Por qué los arreglos pequeños tardan más que las nuevas funciones en código de IA
Entiende por qué los arreglos pequeños tardan más que las nuevas funciones en código generado por IA: acoplamiento oculto, falta de guardarrailes y cómo acotar el trabajo de forma honesta.
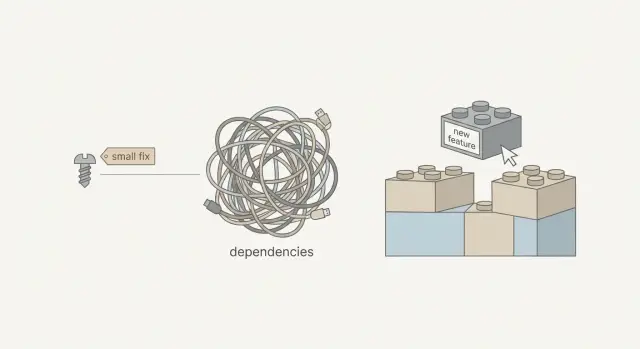
Por qué un “cambio mínimo” puede convertirse en un gran trabajo
Los equipos se llevan la misma sorpresa con prototipos construidos por IA: alguien señala la pantalla y dice, “es solo un pequeño ajuste. Diez minutos.” Luego el arreglo toma medio día (o unos días), y la línea de tiempo empieza a sentirse aleatoria.
Cuando la gente dice “arreglo pequeño”, normalmente se refiere a: cambiar una cosa en un solo lugar, con bajo riesgo y pruebas rápidas.
En el código real, “pequeño” a menudo oculta trabajo adicional:
- “La única cosa” se usa en varios archivos, pantallas o servicios.
- El cambio toca datos que deben guardarse, cargarse, validarse y mostrarse.
- No hay tests, así que tienes que comprobar todo manualmente.
- La solución más segura incluye limpiar problemas cercanos que no planeabas tocar.
Esa discrepancia es la razón por la que arreglar bugs puede tardar más que añadir una nueva función. Las nuevas funciones suelen poder añadirse en los bordes de la app. Los arreglos deben entrar en las rutas que la gente ya usa, lo que significa que necesitas más cuidado y más verificación.
Dos causas aparecen una y otra vez: acoplamiento oculto y ausencia de guardarrailes.
Acoplamiento oculto significa que partes de la app dependen entre sí de formas que no ves desde la UI. Un “renombrado” puede depender silenciosamente de una columna de la base de datos, un validador, una regla de login y una consulta del dashboard, todo mantenido por código copiado.
Faltan guardarrailes quiere decir que el prototipo se saltó barreras que hacen los cambios seguros: manejo claro de errores, valores por defecto sensatos, comprobaciones de entrada y pruebas automáticas básicas. Sin ellos, una edición pequeña puede crear un bug en otra parte.
La idea no es hacer que los arreglos parezcan aterradores. Es hacer que el alcance y las fechas tengan sentido. Cuando puedes señalar el acoplamiento y la falta de guardarrailes, el trabajo deja de parecer arbitrario y pasa a verse como investigación, limpieza y pruebas cuidadosas.
Acoplamiento oculto, explicado sin jerga
El acoplamiento es simple: dos partes de la app dependen una de la otra. Si cambias una parte, la otra puede romperse. Un poco de acoplamiento es normal. Se vuelve problema cuando las conexiones son apretadas, poco claras y dispersas.
Acoplamiento oculto es cuando esas conexiones no son obvias desde lo que ves en la pantalla. Un botón parece “solo UI”, pero afecta login, facturación, emails o reglas de la base de datos porque todo está cableado detrás de escena.
Imagínate una pared de ladrillos donde un solo ladrillo también sostiene una estantería, una lámpara y una tubería. Desde fuera parece un único ladrillo. Lo sacas y tres cosas más se mueven. La reparación no es imposible; solo toma tiempo porque tienes que encontrar qué más sostiene ese ladrillo.
Los prototipos generados por IA suelen tener más acoplamiento oculto porque el código se crea rápido y se reutiliza copiando. En lugar de un lugar claro que defina “reglas de signup”, obtienes varias versiones ligeramente diferentes. Arreglar un bug en un sitio puede dejar otros dos sitios aún rotos, o crear desajustes entre flujos.
Algunas señales de que estás lidiando con acoplamiento oculto:
- La misma lógica aparece en múltiples archivos con pequeñas diferencias.
- Se usa una variable compartida (estado global) en todas partes, por lo que los cambios se propagan.
