Cola de mensajes muertos para trabajos en segundo plano: reintentos y reproducción segura
Aprende cómo una dead-letter queue (DLQ) para trabajos en segundo plano captura mensajes venenosos, limita reintentos y permite reproducir de forma segura sin duplicar efectos secundarios.
Qué falla cuando los trabajos en segundo plano siguen fallando
Un trabajo en segundo plano normalmente se ejecuta fuera de la vista: enviar un correo, cobrar una tarjeta, redimensionar una imagen, sincronizar un registro. Cuando falla una vez, un reintento a menudo lo arregla. El problema empieza cuando el mismo trabajo falla una y otra vez, sin límite y sin un lugar claro donde dejarlo.
Ese tipo de trabajo a menudo se llama mensaje venenoso. Significado sencillo: una entrada mala o una situación rota que hace que el worker falle cada vez que la procesa. Puede ser una carga malformada, una fila de base de datos faltante, una clave de API caducada o un bug en el código que solo aparece para un cliente.
Los reintentos infinitos hacen más daño del que piensas. Pueden:
- Crear una caída al mantener a los workers ocupados con el mismo trabajo fallido en vez de procesar trabajos sanos.
- Aumentar costos (más cómputo, más operaciones de cola, más tráfico a la base de datos).
- Llenar logs y alertas hasta que los problemas reales se ignoran.
- Provocar efectos secundarios repetidos, como cobrar o enviar correos dos veces, si el trabajo falla después de realizar la acción.
Un patrón común de fallo es el éxito parcial. Ejemplo: tu trabajo envía un correo y luego se bloquea al escribir “enviado” en la base de datos. El siguiente reintento no ve la marca “enviado” y vuelve a mandar el correo. Ahora tienes duplicados, usuarios enfadados y un rastro de auditoría confuso.
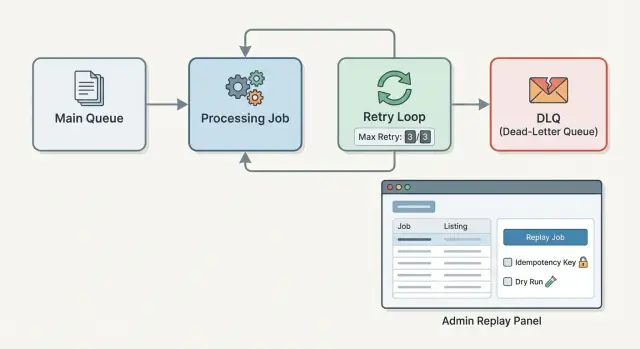
Por eso los equipos añaden una dead-letter queue (DLQ) para trabajos en segundo plano. En vez de reintentar para siempre, limitas los reintentos y separas el trabajo fallido con sus detalles de error. Luego arreglas la causa y lo replays a propósito.
Un montaje sólido tiene tres piezas: una política de reintentos que pare antes de que todo se derrita, un registro DLQ que preserve lo ocurrido y un flujo de reproducción cuidadoso con los duplicados. Si heredaste un worker inestable (incluyendo uno generado rápidamente por una herramienta de IA), estos elementos de protección pueden convertir un sistema ruidoso en uno de confianza.
Colas de mensajes muertos, explicadas sin jerga
Una dead-letter queue (DLQ) es un área de retención para trabajos en segundo plano que fallaron y no deberían seguir reintentándose automáticamente. No es un lugar donde el trabajo desaparece en silencio. Es donde las fallas se vuelven visibles, revisables y solucionables.
Piensa en mover un trabajo atascado fuera de la línea principal para que el resto del sistema pueda seguir funcionando. Estás eligiendo claridad sobre reintentos sin fin.
Algunos términos que se confunden:
- Cola de reintentos: trabajos que fallaron pero que se espera que tengan éxito más tarde (por ejemplo, un problema temporal de red). Se vuelven a ejecutar tras un retraso.
- DLQ: trabajos que fallaron y que necesitan atención humana, una corrección de código, una corrección de datos o una decisión antes de intentarlo de nuevo.
- Cola de aparcamiento: un bucket más amplio que algunos equipos usan para elementos “no urgentes”. En la práctica, a menudo se convierte en una DLQ informal sin reglas claras.
