Cambios de base de datos sin tiempo de inactividad con expand-contract
Aprende a hacer cambios en la base de datos sin tiempo de inactividad con expand-contract: añade campos seguros, migra datos por etapas, mantiene el código antiguo funcionando y luego elimina lo legacy.
Por qué los cambios en la base de datos causan interrupciones
La mayoría de las caídas por trabajos en la base de datos ocurren cuando el código y el esquema cambian al mismo tiempo, pero no se despliegan en el mismo orden en todas partes. Servidores de aplicaciones, jobs en segundo plano y tareas programadas no se actualizan al instante. Durante un tiempo, conviven código viejo y código nuevo. Si cualquiera de las versiones espera algo que la base de datos ya no provee, los usuarios lo notan.
El error clásico es pensar “solo ejecuta una migración” como si fuera un paso seguro. Una migración puede bloquear tablas, reescribir muchas filas o eliminar una columna que algún proceso aún en ejecución lee. Incluso cambios “pequeños” como renombrar una columna pueden romper producción si alguna petición sigue esperando el nombre antiguo.
El downtime suele manifestarse como:
- errores 500 cuando el código lee una columna o tabla que ya no existe
- datos faltantes o incorrectos cuando el código viejo y el nuevo leen y escriben formas distintas
- timeouts cuando una migración bloquea escrituras o dispara consultas lentas
- bugs de “a mí me funciona” cuando solo algunos servidores están actualizados
- jobs en segundo plano que fallan, reintentan y aumentan la carga en el sistema
“Compatible hacia atrás” significa que el código antiguo puede seguir funcionando de forma segura mientras la base de datos cambia. En la práctica, evitas eliminar o cambiar cualquier cosa de la que dependa el código viejo. Añades campos o tablas nuevas de modo que ambas versiones puedan entenderlos, y luego mueves los datos gradualmente.
Los cambios sin downtime son difíciles porque las bases de datos son un estado compartido. Una migración arriesgada puede afectar cada petición, cada escritura y cada job a la vez. El enfoque expand-contract reduce ese riesgo eliminando el momento de todo-a-la-vez: primero expandes el esquema, ejecutas ambas versiones de forma segura, migras datos en background y limpias solo después de que la nueva vía esté probada.
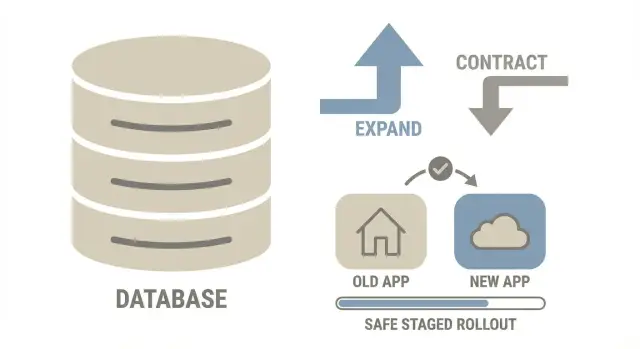
La idea de expand-contract en una imagen
Piensa en expand-contract como reformar una cocina mientras sigues cocinando cada día. No arrancas primero el fregadero viejo. Añades el nuevo fregadero, vas cambiando el uso y solo entonces quitas el antiguo.
Time ->
1) EXPAND 2) MIGRATE (gradual) 3) CONTRACT
Add new parts Copy/backfill data safely Remove old parts
Keep old path Run both paths for a while After new path is proven
- Expand: Añade lo que necesites (nueva columna, nueva tabla, nuevo índice) sin romper el código antiguo.
- Migrate: Mueve datos en pequeños lotes mientras la app sigue en línea. Durante un tiempo, conviven las formas vieja y nueva.
- Contract: Elimina las piezas antiguas solo después de que la nueva vía haya demostrado ser estable en producción.
Esto reduce el riesgo porque cada paso es más pequeño, más fácil de pausar y más fácil de razonar que una migración grande única.
