Buenas prácticas de manejo de errores en APIs para mensajes claros al usuario
Aprende mejores prácticas para el manejo de errores en APIs: formatos de error consistentes, mensajes seguros y un método sencillo para mapear fallos del servidor a estados claros en la UI.
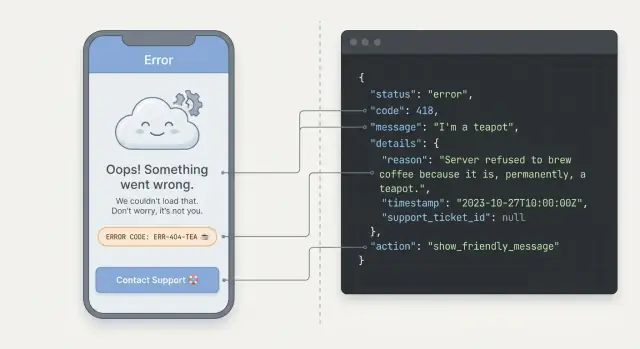
Por qué los errores de API poco claros frustran a los usuarios
Cuando una app falla, los usuarios no ven “una excepción”. Ven una tarea bloqueada. Si el mensaje es vago o alarmante, pueden preocuparse por haber perdido datos, haber hecho algo mal o incluso por un hackeo. La mayoría no intentará depurarlo: se irán, pulsarán el botón otra vez o contactarán al soporte.
Los errores confusos también dan sensación de aleatoriedad. Una pantalla puede decir “Algo salió mal”, otra muestra un largo stack trace del servidor y una tercera no devuelve nada. Esa inconsistencia hace que la gente dude porque no sabe qué esperar. Incluso si el problema es menor, la experiencia se percibe como poco fiable.
Para tu equipo, los errores inconsistentes crean ruido. Los tickets de soporte se alargan porque los usuarios no saben describir qué pasó. Las analíticas se llenan de fallos “desconocidos” sin agrupar. Los ingenieros pierden tiempo reproduciendo problemas porque la forma de respuesta cambia entre endpoints, o porque un 500 se usa para todo.
Cuando los errores son poco claros, los usuarios suelen hacer una de tres cosas: reintentar repetidamente (lo que puede crear peticiones duplicadas y a veces cargos dobles), abandonar el flujo (especialmente checkout, registro y restablecimiento de contraseña), o contactar al soporte con capturas en lugar de detalles útiles.
El manejo claro de errores arregla esto estandarizando tres cosas:
- Una forma de error consistente (para que todos los endpoints fallen igual)
- Redacción segura (para que los usuarios tengan un siguiente paso claro sin exponer detalles internos)
- Comportamiento de UI predecible (para que cada error se mapee a un estado conocido como “intentar de nuevo”, “corregir entrada” o “iniciar sesión otra vez”)
Qué debe lograr un buen error (para usuarios y para tu equipo)
Un buen error no es solo “algo falló”. Ayuda a una persona real a recuperarse y ayuda a tu equipo a encontrar la causa raíz rápido.
Para los usuarios, un error necesita tres cosas: qué pasó (en palabras simples), qué hacer a continuación (un paso claro) y si sus datos están seguros. “Tu tarjeta fue rechazada. Intenta con otra tarjeta o llama al banco. No se ha cobrado” es calmante y accionable. “Pago fallido: 402” no lo es.
Para tu equipo, el mismo error debe llevar identificadores estables y contexto útil. Eso suele implicar un pequeño conjunto de códigos de error en los que puedas confiar en todos los endpoints, más campos consistentes para que logging, alertas y manejo en la UI no se rompan cuando un endpoint cambie. Cuando un usuario reporta un problema, el soporte debe poder copiar un ID de error desde la UI y un ingeniero debe poder encontrar el rastro exacto.
Qué nunca debe llegar a la UI
Algunos detalles son útiles para depuración pero inseguros (o simplemente confusos) para los usuarios. Mantén esto fuera de los mensajes visibles:
- Secretos (API keys, tokens, contraseñas, cadenas de conexión)
- Stack traces y rutas internas de archivos
- SQL crudo, parámetros de consulta y payloads completos de la petición
- Nombres de servicios internos e infraestructura
- Reglas de validación detalladas que ayuden a un atacante a adivinar entradas
Una regla simple: devuelve mensajes seguros y amigables, y guarda los detalles afilados en logs vinculados a un código estable y un request ID.
