Comprobaciones sintéticas para registros fallidos: detecta problemas de registro a tiempo
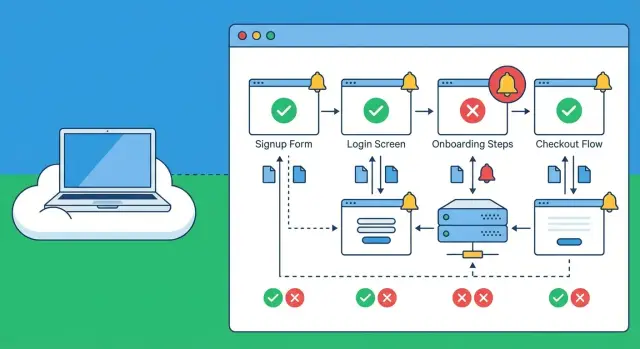
Las comprobaciones sintéticas para registros detectan fallos en inicio de sesión, onboarding y checkout desde fuera de tu red y te alertan antes de que los usuarios reales abandonen.
Por qué los registros rotos se cuelan y cómo lo vive el usuario
Un registro roto rara vez se parece a una caída dramática. Para una persona real, parece que el sitio simplemente no funciona: un botón que no hace nada, un spinner que nunca termina, un vago “Algo salió mal” o un formulario que se envía y luego la devuelve silenciosamente a la pantalla de inicio de sesión.
A veces la interfaz dice “Revisa tu correo”, pero el correo nunca llega. O llega tarde, el enlace caduca y el usuario se rinde. En móvil, un paso extra (como un CAPTCHA que no carga) puede ser suficiente para matar el flujo.
Estos fallos se cuelan porque los equipos normalmente prueban la ruta feliz dentro de su propio entorno. Las comprobaciones internas pueden confirmar que el servidor está arriba y que la base de datos responde, pero eso no garantiza que el recorrido funcione desde Internet público. Los problemas que suelen aparecer solo externamente incluyen:
- Problemas de CDN o cache que sirven un bundle de JavaScript antiguo
- Proveedores de autenticación o email de terceros bloqueados o limitados por región
- Cookies, redirecciones o CORS mal configurados que se comportan distinto fuera de la red
- Un deploy que funciona para admins autenticados pero rompe cuentas nuevas
El impacto en el negocio es directo y rápido. Un registro roto significa clics pagados sin conversiones, carritos abandonados en el checkout y más tickets de soporte que empiezan con “No puedo crear una cuenta”. Peor aún: mucha gente no se quejará. Simplemente se irá.
Las comprobaciones sintéticas para registros fallidos ayudan porque actúan como un cliente real. Ejecutan repetidamente los mismos pasos (registro, verificación, primer inicio de sesión) y avisan cuando el recorrido falla. No reemplazan la retroalimentación real de usuarios, analíticas o soporte, pero reducen el tiempo entre “se rompió” y “sabes que se rompió”.
Qué son las comprobaciones sintéticas (y qué no son)
Las comprobaciones sintéticas son scripts programados que se comportan como un usuario real. Abren tu sitio o app, hacen clic en pasos clave, introducen datos y confirman un “momento de éxito” (por ejemplo, que una cuenta nueva llega a una página de bienvenida o que se carga el primer panel). Piénsalas como un cliente fiable y repetible que aparece cada ciertos minutos y reporta lo que pasó.
“Desde fuera de tu red” significa que la comprobación corre desde Internet público, no desde tu Wi‑Fi de oficina, VPN o red interna en la nube. Eso importa porque muchos fallos de registro solo aparecen en el mundo real: problemas de DNS, CDN, cookies bloqueadas, ruteo por región o scripts de terceros que se comportan distinto fuera de tu entorno.
Las comprobaciones básicas de disponibilidad responden a una pregunta: “¿Responde la página principal?” Las comprobaciones sintéticas para registros fallidos van más allá y siguen todo el recorrido de extremo a extremo. Un sitio puede estar “arriba” mientras el registro está roto en silencio debido a un error de JavaScript, una mala respuesta de API o un secreto caducado.