Diseñar una actualización de esquema compatible hacia atrás
Un cambio de esquema compatible hacia atrás significa que tanto la versión vieja como la nueva de la app pueden ejecutarse contra la misma base de datos.
Empieza con cambios aditivos. Añade una columna nueva, una tabla nueva o una tabla de unión, pero mantén la forma antigua hasta estar seguro de que nada depende de ella. Si necesitas renombrar algo, añade el nuevo nombre primero y mantiene el antiguo funcionando (por ejemplo con una vista o una columna duplicada), y elimina el nombre antiguo después.
Durante la fase de expand, elige valores por defecto que no sorprendan al código antiguo. Los campos nullable suelen ser más seguros que los obligatorios el primer día. Si un campo debe ser NOT NULL, introdúcelo con un valor por defecto seguro que coincida con el comportamiento existente y luego aplica reglas más estrictas después de actualizar la app.
Algunas reglas previenen la mayoría de las roturas:
- No elimines columnas ni cambies significados hasta la fase de contract.
- Evita renombrar como primer paso. Añade primero, migra y luego limpia.
- Añade restricciones gradualmente (NOT NULL, UNIQUE, foreign keys) después de que los datos estén en su lugar.
- Planea cambios de índice para evitar bloqueos largos en escrituras (usa opciones online cuando estén soportadas).
- Asegúrate de que cada nuevo campo tenga una historia para filas antiguas.
Decide pronto cómo funcionarán lecturas y escrituras mientras ambas versiones conviven. Enfoques comunes son:
- El código nuevo escribe tanto la forma vieja como la nueva durante la transición (dual-write).
- El código nuevo escribe solo la forma nueva y una capa de compatibilidad mantiene la forma antigua actualizada.
- Las lecturas cambian primero, con fallback a la fuente vieja hasta que el backfill esté completo.
Ejemplo: si divides users.full_name en first_name y last_name, no elimines full_name todavía. Añade las nuevas columnas, deja que la app nueva escriba las tres y mantiene las lecturas antiguas apuntando a full_name hasta estar seguro.
Paso a paso: el flujo de trabajo expand-contract
Los cambios sin downtime funcionan mejor cuando planificas un estado intermedio temporal. Ese puente permite que el código viejo y el nuevo coexistan mientras mueves datos.
Expand: añade rutas nuevas sin romper las antiguas
Elige el modelo objetivo y diseña un modelo puente que pueda representar ambas versiones (a menudo columnas antiguas más columnas nuevas).
Expande el esquema de forma segura: añade columnas o tablas primero, conserva los campos antiguos y haz los campos nuevos nulos o dales valores por defecto seguros. Si necesitas índices, añádelos de forma que no bloqueen escrituras.
Despliega código compatible con ambas formas: publica código que pueda leer de ambos lugares y escribir de forma que mantenga los datos consistentes.
Migrar y cambiar: mueve datos, luego cambia el tráfico
Haz backfill en pequeños lotes. Haz el job reiniciable y seguro de ejecutar dos veces.
Cambia lecturas antes que escrituras. Las lecturas son más fáciles de observar y revertir porque no cambian datos. Cuando las lecturas estén estables, mueve las escrituras en fases (a menudo mediante dual-write) y luego elimina el fallback.
Solo contrata después de la verificación. Define la “verificación” por adelantado (coincidencia de contadores de filas, comprobaciones puntuales, tasa de errores y latencia normales).
Cómo migrar datos gradualmente sin romper escrituras
El enfoque más seguro es backfill de filas antiguas mientras la app sigue atendiendo tráfico. La clave es lotes pequeños y asegurar que las escrituras nuevas no omitan la nueva forma.
Ejecuta el backfill en lotes lo suficientemente pequeños para terminar rápido, con pausas breves entre lotes para que el tráfico normal se mantenga estable.
Controla el progreso para poder reanudar: un timestamp migrated_at, un flag booleano o un marcador de “último id procesado”. Combínalo con una consulta simple de “cuántos quedan” para saber si realmente avanzas.
