Verificaciones de readiness y liveness que capturan fallos reales
Aprende a diseñar checks de readiness y liveness que validen tu base de datos, cola y APIs críticas para que las caídas se detecten antes de que los usuarios las noten.
Por qué los health checks que dicen “OK” aún dejan a los usuarios rotos
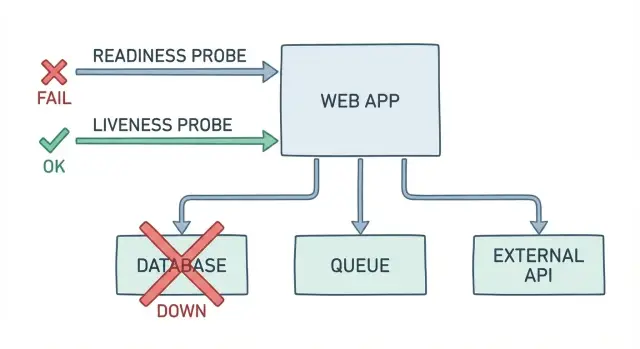
Un endpoint básico /health suele responder a una pregunta: ¿está el proceso en ejecución? Eso no es lo mismo que: ¿puede un usuario iniciar sesión, pagar o terminar su trabajo ahora mismo? Cuando tu health check responde “OK” mientras la app falla en su trabajo real, obtienes alertas “falsos verdes” y un incidente más lento y desordenado.
Así es como se ve en la vida real. El pod está arriba, la CPU parece normal y el endpoint de salud dice “OK”. Pero el inicio de sesión falla porque la base de datos está bloqueada durante una migración. Los pagos fallan porque rotó un secreto y las credenciales expiraron. Los jobs en background se acumulan porque la conexión a la cola está atascada, así que las confirmaciones de pedidos nunca se envían.
Los checks falsos verdes cuestan tiempo y confianza. El on-call persigue señales de “todo parece bien”. Soporte recibe los reportes antes que el monitoreo. Los usuarios reintentan, abandonan y recuerdan el mal día.
Readiness y liveness deberían reflejar lo que los usuarios necesitan para tener éxito. Una buena probe no es un “OK” de vanidad. Es una prueba pequeña y rápida del camino crítico.
Una probe consciente de dependencias debería responder preguntas como:
- ¿Podemos conectarnos a la base de datos y ejecutar una pequeña consulta?
- ¿Podemos autenticarnos en la cola y publicar un mensaje (o al menos verificar que la conexión está viva)?
- ¿Las credenciales requeridas son válidas y no han expirado?
- ¿Los pocos servicios externos de los que dependemos son accesibles?
Si heredaste una app generada por IA que “se ejecuta” pero se rompe en producción (a menudo alrededor de auth, secretos y colas), probes mejores evitan que despliegues dañinos perjudiquen a los usuarios en silencio.
Readiness vs liveness en lenguaje sencillo
Readiness responde: ¿puede esta instancia recibir tráfico de forma segura ahora mismo? Si la respuesta es no, debería seguir ejecutándose pero salir de rotación para que los usuarios no sean dirigidos a una copia rota.
Liveness responde: ¿está el proceso vivo y avanzando, o está atascado de una forma que un reinicio arreglaría? Si la respuesta es no, la plataforma debe reiniciarlo.
Un ejemplo simple de readiness: tu app arranca, pero la base de datos está caída o las credenciales están mal. El proceso se está ejecutando, sin embargo cada inicio de sesión y carga de página falla. Un buen readiness fallará aquí para que las peticiones dejen de llegar a esa instancia hasta que la base de datos vuelva a funcionar.
Un ejemplo simple de liveness: un bug causa un deadlock y la app deja de responder aunque el contenedor siga vivo. Readiness podría también fallar, pero eso no arregla el problema de fondo. Una probe de liveness detecta que la app no está avanzando y desencadena un reinicio para recuperarla.
Una manera fácil de recordarlo:
- Readiness protege a los usuarios de instancias malas.
- Liveness ayuda al sistema a recuperarse de instancias atascadas.
Estas comprobaciones no son tests end-to-end completos. No deberían reproducir flujos de usuario enteros ni llamar a cada dependencia en cada probe. Mantenlas pequeñas y centradas en las pocas cosas que deben ser verdad para que la app sirva tráfico con seguridad.