Elige unos pocos estados de UI que soportarás en todas partes
Si cada pantalla inventa su propio comportamiento de error, los usuarios se sienten perdidos. Acordad un conjunto pequeño de estados de UI que cada página, modal y formulario pueda usar, y luego mapead los errores de la API a esos estados de la misma forma siempre.
Para la mayoría de las apps, un vocabulario corto compartido es suficiente: cargando, éxito, vacío, necesita acción (el usuario debe cambiar algo), intentar de nuevo (problema temporal) y bloqueado (no pueden continuar sin soporte o un plan distinto).
Define qué significa cada estado en palabras simples. Por ejemplo, “vacío” significa que la petición funcionó pero no hay nada que mostrar, mientras que “intentar de nuevo” significa que la petición falló y un reintento podría funcionar.
Decidid qué es reintentable y qué no. Un timeout, límite de tasa o sobrecarga del servidor suele ser reintentable. Permiso faltante, entrada inválida o cuenta expirada generalmente no son reintentables hasta que cambie algo.
Una regla rápida ayuda:
- Intentar de nuevo: temporal, seguro reintentar
- Necesita acción: el usuario puede arreglarlo (editar, iniciar sesión, confirmar email)
- Bloqueado: el usuario no puede solucionarlo solo
También planifica éxitos parciales. Esto ocurre cuando una acción masiva guarda 8 elementos y 2 fallan. La UI debe mostrar lo que sí tuvo éxito, luego señalar claramente lo que necesita acción y permitir al usuario reintentar solo los ítems fallidos.
Diseña una forma de error consistente (un formato para todos los endpoints)
Si cada endpoint devuelve errores de forma distinta, tu UI tiene que adivinar qué pasó. Una forma de error única y predecible es una de las prácticas más prácticas porque te permite construir un solo conjunto de reglas de UI y reutilizarlo en todas partes.
Un formato JSON simple
Elige una estructura JSON y devuélvela para todas las fallas (validación, auth, límites de tasa, bugs del servidor). Manténla pequeña, pero deja espacio para detalles.
{
"error": {
"code": "AUTH_INVALID_CREDENTIALS",
"message": "Email or password is incorrect.",
"details": {
"fields": {
"email": "Not a valid email address"
}
},
"developerMessage": "User not found for email: [email protected]"
},
"requestId": "req_01HZX..."
}
Usa códigos de error estables y no trates el texto del message como contrato. La UI debe mapear códigos al estado correcto, mientras que el message permanece legible para humanos.
Suele ayudar mantener dos mensajes: uno para el usuario que sea seguro mostrar y otro opcional para desarrolladores que ayude a depurar pero que tampoco debería exponer secretos.
Para formularios, reserva un lugar claro para los errores por campo para que puedas resaltar inputs específicos sin tener que parsear texto.
Algunas reglas que previenen el caos más adelante:
- Siempre incluye
error.codeyrequestId. - Mantén
error.messageseguro y en lenguaje sencillo. - Pon problemas por campo bajo
details.fields. - Mantén los códigos estables aunque cambie la redacción.
- Nunca filtrar stack traces o credenciales.
Mensajes de error seguros que los usuarios puedan entender
Los buenos errores ayudan a las personas a recuperarse. Los malos errores les hacen repetir lo mismo o abandonar. Sé específico sobre lo que el usuario puede hacer a continuación, sin revelar cómo funciona tu sistema internamente.
Un mensaje seguro explica el resultado y el paso siguiente, sin filtrar detalles como nombres de tablas, traces, respuestas de proveedores, claves secretas o si una dirección de correo existe en tu sistema.
Mantén dos mensajes: uno para usuarios y otro para desarrolladores. El mensaje para el usuario debe ser corto y calmado. El interno puede incluir la razón técnica, el servicio que falló y un trace completo (pero solo en logs, no en la respuesta que verá el usuario).
Patrones que funcionan bien:
- Di qué pasó en palabras simples: “No pudimos guardar tus cambios.”
- Di qué hacer a continuación: “Intenta de nuevo en un minuto” o “Revisa los campos señalados.”
- Evita culpar y la jerga: omite “invalid payload” y “unauthorized.”
- Usa el mismo tono en todas partes para que los errores se sientan familiares, no aterradores.
Los códigos de error pueden ayudar, pero trátalos como identificadores para soporte, no como acertijos. Si ayuda al soporte, muestra un código corto y estable (por ejemplo, “Error: AUTH-102”) y mantenlo consistente con el tiempo.