Las comprobaciones sintéticas detectan bien problemas de UI (botones no clicables, formularios bloqueados, páginas que no cargan), fallos de API (500s, bugs de validación, auth rota), caídas de terceros (pagos, captcha, scripts que estrellan la página) y pasos lentos que hacen timeout.
Lo que no pueden probar de forma fiable por sí solas es si un humano recibió y usó un enlace por email. Puedes comprobar que se solicitó el correo, pero la entrega a la bandeja varía. Un enfoque común es validar el evento en backend (“email de verificación creado”) y tratar la entrega al buzón como una comprobación separada.
Elige los recorridos que importan: registro, onboarding, checkout
La mayoría de equipos intenta monitorizarlo todo y acaba no monitorizando nada bien. Empieza eligiendo de 2 a 4 recorridos de usuario que afecten directamente a ingresos o carga de soporte. En la mayoría de productos, las comprobaciones de registro reportan retorno más rápido porque fallos pequeños (un email que falta, un spinner atascado) pueden reducir a la mitad los usuarios nuevos sin que te des cuenta.
Elige recorridos que representen a una persona real intentando convertirse en cliente, no rutas internas de administradores ni pantallas de configuraciones poco usadas. Un conjunto inicial sólido es:
- Crear cuenta (email o social)
- Iniciar sesión (incluyendo un intento de “contraseña errónea”)
- Onboarding (primera acción significativa, como crear un workspace)
- Checkout (del carrito al recibo)
- Restablecer contraseña (solicitar y confirmar)
Para cada recorrido, anota una señal de éxito que puedas verificar. No te fíes de “página cargada”. Usa un momento claro que pruebe que el flujo funcionó, como una redirección a la página de bienvenida, un mensaje visible de “Estás dentro” o una pantalla de recibo con número de pedido.
Decide dónde se detiene el script. El mejor punto de parada es el primer momento clave de éxito, no todos los casos límite. Una comprobación de registro que confirma la pantalla de bienvenida suele ser suficiente. Deja casos más profundos (múltiples planes, cupones, formatos de dirección) para después, o crearás alertas ruidosas.
Haz que el script se comporte como un visitante nuevo: sesión de navegador fresca, sin cookies y con un tamaño de ventana normal. Ahí aparecen problemas ocultos, como redirecciones de auth rotas, problemas con cookies de terceros o un paso de onboarding que solo falla con el almacenamiento local vacío.
Ejemplo: pruebas el checkout mientras estás logueado como usuario antiguo, pero los usuarios nuevos deben verificar el email primero. Tu script sintético debe seguir la ruta de usuario nuevo o se te escapará el fallo.
Datos de prueba y cuentas: realista sin riesgos
Las comprobaciones sintéticas solo ayudan si se comportan como un cliente real. Eso significa pantallas reales, emails reales, redirecciones reales y, a veces, un paso de pago real. Pero nunca debes usar datos reales de clientes.
Empieza con usuarios de prueba dedicados. Hazlos obvios (por ejemplo synth_signup_01) y márcalos en tu base de datos si puedes, para que soporte y analíticas no los confundan con clientes reales. Usa direcciones de email de test y el método de pago de sandbox de tu proveedor, o un producto de bajo riesgo y un importe pequeño si debes ejecutar en producción.
Email y códigos de un solo uso son el mayor dolor. Tienes unas opciones seguras: mantener una bandeja de prueba que el script pueda leer, permitir un código de prueba conocido solo para usuarios sintéticos, o añadir una ruta de verificación separada que funcione solo con una bandera sintética. La meta es probar el mismo flujo que usan los clientes sin convertir tu auth en un vector fácil de ataque.
Staging va bien para comprobaciones rápidas, pero muchos equipos también ejecutan registros en producción porque ahí están los fallos reales: límites de tasa, caídas de terceros, redirecciones mal configuradas o un secreto caducado. Si monitorizas prod, mantén el script de bajo impacto: una ejecución, un usuario, una compra (o una autorización de $0) y limpia después.
Las credenciales son parte del producto ahora, trátalas así:
- Guarda credenciales de prueba en un gestor de secretos, no en el script o repo.
- Usa el menor acceso posible (un rol de prueba, no admin).
- Rota contraseñas, claves API y tarjetas de prueba según calendario.
