Auditoría de costos para prototipos generados por IA: reduce gasto en API y BD
La auditoría de costos para prototipos generados por IA te ayuda a identificar endpoints, consultas y jobs que inflan la factura, y a corregir las principales fugas rápidamente.
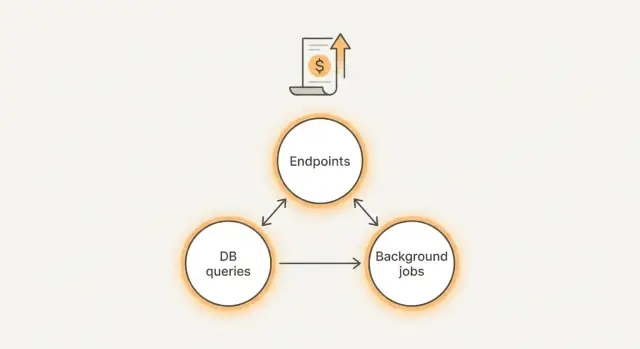
¿Qué está realmente impulsando tu factura?
Muchos prototipos generados por IA se vuelven caros por una razón simple: funcionan bien en demos, pero desperdician dinero en segundo plano. Los generadores de código suelen duplicar llamadas, omitir caché y añadir "ayudantes" de polling que no paran nunca. No lo notas hasta que llegan usuarios reales o algunos testers dejan la app abierta todo el día.
La mayor parte del gasto inesperado viene de tres sitios:
- Endpoints: una pantalla dispara demasiadas llamadas API, reintentos o respuestas sobredimensionadas.
- Consultas: consultas a la base de datos lentas o sin límites que escanean muchos más datos de los necesarios.
- Tareas en segundo plano: cron jobs, workers de cola y webhooks que corren con demasiada frecuencia o no se detienen.
El gasto “bueno” es aburrido. Es predecible y se mueve con la actividad real del producto. Si tienes 10x más usuarios activos, los costos pueden subir, pero el salto tiene sentido. El gasto “malo” crece cuando nadie está haciendo nada, o cuando una función silenciosamente dispara cientos de llamadas.
Si solo tienes 30 minutos, mide las pocas cosas que revelan problemas rápido:
- Endpoints principales por conteo de solicitudes y tamaño medio de respuesta
- Consultas de base de datos más lentas y más frecuentes
- Tareas en segundo plano por frecuencia de ejecución y tiempo medio de ejecución
- Llamadas a APIs de terceros por endpoint y tasa de error o reintentos
- Gasto base durante las horas de “nadie lo está usando”
Una comprobación rápida ayuda: abre la app, realiza una acción normal (como cargar un dashboard) y observa qué se dispara. Si esa sola acción lanza 20 solicitudes, tres consultas largas y un pico en la cola de jobs, ya encontraste por dónde empezar.
Vincula el gasto a funciones reales (no a un vago "uso")
Los dashboards que muestran “llamadas API” o “lecturas BD” no te dicen qué arreglar. Esto se facilita cuando traduces el gasto en acciones reales que hace un usuario.
Haz un mapa simple de costos
Anota el puñado de acciones que pueden costar dinero, y trata todo lo demás como sospechoso hasta que se demuestre necesario. Para muchos prototipos:
- Registro e inicio de sesión (email, SMS, OAuth)
- Búsqueda y filtros
- Chat o generación de contenido
- Informes y exportes
- Subida y procesamiento de archivos
Adjunta una expectativa aproximada a cada acción: “Un mensaje de chat debería costar menos de X”, o “La ejecución de un informe debería tardar menos de Y segundos”. No necesitas números perfectos. Necesitas objetivos que hagan obvio el desperdicio.
Luego separa los costos impulsados por el usuario de los costos siempre activos.
Los costos impulsados por el usuario ocurren solo cuando alguien hace clic. Los siempre activos corren aunque nadie use la app: cron jobs, workers, polling en segundo plano, reintentos automáticos y “health checks” que golpean endpoints caros. Los costes siempre activos suelen ser la victoria más rápida porque pueden quemar dinero 24/7.
También revisa qué entorno está gastando dinero. Las apps creadas con IA a menudo apuntan dev o staging a los mismos servicios pagos que producción, o dejan workers de prueba corriendo por la noche. Si no puedes decir claramente “este costo es prod”, asume que parte no lo es.