Ejemplo: el signup falla porque la base de datos agotó el tiempo. Un mensaje seguro para el usuario es: “No pudimos crear tu cuenta ahora mismo. Por favor, inténtalo de nuevo.” Tus logs internos pueden registrar: “DB timeout on users_insert, requestId=...”.
Si heredaste un backend generado por IA, esta separación suele faltar. FixMyMess ve comúnmente excepciones crudas devueltas a usuarios. Una de las primeras correcciones es mover el detalle técnico a los logs mientras la UI muestra un mensaje claro y consistente.
Mapea errores del servidor a estados de UI (una tabla simple que funciona)
Los usuarios no piensan en códigos de estado. Piensan en resultados: “Puedo arreglar esto”, “Necesito iniciar sesión otra vez” o “Algo está caído”. Elige un pequeño conjunto de estados de UI y mapea cada fallo a uno de ellos.
Un mapeo sencillo que puedes reutilizar
Usa el mismo mapeo en web, móvil y herramientas admin para que el comportamiento sea consistente.
| Qué pasó | Código típico | Estado UI | Qué debería hacer la UI |
|---|---|---|---|
| Petición incorrecta (tu app envió algo mal) | 400 | Entrada corregible | Resaltar el campo o mostrar un mensaje claro. No sugerir reintentar. |
| No autenticado / sesión expirada | 401 | Re-autenticación requerida | Llevar al login, conservar el trabajo del usuario si es posible. |
| Autenticado pero sin permiso | 403 | Sin permiso | Explicar que el acceso está bloqueado, ofrecer “contactar al admin” o cambiar de cuenta. |
| No encontrado | 404 | Recurso faltante | Mostrar “no encontrado” y ofrecer navegación de vuelta. |
| Conflicto (ya existe, desajuste de versión) | 409 | Resolver conflicto | Ofrecer refrescar, renombrar o “intentar de nuevo” tras sincronizar. |
| Validación fallida | 422 | Entrada corregible | Mostrar mensajes por campo y mantener el estado del formulario. |
| Límite de tasa | 429 | Esperar y reintentar | Decir que esperen, deshabilitar el botón brevemente y luego reintentar. |
| Bug del servidor / caída | 500 | Fallo temporal | Pedir disculpas, permitir reintentar y mostrar opción de soporte. |
Las fallas de red y timeouts son distintas de las respuestas del servidor. Trátalas como “offline/conexión inestable”: mantén al usuario en la misma pantalla, muestra un botón de reintentar y evita afirmar “tu contraseña es incorrecta” cuando la petición nunca completó.
Una regla práctica: si el usuario puede arreglarlo, mantenlo en contexto (el formulario conserva los datos). Si no puede, cambia a un estado seguro (re-login, solo lectura o contactar soporte).
Paso a paso: implementar errores consistentes sin reescribir todo
No necesitas reconstruir toda tu API para mejorar los errores. Añade una capa delgada y consistente alrededor de lo que ya tienes.
Empieza decidiendo un pequeño conjunto de códigos de error que soportarás en todas partes. Escribe definiciones cortas y claras para que backend y frontend las usen igual.
Implementa el cambio en un solo lugar en cada lado:
- Elige 8–15 códigos de error (como
AUTH_REQUIRED,INVALID_INPUT,NOT_FOUND,RATE_LIMITED,CONFLICT,INTERNAL). Escribe qué significa cada uno y qué debe ver el usuario. - Añade un formateador de errores del lado del servidor (middleware/filtro) que devuelva la misma forma JSON para todos los endpoints, incluso cuando la excepción sea inesperada.
- Añade un manejador de errores del lado cliente que lea esa forma y la mapee a tus estados de UI (error por campo, banner, toast, página completa).
- Migra gradualmente: actualiza primero los flujos más usados (login, registro, checkout, guardar). Deja el resto para cuando los toques.
- Asegura la forma con algunas pruebas para que cambios futuros no rompan a los clientes.
Un enfoque práctico de migración es soportar ambos formatos brevemente: si un endpoint ya devuelve JSON de error personalizado, pásalo tal cual; si no, envuélvelo en el nuevo formato. Eso mantiene el riesgo bajo.
Ejemplo: arregla el login primero. El servidor deja de devolver stack traces crudos y retorna un código de error estable con un mensaje seguro. El cliente ve INVALID_CREDENTIALS y muestra un mensaje inline junto al campo de contraseña. Si ve INTERNAL, muestra un banner genérico y ofrece reintentar.