- Limita el acceso a la bandeja de prueba solo al sistema de monitorización.
- Registra cada login sintético para detectar abuso.
Dónde y con qué frecuencia ejecutar comprobaciones desde fuera de tu red
Si tu script solo corre desde la IP de oficina (o la misma nube donde está tu app), puede perder los fallos que ven los clientes reales. Ejecuta comprobaciones desde Internet público, desde más de un lugar, para detectar problemas causados por ruteo, DNS, edge de CDN o outages regionales de terceros.
Una configuración simple son 2 a 4 regiones que coincidan con donde están tus usuarios. Si la mayoría están en EE. UU. y Europa, ejecuta una comprobación desde US East, otra desde US West y otra desde Europa Occidental. Esto te ayuda a detectar problemas tipo “a mí me funciona”, como un proveedor de auth que falla solo en una región.
Cadencia: ¿cada cuánto es “suficiente”?
La frecuencia es un equilibrio entre velocidad, ruido y coste. Elige una cadencia por recorrido, no una talla única:
- Cada 1 minuto: checkout y pagos, o registros de alto tráfico durante un lanzamiento
- Cada 5 minutos: registro e inicio de sesión para un producto estable
- Cada 15 minutos: pasos de onboarding que cambian raramente
- Después de despliegues: ejecuta una ronda extra inmediatamente después del release
Haz que los fallos sean fáciles de interpretar fijando timeouts por paso. Usa límites separados para carga de página, respuesta de API y pantalla de confirmación. Si “Crear cuenta” no muestra un mensaje de éxito en 20 segundos, la alerta debe decirlo claramente, no solo “test falló”.
Captura evidencia cuando algo falla
Cuando algo falla a las 3 a.m. quieres evidencia, no conjeturas. Configura tus comprobaciones para guardar una captura de pantalla en el paso que falló, logs de consola y errores de red, el paso exacto y el timeout que disparó la alerta, y un pequeño rastro de las peticiones clave (registro, intercambio de token, confirmación).
Paso a paso: construye un script sintético que realmente coincida con la realidad
Una comprobación útil se lee como una historia de usuario. Finge que eres un visitante primerizo con una conexión lenta, sin cookies y desde fuera de tu red. Tu script debe seguir ese camino, no el camino que ya conoces de memoria.
Un orden práctico de construcción
Empieza simple y afínalo hasta que capture los fallos que ven los clientes.
- Escribe el recorrido en pasos en texto plano primero, luego automatízalo: abre la página pública, espera a que cargue, rellena los mismos campos que ve el usuario, envía y confirma que llegas al estado esperado (por ejemplo, “Bienvenido” más una cabecera de usuario logueado).
- Usa selectores estables y esperas predecibles. Prefiere atributos que controles (como
data-testid) sobre IDs aleatorios o cadenas CSS frágiles. Espera a un elemento específico que indique que la página está lista, no un sleep fijo. - Valida el resultado correcto, no solo “no hubo crash”. Una pantalla de éxito puede ser falsificada por bugs del front-end. Cuando puedas, confirma la realidad del servidor también, como “registro creado” o “cookie de sesión establecida” mediante una comprobación de API.
- Añade reintentos con cuidado. Reintentar la carga de una página está bien. Reintentar una acción de negocio (crear cuenta, enviar un pedido, cobrar una tarjeta) puede crear duplicados y ocultar errores reales.
- Captura evidencia al fallar. Guarda captura de pantalla, logs de consola y errores de red clave para que la persona on‑call vea qué pasó sin reproducirlo localmente.
Hazlo resistente a falsos positivos
Las comprobaciones sintéticas de registro fallan a menudo porque solo prueban la UI. Un ejemplo común: el formulario se envía, ves un mensaje de éxito, pero la auth está rota y la siguiente página te devuelve al login. Añade un paso final “¿puedo acceder a la página de cuenta?” para probar que la sesión funciona realmente.
Alertas y triage: detectar fallos sin crear ruido
Las alertas deben responder rápido a dos preguntas: “¿Es real?” y “¿Quién debe actuar?” Si no lo hacen, la gente las ignora y el siguiente outage real pasa desapercibido.