Define tu objetivo antes de tocar el código:
- Cortar 20% esta semana (apagar los mayores desperdicios)
- Cortar 80% este mes (retrabajar arquitectura, caché y acceso a datos)
Un patrón común: una función de “reporte” se usa una vez al día, pero una tarea en segundo plano la genera cada 5 minutos para cada cuenta. El dashboard muestra “alto uso de BD”, pero el problema real es una función que nadie pidió ejecutándose constantemente.
Paso a paso: inventario de endpoints, consultas y tareas
El objetivo es dejar de adivinar. Quieres un mapa de cada lugar donde tu app gasta dinero, vinculado a solicitudes reales y trabajo real.
Elige un día normal de tráfico y trátalo como tu línea base. Si no tienes mucho tráfico aún, usa un día de pruebas internas donde ejercites los flujos principales (registro, checkout, búsqueda, chat, subidas). Guarda esta línea base para comparar después de los cambios.
Crea un inventario de una página
Recorre la app en tres cubos: endpoints, consultas de base de datos y trabajo en segundo plano.
- Endpoints
- Lista cada ruta API (incluyendo rutas internas) y anota quién la llama: navegador, app móvil, cron job, webhook u otro servicio.
- Añade volumen aproximado y latencia. Números exactos son geniales, pero “alto/medio/bajo” y “rápido/lento” basta para localizar los primeros problemas.
- Consultas
- Para cada endpoint, captura las consultas de BD principales que dispara.
- Muestra ejemplos desde logs, tracing o la vista de consultas lentas de tu BD, y anota la forma de la consulta (tablas tocadas, filtros, joins).
- Trabajo en segundo plano
- Anota cada job programado, handler de webhook y worker de cola.
- Incluye con qué frecuencia corre y qué hace (sync, email, embeddings, limpieza).
Mantén todo ligado al día base para estimar el costo por 1.000 solicitudes o por usuario activo.
Con la lista en mano, los patrones saltan: un endpoint se llama en cada carga de página, una consulta “pequeña” escanea una tabla grande, o un job corre cada minuto aunque nada cambie.
Endpoints que silenciosamente se vuelven caros
Algunas de las mayores fugas se esconden en endpoints “normales” que se llaman todo el día. A menudo el backend no es caro por solicitud. Es caro porque la misma solicitud ocurre cientos o miles de veces.
Un culpable común es el polling: el frontend comprueba actualizaciones cada pocos segundos, incluso cuando nada cambia. Los bucles de refresco también ocurren por accidente, por ejemplo cuando una re-renderización dispara otra fetch, o cuando dos componentes llaman el mismo endpoint sin saberlo. Si los usuarios dejan una pestaña abierta, ese bucle silencioso se convierte en un medidor constante.
Otro patrón es un endpoint que hace demasiado trabajo por solicitud. El código generado por IA puede agrupar múltiples búsquedas, joins extra o procesamiento de archivos en una sola ruta “por conveniencia”. Funciona en una demo, pero cada llamada desencadena una cadena de consultas y llamadas a APIs de terceros.
Las rutas de solo lectura se vuelven caras cuando no hay caché. Si un endpoint devuelve los mismos datos para muchos usuarios (precios, configuraciones, lista de plantillas), pagas repetidamente por lecturas idénticas.
Los reintentos multiplican el costo rápidamente. Si los timeouts son muy cortos o faltan límites de tasa, los clientes pueden reintentar agresivamente. Terminas pagando dos (o más) veces por la misma acción.
Algunas señales de que un endpoint merece atención primero:
- Se llama por temporizador (polling) o en cada pulsación de tecla
- Dispara múltiples llamadas downstream (BD más APIs externas)
- Devuelve la misma respuesta a menudo pero no tiene caché
- A veces se agota y los clientes reintentan automáticamente
- No tiene límite de tasa, así que los picos se convierten en aumentos caros
Ejemplo: un endpoint /messages en un prototipo de chatbot se llama cada 2 segundos para verificar nuevas respuestas. Además, recalcula el contexto de la conversación y toca la base de datos varias veces. Arreglar la frecuencia de llamadas y mover trabajo pesado fuera de la petición puede reducir el gasto inmediatamente.
Consultas que disparan el costo de la base de datos
El gasto en BD a menudo proviene de unas pocas consultas que se ejecutan mucho más de lo que piensas. El código generado por IA puede ocultar ineficiencias detrás de un ORM, así que la app parece bien en pruebas pero se vuelve cara con tráfico real.