- Los límites no son claros (código UI edita datos de la base de datos directamente).
- Un arreglo funciona en un flujo pero rompe otro flujo que “no debería estar relacionado”.
- El código está lleno de parches rápidos, como ifs extras para cubrir casos borde.
Cuando esa es la realidad, un “arreglo mínimo” no es un solo edit. Es: encontrar las conexiones ocultas, cambiarlas de forma segura y luego volver a comprobar los flujos que dependían silenciosamente del comportamiento antiguo.
Falta de guardarrailes: las protecciones que los prototipos se saltan
Los guardarrailes son las protecciones del software. No añaden botones nuevos ni funciones llamativas, pero impiden que cambios pequeños se conviertan en caídas sorprendentes.
Los prototipos suelen saltárselos porque la meta es velocidad: hacer que una demo funcione. El coste aparece después, cuando la app se encuentra con usuarios reales, datos reales y casos borde reales.
Guardarrailes comunes que faltan incluyen:
- Comprobaciones automáticas para flujos clave (signup, pagos, guardado de datos)
- Formas de datos claras (para que el código no pueda pasar silenciosamente el tipo de valor equivocado)
- Validación de entrada (para que datos desordenados no crasheen la app)
- Chequeos de permisos (para que usuarios no accedan a lo que no deben)
- Manejo seguro de fallos (timeouts, registros faltantes, estados vacíos)
Sin esto, cada cambio se convierte en un juego de adivinanza. Puedes arreglar lo que ves, pero no puedes tener confianza sobre lo que no ves.
Ejemplo: haces opcional el campo “teléfono” para reducir fricción en el signup. El backend aún asume que el teléfono siempre está presente. Ahora la app falla solo para algunos usuarios, y solo después de que llegan a un paso posterior. El “arreglo pequeño” se convierte en rastrear la suposición, añadir comprobaciones y probar que se mantiene arreglado.
Los guardarrailes cuestan tiempo al principio, así que los equipos los añaden después. Parecen “extra” hasta que aparece el primer bug real en producción. Con reparación de código generado por IA, un enfoque práctico suele ser: arreglar el problema inmediato y luego añadir el guardarraíl más pequeño que evite que la misma clase de bug vuelva la próxima semana.
Por qué el código generado por IA hace que los arreglos “pequeños” sean más arriesgados
Las herramientas de IA te pueden llevar a una demo rápido. La contrapartida es que el código a menudo solo maneja la ruta feliz: la secuencia de clics que la herramienta “imaginó” al generarlo. Un cambio pequeño puede empujar usuarios a caminos que nunca se probaron.
El código generado por IA también puede parecer más acabado de lo que es. Las pantallas se ven pulidas, hay muchos archivos y parece “real”. Debajo puede haber suposiciones frágiles como “este valor siempre existe” o “esta API siempre devuelve la misma forma”. Cuando tu cambio rompe esa suposición, la app falla en otra parte y terminas persiguiendo una reacción en cadena.
La lógica copiada y pegada es otro problema común. “Cambiar la regla de validación” no es un solo edit si esa lógica existe en cinco sitios. Si omites una copia, los usuarios obtienen comportamientos inconsistentes que pueden tardar días en notarse.
También ves flujo de datos poco claro: el mismo dato se transforma varias veces, de diferentes maneras, antes de llegar a la base de datos o la UI. Eso hace que acotar el trabajo sea difícil porque no puedes decir dónde está la fuente de la verdad hasta que la rastreas.
Peticiones típicas de “arreglo pequeño” que se amplían:
- Guardar un campo nuevo, pero la app tiene dos modelos distintos para el mismo objeto.
- Un ajuste de UI cambia el timing y expone una condición de carrera.
- Una limpieza revela secretos expuestos o chequeos de permisos faltantes.
- Aparece un caso borde (estado vacío, red lenta) y los errores no se manejan.
- Un cambio toca auth y el inicio de sesión falla a través de sesiones, redirecciones y callbacks.
Un ejemplo concreto: “Simplemente requiere número de teléfono en el signup.” Eso puede significar actualizar el formulario, la validación, el esquema de la base de datos, los emails o los pasos de onboarding, y asegurarse de que los usuarios existentes no queden bloqueados. Sin tests y manejo claro de errores, cada paso tiene que verificarse a mano.
Si trabajas con código generado por herramientas como Lovable, Bolt, v0, Cursor o Replit, el camino más rápido suele ser: encontrar primero las suposiciones, arreglar la causa raíz una vez y evitar parchear el mismo síntoma en varios sitios.