Empieza fijando umbrales que acepten la volatilidad de Internet. Una ejecución fallida puede ser un blip. Fallos consecutivos suelen indicar una rotura real.
Un enfoque simple que funciona para la mayoría:
- Alerta tras 2 fallos consecutivos desde la misma ubicación
- Crea ticket o mensaje en la primera falla si es checkout o pago
- Auto-resuelve solo tras 1–2 ejecuciones limpias
- Añade un resumen diario de “casi fallos” para ver patrones sin ruido
El enrutamiento importa tanto como la detección. Un paso roto puede pertenecer a producto (copy o consent), a ingeniería (API o auth) o a un partner. Si no sabes quién es responsable, decide y deja constancia.
Haz las alertas accionables incluyendo contexto que responda las preguntas iniciales: qué paso falló, qué esperaba el script, qué vio en su lugar, desde dónde se ejecutó y cuándo funcionó por última vez. Incluye la última vez exitosa y un breve snippet de error (código de estado, texto de UI o mensaje de validación). “Registro falló” es ruido. “Falló en verificación por email: el campo de código no aparece; última vez OK 03:12 UTC; US‑East” es útil.
Mantén un runbook corto para triage consistente:
- Reintentar una vez desde otra ubicación para confirmar
- Revisar despliegues recientes, feature flags y estado de terceros (email/SMS, pagos)
- Probar el mismo flujo en una ventana de incógnito con cuenta de prueba
- Capturar el paso exacto y el texto de error antes de escalar
- Escalar al responsable con el contexto adjunto
Errores comunes que vuelven inútiles (o peligrosas) las comprobaciones sintéticas
Las comprobaciones sintéticas solo ayudan si se comportan como un cliente real y fallan por las mismas razones. Algunos atajos comunes pueden mostrar “verde” mientras los usuarios están atascados, o peor, causar daño real en producción.
Un fallo fácil de pasar por alto es probar solo la ruta feliz. Un registro que termina en “Cuenta creada” puede seguir roto si la verificación por email no llega, el link falla o el primer login después de verificar da error. Lo mismo ocurre con restablecer contraseña. Si no lo scripts, nunca notarás que la plantilla de email está rota o el token caduca instantáneamente.
Otra trampa es ejecutar checks solo desde tu red. Si el script corre en tu VPC puede saltarse cosas que los clientes usan: resolución DNS, comportamiento de CDN, reglas WAF, geofencing o una redirección mal configurada en el edge. La app puede parecer bien internamente mientras usuarios reales sufren timeouts, peticiones bloqueadas o un asset cacheado erróneo.
Los scripts inestables también son autoinfligidos. Si el check hace clic en un botón que se mueve, espera un spinner sobre la base de tiempos, o apunta a un selector que cambia con cada build, generas fatiga de alertas. Espera señales estables de la página (como un encabezado claro o una respuesta API conocida) y elige selectores pensados para testing.
Ten cuidado con reintentos “útiles”. Reintentar un envío de formulario puede crear usuarios duplicados, suscripciones de prueba duplicadas o incluso cargos repetidos si tu backend no es idempotente. Si necesitas reintentos, aplícalos a pasos seguros (carga de página), no a compras o creación de cuentas.
Una lista rápida de seguridad:
- Cubre verificación y restablecimiento, no solo el registro inicial
- Ejecuta desde fuera de tu red en al menos una región real
- Usa selectores estables y esperas fiables
- Evita reenviar acciones que creen datos
- Mantén credenciales fuera del código y de los logs
Finalmente, trata los secretos como datos de producción. Las cuentas de prueba deben tener permisos mínimos y las credenciales deben vivir en un almacén seguro, no en el repo del script ni en payloads de alerta.
Lista de comprobación rápida: ¿tu monitorización cubre el dolor real del usuario?
Si tu monitorización solo comprueba que la página principal carga, perderá los fallos que realmente detienen ingresos. Usa esta lista para comprobar si tu monitorización de registro sigue lo que hace un cliente nuevo, en el orden correcto, con pruebas accionables.
Una buena comprobación termina en una señal clara de éxito. “200 OK” no es suficiente. Quieres ver la primera pantalla que confirma que el usuario realmente entró (por ejemplo, una página de bienvenida, un dashboard o una pantalla de “revisa tu correo” que aparece solo después de un envío exitoso).