Empieza por lo que debe funcionar para los usuarios
Un health check solo es útil si coincide con lo que los usuarios realmente hacen. Antes de escribir readiness y liveness, anota las pocas acciones que definen “la app funciona” para tu producto. Si esas acciones fallan, los usuarios están rotos incluso si tu endpoint devuelve 200.
Mantén la lista pequeña y real: iniciar sesión y cargar el dashboard, crear un proyecto o pedido, subir un archivo y verlo aparecer, disparar un job o enviar un mensaje, completar el checkout (si tienes pagos).
Ahora mapea cada acción a lo que necesita. “Crear un proyecto” suele significar que la base de datos es escribible y que las migraciones están aplicadas. “Subir un archivo” puede requerir almacenamiento de objetos más un worker en background para procesarlo. “Enviar un mensaje” puede depender de que la cola sea alcanzable y de que los consumidores estén en marcha.
A partir de ese mapa, elige las comprobaciones mínimas que mejor representen “los usuarios pueden completar la ruta”. Un ping a la base de datos no es suficiente si las escrituras están bloqueadas. Una conexión a la cola no basta si publicar falla. Apunta a una o dos comprobaciones por camino crítico, usando las dependencias que más suelen romper la experiencia.
Finalmente, decide qué significa “degradado pero usable”. ¿Pueden los usuarios navegar pero no crear? ¿Pueden iniciar sesión pero las subidas están temporalmente deshabilitadas? Toma esa decisión a propósito, porque controla el comportamiento de readiness (¿debe la app recibir tráfico o no?).
Un escenario simple: la app carga bien, pero los proyectos nuevos nunca aparecen porque el worker no puede encolar jobs. Tu endpoint de salud UI aún dice “OK”. Un readiness que incluya un enqueue ligero (o una comprobación de publish) detecta la falla que sienten los usuarios.
Qué verificar: BD, cola y tus dependencias críticas
Un endpoint de salud útil debería responder a una pregunta: si envías una petición de usuario real ahora mismo, ¿funcionará? Eso significa que readiness (y cualquier endpoint de salud de dependencia que añadas) necesita tocar las mismas dependencias que tu app necesita para hacer su trabajo, no solo devolver “OK” porque el servidor web está corriendo.
Base de datos
Empieza simple y seguro. Verifica que puedes conectar con las mismas credenciales que usa tu app y ejecutar una consulta de solo lectura pequeña como SELECT 1. Esto detecta redes rotas, contraseñas expiradas y cadenas de conexión mal configuradas. Mantenlo rápido y no bloquees tablas ni ejecutes migraciones desde una probe.
Cola y trabajo en background
Si tu app depende de jobs en background, comprobar solo la API no es suficiente. Tu probe debería confirmar que puedes publicar un mensaje de prueba (o al menos autenticarte con el broker) y que los workers realmente consumen. También vigila una acumulación que siga creciendo, porque una cola puede estar “up” mientras el trabajo está efectivamente atascado.
Un conjunto práctico inicial es:
- Conexión a BD + una consulta ligera
- Publicar en la cola (y idealmente una señal de consumo desde un worker)
- Una llamada interna crítica que no puedes operar sin ella
- Una llamada a API externa de la que dependa tu flujo principal
- Sanidad de config: vars necesarias presentes y secretos enlazados correctamente
Las APIs externas merecen cuidado extra. No estás probando todo Internet, pero deberías saber si las credenciales son inválidas, el DNS está roto o las respuestas se han ralentizado hasta volverse inútiles.
Un ejemplo concreto: una petición de signup escribe una fila de usuario y luego encola un job “enviar email de bienvenida”. Si la comprobación de la BD pasa pero la cola no acepta mensajes, los usuarios podrían “registrarse” y nunca recibir el email de verificación. Un readiness que incluya la cola bloqueará el tráfico hasta que esa ruta funcione, en lugar de permitir fallos silenciosos.
Paso a paso: construir un readiness que bloquee tráfico
Una readiness debe responder: ¿esta instancia puede manejar peticiones de usuario reales ahora mismo? Si no, debe fallar para que el tráfico nuevo se contenga.