Entonces, ¿cuándo reintentas y cuándo envías a una DLQ? Reintenta cuando la falla probablemente sea temporal y sea seguro repetirla. Mueve a la DLQ cuando los reintentos no van a ayudar o podrían causar daño. Por ejemplo, “limitado por el proveedor” suele ser reintentable. “ID de cliente inválido” o “campos requeridos faltantes” generalmente requiere corrección de datos o código, por lo que pertenece a la DLQ.
Cuando un trabajo se mueve a la DLQ, debe llevar suficiente contexto para depurar y reproducir de forma segura más tarde:
- La carga del trabajo (entradas exactas usadas)
- Mensaje de error y stack trace (o equivalente)
- Conteo de reintentos y marcas temporales (primera falla, último intento)
- Una clave de idempotencia estable o huella del trabajo
- El último estado conocido del efecto secundario (si lo hay), como “cargo creado” o “correo enviado”
Ese último detalle importa. Una DLQ no es solo para capturar fallos. Es para que el siguiente intento sea una decisión controlada e informada.
Decide qué es reintentable y qué no
Los reintentos solo ayudan cuando el problema es temporal. Cuando el problema es permanente, los reintentos solo desperdician tiempo de los workers y ocultan el problema real. Esta es la primera decisión detrás de cualquier DLQ para trabajos en segundo plano: qué debe intentarse de nuevo y qué debe pararse rápido.
Una regla simple funciona bien: reintenta cuando el trabajo podría tener éxito después sin cambiar el código o la entrada. Si nunca puede tener éxito con la misma carga, no reintentes.
Clasifica fallos según la intención
En vez de tratar todas las excepciones igual, mapea las a unos pocos grupos claros:
- Transitorio: timeouts de red, caídas de conexión de base de datos, 5xx temporales de un proveedor.
- Estrangulamiento (throttling): límites de tasa (429), cuota excedida, “intenta de nuevo en 60 segundos”.
- No encontrado / estado faltante: registro relacionado eliminado, usuario que ya no existe.
- Entrada inválida: payload que falla validación, campo requerido faltante, formato incorrecto.
- Auth / permisos: credenciales caducadas, acceso revocado, acción prohibida.
Esa clasificación debe guiar lo que sucede después: reintento inmediato, reintento diferido o mover a la DLQ con una razón clara.
Ejemplo: un trabajo que cobra una tarjeta falla con un timeout de la API de pagos. Eso es transitorio, así que reintentar tiene sentido. Pero si el trabajo falla porque falta el ID del cliente en la carga, reintentar nunca lo arreglará. Ponlo en la DLQ y alerta a alguien para corregir los datos (o al productor del trabajo).
Por qué esto importa para alertas y reproducción
Una DLQ no es solo un lugar para aparcar. La razón por la que moviste un trabajo allí te dice qué hacer después:
- Fallos transitorios a menudo significan que necesitas mejor backoff, no un humano.
- Entrada inválida suele significar corrección de bug o de datos antes de reproducir.
- Fallos de auth suelen significar rotar claves antes de otra cosa.
Esto también hace la reproducción más segura. Si un trabajo está en la DLQ por “payload inválido”, tu herramienta de administración puede bloquear la reproducción por defecto y pedir una corrección primero. Muchos workers heredados fallan aquí porque todo se trata como “reintentable” hasta que alguien añade categorías claras y reglas de parada.
Define una política de reintentos que no derrita tu sistema
Los reintentos son útiles, pero los reintentos sin control pueden convertir un trabajo roto en una caída general. Una buena política limita el daño, distribuye la carga en el tiempo y para pronto cuando un trabajo claramente no va a funcionar.
Los intentos máximos deben coincidir con el tipo de fallo. “Una talla para todos” es como terminas reintentando lo incorrecto. Una llamada de red inestable podría merecer 5–10 intentos. Un payload malo (campos requeridos faltantes) no debería tener 10 intentos: debe ir a la DLQ rápidamente. Trata la DLQ como el lugar donde van los trabajos cuando se agota tu presupuesto de reintentos.
Backoff y jitter, en términos simples
Backoff significa esperar más entre intentos. Esto da tiempo a los servicios downstream para recuperarse y evita que tus workers apalancen el mismo endpoint.
- Backoff fijo: espera el mismo tiempo en cada reintento.
- Backoff exponencial: espera cada vez más tiempo.
- Jitter: añade un pequeño retraso aleatorio para que muchos trabajos no reintenten exactamente al mismo segundo.
Ejemplo: tu proveedor de pagos tiene una breve caída. Sin jitter, todos los trabajos reintentan a los 30 segundos exactos y provocan una segunda ola de fallos.