Uno de los culpables más grandes es el patrón N+1: obtienes una lista de ítems y luego el código busca datos relacionados fila por fila dentro de un bucle. Una página que muestra 50 pedidos puede convertirse en 51 consultas (o 201 si cada pedido trae cliente y artículos), y cada refresco repite el trabajo.
Los índices faltantes son otro multiplicador común. Si filtras por campos como user_id, created_at o status, o haces joins en claves foráneas, la BD no debería escanear toda la tabla cada vez. Cuando falta el índice, los costos suben al crecer los datos, así que empeora con el tiempo.
También vigila consultas que traen demasiado. Seleccionar todas las columnas, cargar blobs JSON grandes o devolver miles de filas cuando la UI solo muestra las primeras 20 desperdicia CPU, memoria y red. Búsquedas, feeds de actividad y tablas de admin son infractores frecuentes, especialmente cuando se olvida la paginación.
Cinco comprobaciones que suelen encontrar los peores picos:
- Busca lecturas repetidas dentro de bucles (N+1) en logs o trazas
- Verifica que existan índices para filtros habituales y claves de join
- Selecciona solo columnas necesarias, no
SELECT * - Añade paginación y límites duros para scroll y búsqueda
- Confirma que el pool de conexiones esté configurado, para no abrir una conexión BD por solicitud
Ejemplo: un prototipo de chatbot almacena mensajes y “carga los últimos 5.000” en cada vista de página para construir contexto. Cambiarlo por los últimos 30 mensajes, indexar conversation_id y agrupar búsquedas relacionadas puede reducir la carga de BD rápido.
Tareas en segundo plano que corren más de lo que crees
Las tareas en segundo plano son una razón común por la que un prototipo IA parece barato en pruebas y luego caro en producción. Corren cuando nadie usa la app y suelen tocar las partes más costosas: APIs externas, tu base de datos y el almacenamiento de archivos.
Empieza listando cada job que corre por temporizador y escribe su programación en lenguaje claro. “Cada minuto” y “cada 5 minutos” son asesinos de presupuesto, especialmente cuando el job llama APIs pagas o escanea tablas grandes.
Luego busca jobs que se ejecutan aunque no haya trabajo. Un ejemplo típico es una tarea de “sync” que comprueba datos nuevos pero aun así trae miles de filas o llama a una API cuando no ha cambiado nada. Guardas simples antes de las partes caras suelen ser suficientes para detener la fuga.
El comportamiento de fan-out es otro multiplicador silencioso. Un job programado puede encolar un trabajo por usuario, por workspace o por registro. Si corre cada hora y tienes 2.000 usuarios, de repente ejecutas 48.000 jobs al día.
Algunas correcciones que suelen recortar gasto rápidamente:
- Añadir una comprobación de “no hay trabajo” (longitud de cola, timestamp de última actualización o un conteo barato) antes de cualquier consulta o llamada API costosa
- Limitar el fan-out con batching (procesa 100 registros a la vez) y backoff cuando el sistema esté ocupado
- Hacer jobs idempotentes para que los reintentos no repitan trabajo caro (usar una clave única o un marcador de procesado)
- Poner conteos y duraciones en logs: ítems procesados, llamadas API realizadas, filas escaneadas, tiempo total de ejecución
Cómo elegir las pocas correcciones que cortan gasto rápido
Una auditoría sólo importa si se convierte en un plan corto y enfocado. El objetivo no es dejar todo perfecto. Es eliminar los pocos puntos calientes que generan la mayor parte de la factura.
Para cada cambio candidato, anota dos cosas: qué tan difícil es y cuánto podría ahorrar. Manténlo ligero para decidir rápido.
- Añadir límites de request a endpoints costosos (poco esfuerzo, alto ahorro)
- Cachear respuestas de lectura intensiva por 60 segundos (poco esfuerzo, ahorro medio a alto)
- Añadir un índice de BD a una consulta principal (esfuerzo medio, alto ahorro)
- Reducir la frecuencia de polling en un worker o UI (poco esfuerzo, ahorro medio a alto)
- Refactorizar un módulo entero (esfuerzo grande, ahorro incierto)
Prioriza correcciones que reduzcan uno de estos impulsores:
- Número de llamadas API (menos requests, menos reintentos, respuestas más pequeñas)
- Filas escaneadas (consultas más rápidas, menos scans de tabla completa)
- Frecuencia de jobs (menos polling, menos ejecuciones programadas)
Los guardarraíles rápidos suelen ganar primero. Pon un tope a patrones abusivos (rate limits, timeouts, tamaño máximo de página). Añade caché donde los datos no cambian cada segundo. Para trabajo en segundo plano, pasa de “comprobar cada minuto” a “ejecutar cuando sea necesario” o a un cron menos frecuente.