1) Prueba lo mínimo que importa
Comienza con la operación de base mínima que aún demuestre que la app puede funcionar. Una conexión TCP no es suficiente. Prefiere una consulta pequeña que use las mismas credenciales, esquema y ruta de red que tu app.
Un patrón común es un endpoint como /ready que ejecuta una consulta rápida y revisa una o dos dependencias críticas.
- Ejecuta una consulta ligera en la BD (por ejemplo,
SELECT 1) usando la conexión normal de la app. - Establece timeouts estrictos (centenares de milisegundos, no segundos) para que las fallas aparezcan rápido.
- Si la BD es inaccesible o expira el tiempo, devuelve “not ready” para que el balanceador mantenga el tráfico lejos.
- Incluye una razón legible en el cuerpo de la respuesta, pero nunca incluyas secretos, cadenas de conexión o volcados completos de error.
- Añade un periodo de gracia al arrancar para que los cold starts no provoquen flapping mientras la app se calienta.
2) Haz que las fallas sean obvias (pero seguras)
Devuelve un código claro (como 503) y una carga útil pequeña y segura:
{ "ready": false, "reason": "db_timeout" }
Ese campo reason ahorra tiempo en incidentes porque apunta a la dependencia fallida sin exponer datos privados.
3) Conéctalo para que realmente bloquee tráfico
En los health checks de Kubernetes, la readiness controla si un pod recibe tráfico. Asegúrate de que tu app sólo reporte ready después de poder completar esa operación real.
Paso a paso: construir un liveness que dispare reinicios
Una liveness responde: ¿este proceso sigue haciendo progresos, o está atascado? Si está atascado, un reinicio suele ser la forma más rápida de volver a un estado operativo.
- Elige una “señal de progreso” que pruebe que la app no está wedged. Buenas señales son locales y simples: un timestamp de watchdog actualizado por el bucle principal, o “tiempo desde la última petición completada”.
- Mantenla ligera y local. Una probe de liveness no debería llamar a la base de datos, cola o servicios externos. Los problemas de red provocarían reinicios innecesarios.
- Añade umbrales para evitar bucles de reinicio. Probar regularmente está bien, pero exige múltiples fallos antes de declarar el contenedor muerto. También añade un periodo de gracia de arranque.
- Registra la razón justo antes de fallar. Escribe una línea clara con la señal de bloqueo y unos pocos contadores clave (tareas pendientes, hilos ocupados, memoria).
- Prueba bajo carga real, no solo en dev. Simula alta carga, llamadas downstream lentas y payloads grandes. Muchas apps parecen bien hasta que se llenan los pools de hilos y el proceso deja de responder.
Ejemplo: un servicio acepta HTTP pero todos los hilos worker están bloqueados en un lock deadlocked. Las peticiones cuelgan, los usuarios ven spinner y la readiness puede seguir verde. Una liveness que vigile “tiempo desde la última petición completada” puede detectar el freeze y forzar un reinicio.
Bien implementadas, readiness y liveness trabajan juntas: readiness protege a los usuarios de dependencias rotas y liveness te rescata de código atascado.
Timeouts, reintentos y umbrales que funcionan en producción
Las probes deben ser rápidas y aburridas. Si una probe tarda demasiado, las peticiones se acumulan, tu app hace trabajo extra y la propia probe puede convertirse en la causa de la caída. Para la mayoría de apps, apunta a un timeout corto (a menudo 1-2 segundos) y una cantidad pequeña y fija de trabajo por probe.
Evita reintentos pesados dentro de la probe. Los reintentos pueden ocultar fallos reales y añadir carga cuando los sistemas ya están sufriendo. Si la BD está expirando tiempos, una probe que reintenta tres veces podría devolver éxito a veces, pero también golpearía la BD con más carga en el peor momento.
Umbrales simples que separan picos de fallos
En lugar de reintentar dentro de la probe, usa umbrales simples a nivel del orquestador. En Kubernetes eso suele significar permitir algunos fallos antes de actuar.
Un punto de partida práctico:
- Timeout de readiness: 1-2s, failureThreshold: 2-3
- Timeout de liveness: 1-2s, failureThreshold: 3-5
- periodSeconds: 5-10 (no sondees cada segundo salvo que sea imprescindible)
- successThreshold: 1
Piensa en esto como un pequeño presupuesto de fallos: una respuesta lenta no debería causar caos, pero fallos repetidos sí.