Cómo acotar un “arreglo pequeño” paso a paso
Cuando alguien dice “es un arreglo pequeño”, se imaginan una línea de código. En proyectos desordenados, una sola petición puede tocar la UI, la API, la base de datos y la autenticación.
Un flujo de acotación que sigue siendo práctico
Haz el problema reproducible. Si no puedes dispararlo bajo demanda, no puedes estimarlo. Anota los clics exactos, las entradas y el resultado esperado, además de lo que realmente ves.
Luego haz un pase rápido de “¿dónde vive esto?”. Muchos bugs parecen de UI pero en realidad son reglas del backend, datos de la base, o casos de auth.
Una lista de comprobación simple que suele ser suficiente:
- Reprodúcelo dos veces y captura los pasos exactos (y cualquier mensaje de error).
- Decide qué capa es la propietaria: frontend, backend, base de datos, auth o terceros.
- Traza los datos de extremo a extremo: dónde empiezan, cómo cambian y dónde terminan.
Una vez que ves el flujo de datos, lista los puntos de contacto: componentes compartidos, endpoints reutilizados, restricciones de la base, estado de login, caching y handlers de webhooks.
Antes de cambiar el comportamiento, añade un pequeño guardarraíl. Puede ser una prueba diminuta, una aserción o incluso un log que demuestre que estás arreglando lo correcto. Ese paso suele evitar que un “parche rápido” se convierta en una segunda emergencia más adelante.
Luego haz el trabajo y verifica los flujos cercanos que comúnmente se rompen: signup, login, pagos, emails y acciones de admin. Finalmente, anota qué cambiaste y qué verificaste para que el siguiente arreglo sea más rápido.
Cómo se ve un “alcance justo”
Un alcance defendible no es solo “arregla el bug”. Es:
- pasos para reproducir
- la capa propietaria
- puntos de contacto afectados
- el guardarraíl que añadirás
- comprobaciones de regresión que ejecutarás
- una nota corta de lo confirmado
Eso te da una línea de tiempo que puedes explicar y defender.
Un ejemplo realista: un ajuste de UI que rompe el signup
Un fundador pide un cambio pequeño: “En el formulario de signup, renombra la etiqueta del campo de ‘Company’ a ‘Business name’.” Parece una edición de UI de cinco minutos. Luego el signup empieza a fallar.
Aquí está el problema: el frontend no solo cambió la etiqueta. También cambió el nombre del campo de company a businessName. El API del backend aún espera company. Cuando el formulario envía, el servidor ve un campo requerido faltante y rechaza la petición.
La ruptura a menudo no se queda ahí. Una vez que ese valor falta, puedes obtener efectos colaterales como validación fallando con un genérico “Algo salió mal”, pasos de onboarding que crashean, emails de bienvenida que renderizan espacios en blanco como “Hola ,” y analíticas que empiezan a agrupar usuarios incorrectamente.
Eso es acoplamiento oculto: una pieza pequeña es dependida silenciosamente por muchas otras piezas. En prototipos generados por IA es común encontrar el mismo nombre de campo reutilizado en varios sitios: un componente de formulario, un validador de esquema, un handler de API, una inserción en la base de datos y un tracker de analíticas. Ninguno de esos lugares “anuncia” la dependencia.
La falta de guardarrailes empeora la situación. Si no hay tests de signup, nadie lo nota hasta después del despliegue, cuando usuarios reales golpean la ruta rota. Ahora el “cambio pequeño” incluye depurar comportamiento en producción, revisar logs y confirmar qué datos se escribieron (o no) en la base de datos.
Un plan que mantiene esto seguro suele verse así:
- Traza el campo de extremo a extremo (UI, validación, API, base de datos, tracking).
- Parchea con un contrato estable (mantén
company, o mapeabusinessNamea él). - Añade un guardarraíl simple (al menos una prueba o una comprobación en servidor con un error claro).
- Verifica el flujo completo en un entorno limpio (usuario nuevo, onboarding, email, analíticas).
- Lanza y monitoriza brevemente por sorpresas.
Errores que hacen que los arreglos se prolonguen
El mayor sumidero de tiempo es tratar un arreglo como si viviera en un solo lugar. En prototipos construidos por IA, el problema visible suele ser solo la última ficha del dominó.
Una trampa común es arreglar el síntoma en la UI mientras la causa real está en el manejo de datos o la autenticación. Un botón puede parecer “roto” porque la llamada API falla, pero el problema real es un rol faltante, una sesión expirada o un registro que nunca se guardó correctamente.