Usa una regla clara de parada: lanza 2–3 cambios, luego vuelve a medir por un día (o un ciclo de negocio normal). Si no ves una caída significativa, vuelve al inventario. Los grandes reescritos son tentadores, pero a menudo fallan en encontrar el verdadero motor de costo.
Ejemplo: si un chatbot prototipo reenvía la conversación completa en cada mensaje, un cambio pequeño como resumir los mensajes antiguos o limitar el historial puede reducir el gasto en tokens más rápido que reconstruir toda la función de chat.
Ejemplo: un prototipo de chatbot con costos desbocados
Un caso común: un prototipo de Lovable o Bolt con una pantalla de chat simple y un dashboard de “uso” e “historial”. Funciona en demos, pero la factura crece más rápido que el número de usuarios.
Aquí está el patrón. Cada carga de página dispara varias llamadas a IA “por si acaso” (resúmenes, prompts sugeridos, sentimiento, generación de títulos). Al mismo tiempo, el dashboard ejecuta escaneos completos de tabla para recalcular estadísticas desde cero. Unos pocos testers activos generan cientos de llamadas por hora y la base de datos comienza a realizar lecturas pesadas que parecen picos aleatorios.
A menudo hay un culpable principal: un endpoint de chat que repite trabajo de embeddings en cada mensaje, a veces más de una vez por petición. Puede embedear el texto del usuario, volver a embedear los últimos N mensajes y re-embedear los mismos fragmentos de la base de conocimiento porque nada está en caché. Si el endpoint además guarda todo y luego consulta “todos los mensajes de este usuario” sin límites, el costo de consultas crece con cada conversación.
Las correcciones que recortan gasto suelen ser aburridas pero efectivas:
- Desacoplar triggers en la UI para que una acción de usuario haga una solicitud, no cinco
- Cachear embeddings y reusarlos cuando el texto no cambió
- Añadir paginación y límites al historial de mensajes y tablas del dashboard
- Mover trabajo “agradable de tener” (títulos, resúmenes) a jobs programados que corran menos a menudo
- Añadir guardas: timeouts, tokens máximos y límites por usuario
El resultado esperado es menos llamadas por acción de usuario y una curva de costos más plana. Tras estos cambios deberías poder predecir el gasto según usuarios activos, en lugar de sorprenderte por una tarde muy ocupada.
Errores comunes a evitar durante una auditoría de costos
Una auditoría puede desviarse si la tratas como un ejercicio de hoja de cálculo en vez de una búsqueda de las pocas cosas que generan la mayor parte de la factura. El objetivo no es la medición perfecta. Es ahorro rápido y seguro.
Una trampa es recopilar montones de métricas y pasar por alto lo obvio. Los equipos rastrean cada ruta, cada tabla, cada dashboard y luego no actúan sobre los peores responsables. En la práctica, tus 5 endpoints principales y 5 consultas principales suelen explicar la mayor parte del gasto.
Otro error es arreglar la capa equivocada. Puedes optimizar una consulta lenta, pero si un job la llama cada minuto (o se ejecuta dos veces por reintentos), la factura no bajará. Confirma siempre qué dispara el trabajo: acciones de usuario, cron, webhooks, reintentos o workers de cola.
Vigila estos patrones de fallo:
- Desactivas una función para cortar costos, pero el problema real era un bucle de llamadas accidental o un cliente que hace polling demasiado frecuente
- Ajustas una consulta mientras un job de exportación o sincronización ejecuta la misma consulta miles de veces
- Persigues ahorros y rompes la corrección (datos parciales, escrituras faltantes, caché obsoleta)
- Omites verificaciones básicas de seguridad y publicas secretos expuestos, auth débil o riesgos de inyección
- “Arreglas” el costo bajando límites sin abordar por qué la app llega a esos límites
Ejemplo: una función de “notificaciones” parece cara, así que se desactiva. Más tarde descubres que el culpable real era un worker que reenvió el mismo lote porque el job nunca guardó su checkpoint.