Límites de tiempo que evitan el “dolor infinito”
Define dos relojes:
- Timeout por intento (cuánto puede durar un intento antes de cancelarlo).
- Ventana temporal total (cuánto tiempo estás dispuesto a seguir reintentando antes de rendirte).
Un valor práctico para muchos equipos es: 3–5 intentos, backoff exponencial empezando en 10–30 segundos, jitter pequeño (por ejemplo, 0–10 segundos), un timeout por intento que coincida con el tiempo normal de llamada y una ventana global como 15–60 minutos. La meta no es la perfección. Es parar reintentos descontrolados antes de que se amontonen y bloqueen trabajo sano.
Qué registrar cuando mueves un trabajo a la DLQ
Cuando un trabajo de fondo termina en una dead-letter queue (DLQ), no solo estás guardando un “mensaje fallido”. Estás creando un expediente que alguien puede necesitar para entender, arreglar y reproducir de forma segura días después.
Empieza con los datos mínimos necesarios para reproducir el fallo y decidir qué hacer. Un buen registro DLQ suele incluir:
- Tipo de trabajo (qué worker debería manejarlo) y versión (si la forma del payload cambia con el tiempo)
- Payload original (tal como se recibió) más un resumen seguro y redactado para admins
- Conteo de intentos e historial de reintentos (cuántas veces y por qué siguió fallando)
- Timestamps: primera vez visto, último intento, movido a DLQ
- Detalles del error: último mensaje/stack y la cadena de causa raíz si la tienes
Un ID de trabajo estable es crítico. Généralo cuando el trabajo se crea por primera vez y mantenlo igual en reintentos y reproducciones. Luego añade una clave de deduplicación o idempotencia que represente el efecto del mundo real que intentas (por ejemplo, send_invoice_email:invoice_123:recipient_456). Eso permite reproducir sin realizar la acción dos veces.
Ten cuidado con lo que los admins ven. Los payloads suelen contener secretos, tokens o datos personales. Guarda el payload bruto solo si es necesario para depurar, pero también guarda un campo resumen seguro que esté redactado (por ejemplo, muestra el ID de usuario, no el correo; muestra los últimos 4 dígitos de una tarjeta, no el token completo).
Finalmente, guarda tanto el último error como la causa original cuando puedas. Ejemplo: un trabajo puede terminar con “timeout llamando al proveedor”, pero el error raíz fue “falta clave API”. Si tu DLQ guarda la cadena, la solución es obvia y la reproducción es más segura.
Paso a paso: añade DLQ y reintentos limitados a tu worker
Trata cada ejecución de trabajo como una pequeña transacción: o termina, o falla de una manera que puedas razonar después. Una DLQ es simplemente el lugar al que van los trabajos “ya intentamos suficiente, ahora un humano debe mirar”.
Un flujo simple que funciona en la mayoría de stacks:
- Ejecuta el manejador dentro de un try/catch (o equivalente) que capture un error tipado, no solo una cadena.
- En fallo, incrementa el contador de intentos y calcula el siguiente tiempo de ejecución usando backoff (por ejemplo: 1m, 5m, 20m), con un poco de jitter para que los reintentos no se agrupen.
- Si el error es claramente no reintentable (input malo, registro faltante, permiso denegado), o los intentos alcanzan el tope, mueve el trabajo a la DLQ en lugar de reintentar de nuevo.
- Dispara una alerta con contexto suficiente para depurar (tipo de trabajo, id, intento, clase de error, primera vez visto). Evita volcar payloads completos en alertas porque suelen contener secretos o datos personales.
- Controla algunos contadores para que los problemas se vean temprano.
try {
handle(job)
markDone(job)
} catch (err) {
attempts = job.attempts + 1
if (!isRetryable(err) || attempts >= MAX_ATTEMPTS) {
moveToDLQ(job, err)
alert(job, err)
} else {
reschedule(job, backoff(attempts))
}
}
Para dashboards, no necesitas nada sofisticado. Controla trabajos en vuelo, trabajos programados para reintento, profundidad de DLQ y “DLQ añadidos por hora”.
Evitar efectos secundarios duplicados al reproducir
Reproducir un trabajo fallido es donde se esconde el riesgo real. El trabajo original puede ya haber hecho la parte peligrosa (cobrar una tarjeta, enviar un correo, escribir una fila) y luego bloquearse al registrar, actualizar un estado o hacer un segundo paso. Si lo reproduces desde la DLQ sin protección, puedes cobrar doble, enviar un correo doble o crear registros duplicados.