Esto es especialmente útil en bases de código generadas por IA donde cada endpoint lanza errores de forma distinta. Un formateador central y un mapeador central pueden hacer que la app se sienta consistente rápidamente.
Flujos comunes y cómo presentar errores en la UI
Las personas no experimentan “un error de API”. Experimentan un formulario que no se envía, una sesión que expira o un pago que no se procesa. Si tu UI trata cada fallo igual, los usuarios adivinan, reintentan a ciegas o se van.
Formularios: la validación debe sentirse local
Cuando el servidor dice que un input es inválido, muestra el mensaje junto a ese campo concreto. Un banner arriba que diga “Algo salió mal” hace que los usuarios escaneen y reescriban todo.
Patrones buenos:
- Resalta el campo, conserva los valores escritos por el usuario y enfoca el primer input inválido.
- Usa lenguaje simple como “La contraseña debe tener al menos 12 caracteres” en lugar de códigos.
- Si hay un error general (por ejemplo, “Email ya en uso”), muéstralo cerca del botón de envío.
Autenticación: sé claro sobre lo que puede hacer el usuario
Para sesiones expiradas, decide una regla y síguela. Si puedes refrescar en segundo plano, hazlo silenciosamente una vez y continúa. Si no puedes (el refresh falla o es una acción sensible), muestra un aviso claro: “Por favor, inicia sesión de nuevo para continuar.” Evita dejar al usuario en una pantalla de error en blanco.
Pagos y conflictos necesitan cuidado extra. Di qué pasó y qué acción es segura: “No se cobró en tu tarjeta. Intenta de nuevo.” Para conflictos (otro usuario cambió los datos), explica el siguiente paso: “Este elemento se actualizó en otra sesión. Refresca para ver la versión más reciente.”
Las subidas de archivos deben responder a una pregunta: qué se subió y qué no. Muestra progreso, conserva los archivos exitosos en la lista y ofrece un reintento simple para los fallidos. Si reintentar puede crear duplicados, informa antes de que el usuario haga clic.
Escenario de ejemplo: un error de login manejado correctamente
Un usuario abre tu app después de unos días y intenta iniciar sesión. Su token de sesión guardado expiró, así que el servidor no lo acepta. Eso es normal, pero la experiencia depende de cómo lo reportes.
Aquí hay una respuesta simple que sigue buenas prácticas y es segura:
{
"error": {
"code": "AUTH_TOKEN_EXPIRED",
"message": "Your session expired. Please sign in again.",
"requestId": "req_7f3a1c9b2d"
}
}
Usa un estado HTTP claro (a menudo 401 Unauthorized para token expirado o faltante). El code permanece estable para la UI y para soporte. El message está escrito para un humano y no expone detalles como qué parte de la auth falló o qué librería usas.
En la UI, muestra un paso siguiente calmado: “Tu sesión expiró. Inicia sesión de nuevo.” Añade un botón que lleve a la pantalla de login. No muestres stack traces, JSON crudo ni palabras alarmantes como “invalid signature.” Si el usuario estaba editando algo, conserva su trabajo y vuelve a autenticar solo cuando intente enviar.
Para soporte, muestra un pequeño detalle o un botón para copiar el requestId (o código de error). Eso da a tu equipo algo accionable: “Por favor comparte requestId req_7f3a1c9b2d”, que pueden emparejar con los logs.
Logging y monitoreo que coincidan con tus códigos de error
Si la API devuelve un código de error claro pero tus logs no lo hacen, pierdes el beneficio principal. La regla más simple es loguear el mismo error.code que envías al cliente, siempre.
Una buena entrada de log es pequeña pero completa. Captura lo necesario para depurar sin volcar datos sensibles:
error.codey estado HTTP (ejemplo:AUTH_INVALID_PASSWORD, 401)requestId(ID de correlación) para seguir una petición de punta a punta- contexto seguro del usuario (userId, no email ni tokens)
- la pantalla o acción (nombre de ruta, endpoint, método)
- detalles internos para desarrolladores (stack trace, error de upstream), guardados solo del lado servidor
Genera un requestId en el borde (o acepta uno del cliente) y devuélvelo en la respuesta. Cuando un error bloquea a un usuario, muestra un mensaje corto más “Referencia: X” para que soporte encuentre el log exacto rápido.
El monitoreo es principalmente contar y agrupar, pero debe coincidir con cómo funciona la UI. Rastrea errores por código y por pantalla para detectar patrones como “PAYMENT_DECLINED ocurre mayormente en checkout” o “RATE_LIMITED se disparó tras un release.”
