no hay API keys, URLs de BD ni tokens de servicio expuestos al navegador.
- Revisión de visibilidad: fuerza un error (secret de webhook incorrecto, dirección de correo inválida, pago fallido) y confirma que lo ves claramente en los logs con detalle suficiente para actuar.
Una forma práctica de hacerlo: pide a un amigo que siga los pasos sin ayuda. Si se confunde o no puedes diagnosticar fallos rápido, pausa el lanzamiento y cierra esas brechas primero.
Un ejemplo realista de semana de lanzamiento (y cómo recuperarse)
Un fundador monta una app hecha con IA, clava la demo e invita a 50 beta users el lunes. La primera hora se siente bien. Al mediodía los mensajes de soporte empiezan a acumularse.
En el Día 1, tres pequeñas grietas se vuelven problemas reales. Algunos usuarios caen en un bucle de login tras restablecer contraseña porque sesiones y redirecciones se manejaron de forma laxa. Otros nunca reciben el correo de verificación porque la app usó una configuración de envío de prueba que funcionó localmente pero no en buzones reales. Unos pocos pagan, ven una pantalla de éxito y aún no pueden acceder a la zona paga porque la app trata “pago exitoso” y “suscripción activa” como lo mismo.
En el Día 2, el fundador hace arreglos manuales: borra cuentas, cambia flags en la base de datos y pide a los usuarios que lo intenten otra vez. Usuarios confundidos se registran doble, los proveedores de correo empiezan a aplicar throttling y algunos clientes piden reembolso tras ser cobrados pero bloqueados. La app no está “caída”, pero la confianza sí.
Un sprint de reparación enfocado difiere del parcheo aleatorio. La meta es hacer fiables los flujos principales antes de añadir nada nuevo:
- Reproduce fallos end-to-end para los flujos núcleo (login, verificar correo, pagar, desbloquear acceso).
- Arregla causas raíz, no síntomas (tokens, redirecciones, webhooks, verificaciones de estado).
- Añade salvaguardas como límites de tasa, reintentos seguros y mensajes de error claros.
- Vuelve a probar en condiciones reales (cuentas nuevas, buzones reales, tarjetas reales).
- Repite un beta pequeño (5–10 usuarios) antes de abrir las puertas de nuevo.
Luego toma una decisión clara sobre el alcance. Parchea cuando la arquitectura está mayormente sana y los fallos son aislados. Refactoriza cuando el mismo patrón de bug aparece por todas partes. Reconstruye cuando la base de código está demasiado enredada para razonar con seguridad, algo común con prototipos generados por IA.
Próximos pasos - aclara, luego arregla lo correcto primero
Si tu app fue construida con herramientas como Lovable, Bolt, v0, Cursor o Replit, asume que fue optimizada para una demo. Eso no significa que sea mala. Significa que debes esperar atajos en login, correos, pagos y seguridad.
Antes de reescribir nada, aclara qué está fallando realmente. Los equipos pierden semanas reconstruyendo partes equivocadas cuando empiezan por opiniones en vez de evidencia.
Recopila pruebas del uso real y reduce todo a los pocos flujos que importan. Un usuario no puede restablecer contraseña, otro nunca recibe el correo de bienvenida y un tercero ve un error de pago con una tarjeta real. Eso basta para planear el siguiente sprint.
Qué reunir en un pase corto:
- 3–5 reportes de usuarios con pasos exactos (qué hicieron clic y qué esperaban)
- Capturas de pantalla de errores y el texto completo de los mensajes
- Los 3 flujos rotos principales que bloquean registros o ingresos
- Notas sobre dónde ocurre (dispositivo, navegador, hora)
- Acceso a logs o a lo que provea tu host
A partir de ahí, pide diagnóstico antes de una reconstrucción. Una auditoría sólida mapea síntomas a causas raíz (manejo de sesión, configuración de dominio de correo, validación faltante, webhooks no manejados) y ordena los arreglos por impacto.