Los parches rápidos también generan deuda rápido. Un caso especial extra puede funcionar hoy, pero hace más difícil el cambio de mañana. Terminas con código lleno de excepciones que nadie confía.
Patrones que suelen extender el trabajo más de lo esperado:
- Probar solo la pantalla tocada, no flujos relacionados como onboarding, restablecimiento de contraseña, facturación o roles de admin.
- Cambiar cómo luce la data (nombres de campos, tipos, campos requeridos) sin actualizar validación y migraciones de base de datos.
- Saltarse checks de seguridad porque “funcionó localmente”, y luego descubrir secretos expuestos, cheques de auth débiles o entradas no seguras.
- Arreglar un endpoint o consulta sin comprobar dónde más se reutiliza.
- Añadir lógica “temporal” que nunca se quita.
Lista de comprobación antes de prometer una fecha
Un arreglo solo se mantiene pequeño cuando todos están de acuerdo en qué está roto, dónde está roto y qué significa “hecho”.
Empieza confirmando que el problema es reproducible. Si solo aparece “a veces” o solo en un portátil, no estás listo para prometer una fecha. Apunta a 2–3 pasos claros que lo desencadenen consistentemente.
A continuación, sé explícito sobre la capa propietaria. El mismo síntoma puede venir de sitios distintos: UI, API, base de datos o auth. “El login no funciona” podría ser una configuración de cookies, un chequeo de sesión faltante o un registro de usuario que nunca se guardó.
Antes de que nadie toque el código, acuerda una comprobación que pruebe el arreglo y lo detecte si vuelve. Puede ser una pequeña prueba automatizada, un script manual repetible o un check de logs que confirme que corre la ruta correcta.
También señala efectos secundarios probables. Tres suele ser suficiente para mantener el alcance honesto:
- Si cambiamos esta validación, ¿podría bloquear el signup?
- Si ajustamos esta consulta, ¿podría ralentizar el dashboard?
- Si cambiamos reglas de auth, ¿podría desconectar a usuarios existentes?
Finalmente, decide qué significa rollback si producción se vuelve inestable. No necesita ser sofisticado, pero debe ser real: revert rápido, feature flag o una forma segura de restaurar el comportamiento anterior.
Si estás heredando código generado por IA y estas respuestas son difíciles de obtener, incluye tiempo de descubrimiento en la estimación. Eso no es inflar tiempos; es el trabajo necesario para cambiar suposiciones por evidencia.
Cómo explicar el alcance para que parezca justo
Cuando alguien pide un “arreglo pequeño”, se imagina una edición rápida. Un alcance justo separa el cambio visible del trabajo necesario para hacerlo seguro.
Explica las incógnitas como comprobaciones concretas, no como excusas. Por ejemplo: “Antes de cambiar el comportamiento del botón, necesitamos confirmar dónde se define ese comportamiento, qué más lo usa y qué lo detectará si se rompe.” Eso es investigación, no dilación.
Los timeboxes ayudan porque crean un punto de decisión claro:
- Descubrimiento: trazar dónde vive el cambio, mapear dependencias, detectar preocupaciones de seguridad
- Implementación: hacer el cambio con el menor radio de impacto
- Verificación: probar flujos clave y los casos borde riesgosos
Luego fija criterios de aceptación en términos de usuario, no de código. “Arreglado” debe significar algo que alguien pueda observar:
- El usuario puede iniciar sesión, completar la acción y ver el resultado correcto.
- Flujos clave no lanzan errores nuevos (signup, compra, páginas admin).
- Los permisos siguen funcionando (los usuarios no ven datos de otros usuarios).
- No se exponen secretos y no se introducen fallos de seguridad evidentes.
Cuando tengas opciones, preséntalas claramente: un arreglo mínimo ahora (más rápido, mayor riesgo de regresiones) o un arreglo más seguro que añada guardarrailes como validación, checks de permisos y pruebas básicas.
Siguientes pasos si tu prototipo de IA sigue dándote guerra
Si cada “pequeño cambio” desencadena otra rotura, para antes de añadir más funciones. Ese patrón suele significar que el código está enredado: tiras de un hilo y otra cosa se tensa.
Decide: arreglo rápido, refactor o reconstrucción
Un “arreglo” se convierte en refactor cuando el código necesita limpieza solo para hacer cambios de forma segura. Fíjate en señales como bugs recurrentes, un cambio que rompe pantallas no relacionadas (login, checkout, admin), miedo a tocar el código, límites poco claros y faltas de seguridad básicas (secretos en el código, auth débil, llamadas inseguras a la base de datos).