Decide antes en qué alertarás para que las notificaciones no sean ruido:
- picos repentinos en errores 500 (fallos del servidor)
- repeticiones en fallos de auth (puede ser bug o abuso)
- aumento de errores de límite de tasa (problema de capacidad o bug del cliente)
- un código de error dominando un endpoint o pantalla
Los equipos que arreglan backends generados por IA suelen encontrar códigos mal emparejados y request IDs faltantes. Limpiar eso primero hace que cada arreglo posterior vaya más rápido.
Errores comunes y trampas a evitar
Mucho de la mala UX viene de pequeñas inconsistencias. Incluso si cada endpoint es “correcto” por sí mismo, el producto se siente aleatorio cuando los errores son desordenados o inseguros.
Trampas comunes:
- Devolver formas diferentes de error desde distintos endpoints. El frontend se convierte en un montón de casos especiales (
messageaquí,errorallá,errors[0]en otro sitio). - Usar el texto del mensaje como “código”. Funciona hasta que alguien edita la redacción por claridad, tono o traducción, y entonces la lógica de UI se rompe.
- Filtrar stack traces, fragmentos SQL, IDs internos o valores secretos. Los usuarios no pueden actuar con ellos y los atacantes sí pueden.
- Tratar todo error como un toast que dice “Algo salió mal.” Si el usuario puede arreglarlo, dile cómo. Si no puede, di qué hacer a continuación.
- Reintentar automáticamente acciones inseguras. Reintentar una lectura suele estar bien. Reintentar una escritura puede crear duplicados o cargos dobles.
Los equipos suelen encontrarse con estos problemas en backends generados por IA. En FixMyMess vemos endpoints que devuelven varios formatos y que accidentalmente exponen secretos en la salida de errores. La victoria rápida suele ser formateo central y eliminar respuestas ad-hoc.
Lista de verificación rápida antes de lanzar
Corre esto justo antes del release. Atrapa los huecos pequeños que se vuelven tickets enojados.
Comprobaciones de salida API
Confirma que cada endpoint habla el mismo “lenguaje de error”. Aunque la causa difiera, la respuesta debe resultar familiar al cliente y fácil de loguear.
- ¿Devuelve cada endpoint la misma forma de error de nivel superior (por ejemplo:
error.code,error.message,requestId)? - ¿Son los códigos de error estables (no cambiarán la próxima semana) y están documentados en palabras claras?
- ¿Siempre hay un mensaje seguro para el usuario y detalles internos por separado (en logs) cuando los necesites?
- ¿Incluye cada error un
requestIdpara que soporte lo encuentre rápido?
Comprobaciones de comportamiento en la UI
Asegúrate de que la app reaccione de forma consistente. Los usuarios recuerdan patrones.
- ¿El cliente mapea errores del servidor a un conjunto pequeño de estados de UI (validación, auth requerida, no encontrado, conflicto, reintentar más tarde)?
- ¿Evita cada mensaje detalles internos (stack traces, SQL, nombres de proveedores) y da un paso siguiente claro?
- Cuando un error es accionable, ¿la UI apunta al campo o paso que hay que corregir?
- Cuando no es accionable (servidor caído, timeout), ¿la UI dice que el problema está del lado del servicio y ofrece reintentar?
Si tu proyecto es un prototipo generado por IA, estos básicos suelen faltar o ser inconsistentes entre endpoints. FixMyMess puede auditar el código y ayudar a que el manejo de errores sea predecible sin reescribir todo.
Siguientes pasos (y cuándo pedir ayuda para arreglar el código)
Elige un flujo crítico y hazlo tu “estándar de oro” primero. Login, checkout u onboarding son buenas opciones porque tocan auth, validación y llamadas a terceros.
Antes de cambiar nada, recopila unos 10 ejemplos reales de errores en producción (o desde logs e informes de bugs). Reescríbelos para que coincidan con tu nuevo estándar: mismos campos, misma nomenclatura, mismo nivel de detalle. Eso te da un objetivo claro y evita debates interminables.
Un camino práctico que suele funcionar:
- Añadir un formateador compartido del lado servidor que convierta cualquier error lanzado en tu forma estándar.
- Añadir un mapeador compartido del lado cliente que convierta esa forma en los estados de UI que soportas (reintentar, corregir entrada, iniciar sesión de nuevo, contactar soporte).