Lista de control rápida que refleja el dolor real del usuario:
- Un usuario completamente nuevo puede enviar el formulario de registro y llegar a la primera pantalla de éxito (no una redirección genérica).
- El inicio de sesión funciona justo después del registro en una sesión nueva (cerrar y reabrir el contexto del navegador para no depender de auth en cache).
- El onboarding realmente cambia el estado de la app (por ejemplo: un campo de perfil se guarda, o el primer workspace/proyecto se crea y es visible tras refrescar).
- El checkout llega a una pantalla de confirmación sin reintentos y no provoca un segundo cargo al refrescar la página.
- Cuando algo falla, la alerta incluye captura de pantalla y el paso exacto que falló (qué botón, qué URL, qué texto de error).
Un chequeo sencillo: imagina que tu formulario de registro funciona, pero la página siguiente se cae solo para usuarios primerizos porque no se creó un “equipo por defecto”. Las pruebas locales puede que nunca lo vean porque tu cuenta ya tiene datos. Una ejecución sintética que crea un usuario nuevo cada vez lo detectará rápido.
Escenario ejemplo: el registro funciona para ti pero falla para clientes
Un fundador lanza un lunes. El tráfico está sano, pero las cuentas nuevas caen casi a cero. El equipo revisa la disponibilidad y todo parece bien: la página principal carga, la API responde y no hay errores de servidor.
El problema es simple: el fundador (y su equipo) siguen probando el registro desde la red de la oficina en un país, en un navegador, mientras los usuarios reales vienen de varias regiones y dispositivos.
Añaden comprobaciones sintéticas para registros que corren desde fuera de su red. Una comprobación desde EE. UU., otra desde la UE y otra desde Asia. EE. UU. y la UE pasan, pero la ejecución desde Asia falla siempre justo después del botón “Continuar con Google”.
La alerta es útil porque incluye lo que vería una persona real:
- Una captura de pantalla de un bucle de redirección entre la app y el proveedor de identidad
- Un breve error de consola como “redirect_uri_mismatch” y la URL final que se repite
- El paso exacto que falló (después de auth, antes de crear la cuenta)
Resulta que la URL de callback de auth estaba mal configurada. La app tenía un callback que funcionaba para el dominio principal, pero un edge regional o un dominio alterno en Asia producía una URL de redirección ligeramente distinta. Desde el portátil del fundador nunca aparecía.
La solución es pequeña: actualizar las URLs de callback permitidas en el proveedor de auth y asegurar que la app siempre devuelva un target de redirección consistente. Luego volver a ejecutar el script sintético desde todas las regiones, confirmar que cada ejecución llega a “Cuenta creada” y cerrar el incidente.
Antes de terminar, añade una comprobación de regresión: ejecuta el mismo script de registro después de cada despliegue desde al menos una ubicación externa y alerta solo si falla dos veces seguidas.
Próximos pasos: publica tus primeras comprobaciones y estabiliza la app
Empieza pequeño y pon algo en marcha esta semana. Un script para registro y otro para checkout son suficientes para detectar la mayoría de los momentos en que “nada funciona”. Elige la ruta feliz más simple primero y añade variaciones luego (diferentes planes, códigos promocionales, métodos de pago, nuevo usuario vs recurrente).
Lanza tus dos primeros scripts como si fuera un release de producto:
- Escribe un recorrido de registro y otro de checkout que coincidan con lo que hace un cliente real, desde fuera de tu red.
- Registra una línea base: tasa de éxito y tiempo medio para completar cada recorrido.
- Añade reglas claras de éxito/fallo (por ejemplo: cuenta creada, pantalla de bienvenida mostrada, pago confirmado).
- Configura una alerta por recorrido y enrútala a la persona que puede actuar.
- Revisa resultados semanalmente y amplía cobertura solo cuando lo básico esté estable.
Una vez activas las comprobaciones, vigila los números unos días. Una pequeña caída en la tasa de éxito puede ser tan importante como una caída completa. También mide tiempo de finalización. Si tu registro de repente tarda el doble, suele indicar que algo está a medias roto (API lenta, spinner atascado, retraso en entrega de email) antes de fallar por completo.