Mientras el backfill corre, siguen llegando registros nuevos. Gestiona eso haciendo que la aplicación escriba los campos nuevos para todas las filas nuevas o actualizadas. Si no puedes hacerlo en todas partes todavía, haz dual-write por un periodo corto y luego lee desde los campos nuevos con fallback al antiguo.
Mantén el job idempotente. Debe ser seguro si se ejecuta dos veces sobre la misma fila:
- Actualiza solo filas que aún no están migradas
- Usa transformaciones deterministas (misma entrada, misma salida)
- Evita actualizaciones de tipo append que puedan duplicar datos
- Registra fallos por fila y continúa en vez de detener todo el job
También inventaría cada writer, no solo la API principal: workers, webhooks, herramientas de administración, imports y scripts. Un writer perdido puede deshacer silenciosamente tu plan.
Estrategia de despliegue: mantén el código antiguo funcionando mientras cambias datos
Asume que coexistirán formas de datos viejas y nuevas. Publica código que pueda leer ambas y no se bloquee si falta, está duplicado o no está totalmente backfilled.
Un interruptor controlado (feature flag o configuración) te ayuda a cambiar comportamiento en pasos pequeños. Una secuencia típica de despliegue:
- Despliega código que pueda leer columnas (o tablas) viejas y nuevas.
- Activa las lecturas nuevas para una pequeña porción (un entorno, un tenant o un pequeño porcentaje de tráfico).
- Observa tasas de error y consultas lentas, luego amplia.
- Una vez estables las lecturas, empieza con dual-write o cambia las escrituras en fases.
- Mantén la vía antigua disponible hasta estar seguro de que la migración está completa.
El rollback debe ser aburrido. Idealmente puedes volver a apuntar lecturas a la fuente antigua y dejar de escribir nuevo sin perder datos. Con dual-write, el rollback a menudo consiste en seguir escribiendo la forma antigua mientras investigas.
Antes de contratar (eliminar columnas o tablas), busca señales de estabilidad: no hay nulls inesperados en los campos nuevos, contadores de filas consistentes, backlog de migración que no crece y volumen de soporte normal.
Errores comunes que provocan downtime
La mayoría de las caídas durante expand-contract vienen de dos problemas: la base de datos se bloquea, o distintas partes de la app no están de acuerdo sobre lo que significan los datos.
Los errores que más golpean:
- Bloqueos largos. Cambiar tipo de columna en una tabla grande o añadir un índice “a la manera simple” puede bloquear lecturas o escrituras durante minutos.
- Deriva silenciosa en dual-write. Fallar una ruta de escritura y las formas vieja y nueva divergen. Los usuarios ven fallos “aleatorios”.
- Renombres que rompen todo lo demás. La app puede seguir funcionando mientras exportes, paneles y scripts ad-hoc empiezan a fallar.
- Olvidar rutas fuera de petición. Cron jobs, workers, paneles de admin y scripts necesitan el mismo plan de compatibilidad.
- Contratar demasiado pronto. Eliminar la columna antigua demasiado pronto y pierdes la opción de rollback.
Un ejemplo sencillo: cambias lecturas a profile_json, pero un worker de correo sigue usando last_name y empieza a enviar “Hola ,” a usuarios. No es una caída completa, pero sí un incidente en producción.
Lista rápida antes, durante y después del cambio
Los cambios sin downtime fallan por razones aburridas: la tabla es más grande de lo esperado, hay picos de tráfico, o una ruta de código sigue esperando el esquema antiguo.
Antes de empezar, confirma alcance y momento (tamaño de tabla, churn, ventana de baja carga) y confirma compatibilidad (código viejo y nuevo pueden ejecutarse de forma segura).
Durante el despliegue, vigila la app (tasa de errores, latencia) y la base de datos (CPU, locks, lag de replicación, consultas lentas). Ralentiza o pausa el backfill si suben los timeouts.