A veces una reconstrucción sale más barata que parches interminables. Si cada semana aparece una nueva sorpresa o los problemas de seguridad siguen surgiendo, reconstruir el flujo central puede costar menos que meses de whack-a-mole.
Reúne la información correcta antes de pedir ayuda
Puedes ahorrar horas enviando un “paquete de bug” claro en vez de una petición vaga:
- Acceso al repo (o un zip) y notas del entorno (keys, servicios, dónde corre)
- Pasos exactos para reproducir, empezando desde una sesión limpia
- Capturas de pantalla o un corto video de la pantalla
- Resultado esperado vs. lo que ocurre realmente
- Cualquier texto de error que veas (copiar/pegar)
Añade una frase sobre qué cambió más recientemente. En proyectos generados por IA, eso suele apuntar directamente al acoplamiento oculto.
Si quieres que un equipo externo revise, FixMyMess (fixmymess.ai) empieza con un diagnóstico del codebase y ofrece una auditoría de código gratuita para apps generadas por IA. Es una forma directa de identificar qué está realmente conectado a tu “cambio mínimo” antes de comprometer un plazo.
Preguntas Frecuentes
¿Por qué mi “ajuste de 10 minutos” se convirtió en un arreglo de medio día?
Una petición de UI “pequeña” suele cambiar nombres de datos, reglas de validación o el payload de una API detrás de escena. Si ese valor se usa en varios sitios, tienes que actualizar todos ellos y luego volver a comprobar los flujos que dependen de ello.
¿Qué significa realmente “acoplamiento oculto”?
El acoplamiento oculto significa que partes de tu app dependen entre sí de formas que no son evidentes desde la pantalla. Cambias una cosa y algo “no relacionado” se rompe porque la misma lógica o dato se comparte silenciosamente en otra parte.
¿Por qué el código generado por IA tiene más probabilidad de tener acoplamiento oculto?
Los prototipos generados por IA con frecuencia copian lógica similar en varios archivos en vez de crear una única fuente de verdad. Eso hace que el comportamiento sea inconsistente y obliga a buscar cada copia antes de que el arreglo sea real.
¿Qué son los “guardarrailes” y por qué importan para cambios pequeños?
Los guardarrailes son protecciones básicas como validación de entrada, checks de permisos, errores claros y unas pocas pruebas automatizadas para flujos clave. Sin ellos, cada cambio se convierte en investigación manual más verificación extra para evitar fallos sorpresa.
¿Cuál es la forma más rápida de hacer un bug “escalable” antes de que alguien empiece a codificar?
Pide pasos exactos para reproducir desde una sesión nueva, el resultado esperado y lo que realmente ocurre (incluido el texto completo del error). Si el bug no puede dispararse bajo demanda, cualquier estimación es una conjetura.
¿Por qué renombrar un campo del formulario puede romper el signup?
Un cambio de nombre puede cambiar la clave del campo (por ejemplo company a businessName), no solo la etiqueta. Si el backend o la base de datos aún espera la clave antigua, la petición falla y pasos posteriores como emails de onboarding o analíticas también pueden romperse.
¿Por qué los arreglos de bugs pueden tardar más que desarrollar una nueva función?
Las nuevas funcionalidades a menudo se añaden en los bordes de la app sin tocar el comportamiento existente. Los arreglos de bugs suelen entrar en rutas que los usuarios ya usan, por lo que requieren más trazado, más cuidado y más comprobaciones de regresión.
¿Cómo averiguo si un bug es de frontend, backend, base de datos o auth?
Empieza por identificar la capa propietaria: frontend, backend, base de datos, auth o un servicio de terceros. Luego traza los datos de extremo a extremo para saber dónde empieza el valor, dónde cambia y dónde se usa.
¿Cuál es el guardarraíl más pequeño que vale la pena añadir durante un arreglo?
Añade la menor protección segura: una prueba enfocada para el flujo roto, una comprobación en el servidor con un error claro, o un log que confirme que corre la ruta correcta. El objetivo es impedir que la misma clase de bug vuelva la próxima semana.
¿Cuándo deberíamos refactorizar frente a reconstruir un prototipo generado por IA?
Considera reconstruir cuando los cambios sigan rompiendo pantallas no relacionadas, falten bases de seguridad y nadie tenga confianza de tocar el código. Si heredaste una app generada por IA que no se comporta en producción, FixMyMess puede diagnosticarla rápido y ayudar a reparar o reconstruir los flujos principales en un plazo predecible.