Si los fallos son frecuentes, para y estabiliza la app antes de añadir más monitorización. Los culpables habituales son casos límite de autenticación, pasos de onboarding frágiles y manejo de errores inexistente. Arregla la causa raíz y luego ajusta el script para que compruebe los mensajes y cambios de estado correctos.
Si heredaste una base de código generada por IA y no sabes si el script está mal o la app, una pasada de remediación dirigida puede ahorrar mucho tiempo. FixMyMess (fixmymess.ai) se centra en diagnosticar y reparar problemas como autenticación rota, ruteo confuso, secretos expuestos y brechas de seguridad para que tu monitorización de registro refleje la salud real de usuarios en lugar de generar falsas alarmas.
Preguntas Frecuentes
Why does signup work for us but fail for real users?
Porque la mayoría de los equipos prueban la “ruta feliz” en su propio entorno, donde DNS, nodos CDN, cookies y proveedores de terceros se comportan de forma distinta. Los usuarios reales usan la versión pública, por lo que problemas como JavaScript antiguo en cache, cookies mal configuradas o límites regionales pueden romper el registro sin aparecer en las pruebas internas.
What’s the difference between uptime monitoring and a synthetic signup check?
Un chequeo de disponibilidad solo te dice si una página responde. Una comprobación sintética de registro recorre todo el flujo, hace clics y confirma un momento real de éxito, como llegar a una pantalla de bienvenida o cargar el primer panel tras crear una cuenta nueva.
Which user journeys should we monitor first?
Empieza con las 2–4 rutas de usuario que afectan directamente los ingresos o la carga de soporte. Para la mayoría de productos eso incluye crear cuenta, primer inicio de sesión, restablecer contraseña y checkout, porque son los caminos que los usuarios abandonan rápidamente si hay fricción.
What’s a good success signal for a signup synthetic check?
Elige una única «prueba» que demuestre que el flujo realmente funcionó, no solo que una página se cargó. Un buen valor por defecto es verificar que el usuario puede acceder a una pantalla autenticada en una sesión nueva, así evitas falsos positivos por mensajes de éxito puramente front-end.
How do we test email verification if inbox delivery is unreliable?
La forma más sencilla es validar el evento en backend de que se generó y encoló un correo, y tratar la entrega en la bandeja como una comprobación separada. Si necesitas validar el enlace de extremo a extremo, usa una bandeja de test dedicada que el script pueda leer y mantén ese acceso muy restringido.
What’s the safest way to handle test accounts and credentials?
Usa usuarios de prueba dedicados claramente identificables y evita datos reales de clientes. Guarda las credenciales en un gestor de secretos, limita permisos, y rota contraseñas, claves y tarjetas de prueba con regularidad para que no se conviertan en un punto débil.
Where should synthetic checks run from to catch real-world failures?
Ejecuta las comprobaciones desde Internet público y desde varias regiones; si solo corres desde tu red interna te perderás problemas en el edge de CDN, DNS o proveedores que solo afectan a ciertas zonas. Un valor práctico es 2–4 regiones donde estén tus usuarios para detectar fallos regionales.
How often should we run signup checks without creating alert noise?
Para productos estables, cada 5 minutos para registro e inicio de sesión es una buena base, con una ejecución extra justo después de despliegues. Aumenta la frecuencia durante lanzamientos o para checkout, y define timeouts por paso para que la alerta diga exactamente dónde se quedó.
How do we prevent flaky scripts and false passes?
Usa selectores estables que controles (por ejemplo data-testid) y espera señales claras en lugar de sleeps fijos. Evita reintentar acciones que creen datos (como crear cuenta o realizar un pedido), porque los reintentos pueden ocultar errores reales y generar duplicados.
What if our app is AI-generated and signup is already unstable?
Si ves roturas repetidas y no sabes si el script está mal o la app, arregla primero el flujo subyacente. FixMyMess (fixmymess.ai) puede auditar un código generado por IA, reparar autenticación rota, problemas de ruteo y brechas de seguridad, y ayudarte a dejar el flujo de registro estable para que la monitorización sea fiable en lugar de ruidosa.