Después, demuestra que es seguro contratar: ninguna lectura ni escritura toca ya el esquema antiguo, los paneles permanecen limpios durante un ciclo de negocio completo y se eliminan flags temporales.
Una forma práctica de descubrir dependencias ocultas: en staging, haz que temporalmente las columnas antiguas devuelvan null y ejecuta flujos normales (signup, checkout, edición de perfil). Si algo falla, aún no estás listo para eliminar piezas legacy.
Ejemplo: cambiar el esquema de perfil de usuario sin downtime
Imagina que tu tabla users tiene una sola columna name ("Ada Lovelace"), pero ahora necesitas first_name y last_name para búsqueda, ordenación y correos personalizados.
Expand
Añade first_name y last_name como columnas nulas. Mantén name. No pongas NOT NULL todavía.
Actualiza la app para que cada escritura establezca ambas: sigue llenando name y además llena first_name y last_name. Las lecturas pueden seguir usando name por ahora.
Migrar y desplegar
Backfill las filas existentes con un job en background. Mantenlo simple: divide por el primer espacio, y para casos complejos ("Prince", "Mary Jane Watson-Parker") haz el mejor esfuerzo para first_name y deja last_name vacío.
Una secuencia práctica:
- Deploy 1: añade columnas
first_name,last_name - Deploy 2: dual-write (actualiza campos viejos y nuevos)
- Backfill: migra usuarios existentes en lotes
- Deploy 3: lee
first_name/last_nameprimero, con fallback aname - Verificación: confirma que los campos nuevos están llenos para usuarios activos y nuevos registros
Una vez estable el código nuevo, cambia la UI y las exportaciones para usar los campos nuevos (con fallback seguro para mostrar el nombre).
Contract
Tras confirmar que nada depende de name (incluyendo scripts y workers), deja de escribir en ella y elimínala en una release posterior.
Fase de contract: limpiar con seguridad y evitar complejidad persistente
La fase de contract elimina la estructura temporal que hizo seguro el cambio. Omitirla te deja con complejidad permanente y futuras migraciones serán más riesgosas.
"Hecho" significa que el esquema antiguo está realmente sin uso. Una definición simple para el equipo:
- Ningún código de la app lee o escribe columnas o tablas antiguas
- Ningún worker, cron o script las referencia
- No queda lógica de dual-write
- No existen feature flags solo para soportar la vía antigua
- La monitorización muestra que solo se usa la vía nueva
Antes de borrar nada, haz una búsqueda enfocada: busca en el código nombres antiguos, revisa jobs programados, chequea logs de consultas para lecturas contra objetos viejos y verifica que paneles y runbooks no mencionen campos legacy.
Después de la eliminación, borra también los ayudantes: scripts de backfill, métricas temporales y validaciones especiales que solo existieron durante la transición.
Anota qué cambió y por qué: esquema antiguo vs nuevo, cómo se movieron los datos y cuándo declaraste muerta la vía antigua. La próxima vez irás más rápido.
Siguientes pasos: planifica tu cambio y consigue una segunda opinión
Expand-contract merece la pena cuando un cambio de esquema toca una tabla caliente, autenticación, pagos o cualquier cosa que tu app escriba todo el día. Si no puedes permitir ni una ventana de mantenimiento corta, trátalo como un release, no como una "migración rápida". Para herramientas internas de poco tráfico o tablas de reporteo puntuales, una ventana planificada puede ser suficiente.
Para estimar riesgo, mira el radio de impacto y la reversibilidad. El radio de impacto es cuántas rutas de código leen o escriben esos datos (incluyendo jobs y herramientas admin). La reversibilidad es si puedes hacer rollback de la app y seguir funcionando con la base de datos.
Si tu proyecto empezó como un prototipo generado por IA, las migraciones suelen romper por razones previsibles: SQL crudo escondido, writers en background perdidos, lógica de dual-write a medias y suposiciones de esquema esparcidas por el código. Si necesitas ayuda para desenredar eso antes de un cambio en producción, FixMyMess puede auditar el código y el plan de migración y señalar los puntos riesgosos que suelen causar caídas.