Lista rápida: antes y después de cambiar algo
Trata esto como un pequeño experimento: mide primero, cambia una cosa, mide de nuevo. Si no, corres el riesgo de “ahorrar dinero” en papel mientras rompes el inicio de sesión, ralentizas páginas o provocas reintentos que cuestan más.
Elige un día base (o una ventana típica de 24 horas) y anota tus números en un solo lugar: gasto total en API, gasto en BD y gasto en workers, más algunos responsables principales.
Antes de cambiar código, asegúrate de poder responder:
- ¿Cuáles son los 3 endpoints principales por costo y por volumen (solicitudes)?
- ¿Cuáles son las 3 consultas principales por tiempo total o filas escaneadas?
- ¿Tienes una lista completa de jobs programados, colas y tareas cron, más la frecuencia con la que corren?
- ¿Grabaste números “antes” para una ventana base (gasto, latencia, tasa de errores, reintentos)?
- ¿Sabes cómo se ve “bien” para los usuarios (tiempo de carga, tiempo a la primera respuesta, tasa de checkout o inicio de sesión exitoso)?
Después de los cambios, vuelve a revisar la misma ventana y añade dos verificaciones: reintentos y experiencia de usuario. Una trampa común es reducir cómputo por solicitud pero introducir errores 500, timeouts o fallos de auth que disparan reintentos automáticos. Un endpoint roto puede duplicar tráfico y costos sin usuarios nuevos.
Verifica también que no hayas movido el costo a otro lado (por ejemplo: menos llamadas API pero consultas de BD más pesadas, o menos lecturas BD pero más trabajos en segundo plano).
Siguientes pasos si tu prototipo IA es difícil de desenredar
Si tu auditoría dice “todo es caro”, el problema suele ser el código, no la nube. Los proyectos generados por IA a menudo llegan con routing enredado, lógica duplicada y reintentos ocultos. Antes de optimizar línea por línea, haz un diagnóstico corto para mapear qué corre en producción y cómo fluyen las solicitudes.
Empieza por encontrar puntos calientes. Si sólo hay 1–3 culpables claros (un endpoint ruidoso, una consulta lenta, un job sobreactivo), parchear suele ser la victoria más rápida. Si encuentras una docena de problemas medianos repartidos por muchos archivos, gastarás más persiguiendo síntomas y un pequeño refactor suele ser más barato.
Una regla simple:
- Parchea cuando la corrección sea aislada y testeable (limitar un endpoint, añadir caché, arreglar un N+1)
- Refactoriza cuando el mismo patrón de bug se repite (carga de datos copiada, múltiples endpoints haciendo lo mismo, jobs que se disparan entre sí)
- Reconstruye cuando lo básico está roto (auth poco fiable, secretos expuestos, arquitectura que impide cambios seguros)
Si traes ayuda externa, la transferencia importa más que largas explicaciones. Lleva un día base (24 horas normales de tráfico) y un paquete corto de hechos:
- Lista de endpoints con conteos de solicitudes y los peores responsables
- Consultas principales con tiempo medio y frecuencia
- Lista de jobs en segundo plano con cronogramas y conteos reales de ejecución
- Notas de deploy recientes (qué cambió cuando el gasto subió)
Si el código vino de herramientas como Lovable, Bolt, v0, Cursor o Replit y es difícil trazar qué llama a qué, FixMyMess (fixmymess.ai) puede hacer una auditoría de código gratuita para mapear endpoints, consultas y jobs antes de tocar nada. A partir de ahí, el foco es la remediación: reparación lógica, endurecimiento de seguridad, refactor y preparación para despliegue para que el prototipo se comporte como software de producción, no como una demo.
Preguntas Frecuentes
Mi factura del prototipo IA es alta—¿qué debo revisar primero?
Empieza por comprobar qué sigue gastando dinero cuando nadie está usando activamente la app. Compara una ventana tranquila durante la noche con una hora de mucha actividad y busca un pequeño conjunto de puntos calientes: unos pocos endpoints con conteos de solicitudes muy altos, unas pocas consultas de base de datos que dominan el tiempo total, y cualquier tarea en segundo plano que corra con mucha frecuencia. Si los costos no bajan en las horas «sin uso», la victoria más rápida suele ser el trabajo siempre activo, no las funciones de usuario.
¿Cómo establezco una línea base antes de empezar a cambiar código?