No listo vs muerto: elige la acción menos disruptiva
Readiness y liveness no son la misma palanca. Si una dependencia está caída, la jugada más segura suele ser marcar la app como no ready para que deje de recibir tráfico. Reiniciar a menudo no arregla una base de datos o una cola rota, y puede ralentizar la recuperación.
Usa readiness para decir: “No puedo servir usuarios correctamente ahora.” Usa liveness para decir: “Estoy atascado y necesito un reinicio.”
Errores comunes que crean falsos verdes (o flapping constante)
La mayoría de health checks fallan por una de dos razones: son demasiado superficiales (todo está “OK” mientras los usuarios no pueden iniciar sesión) o demasiado profundos (fallean por hiccups normales y provocan reinicios).
Un falso verde clásico es una probe que solo prueba que el servidor web está arriba. Si tu app acepta HTTP pero no puede leer de la BD, publicar en la cola o cargar la config esencial, los usuarios siguen rotos.
Los errores que aparecen más a menudo:
- Usar un flujo end-to-end como liveness (login + BD + cola + API externa). Cuando cualquier dependencia parpadea, el orquestador mata un proceso sano y provoca downtime auto-infligido.
- Hacer que readiness dependa de terceros inestables. Si una API de pagos o correo está lenta 30 segundos, puedes flapear entre ready y not-ready y perder tráfico. Prefiere señales más suaves (último éxito cacheado, estado de circuit breaker) en lugar de fallar siempre.
- Loguear o devolver dumps de error sin filtrar. Los endpoints de salud son lugares tentadores para imprimir stack traces, connection strings y tokens. Mantén las respuestas mínimas y limpias.
- Decir “ready” antes de que la app sea utilizable. Culpables comunes: migraciones en curso, caches sin calentar, workers no conectados o consumidor de cola caído.
- Ignorar timeouts y umbrales. Una probe sin timeouts ajustados puede acumular peticiones. Una probe sin threshold puede oscilar constantemente.
Mantén liveness superficial (¿el proceso está wedged?) y readiness honesta (¿puede servir usuarios con seguridad?).
Haz que las fallas sean fáciles de ver y actuar
Una probe que falla en silencio es casi tan mala como una que siempre devuelve OK. Cuando readiness y liveness fallan, quieres que un operador sepa qué se rompió, qué tan extendido es y qué está haciendo el sistema al respecto.
Loguea fallos de probe con un código de error corto y estable. Mantén el conjunto de códigos pequeño y consistente para que se puedan buscar y graficar. Incluye una frase de contexto y evita volcar stack traces en cada fallo de probe.
La salida útil de una probe suele incluir un código estable (como DB_CONN_TIMEOUT o QUEUE_AUTH_FAILED), el nombre de la dependencia más la operación que falló (connect, query, publish, consume) y un estado básico como ready o not-ready. Si usas degraded, sé claro qué significa y qué tráfico sigue siendo seguro.
Asegúrate de que “not-ready” tenga efecto. Pruébalo forzando una falla real en una dependencia (por ejemplo, revocar credenciales de la cola en staging). Confirma que la readiness se vuelve roja, el tráfico se detiene y la instancia deja de recibir peticiones. Si los usuarios siguen golpeándola, tu señal de readiness no está conectada al enrutamiento como piensas.
Sé igualmente estricto con los reinicios. Un fallo de liveness debe desencadenar reinicios solo cuando el proceso esté realmente wedged. Si un blip temporal en la BD causa reinicios repetidos, has convertido un problema de dependencia en una caída.
Un ejemplo concreto: los inicios de sesión fallan porque la BD es alcanzable pero las migraciones no se han ejecutado. La app devuelve HTTP 200 en /health, y sin embargo cada login lanza error. Un readiness mejor reportaría not-ready con MIGRATION_PENDING, manteniendo instancias rotas fuera del tráfico.
Lista rápida antes de lanzar health checks
Antes de confiar en readiness y liveness en producción, asegúrate de que tus probes fallen por las mismas razones que fallan los usuarios reales. Si una dependencia está caída, la probe debe decirlo rápido y claramente.