La forma más sencilla de estar seguro es la idempotencia. En palabras simples: la misma solicitud debe producir el mismo resultado, aunque se ejecute dos veces. Tu trabajo debe poder decir “ya hice esto” y salir sin repetir el efecto secundario.
Formas prácticas de lograrlo:
- Claves de idempotencia: genera una clave estable por acción del mundo real (como
invoice_123_charge) y guárdala con el resultado. Al reproducir, busca la clave primero. - Restricciones únicas: haz que la base de datos imponga “solo uno” (un pago por pedido, un correo de bienvenida por usuario) y trata los duplicados como éxito.
- Patrón outbox: escribe la intención en la base de datos una vez y luego ten un remitente separado que lo entregue. Las reproducciones vuelven a comprobar y solo envían lo que sigue pendiente.
Un buen modelo mental es “escribir una vez, enviar después”. Primero, registra un hecho durable como “Pago para la orden 8821 autorizado” en una transacción. Solo después llama al servicio externo (proveedor de correo, gateway de pagos). Si el trabajo muere a mitad, la reproducción ve el hecho almacenado y hace lo mínimo que falta.
Ejemplo: un trabajo envía un correo de recibo tras una compra. Si envía el correo y luego se bloquea antes de marcar receipt_sent=true, reproducirlo enviará un segundo recibo. Arréglalo guardando receipt_sent_at con una clave única como receipt:{order_id} antes de enviar, o poniendo el correo en una tabla outbox y dejando que un remitente dedicado haga la entrega.
Construye un flujo de reproducción de administración que sea seguro por defecto
Si la gente puede reproducir trabajos de la DLQ con un clic, lo harán. El flujo de administración debe asumir errores, presión y contexto parcial. Seguro por defecto significa que la acción más fácil también es la más segura.
Empieza con un conjunto pequeño de vistas que respondan lo básico rápidamente:
- Lista DLQ: filtrar por tipo de trabajo, clase de error, fecha y entorno.
- Vista detalle: payload, clave de idempotencia, headers/metadata y el error exacto.
- Reproducir: opciones para reproducir ahora vs programar, individual vs lote.
- Descartar/resolver: un lugar para marcar “no se arreglará” con una razón.
En la vista detalle, muestra el historial de intentos: timestamps, versión del worker, conteo de reintentos y cualquier efecto secundario que registraste (por ejemplo, “factura #1234 creada”). Eso es en lo que se basan las buenas decisiones.
Los controles de reproducción deben forzar al operador a declarar la intención. La reproducción por lotes debería requerir una vista previa del filtro (“32 trabajos coinciden”) y una segunda confirmación que nombre el tipo de trabajo y el riesgo de efectos secundarios (“puede enviar correos”). Un modo de ejecución en seco (dry run) vale la pena: valida entradas y dependencias sin escribir ni llamar a externos, y luego muestra lo que ocurriría.
Los guardarraíles evitan que la reproducción convierta un mal trabajo en dos malos resultados:
- Bloquear la reproducción si la misma clave de idempotencia ya tuvo éxito.
- Por defecto programar (unos minutos después) acciones por lote, no inmediatas.
- Requerir una elección explícita cuando el trabajo se sabe no idempotente.
- Limitar la tasa de reproducciones por tipo de trabajo para evitar ráfagas.
- Siempre escribir una entrada de auditoría.
Los permisos importan. Limita la reproducción a un rol pequeño y registra quién reprodujo qué y cuándo, incluyendo la nota de motivo.
Errores comunes y trampas a evitar
La mayoría de implementaciones DLQ fallan por razones aburridas: las reglas no están claras, los reintentos son demasiado agresivos o la reproducción se trata como un botón inofensivo.
Trampas comunes (y cómo evitarlas):
- Reintentar todo para siempre. Si cada fallo es “intenta de nuevo”, nunca aprendes qué está roto. Define reglas DLQ claras (input malo, registros faltantes, fallos de auth, 4xx de terceros) y saca esos trabajos del camino caliente pronto.
- Sin tope + sin backoff = tormentas de reintentos. Una caída puede convertirse en una avalancha que enlentezca todo el sistema. Fija un conteo máximo de intentos, usa backoff exponencial con jitter y para de reintentar cuando el error sea claramente no temporal.