Elige un periodo de 24 horas representativo y registra los números que puedas volver a comprobar: gasto total en API, gasto en base de datos y gasto en workers en segundo plano, además de los principales responsables por volumen y latencia. La idea no es una contabilidad perfecta, sino tener una instantánea “antes” para saber si los cambios realmente redujeron el costo en lugar de moverlo a otro sitio.
¿Cómo vinculo el gasto en la nube a una función real en vez de métricas vagas?
Traduce “uso” en acciones reales de usuario como cargar un dashboard, enviar un mensaje de chat, generar un reporte o subir un archivo. Luego observa qué dispara cada acción en producción: solicitudes lanzadas, consultas ejecutadas, picos de jobs y llamadas a terceros. Cuando una acción simple provoca una cadena de trabajo sorprendente, ahí tienes qué arreglar.
¿Por qué el polling hace explotar los costos incluso con pocos usuarios?
El polling suele parecer inofensivo porque cada petición es pequeña, pero corre constantemente y se multiplica entre pestañas abiertas y usuarios. Si la UI consulta cada pocos segundos por actualizaciones que rara vez cambian, el gasto crece aun cuando el producto está “inactivo”. La solución habitual es reducir o eliminar el polling y sólo obtener datos cuando algo cambie o cuando el usuario lo solicite explícitamente.
¿Cómo incrementan silenciosamente mi gasto los reintentos y los timeouts?
Los reintentos pueden duplicar o triplicar tu factura porque pagas el mismo trabajo varias veces. Esto ocurre cuando los timeouts son demasiado agresivos, los errores no se manejan bien o los clientes reintentan automáticamente sin límites. Normalmente se arregla usando timeouts razonables, añadiendo límites de tasa, haciendo las peticiones idempotentes y evitando que llamadas fallidas disparen trabajo costoso downstream repetidamente.
¿Qué es el problema N+1 y cómo lo detecto?
El patrón N+1 ocurre cuando tu código obtiene una lista y luego consulta datos relacionados uno por uno dentro de un bucle. Puede parecer bien con datos de prueba pequeños, pero escala terriblemente y se vuelve caro rápido. La solución práctica es agrupar esas consultas para que una carga de página no genere decenas o cientos de consultas separadas.
¿Cuándo es añadir un índice de base de datos la mejor solución para el costo?
Si filtras o haces joins por campos como user_id, created_at o status y la BD termina escaneando toda la tabla cada vez, verás consultas lentas que empeoran al crecer los datos. Añadir el índice correcto suele dar una caída directa y medible en tiempo de consulta y uso de CPU. La clave es indexar lo que tus endpoints principales realmente filtran y unen, no lo que “parece” importante.
¿Por qué las tareas en segundo plano causan gasto “inactivo” durante la noche?
Porque las jobs corren aunque nadie use la app y suelen tocar las partes más caras de tu stack: base de datos, APIs de pago y almacenamiento. Una tarea que se ejecuta cada minuto puede convertirse en una fuga de costo 24/7, sobre todo si escanea muchas filas o hace fan-out por usuario. Añade una comprobación simple de “no hay trabajo” y evita el fan-out innecesario para recortar gasto sin cambiar funciones visibles.
¿Cómo decido entre parchear, refactorizar o reconstruir?
Empieza con cambios fáciles y comprobables que reduzcan un motor claro como el número de llamadas, filas escaneadas o frecuencia de jobs. Parchea cuando el arreglo esté aislado y sea testeable (limitar un endpoint, añadir cache, arreglar un N+1). Refactoriza cuando el patrón se repite (cargas duplicadas de datos, endpoints que hacen lo mismo). Reconstruye cuando los fundamentos están rotos (auth poco fiable, secretos expuestos, arquitectura que impide cambios seguros).
¿Qué debo entregar si le pido a alguien que arregle un codebase caro generado por IA?
Trae un día de línea base (24 horas de tráfico normal) y un resumen corto de lo que está caro: qué endpoints son ruidosos, qué consultas son lentas y frecuentes, y qué jobs corren con demasiada frecuencia. Si el código vino de herramientas como Lovable, Bolt, v0, Cursor o Replit y es difícil trazar qué llama a qué, FixMyMess puede empezar con una auditoría de código gratuita en fixmymess.ai y luego remediar los puntos calientes con verificación humana. La mayoría de proyectos se completan en 48–72 horas con una alta tasa de éxito; el objetivo es que el código de demostración se comporte como software de producción sin facturas sorpresa.