Readiness debe bloquear el tráfico cuando dependencias núcleo se quiebren: BD inaccesible, credenciales erróneas o una consulta simple expirando. Las comprobaciones de cola deben reflejar el flujo real de mensajes, no solo “puedo alcanzar el host”. Cada probe necesita un timeout duro. Las respuestas de fallo deben ser seguras de exponer (códigos y razones cortas, sin stack traces ni secretos). Y los despliegues no deben flapper, así que añade un periodo de gracia al arrancar para trabajos de calentamiento.
Una prueba en staging que vale la pena
Simula una caída real: bloquea el acceso a la BD por unos minutos o detén los workers de la cola. Confirma que la readiness se pone en rojo rápidamente, el tráfico se detiene y la app se recupera limpiamente cuando la dependencia vuelve.
Ejemplo: la app parece bien, pero la cola está rota
Una falla común se ve así: los usuarios pueden realizar un pedido, el checkout devuelve 200 y tu endpoint “health” responde “OK”. Pero los clientes nunca reciben confirmaciones de pedido y los tickets de soporte se acumulan.
¿Qué pasó? La web sigue sirviendo peticiones, pero la ruta de la cola de mensajes está rota. Quizá la app no puede publicar por credenciales malas. Quizá la cola está arriba pero con un backlog tal que los mensajes no se procesarán por horas. Desde fuera, la app parece bien.
Aquí es donde readiness y liveness importan. La probe antigua solo probaba una cosa: que el servidor web puede responder. Un readiness mejor se comporta más como un probe de dependencia y verifica lo que debe funcionar para usuarios reales.
Un readiness simple para este caso:
- Intenta una publicación ligera en la cola (o una llamada de permisos) con un timeout corto.
- Opcionalmente, verifica la latencia de la cola (por ejemplo, la edad del mensaje más antiguo) y falla readiness si sobrepasa un umbral.
- Devuelve “not ready” para que el tráfico deje de ir a esta instancia hasta que la ruta de la cola esté sana.
Liveness es distinto. Si el worker de la cola está atascado (deadlock, fuga de memoria, bucle de mensajes envenenados), normalmente quieres que el proceso worker se reinicie mientras el proceso web puede quedarse arriba. Eso suele significar probes separadas: mantiene vivo el contenedor web y permite que el contenedor worker falle liveness cuando deja de hacer progresos.
Trata la investigación posterior como tal, no conjeturas. Loguea el fallo exacto (publish timeout, auth error, spike de backlog), luego aísla la causa: servicio de cola, credenciales, policy de red o código consumidor.
Próximos pasos: mejora las probes, luego arregla las causas raíz
Si ya tienes endpoints de salud, el siguiente paso es volverlos útiles. Buenas readiness y liveness no solo reportan que el proceso corre. Detectan roturas reales temprano y evitan que pods rotos sirvan usuarios.
Escribe lo que debe funcionar para que un usuario complete la acción principal en tu app (iniciar sesión, pagar, subir, enviar un mensaje). Elige las tres dependencias principales que deben estar sanas para esa acción. Para cada una, añade una única comprobación que pruebe que la app puede usarla realmente, no solo alcanzar un hostname.
Después, arregla lo que las probes exponen. Si readiness falla porque las conexiones a BD se filtran, la probe está haciendo su trabajo. El trabajo es cerrar conexiones, ajustar límites de pool, manejar timeouts y fallar con errores claros. Si las comprobaciones de cola fallan porque los mensajes se acumulan, revisa consumidores, lógica de reintentos y manejo de dead-letter.
Si heredaste un prototipo generado por IA que se ve “verde” en checks básicos pero se rompe bajo tráfico real, una auditoría enfocada ayuda. FixMyMess (fixmymess.ai) se especializa en tomar apps generadas por IA y arreglar problemas como auth roto, secretos expuestos y jobs poco fiables, empezando a menudo con una auditoría de código gratuita para sacar a la luz lo que está fallando en producción.
Preguntas Frecuentes
¿Por qué mi endpoint /health dice OK cuando los usuarios no pueden iniciar sesión o pagar?