Preguntas Frecuentes
¿Por qué las migraciones de base de datos rompen producción incluso cuando el cambio parece pequeño?
Porque tu flota rara vez se actualiza toda a la vez. Durante un tiempo, el código viejo y el nuevo funcionan juntos, y si alguno espera una columna, tabla o restricción que ya no existe (o que aún no existe), las peticiones empiezan a fallar o a escribir datos con la forma equivocada.
¿Qué significa “compatibilidad hacia atrás” para un cambio de base de datos?
Significa que puedes cambiar el esquema mientras el código antiguo sigue en ejecución sin provocar caídas ni corrupción de datos. En la práctica, no eliminas ni cambias el significado de nada de lo que depende el código viejo hasta estar seguro de que el nuevo camino está completamente activo y estable.
¿Qué es el enfoque expand-contract en términos sencillos?
Expand-contract es un patrón de despliegue más seguro: primero añades piezas nuevas del esquema, luego migras los datos gradualmente mientras ambos caminos (viejo y nuevo) pueden funcionar, y solo entonces eliminas las piezas antiguas. Reduce el momento único y arriesgado donde una migración grande puede tumbar todo.
¿Qué debo hacer primero en la fase de expand?
Empieza por añadir nuevas columnas o tablas sin tocar las antiguas. Haz los nuevos campos nulos o ponles valores por defecto seguros para que las escrituras existentes no fallen, y despliega código que no se bloquee si los nuevos campos faltan o están vacíos.
¿Cuándo es seguro eliminar una columna o tabla antigua?
Eliminar o renombrar columnas que el código antiguo aún lee es la forma más rápida de provocar 500s. Incluso si la API principal está actualizada, jobs en segundo plano, tareas programadas, herramientas de administración y scripts pueden seguir usando los nombres antiguos durante horas o días.
¿Cómo migro los datos existentes sin bloquear el tráfico en vivo?
Ejecuta un backfill reiniciable que mueva filas en pequeños lotes y que se pueda volver a ejecutar de forma segura. Al mismo tiempo, asegúrate de que las escrituras nuevas populen la nueva forma (a menudo mediante dual-write o una capa de compatibilidad) para no dejarte un objetivo en movimiento que nunca termina.
¿Qué es dual-write y cuándo debería usarlo?
Es cuando el código nuevo escribe tanto la representación antigua como la nueva durante la transición. Sirve para seguridad y para facilitar rollback, pero puede crear deriva si se te escapa alguna ruta de escritura, así que debes inventariar todos los writers y mantener la transformación determinista.
¿Debería cambiar las lecturas o las escrituras primero durante el despliegue?
Cambia primero las lecturas, porque puedes observar errores y volver atrás sin alterar datos. Una vez que las lecturas sean estables y el backfill esté mayormente completado, cambia las escrituras por fases y solo elimina la vía de respaldo después de verificar que el camino nuevo es consistente.
¿Qué debería monitorizar para detectar problemas pronto?
Vigila bloqueos en la base de datos, consultas lentas y lag de replicación durante cambios de esquema e índices, y observa la tasa de errores y latencia de la app durante el despliegue. Si los timeouts suben, reduce la velocidad o pausa el backfill y ajusta el plan de consultas o el tamaño de los lotes antes de continuar.
¿Cómo puede ayudar FixMyMess si mi app generada por IA sigue fallando durante migraciones?
Si tu base de código fue generada por herramientas como Lovable, Bolt, v0, Cursor o Replit, las suposiciones de esquema pueden estar repartidas en SQL crudo, jobs y migraciones a medias. FixMyMess puede hacer una auditoría gratuita del código para encontrar writers riesgosos, autenticación rota, secretos expuestos y peligros en migraciones, y luego ayudar a desplegar un rollout expand-contract seguro rápidamente.