- Actualizar solo el flujo elegido de extremo a extremo, incluyendo pruebas y un par de fallos “falsos”.
- Desplegar el patrón endpoint por endpoint en lugar de intentar arreglar todo en un release.
- Mantener un conjunto corto de reglas de mensajes (qué puede ver el usuario, qué debe quedarse interno).
Si tu app fue generada por herramientas como Lovable, Bolt, v0, Cursor o Replit, planea tiempo extra. Estos proyectos suelen tener manejadores inconsistentes por ruta, middleware duplicado y objetos de error crudos filtrando al cliente. La victoria más rápida suele ser formato central y eliminar respuestas puntuales.
Pide ayuda cuando los errores estén ligados a problemas más profundos: flujos de autenticación rotos, secretos expuestos, riesgos de inyección SQL o lógica que “funciona en local pero falla en producción”. FixMyMess (fixmymess.ai) se centra en diagnosticar y reparar bases de código generadas por IA, incluyendo manejo de errores, endurecimiento de seguridad y preparación para despliegue.
Si solo haces una cosa esta semana, haz un flujo consistente y medible. Así los errores más claros se traducen en menos tickets de soporte y usuarios más tranquilos.
Preguntas Frecuentes
¿Qué debe incluir toda respuesta de error de la API?
Un buen punto de partida es un código de error estable, un mensaje corto seguro para el usuario y un request ID. El código permite que la UI reaccione de forma consistente, el mensaje le indica al usuario qué hacer y el request ID permite al soporte encontrar la entrada de log exacta.
¿Debo confiar en los códigos de estado HTTP o en códigos de error personalizados?
Mantén los códigos de estado HTTP con su significado general, pero no te apoyes solo en ellos. Usa el estado para categorías amplias (autenticación, validación, fallo del servidor) y tu propio error.code para casos específicos, así la UI no tiene que adivinar.
¿Cómo hago que los errores se sientan consistentes en toda la app?
Elige un conjunto pequeño de estados de UI y asigna cada código de error a uno de ellos. Cuando el mismo problema ocurra en pantallas distintas, la app debe reaccionar igual, con el mismo tono y el mismo paso siguiente.
¿Cómo escribo mensajes de error que los usuarios entiendan?
Explica lo que pasó en lenguaje llano, di el paso siguiente y tranquiliza sobre la seguridad cuando importe (por ejemplo, si se cobró o no). Evita jerga como “unauthorized” y no culpes al usuario.
¿Qué detalles nunca deben aparecer en errores visibles al usuario?
No muestres stack traces, rutas internas de archivos, SQL crudo, secretos, tokens o nombres detallados de servicios internos. Esos detalles confunden a los usuarios y pueden crear riesgos de seguridad; guárdalos en los logs del servidor asociados al request ID.
¿Cuál es la mejor forma de manejar errores de validación en formularios?
Trata la validación como “necesita acción” y muestra los mensajes junto al campo específico. Mantén el formulario con los valores ingresados, enfoca el primer campo inválido y evita banners genéricos que obliguen al usuario a buscar qué corregir.
¿Cómo debe manejar mi app sesiones expiradas (errores 401)?
Ante sesiones expiradas, muestra un mensaje claro para iniciar sesión de nuevo y procura preservar el trabajo del usuario. Usa una regla única en toda la app para que los usuarios sepan qué esperar; evita textos técnicos alarmantes como fallos de firmas o tokens.
¿Cómo debo manejar límites de tasa (429) y reintentos?
Diles al usuario que espere brevemente e intente de nuevo; considera una pequeña pausa en la UI para prevenir repeticiones rápidas. No sugieras reintentar para problemas que el usuario debe arreglar, como entrada inválida o permisos faltantes.
¿Cuándo es seguro reintentar automáticamente una petición fallida?
Asume que los reintentos pueden crear duplicados en operaciones de escritura a menos que hayas diseñado idempotencia. Si no puedes garantizar seguridad, no reintentes automáticamente; muestra una opción clara para reintentar y explica qué pasará para evitar envíos dobles o cargos duplicados.
¿Cómo puedo mejorar el manejo de errores sin reescribir toda mi API?
Empieza añadiendo un formateador del lado del servidor que convierta cualquier error lanzado a la misma forma de error, y un manejador del lado del cliente que asigne los códigos a estados de UI. Si el backend es generado por IA e inconsistente, FixMyMess puede auditar y arreglar excepciones filtradas, flujos de autenticación rotos y respuestas inestables para que la app sea predecible.