- Un botón de reproducción que puede duplicar efectos. Reproducir un trabajo que ya cobró una tarjeta o envió un correo puede causar daños reales. Haz handlers idempotentes (clave de idempotencia, restricciones únicas o un marcador de “ya procesado”) y diseña la reproducción para que sea segura aunque se pulse dos veces.
- Registrar secretos dentro de payloads o errores. Las DLQ suelen almacenar el cuerpo original del trabajo. Si eso incluye tokens, contraseñas o datos completos del cliente, has creado una fuga silenciosa. Redacta campos sensibles antes de encolar y sanitiza mensajes de error antes de almacenarlos.
- Usar la DLQ como almacenamiento a largo plazo. Una DLQ sin responsabilidad se convierte en un cementerio. Asigna un responsable, define una política de retención y programa limpiezas. Controla métricas básicas (tamaño de DLQ, antigüedad del elemento más viejo, tasa de éxito de reproducciones) para mantenerla bajo control.
Una regla simple ayuda: tu DLQ debe ser una bandeja de entrada de corta vida para investigación, no un vertedero. Si crece, es un bug de producto o un problema de ops y alguien debe encargarse de arreglarlo.
Ejemplo: un trabajo de correo fallido que no debe enviarse dos veces
Un usuario se registra y tu app encola un trabajo en segundo plano “enviar correo de bienvenida”. El trabajo incluye user_id, to_email, template_id y un send_id (una idempotency key única para este correo).
Un registro tiene una dirección mala como alex@@example.com. El worker llama al proveedor de correo, recibe un 400 “receptor inválido” y falla.
Tu política de reintentos lo intenta unas veces (por ejemplo, 3 intentos en 10 minutos) por si el error fuera temporal. Cada intento falla igual, así que el trabajo se mueve a la DLQ con una razón clara y no reintentable: “Formato de email inválido: alex@@example.com”. Esa frase importa porque le dice al admin qué arreglar sin hurgar en stack traces.
Durante el incidente, tus logs y métricas deberían contar la historia claramente:
- Intentos del trabajo: 3 (todos fallaron con el mismo 400)
- Cuenta DLQ: +1 (etiquetado
reason=invalid_recipient) - Envíos de correo: 0 (ningún id de mensaje del proveedor almacenado)
- Tiempo a DLQ: 10m (muestra que se limitan los reintentos)
Un admin abre el ítem de la DLQ, edita la entrada (o corrige el registro del usuario) y hace clic en reproducir. El flujo de reproducción debe ser seguro por defecto: vuelve a encolar el trabajo con el mismo send_id, y el worker comprueba primero una tabla sent_emails. Si ya existe una fila para send_id, se detiene. Si no, envía el correo, almacena el id de mensaje del proveedor y marca el trabajo como completado.
Para evitar el mismo fallo la próxima vez, valida temprano (rechaza emails malos antes de encolar) y mantiene idempotencia en cada efecto secundario (correos, cobros, webhooks).
Lista rápida y siguientes pasos
Una DLQ para trabajos en segundo plano solo ayuda en producción si los detalles aburridos están bien. Esos detalles son los que evitan que las fallas se conviertan en duplicados, caídas o desordenes silenciosos de datos.
Checklist para reintentos y captura DLQ:
- Limita intentos y define backoff (por ejemplo, 5 intentos con backoff exponencial y jitter), más un timeout rígido por intento.
- Escribe qué es reintentable vs no (huecos de red, 429/503, locks temporales en BD) y trata todo lo demás como no reintentable por defecto.
- Añade una condición de parada para mensajes venenosos (misma firma de error repitiéndose, payload inválido, campos requeridos faltantes) para que vayan a la DLQ temprano.
- Registra lo básico de la DLQ: tipo de trabajo, args (redactados), conteo de intentos, última clase y mensaje de error, stack trace, timestamps y versión del worker.
- Redacta secretos y datos personales antes de almacenar nada (tokens, contraseñas, emails completos, cuerpos de request) y lleva una pista de auditoría de quién cambió qué.
Checklist de seguridad para la reproducción:
- Elige una estrategia de idempotencia por tipo de trabajo (clave de idempotencia, restricción única o marcador de “ya procesado”) y pruébala reproduciendo el mismo trabajo dos veces.
- Separa reproducción de reintento: la reproducción debe requerir decisión humana y, idealmente, una nota de motivo.