Una endpoint básica /health normalmente solo prueba que el proceso web puede responder. Los usuarios pueden quedar bloqueados si la base de datos está bloqueada, las credenciales expiraron, hay migraciones pendientes o la cola está atascada. Un check útil debe reflejar si la app puede completar el trabajo mínimo del que dependen los usuarios.
¿Cuál es la forma más sencilla de explicar readiness vs liveness?
Readiness significa “¿debería esta instancia recibir tráfico ahora?” y debe fallar cuando dependencias clave necesarias para peticiones reales no están disponibles. Liveness significa “¿está el proceso atascado de una forma que un reinicio arreglaría?” y solo debe fallar cuando la app deja de hacer progresos, no cuando una dependencia tiene una pequeña caída.
¿Qué debe hacer un readiness check para la base de datos?
Empieza con una operación pequeña que use la misma ruta que tu app, como ejecutar SELECT 1 con la conexión normal y un timeout estricto. Esto detecta redes rotas, credenciales incorrectas y muchos fallos de BD. Si tu flujo principal requiere escrituras, considera una señal segura relacionada con escritura (por ejemplo, verificar que las migraciones están aplicadas) en lugar de solo una lectura.
¿Cómo incluyo la cola en readiness sin volver pesada la probe?
Si la app depende de jobs en background, tu probe de readiness debe verificar que la app puede publicar en la cola (o al menos realizar una comprobación de permisos/handshake) con un timeout corto. Ahí es donde “todo parece arriba” pero confirmaciones, correos o procesamiento asíncrono fallan en silencio. Mantenlo liviano para no agregar carga extra durante incidentes.
¿Debería mi liveness check llamar a la base de datos o APIs externas?
Evita llamar servicios externos desde liveness porque una caída de terceros puede provocar bucles de reinicio y agravar la caída. Liveness debe ser local: un timestamp de watchdog, latido del event loop o “tiempo desde la última petición completada” suele ser suficiente. Usa readiness para reflejar la salud de dependencias externas.
¿Cómo debo configurar timeouts y reintentos para readiness y liveness?
Usa timeouts estrictos para que las probes fallen rápido y deja que el orquestador trate las pequeñas interrupciones con thresholds de fallos. Esto reduce el tráfico de probes durante fallos parciales y evita esconder problemas reales con reintentos internos. Si una dependencia está lenta, suele ser mejor quedar "no ready" rápido a tener pods medio operativos en rotación.
¿Cómo evito que los readiness checks flapeen con una API de terceros inestable?
Un error común es depender de un tercero inestable, lo que provoca que la app pase constantemente entre ready y not-ready y se pierda tráfico. Otra causa es que las probes hagan demasiado trabajo, convirtiéndose en mini pruebas de carga. Mantén readiness enfocado en lo esencial para servir usuarios de forma segura y trata integraciones opcionales como “degradadas” en lugar de fallos inmediatos cuando sea posible.
¿Qué deberían devolver mis endpoints de salud cuando algo está mal?
Devuelve un código claro (por ejemplo 503) y una cadena de razón corta y estable como db_timeout o queue_auth_failed. Registra el mismo código una vez por ventana de fallo para que sea buscable sin llenar logs. Nunca incluyas stack traces, tokens, connection strings o dumps de excepciones en la respuesta de la probe.
¿Puede mi app estar “degradada pero usable”, y cómo lo debe manejar readiness?
Sí, puede estar degradada y usable, si esa es la decisión correcta para tu producto. Puedes seguir aceptando navegación en solo lectura mientras deshabilitas acciones de creación, pero la app debe aplicar las mismas reglas para que los usuarios no lleguen a rutas rotas. Si no puedes separar de forma fiable “seguro” de “no seguro”, falla readiness y deja de recibir tráfico hasta que la ruta núcleo funcione de nuevo.
Mi app fue generada por una herramienta de IA y falla en producción—¿pueden ayudar?
Suelen “ejecutarse” pero fallan en auth, secretos, migraciones y jobs en background, que los health checks básicos no detectan. FixMyMess (fixmymess.ai) se especializa en diagnosticar y reparar estas fallas en producción, incluyendo endurecer probes para que despliegues defectuosos no perjudiquen a los usuarios silenciosamente. Si no sabes por dónde empezar, una auditoría de código gratuita puede mostrar los puntos de fallo reales.