Si heredaste un prototipo generado por IA que se rompe bajo uso real, FixMyMess (fixmymess.ai) se enfoca en diagnosticar y reparar esas brechas exactas: autenticación, entregabilidad, lógica de webhooks, endurecimiento de seguridad y limpieza que hace el código seguro para enviar. Una auditoría rápida puede convertir “funciona en la demo” en una lista de correcciones priorizada que puedes ejecutar con confianza.
Preguntas Frecuentes
¿Por qué mi app se ve perfecta en una demo pero se desmorona con usuarios reales?
Una demo demuestra el camino feliz una vez, bajo tus condiciones. Producción debe manejar uso repetido, entradas desordenadas, redes lentas, sesiones caducadas, múltiples dispositivos y usuarios que hacen clic en un orden “incorrecto”.
¿Qué debo arreglar primero antes de invitar usuarios reales?
Concéntrate en los recorridos clave que generan confianza e ingresos: registrarse, iniciar sesión, verificar correo, restaurar contraseña y pagar. Haz que cada uno funcione repetidamente y que los fallos sean comprensibles para que el usuario pueda recuperarse sin contactarte.
¿Por qué los usuarios dicen “puedo iniciar sesión una vez, luego deja de funcionar”?
Normalmente es un problema de sesión o de redirección, no solo del botón de iniciar sesión. Las cookies pueden configurarse de forma que funcionen en localhost pero fallen en dominios reales, con distintas políticas de privacidad o navegadores, provocando bucles tras el primer acceso exitoso.
¿Cuál es el error de OAuth más común en apps generadas por IA?
Los proveedores OAuth son estrictos con URLs de callback exactas y el comportamiento de redirección. Una mínima discrepancia entre entornos puede dejar al proveedor en “Success” mientras tu app no completa la sesión, por eso el usuario vuelve a la pantalla de login.
¿Por qué los correos funcionan para mí pero los clientes nunca los reciben?
Enviar no es lo mismo que entregar. Si tu dominio no tiene SPF, DKIM y DMARC configurados, muchos buzones tratarán los mensajes como sospechosos. Resultado: tu app marca “enviado” pero el cliente nunca lo ve.
¿Qué debo revisar en las plantillas de correo antes del lanzamiento?
Suele ser un artefacto de staging: enlaces a localhost o dominios de prueba, o identidad del remitente que dispara filtros de spam. Incluso si el correo llega, un enlace roto o un entorno equivocado lo convierte en un callejón sin salida.
¿Por qué los pagos funcionan en sandbox pero fallan con tarjetas reales?
Los entornos sandbox son permisivos; los bancos reales no. Aparecen rechazos, 3D Secure, verificaciones AVS/CVC y problemas de conversión de divisas o impuestos. Además, los webhooks y la lógica alrededor del pago suelen ser la causa real de fallos en producción.
¿Cuáles son los mayores errores con webhooks que causan caos de facturación?
En producción los webhooks son la fuente de la verdad y pueden llegar tarde, duplicados o no llegar si el endpoint está mal configurado. Si no usas idempotencia y manejo consistente, verás cargos duplicados, usuarios pagados sin acceso o acceso concedido sin pago exitoso.
¿Qué problemas de seguridad se esconden detrás de fallos “aleatorios” en producción?
Los prototipos generados por IA a menudo exponen secretos en el frontend o logs, y cometen errores de autorización que permiten a usuarios ver datos ajenos. Estos problemas pueden parecer fallos aleatorios, pero son fallas de seguridad que pueden volverse graves rápidamente.
¿Cuándo parcheo, refactorizo o reconstruyo, y quién puede ayudar?
Captura suficiente información para responder: ¿qué falló?, ¿para qué usuario?, ¿por qué? Reproduce el fallo de extremo a extremo. Si estás atascado en parches repetidos o el código está demasiado enmarañado, una auditoría focalizada puede mapear síntomas a causas raíz y priorizar arreglos por impacto; FixMyMess puede convertir eso en un plan claro, a menudo en 48–72 horas tras el diagnóstico.