- Restringe permisos (solo admins), añade una confirmación clara y muestra una vista previa de lo que ocurrirá (incluyendo efectos como pagos o correos).
- Decide qué cambios se permiten antes de reproducir (editar payload, cambiar destino, sobreescribir config) y registra cada edición.
- Tras reproducir, escribe el resultado (sucedió, volvió a fallar con un nuevo error o cancelado) para que la DLQ no se convierta en un agujero negro.
Si estás lidiando con una base de código generada por IA donde reintentos, idempotencia y reproducción segura nunca se diseñaron, FixMyMess (fixmymess.ai) puede ayudar a diagnosticar el comportamiento de workers y colas, reparar la lógica y endurecerla para producción.
Preguntas Frecuentes
What is a “poison message” in a background job queue?
Un mensaje venenoso es un trabajo que falla siempre con la misma entrada, por lo que los reintentos no ayudan. La solución es detener los reintentos automáticos pronto, moverlo a una DLQ con el error y la carga, y luego corregir el código o los datos antes de reproducirlo a propósito.
What’s the difference between a retry queue and a dead-letter queue (DLQ)?
Una cola de reintentos es para fallos que probablemente sean temporales y seguros de repetir, como timeouts u caídas breves. Una DLQ es para trabajos que requieren una decisión o una corrección primero, como payloads inválidos, registros faltantes o problemas de permisos, para que no sigan obstruyendo a los workers.
How many retries should a background job get before going to the DLQ?
Un valor práctico por defecto son pocos intentos con retrasos crecientes y un límite temporal rígido. Empieza con 3–5 intentos y backoff exponencial; cuando se agote el presupuesto de reintentos, mueve el trabajo a la DLQ para que un solo trabajo defectuoso no pueda dejar sin recursos al sistema.
How do I decide what errors are retryable vs non-retryable?
Reintenta solo cuando la misma carga podría tener éxito más tarde sin cambiar el código ni los datos. Timeouts, errores 5xx temporales y desconexiones breves de BD suelen ser reintentables; entradas inválidas, campos obligatorios faltantes y condiciones de “no encontrado” normalmente deben ir a la DLQ rápido.
What should I store when a job is moved to the DLQ?
Registra lo suficiente para reproducir y reproducir con seguridad: tipo de trabajo, payload (con campos sensibles redactados), conteo de intentos y tiempos, y los detalles completos del error. También guarda un ID de trabajo estable y una clave de idempotencia para que la reproducción detecte que ya se hizo la acción real y no la repita.
How do I prevent double charges or duplicate emails when replaying DLQ jobs?
La idempotencia es la principal protección: el trabajo debe poder ejecutarse dos veces y producir el mismo resultado sin repetir el efecto secundario. Usa una clave de idempotencia estable, aplica una restricción única para la acción del mundo real, o registra un estado de “ya procesado” antes de enviar correos, cobrar tarjetas o crear recursos externos.
What does a safe admin replay flow look like?
Haz que la reproducción requiera intención y añade salvaguardas: muestra el payload y el error, bloquea la reproducción si la clave de idempotencia ya tuvo éxito, y registra quién la reprodujo y por qué. En caso de duda, reproduce un solo trabajo primero y verifica el estado del efecto secundario antes de ejecutar replays por lotes.
Why are endless retries so dangerous in production?
Los reintentos infinitos pueden dejar sin recursos a los workers y convertir un trabajo malo en una caída. También aumentan costos de cómputo y de cola, ahogan las alertas reales con ruido y elevan la posibilidad de repetir efectos secundarios cuando el trabajo tuvo éxito parcialmente y luego falló.
How do I avoid leaking secrets or personal data through DLQ payloads and errors?
Sanea tanto el payload como los detalles del error antes de almacenarlos o mostrarlos, porque los trabajos suelen contener tokens, credenciales o datos personales. Mantén un resumen redactado para admins, almacena solo lo necesario para depurar y evita que logs y alertas muestren secretos en bruto.
Can FixMyMess help if my background job system was generated by an AI tool and keeps failing?
Sí. Especialmente cuando la lógica de reintentos, idempotencia y reproducción segura nunca se diseñó en una base de código generada por IA. FixMyMess puede auditar el comportamiento de la cola y los workers, identificar por qué fallan los trabajos y duplican efectos secundarios, y luego reparar y endurecer el código para producción, a menudo en 48–72 horas tras una auditoría gratuita de código.